딥러닝을 마무리하고 여태까지 배운 내용을 꽃 피우는 프로젝트 주간이 지나갔다.
https://github.com/SKNETWORKS-FAMILY-AICAMP/SKN13-2nd-7Team.git
데이터를 분석해서 이탈 유저를 분석하라는 대주제에 우리 팀은 이탈 대상을 병원으로 잡으면 어떨까? 하는 생각에 환자를 이탈 유저로 보고 프로젝트를 시작하였다.
시작부터 난관.... 정형 데이터고 뭐고 데이터를 다루고 파악하는 과정은 정말 치가 떨렸다.....
강사님께서 언젠가 말씀하시길 머신러닝 결과가 안좋으면 데이터 전처리가 잘못된 것이고, 딥러닝 결과가 안좋으면 모델링이 잘못된 것이라 하셨나?
그렇게 귀 어딘가에 맴돌던 그 말이 이번 프로젝트를 관통하는 문장이 되었다.
데이터 전처리
머신러닝 모델의 성능을 높이기 위해서 필수적인 데이터 전처리 과정, 그리고 전처리 과정을 진행하기 위해서 필수적인 데이터 파악 !
우리가 선택한 데이터는 뉴욕 병원들을 대상으로 집계된 무려 260만 개의 데이터... 그것도 Feature Column 이 39개나 되는 만져보지도 못한 크기의 데이터 셋이었다.
각 컬럼이 어떤 값으로 구성되었는지 알아야하니 한 번 쳐보자.
data = pd.read_csv('datasets/hospital.csv')
data.columns
data['CCS Diagnosis Description'].value_counts()
>>> CCS Diagnosis Description
>>> LIVEBORN 241123
>>> MOOD DISORDERS 63068
>>> CHF 62241
>>> SEPTICEMIA 60989
>>> CHEST PAIN 60055
>>> ...
>>> HYPERLIPIDEMIA 42
>>> CATARACT 42
>>> BIRTH TRAUMA 32
>>> OSTEOPOROSIS 21
>>> FEMALE INFERTILITY 13
>>> Name: count, Length: 262, dtype: int64
len(data['CCS Diagnosis Description'].value_counts())
>>> 262정말 모든 컬럼이 이런식이었다.. 컬럼 39개 중 3개의 컬럼을 제외하고는 모두 범주로 나뉘는 범주형 컬럼이었는데 데이터가 260만 개이다 보니 그 범주가 262개... 이런다.
그 중 환자의 우편번호, 담당 의사의 면허 번호와 같은 컬럼을 제거하고나서 우리는 범주형 컬럼에 대해 새로운 'Others' 컬럼을 만들어내는 Feature Engineering 을 진행하였다.
for column in categorical_columns:
ratio = data['column'].value_counts(normalize=True)
data['column'] = data['column'].apply(lambda x: \
'Others' if ratio > threshold else x)외에도 숫자형 컬럼은 각각 mean, std, max, min 등의 값을 비교하여 본 결과 이상치가 일부 확인되어 Z-score 기반 이상치를 처리해주었다.
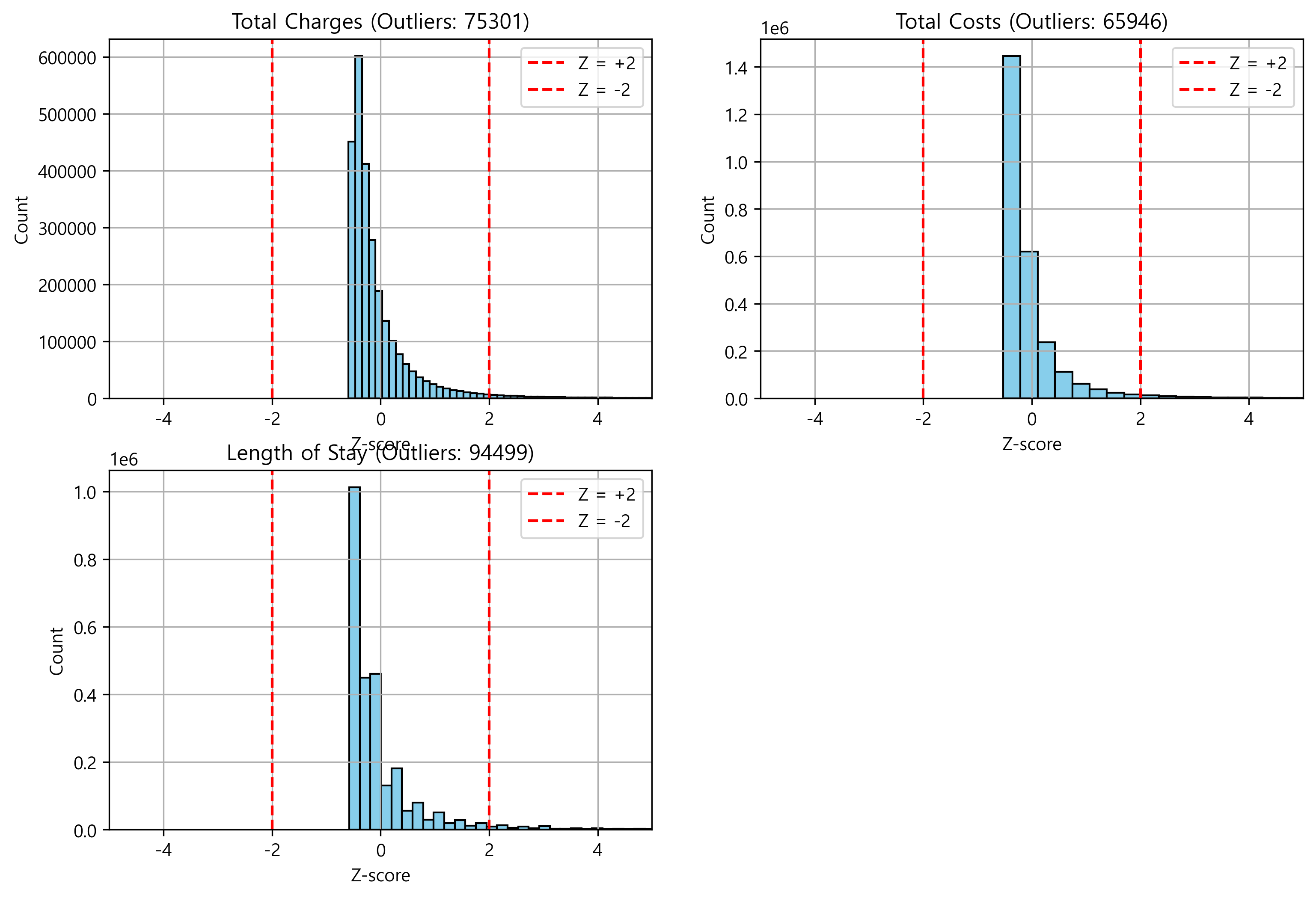
모델링
우리는 이진 분류 문제 해결을 위해 적합한 모델을 선택하기 위해 Logistic Regression 부터 여러 Tree 기반 모델, XGBoost와 RandomForest 등의 모델들로 데이터를 일부 학습 및 평가해보고 f1-score가 가장 좋은 XGBoost 모델을 사용하기로 하였다.
모델링에서 가장 어렵고 힘들었던 부분은 최종 모델의 튜닝 과정이었다.
직접 프로젝트를 진행해보기 이전, 개념으로 배울 때에는 선택한 최종 모델의 하이퍼 파라미터들에 대해 GridSearchCV 혹은 RandomizedCV 를 적용시켜 여러 조합을 시도해보기만 하면 되는거 아닌가? 싶었다.
하지만 현실은...
우리 조는 데이터의 불균형을 해소해주는 SMOTE 기법을 사용하였는데 이 SMOTE 기법에서 얼마만큼의 데이터를 만들지, 얼마나 비슷한 데이터로 만들지 등의 파라미터부터 시작해서 모델의 하이퍼 파라미터들, 그 파라미터별로 달라지는 최적의 Threshold 값... 심지어는 260만 개의 큰 데이터셋을 가졌기에 얼마만큼의 데이터셋을 사용할건지에 따라서도 모델의 성능이 크게 좌지우지 되었다.
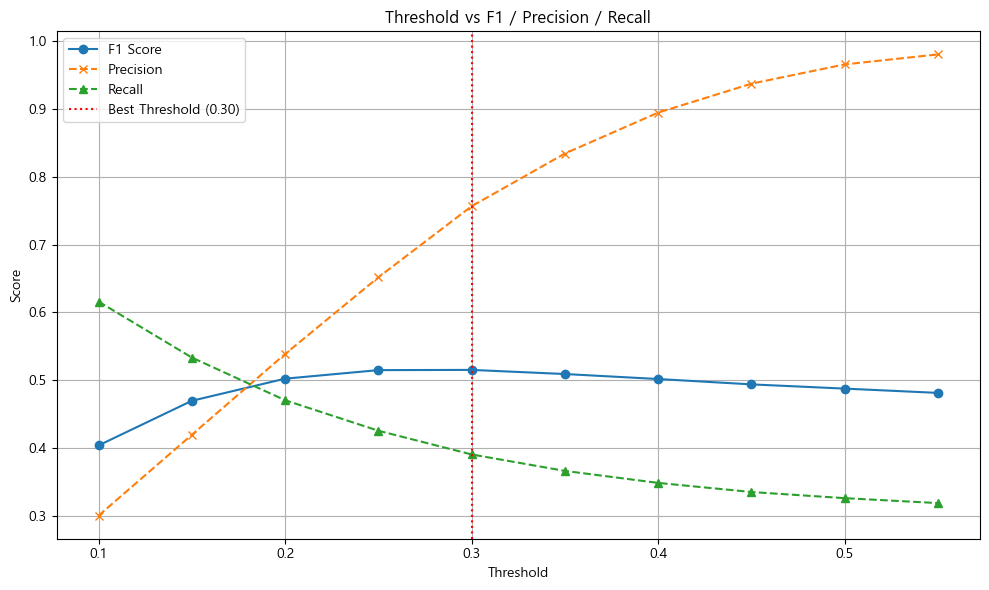
위 그림은 그 중 최적의 Threshold 를 찾는 과정인데 데이터셋의 불균형, 이진 분류 모델임에도 y=1 인 클래스가 너무 적어서 발생하는 문제점을 보여준다.
실제 프로젝트 진행 과정에서는 여러 파라미터들을 바꿔가며 각각에 대해 최적의 Threshold를 찾고, 평가 지표를 계산하였는데 데이터셋이 큰 만큼 이 과정에서 소요되는 시간이 오래 걸린다는 점이 장애물로서 크게 작용하였다.
그럼에도불구하고 결국 초기 0.4624의 f1-score 값을 0.5153 까지밖에 올리지 못했다.. 아무래도 정형 데이터를 사용하는 머신러닝의 특성상 파라미터 튜닝보다 데이터 전처리 과정을 통해 얻는 성능 개선이 훨씬 크기 때문인 것 같다.
결과 해석
그렇게 튜닝된 최종 모델을 가지고 데이터를 분석한 결과는 다음과 같다 !
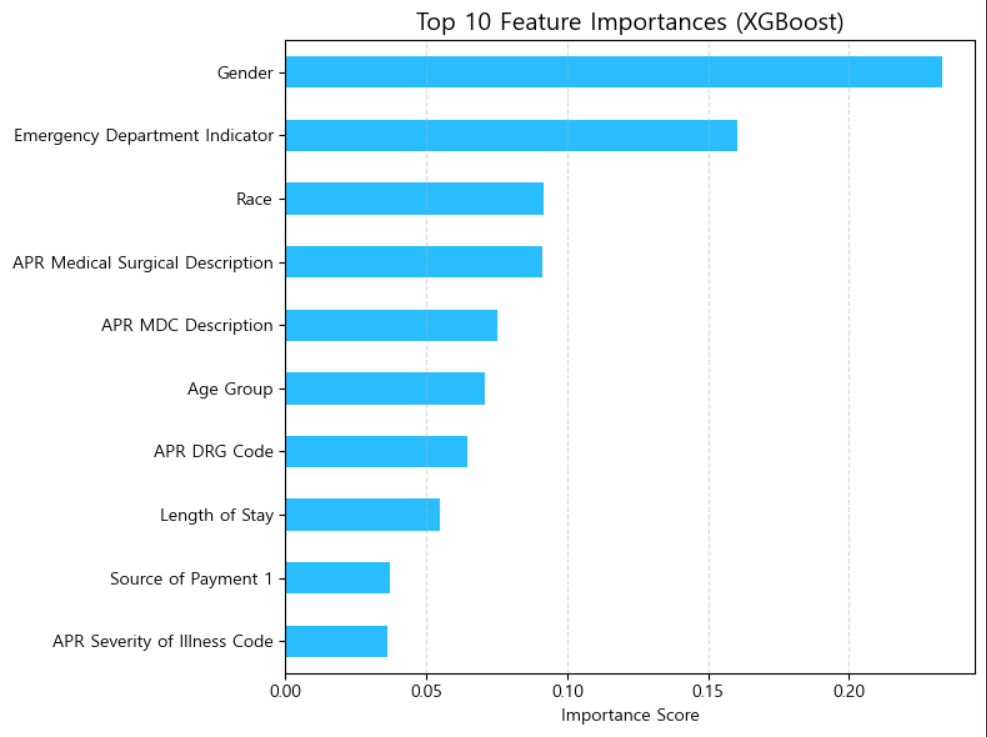
위 표는 환자의 병원 이탈 여부에 가장 크게 영향을 미치는 요인은 성별, 응급실 이용 여부, 인종, 병명 등이라는 점을 나타낸다.
그래서?
직접 데이터를 만지고 다루며, 모델을 만들어 이 데이터를 스스로 분석하고 결과를 해석하는 과정이 너무나 값지게 느껴졌다.
다만, 이는 데이터를 그저 '분석'할 뿐 없는 관계성을 만들어내는 작업이 아니기에 분석하고자 하는 관계성에 따라 그 값이 굉장히 의미없는 값이 나올 수 있다는 점은 조금 허무할 수 있겠다.
