
앞서 Hugging Face의 transformer 기반 모델을 활용하여 여러 task를 해결할 수 있음을 알았다.
그럼 끝인가?
초기 학습과 지속적인 추가 학습, 출력 저장용 데이터베이스가 추가로 필요하며 연결되어야 할 것이며 이 모델을 상용화하기 위한 여러 프레임워크가 추가적으로 필요할 것이다. 또한 사용자는 여러 LLM API 중 하나를 골라 사용할 수 있어야 할 것이다.
그렇게 나온것이 LangChain . 이번 주의 키워드이다.
들어가기 전에) LLM 의 한계
LLM, Large Language Model은 기본적으로 굉장히 깊은 layer를 가지고 있으며 상상못할 만큼의 데이터를 학습한다. 이에 따라 그들이 가지는 파라미터의 수는 수 억개를 넘어가며 대략 70억 개 이상의 파라미터를 가지는 모델부터 LLM 이라고 칭한다고 한다.
이렇게 많은 데이터를 학습한 모델은 그 데이터의 양만큼이나 다양한 작업에 고루 사용될 수 있는데 이를 파운데이션 모델 이라고 한다. 그럼 이들은 만능인가?
-
편향 (biased) 문제
대규모의 데이터를 학습하는 과정에서 필연적으로 편향된 키워드나 문장을 학습하게 되고 이는 곧 출력에 스며들게 된다.
- INLP ( Iterative Nullspace Projection ) : 편향된 키워드( ex . liberal | conservative or black | white 등 )의 벡터 값을 구해놓은 뒤, 특정 문장이나 키워드가 선형 분류기를 통해 해당 벡터로 추론될 수 있는지 여부를 확인함. 만약 추론이 가능하다면 편향성이 존재한다는 의미이므로 편향 벡터에 수직인 방향으로 투영시켜 해당 값을 없앰.
-
할루시네이션 문제
수많은 데이터를 벡터로서 학습하고 이 벡터값에 의존해 글을 생성해내는 LLM 이기에 LLM 은 올바른 정보를 뽑아내는 도구가 아니라 그럴듯한 정보를 뽑아내는 도구이다.
-
RAG ( Retrieval-Augmented Generation ) : LLM 이 응답 시 특정 문서에서 참조하여 대답을 생성하도록 하는 방법
-
CoT ( Chain of Thoughts ) : 프롬프트 엔지니어링의 한 종류로 LLM 으로 하여금 논리에 기반하여 답변을 생성하도록 하는 방법
-
Fact Checking Module : LLM 의 응답을 내보내기전에 외부 참조를 통해 사실 여부를 재검증하고 내보내도록 하는 방법
외에도 강화학습을 통해 논리적인 추론 방식을 선호하도록 만들거나, 대답에 대해 확실한 정도를 수치화시켜 표현하는 Confidence Scoring 등의 방법이 존재한다.
API 사용해보기
위의 한계에도 불구하고 LLM 은 현재 매우 강력한 성능을 보이고 있다.
지난주 Hugging Face를 통해 학습이 완료된 여러 모델을 로컬로 다운받아 사용해보았다. 하지만 로컬로 모델을 다운받는 것은 OpenSource의 경우에나 가능한 것이므로, 여기서는 직접 API를 받아 실행하는 과정에 대해 배워본다.
OpenAI 라이브러리
OpenAI 에서 제공하는 별도의 파이썬 패키지가 존재한다. 여러 GPT 모델을 사용할 수 있으며 API를 별도로 결제해놓은 상태이다.
from openai import OpenAI
client = OpenAI # 클라이언트 객체OpenAI 패키지는 아래서 나올 LangChain 을 이용한 API 사용법과 다르게 클라이언트 객체를 제공한다.
클라이언트 객체는 챗봇, 텍스트 생성, 이미지 생성, 임베딩 벡터 변환 등 openai 를 통해 할 수 있는 모든 일을 해주는 친구다.
# 챗봇
messages = [
{"role":"user", "content":"LLM에 대해 알려줘"}
]
response = client.chat.completions.create(
model='gpt-4.1',
temperature=1,
max_tokens=10,
messages=messages
)
response
>>> ChatCompletion(id= ~ , choices= ~ , model= ~ , usage= ~ ...)chat.completions 를 통해 흔히 사용하는 ChatGPT 의 역할을 할 수 있다. temperature 변수를 통해 무작위성을 올려주었으며, max_tokens 등 관련 변수들을 설정할 수 있다.
그렇게 반환된 값은 메세지 이외에도 많은 값들을 담고 있다. usage 속성을 이용하여 이번 API 사용을 통해 쓴 사용량을 확인할 수 있으며 model 속성에 사용한 모델을 확인할 수 있다.
response.choices[0]
>>> Choice(finish_reason='length', ... , message= ~ )
response.choices[0].message
ChatCompletionMessage(content='물론입니다! LLM은 "Large Language', role='assistant', ... )그 중 choices 변수를 통해 챗봇의 응답 하나하나가 담겨있으며 finish_reason 등을 확인할 수 있었다.
그 응답 하나하나, Choice 객체의 message 속성을 통해 ChatCompletionMessage 메세지 객체를 확인할 수 있었다.
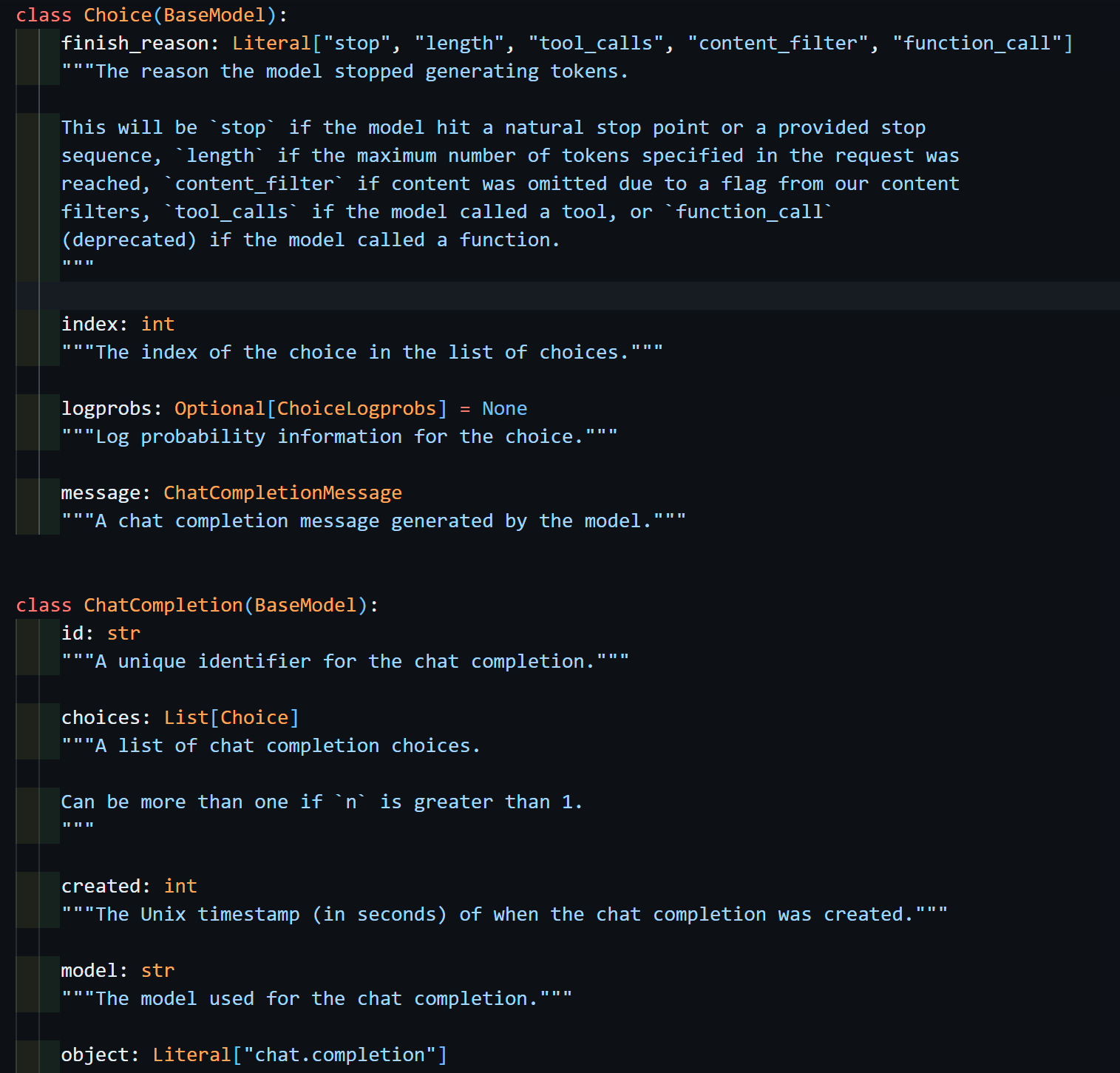
궁금해서 들어가봤다. chat.completions 로 들어가면 엄청 복잡하던데 얘는 볼만하다 !
# 텍스트 생성
response = client.completions.create(
model="gpt-4o-mini",
prompt="I used to"
)
response
>>> Completion(id= ~ , choices= ~ , model= ~ , usage= ~ ...)
response.choices[0].text
>>> ' think...\nAll stars considered... I used to think... What I liked was my'completions 을 통해서는 Completion 객체를 불러와 텍스트 생성 작업을 맡길 수 있다.
# 임베딩 벡터 생성
response = client.embeddings.create(
model="text-embedding-3-small",
input=["I", "used", "to"]
)
response
>>> CreateEmbeddingResponse(data=[Embedding(embedding=(~)), ...])
len(response.data[0].embedding)
>>> 1536임베딩 벡터 생성의 경우 gpt-4.1 등의 모델에서 지원하지 않기에 별도의 모델을 사용해야했다. 이 기능은 후에 RAG 나 유사도 검색 등에 활용할 수 있지 않을까 싶다.
# 이미지 생성
import requests
from PIL import Image
from io import BytesIO
response = client.images.generate(
model="dall-e-3",
prompt="A man eating pizza"
)
response
>>> ImagesResponse(~, data=[Image(revised_prompt= ~ , url= ~ , ...)])
response.data.revised_prompt
>>>
"""
A Middle-Eastern male in his mid-30s enjoying a slice of freshly baked pizza.
He's sitting in a bustling pizzeria with a warm, vibrant atmosphere.
Strings of twinkling lights adorn the rustic wooden beams overhead, and there's a lively chatter around him.
He's wearing a casual outfit, maybe jeans and a t-shirt, and there's a look of pure content on his face as he savors each bite.
The pizza is loaded with a colorful array of toppings, including tomatoes, basil, and melted mozzarella cheese.
"""
url = response.data[0].url
res = requests.get(url)
img = Image.open(BytesIO(res.content))
img.show()
이미지 생성 모델의 경우에도 별개의 모델을 사용해야 했으며 사용자가 제공하는 이미지에 대한 prompt를 내부적으로 LLM 을 통해 재생성한 revised_prompt 를 볼 수 있었는데 그 정교함에 놀랄 수 밖에 없었다... 어쩐지 사진이 잘 나오더라.
외에도 사용할 수 있는 모델에 대해 알아볼 수 있는 client.models , 파인튜닝을 호출하는 client.fine_tuning 등 할 수 있는 일이 정말 많았다.
LangChain을 이용한 OpenAI
여태까지 알아본 것은 OpenAI 에서 만든 OpenAI 패키지 사용법이다. 위에서 나온 클래스만 해도 ChatCompletion, Choice, ChatCompletionMessage, Completion, CreateEmbeddingResponse, ImagesResponse 등 넘쳐나는데 이걸 회사마다 다 다르게 사용하니....
위 동일한 API 를 Langchain 을 통해 사용해보자.
from langchain_openai import ChatOpenAI
# 모델 객체 생성
model = ChatOpenAI(
model='gpt-4.1', # 모델 이름
temperature=1, # 무작위성 (default=0.7)
max_tokens=100, # 최대 토큰 수
top_p=0.9, # 사용할 문서 범위
stop='\nAI', # 멈춤 트리거
frequency_penalty=1.0, # 반복 제어
presence_penalty=1.0, # 새로운 단어 추구
streaming=True, # 답변 형식 - streaming
request_timeout=10, # API 대기 시간
max_retries=10 # 최대 연결 시도 횟수
)
# 질문
response = model.invoke("ChatOpenAI의 streaming 변수는 어떻게 활용해?)
# 답변
response
>>> AIMessage(content= ~ , response_metadata= ~ , usage_metadata= ~ , ... )
response.content
>>> "streaming 변수(또는 `stream"
response.reponse_metadata
>>> {'finish_reason': 'stop',
'model_name': 'gpt-4.1-2025-04-14',
'system_fingerprint': 'fp_51e1070cf2',
'service_tier': 'default'}
response.usage_metadata
>>> None앞서 OpenAI 라이브러리를 사용했던 것과 다르게 LangChain 에서는 langchain_openai 의 하위 모듈로 chat_models, embeddings, llms 를 가지고 이들이 각각 ChatOpenAI, OpenAIEmbeddings, OpenAI 의 모델 클래스를 받는다. client 객체를 가지고 모든 일을 하던 전보다 조금 더 단순화된 느낌이다.
LangChain 에서는 이와 같이 1) Model 객체를 만들고 2) invoke( ) 메소드를 사용하여 질문을 넘기고 3) AIMessage 객체의 content 속성을 확인하는 과정으로 모든 과정이 일관되게 구성되어있다.
다른 API 에 대해서는 어떨까?
LangChain을 이용한 다른 API
< Hugging Face > < Anthropic >
< Anthropic >
 < Ollama >
< Ollama >
 < Gemini >
< Gemini >
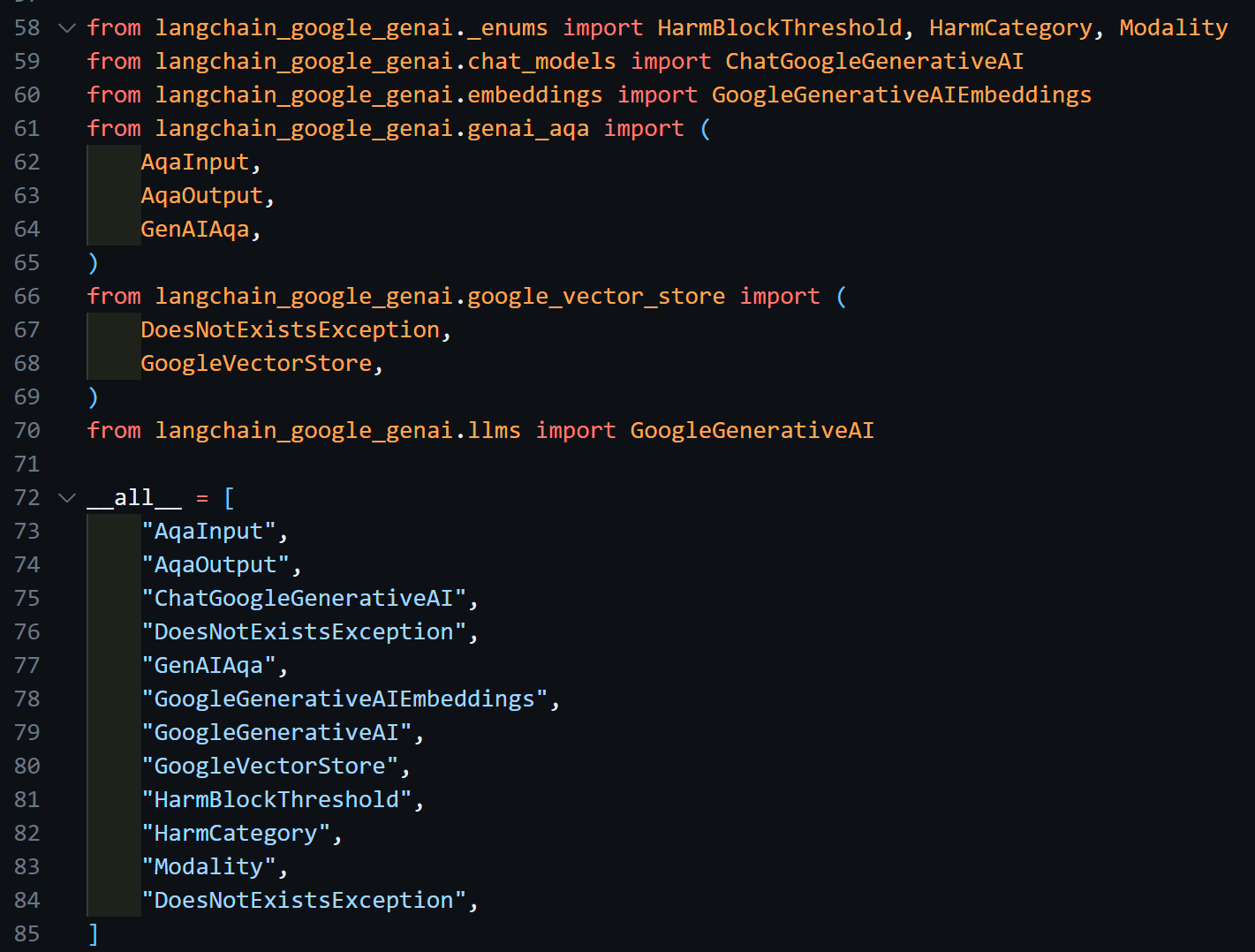
다른 API에서도 langchain_{api_source_name} 의 패키지 내에 chat_models, embeddings, llms 의 하위 모듈이 존재하고 거기에 모델 클래스가 저장되어있는 일관된 구조를 확인할 수 있다.
환경 변수에 API_KEY 만 잘 있다면 마찬가지로 사용이 가능하다 !
LangChain Model I/O
여기까지 API를 통해 LLM 모델을 사용법을 알아보았다면 이제는 그 LLM 모델에 들어갈 입력과 출력에 대해 알아볼 차례이다.
우리는 모델의 입력을 문자열(str) 으로, 출력을 AIMessage 객체로 받고 있었다.
Prompt Engineering / PromptTemplate
LLM 모델에 "최근 논란에 대해 알려줘" 라고 물어보는 것과 "근 1개월간 OO 분야에 대해 발생한 사고 및 뉴스에 대해 요약해줘" 라고 물어보는 것은 같은 모델이라 하더라도 엄연히 다른 결과를 낳는다.
이러한 이유로 LLM 모델에 들어가는 프롬프트 는 모델에 내리는 명확한 지시인 Instruction , 대화 이력이나 사용자의 정보인 Context , 입력받을 값인 Input Data , 요구되는 출력 형식인 Output Indicator 로 구성된다.
Instruction 부분에 "너는 AI 전문가야" 등의 역할을 지정해준다든가, 생각의 꼬리를 물도록하는 Chain of Thoughts(CoT) 를 적용시킨다든가, 생각의 가짓수를 늘리는 Tree of Thoughts(ToT) 등을 적용시킬 수 있다.
이런 프롬프트들은 매번 작성하기 번거로우므로 LangChain 에서 이를 만들기위한 템플릿 클래스를 제공해준다.
from langchain_core.prompts import PromptTemplate
# 템플릿 작성
template = "당신은 {subject} 전문가입니다. 2문장이내로 {object}에 대해 설명하세요."
# 프롬프트 템플릿 생성
prompt_template = PromptTemplate(template=template)
prompt_template
>>> PromptTemplate(input_variables= ~ , template="당신은 {subject} 전문가입니다."
"2문장이내로 {object}에 대해 설명하세요.", ~ )
# 프롬프트 작성
prompt = prompt_template.invoke({'subject':'AI', 'object':'prompt'})
prompt
>>> StringPromptValue(text='당신은 AI 전문가입니다. 2문장이내로 prompt에 대해 설명하세요.'위 예시는 가장 기본이 되는 PromptTemplate 클래스를 이용한 것이다. 내부에 우리가 넣어준 template 을 가지고 있으며 .invoke 메소드나 .format 메소드를 통해 해당 template에 맞는 새로운 프롬프트를 반환해준다.
이때 반환된 프롬프트는 StringPromptValue 타입을 가지게 되는데 이는 프롬프트를 표준화된 방식으로 표현하기 위한 클래스로 BasePromptValue 클래스를 상속받아 .to_string 메소드가 구현되어 있다. 그래서 이후 OpenAI 등의 모델에 입력값으로 들어갈 수 있는 것.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 채팅 형태 템플릿 작성 - 튜플로 이루어진 리스트
template = [
('system', '당신은 {subject} 전문가입니다.'),
MessagesPlaceholder(variable_name='history', optional=True),
('human', '2문장이내로 {object}에 대해 설명하세요.')
]
# 프롬프트 템플릿 생성
prompt_template = ChatPromptTemplate(messages=template)
prompt_template
>>> ChatPromptTemplate(input_variables=['object', 'subject'], optional_variables=['history'] ~ )
# 채팅 내역
chat_history = [
('human', 'prompt에 대해 설명하세요.'),
('ai', 'prompt는 모델에 들어가는 어쩌구~')
]
# 프롬프트 작성
prompt = prompt_template.invoke(
{'history':chat_history,
'subject':'AI',
'object':'template'}
)
prompt
>>> ChatPromptValue(messages=[SystemMessage( ~ ), HumanMessage( ~ ), AIMessage( ~ ), HumanMessage( ~ )] ~ )챗봇 계열의 모델을 위한 ChatPromptTemplate 을 사용해보았다. 앞서 string 타입으로 한 번에 template을 전달한 것에 반해 이번에는 리스트로 대화 내역을 넘겨주었다. 이 과정에서 MessagesPlaceholder 객체를 이용해 이전 채팅이 들어갈 공간을 확보해주었으며 이 값을 history 라는 변수로 할당해놓았다.
본래 발화자를 표현하는 기본 방법은 딕셔너리를 사용해 {"role":"human", "content":"질문 내용"} 꼴로 전달하는 것이지만, 간소화하여 위처럼 사용할 수도 있다.
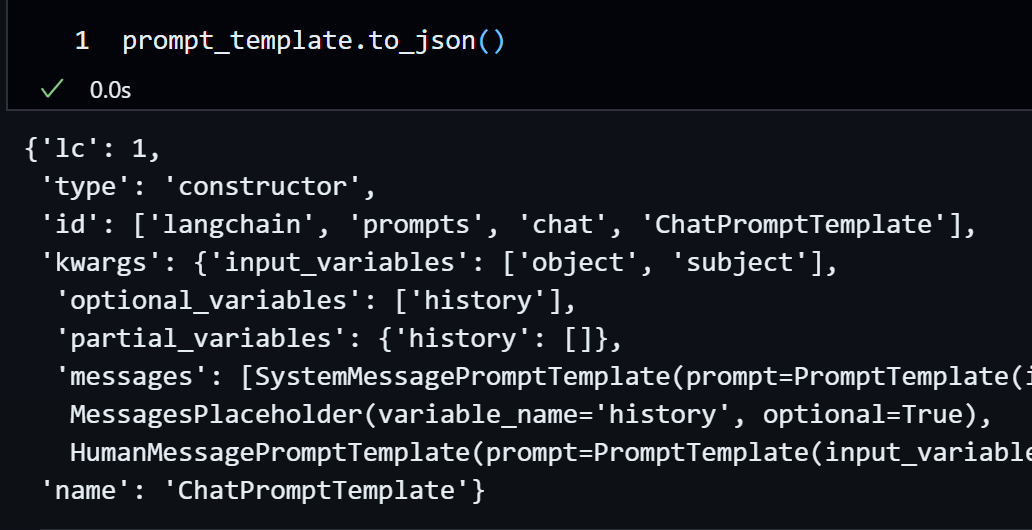
prompt_template 을 뜯어보면 각각의 채팅에 대해 기본 템플릿인 PromptTemplate 객체가 사용되었음을 확인할 수 있다.
OutputParser
앞서 모델에서 반환된 값은 모두 BaseMessage 클래스를 계승한 객체로 내부에 content, response_metadata, usage_metadata 속성을 가지고 있었다.
이 출력
Message객체를 받아 우리가 원하는 값으로 바꿔주고자 나온 것이OutputParser이다.
이들은 단순히 반환값에서 우리가 원하는 값을 뽑기만 하는 경우도 있지만, LLM 으로 하여금 우리가 원하는 형식으로 값을 반환하도록 바꾼 후 원하는 값을 뽑기도 한다.
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 모델 객체 생성
model = ChatOpenAI()
# 파서 객체 생성
str_parser = StrOutputParser()
# Parser X
response = model.invoke(prompt)
response
>>> AIMessage(content='템플릿은 일정한 형식을 가진 문서나 파일의 공통된 틀이다.', ~ )
# Parser O
response = parser.invoke(model.invoke(prompt))
response
>>> '템플릿은 일정한 형식을 가진 문서나 파일의 공통된 틀이다.'OutputParser 중 가장 단순한 StrOutputParser 를 사용해보았다. 이는 그저 BaseMessage 클래스를 계승한 메세지 객체에서 문자열 값만을 추출해주는 파서로 아마 공통적으로 존재할 content 속성을 따오는게 아닐까 싶다.
말고도 만약 여러 종류의 병렬적인 응답을 받아야하는 경우 콤마로 나누어진 여러 응답을 리스트로 묶어서 반환해주는 CommaSeparatedListOutputParser 가 존재한다. 단, 이 경우 LLM 의 응답이 "콤마로 이루어진 여러 응답" 꼴이어야기에 별도의 프롬프트를 전달해주어야 한다.
from langchain_core.output_parsers import CommaSeparatedListOutputParser
# 파서 객체 생성
list_parser = CommaSeparatedListOutputParser()
# 프롬프트 추출 by 메소드
prompt = "###Output Instructions : " + list_parser.get_format_instructions()
prompt
>>> 'Your response should be a list of comma separated values, eg: `foo, bar, baz` or `foo,bar,baz`'
# 최종
res = model.invoke("###Instructions : 과일 종류 5개" + prompt)
response = list_parser.invoke(res)
response
>>> ['사과', '바나나', '딸기', '수박', '포도']앞서 프롬프트에서 본 Instruction, Context 등등의 기능을 사용해보았다. 파서에 따른 별도의 프롬프트는 다행히 파서 객체에서 추출이 가능하다는 점.
그렇지만 LLM 을 이 콤마 구분 용도로 사용할 일이 있을까 싶다,,,,,
조금 더 유용한 파서로 LLM 의 응답을 여러 방면으로 나누어 반환해주는 JsonOutputParser 가 존재한다. 예시를 한 번 보자.
from langchain_core.output_parsers import JsonOutputParser
# 파서 객체 생성
parser = JsonOutputParser()
# 프롬프트 추출
prompt = "###Output Instructions : " + parser.get_format_instructions()
# 최종
res = model.invoke("###Instructions : 파파야에 대해" + prompt)
response = parser.invoke(res)
response
>>> {'name': 'Papaya',
'scientific_name': 'Carica papaya',
'origin': 'Tropical regions of the Americas', ~ }조금 더 실제로 사용할 만 해졌다. LLM 이 알아서 name, scientific_name 등 사용자의 질문에 맞게 특성들을 추출해 답을 만들어준다. 이 형태를 내가 정할 수는 없을까?
pydantic패키지를 통해 데이터 스키마를 정해놓을 수 있다.
입력 데이터에 대해 원하는 값의 형식에 맞는지, 자료형이 맞는지 등의 검사 작업이 가능하다.
기본적인 데이터 유효성 검사 등을 계승하기 위해 pydantic 패키지의 BaseModel 클래스를 계승한다. 이후 원하는 특성의 이름과 그 값의 자료형 등을 넣어줌으로써 나만의 스키마를 만들어낼 수 있다.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser, PydanticOutputParser
from pydantic import BaseModel, Field
from textwrap import dedent
# 스키마 작성
class MySchema(BaseModel):
"name, info, price 특성"
name: str = Field(description='제품의 이름')
info: str = Field(description="제품의 정보")
price: int = Field(description='제품의 가격', ge=0, le=320_000) # 최저, 최고 가격 설정
# 파서 객체 생성
json_parser = JsonOutputParser(pydantic_object=MySchema)
# 프롬프트 작성
template = dedent("""
### Instructions : {query}
### Output Indicator : {format}
""")
prompt_template = PromptTemplate(template=template, \
partial_variables={'format':json_parser.get_format_instructions()})
prompt = prompt_template.invoke({'query':'클라이밍 드라고 lv 신발'})
# 최종
res = model.invoke(prompt)
response = json_parser.invoke(res)
response
>>> {'name': 'Climbing shoe',
'info': 'High performance climbing shoe designed for advanced climbers.',
'price': 250000}당연하게도 JsonOutputParser 가 해당 데이터를 뽑아내는 것이고, 이 파서의 .get_format_instructions() 메소드를 통해 모델에 출력 형식을 지정해주는 것이기에 파서 객체 생성시에 데이터 스키마를 전달해주면 된다.
이렇게 파서를 거쳐 반환된 값은 딕셔너리 형태로 우리가 원한 특성들을 가지고 있게 된다.
여기서 JsonOutputParser 만 PydanticOutputParser 로 바꿔주면 동일한 내용이지만 딕셔너리의 키 값을 속성 이름으로, value 값을 속성값으로 가지는 데이터 스키마 객체 를 반환한다.
# json_parser -> pydantic_parser 로 변경
# 동일 과정 수행 후
response
>>> MySchema(name='Climbing shoe', info='Lowa Renegade GTX Mid', price=250000)LangChain Chain 기능
LangChain 에 대해 소개할 때 여러 플랫폼을 통합시켜주는 서비스라고 소개했다 아마도. 그렇기에 PromptTemplate, Model, Parser 등의 과정은 모두 입력과 출력의 형식은 다를지라도 그 작동방식은 .invoke 로 통일되어 있다. 이는 LangChain 에서 제공하는 위 클래스들이 모두 Runnable 이라는 부모 클래스를 계승받기 때문이다.
Runnable 클래스는 LangChain의 실행가능한 작업 단위를 캡슐화해놓은 것이다.
단일 입력의invoke, 다중 입력의batch, 스트리밍 방식의stream, 비동기 방식의ainvoke메소드를 지원한다.
이러한 특징을 이용해 우리는 LangChain 에서 정해준 형식 외에도 원하는 형태로 chain 을 구성할 수 있다.
# 기본 체인 구성 방식
chain = prompt_template | model | parser단, chain 은 전 과정의 출력을 다음 과정의 입력으로 받아 동일 메소드를 실행시켜주는 tool 일 뿐 입력과 출력의 형식을 다듬어주진 않는다. 각 과정의 입력과 출력 과정을 구경해보자.
# StrOutputParser 의 경우
(dictionary) > prompt_template > (PromptValue) > model > (Message 객체) > str_parser > (string)
# PydanticOutputParser 의 경우
(dictionary) > prompt_template > (PromptValue) > model > (Message 객체) > pydantic_parser > (MySchema 객체)이런 식으로 자료형이 변하게 되고 이를 다루는 것은 오롯이 사용자의 몫이다.
Runnable 의 대표적인 종류
근데 만약 입력으로 받은 값을 가공하여 모델에 제공하고 싶다면 ?
이러한 경우에 대비해 LangChain 은 크게 4가지 종류의 Runnable 하위 클래스를 제공한다.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import OpenAI
from langchain_core.runnables import (RunnableSequence, RunnableLambda,
RunnablePassthrough, RunnableSequence)
### RunnableSequence : 토대가 되는 chain 역할. 순서대로 메소드를 호출해줌
template = "{query}"
model = OpenAI()
prompt_template = ChatPromptTemplate.from_template(template=template)
parser = StrOutputParser()
seq = RunnableSequence(prompt_template, model, parser)
# prompt_template | model | parser 와 동일한 역할
response = seq.invoke("안녕 반가워")
response
>>> '\n\nAI: 반가워! 나는 OpenAI의 인공 지능이야. 어떤 일을 도와줄까?'
### RunnableLambda : 함수꼴을 Runnable 클래스로 만들어주기 위함
lam = RunnableLambda(lambda x: x.messages[0].content + "단 10단어 이내로 답변해줘")
chain = prompt_template | lam | model | parser
response = chain.invoke("안녕 반가워")
response
>>> '\n\n반가워, 만나서 반가워!'
### RunnablePassthrough : 입력값을 그대로 넘겨주는 역할
pas = RunnablePassthrough()
response = pas.invoke("안녕 반가워")
response
>>> "안녕 반가워"
### RunnableParallel : 입력값을 여러 경로로 넘겨주는 역할
par = RunnableParrallel(
{
'result1':pas,
'result2':RunnableLambda(lambda x: x + " 이름이 뭐야?")
}
)
response = par.invoke("안녕 반가워")
response
>>> {'result1':"안녕 반가워", 'result2':"안녕 반가워 이름이 뭐야?"}첫 RunnableLambda 의 경우 prompt_template 의 반환값이 ChatPromptValue 이므로 이에 맞춰 string 값을 뽑아주었다.
이러한 " | " 표현을 통한 LangChain 연결을 LCEL (LangChain Expression Language) 라고 한다.
여기까지보면 chain 을 구성하기위한 꽤나 많은 요소를 배운 것 같지만 아직 부족하다 !!
사용자 정의 Chain
chain 내의 모든 요소는 Runnable 클래스를 계승한 요소로 invoke, batch 등의 메소드에 의해 호출되고 다뤄진다. 하지만 @chain 데코레이터를 사용하면 일반 함수도 chain의 요소로써 사용이 가능하다.
데코레이터는 해당 함수를 감싸는 또 다른 함수이다. 함수를 인자로 받는 함수라고 보면 되겠다.
따라서,@chain데코레이터는 일반 함수에 붙어 이 함수를Runnable타입의 객체로 만든다.
단!! 모든 Runnable 타입은 입력을 하나만 받기 때문에 함수가 여러 입력을 받을 경우 별도의 wrapper_function 을 정의해주어야 한다.
from langchain_core.runnables import chain # 데코레이터 호출
# @chain
def sum(num1, num2):
return num1+num2
@chain
def wrapper_sum(num):
return sum(num[0], num[1])
type(sum), type(wrapper_sum)
>>> (function, langchain_core.runnables.base.RunnableLambda)이런식이다. sum 함수를 @chain 으로 만들지 못하기에 wrapper_sum 을 별도로 만들어 체인에 합류시켰다.
다른 메소드들
Runnable 타입의 invoke 메소드는 한 번 호출되면 LLM 의 응답이 전부 생성된 뒤, 이를 모아 하나의 응답데이터로 반환해준다. 이 경우 응답이 완료되기까지 오랜 시간이 걸리기에 LangChain은 이 응답을 실시간으로 받을 수 있는 stream 메소드를 지원한다.
stream메소드는 LLM 의 응답 데이터를 받는 iterator 객체를 반환한다.
이를 통해 LLM 의 응답을 chunk 별로 받아볼 수 있다.
from langchain_open import ChatOpenAI
model = ChatOpenAI()
output_iter = model.stream("LLM이 뭐야?")
type(output_iter)
>>> <class 'generator'>
for output in output_iter:
print(output)
>>> 실시간 응답위 코드에서는 output_iter 변수가 model 의 응답을 받을 iterator 객체로서 선언되었다. 이후 모델이 응답을 하나하나 생성함에 따라 이 iterator 는 다음 값을 하나씩 전달받게 되므로 for 구문에서 내부적으로 시행되는 next() 메소드에 의해 실시간으로 응답이 출력되는 것이다.
batch메소드는 LLM 에게 여러 데이터를 한 번에 넘겨줄 때 사용한다.
messages = ["LLM에 대해 10단어로", "클라이밍에 대해 10단어로"]
response = model.batch(messages)
response
>>> [AIMessage(content='대량 데이터를 학습하여 자연어 처리하는 AI 모델입니다.', ~ ),
AIMessage(content='클라이밍은 암벽을 오르는 스포츠로 도전과 기술을 요구합니다.', ~ )]비동기 방식의
ainvoke는 나중에...
