지난 주차까지 LLM API 를 이용하여 여러 체인을 구성해 원하고자 하는 task 를 해결해보는 과정을 배웠다.
이렇게 발전된 거대 LLM 모델은 터무니없는 데이터 양을 학습하였기에 분명 막강한 성능을 지녔지만, 여러 방면에 있어 명백한 한계점을 지닌다.
1) 특정 작업 최적화
- 파운데이션 모델 인 거대 LLM 은 텍스트 생성, 번역 등의 작업에 굉장한 성능을 지니지만 그 외에 특정 형식에 맞는 문서화 작업 등 세분화된 작업에 비교적 약한 모습을 보인다.
2) 도메인 특화 지식 부족
- 기업의 내부 문서 등 실제 LLM 이 유용하게 쓰일 수 있는 환경의 문서는 비공개인 경우도 많아 추가 학습이 필요할 수 있다.
2) 의 문제를 해결하기 위해 지난 시간 외부 문서를 이용한 RAG 기법까지 알아 보았지만 이는 매 질문마다 옆에 있는 책을 뒤져보는 꼴이다. 이에 small LLM, sLLM 을 대상으로 모델을 새로이 학습시키는 파인튜닝에 대해 알아보자.
다양한 파인튜닝 방법
파인튜닝은 특정 작업에 대해 강력한 모델을 만드는 일이므로 굉장히 유용한 방법이지만 거대한 모델을 새로 튜닝하는데에 걸리는 비용이 심각하다는 문제가 발생한다.
이에 파인튜닝은 모델의 크기를 줄이거나 모델의 학습 과정을 더욱 효율적으로 하는 방법으로 발전되어 왔다.
모델의 크기 줄이기
기본적으로 딥러닝 모델들은 float32 타입의 부동소수점을 통해 데이터를 표현한다. 이는 지수부가 8 bit, 가수부가 23 bit 로 float16 타입이 각각 5 bit, 10 bit 인 것에 비해 수의 범위나 정밀도에서 강한 성능을 보인다.
그런데 수의 정밀도를 표현하는 가수부가 23 bit 나 필요한가?
23 bit 를 통해 표현되는 가수부는 대략 1.XXXXXXX 정도이지만 10 bit 를 통해 표현되는 가수부는 대략 1.XXX 정도의 표현이 가능하다.
float32 타입 과 동일한 수의 표현 범위를 가지나 그 정밀도만을 떨어트린 자료형이 bf16(brain floating point) 이다.

위 자료형으로 파라미터를 받음으로써 모델의 정밀도만을 낮추며 용량을 절반 가까이 낮출 수 있다.
이 방법까지는 여전히 파라미터의 값을 실수로 유지하지만 모든 파라미터를 정수로 치환함으로써 더 낮은 용량으로 같은 모델을 받을 수도 있다.
8-bit Absmax Quantization 기법은 각 구간별로 파라미터의 최대, 최소 범위를 개의 같은 크기 조각으로 나누어 매핑하는 방법이다.
4-bit NormalFloat Quantization 기법은 각 구간을 정규분포를 따르는 개의 같은 수를 가지는 조각으로 나누어 매핑하는 방법이다.
효율적인 모델 학습
모델의 일부만을 학습시키는 파인튜닝에도 파라미터를 효율적으로 학습하기 위한 PEFT(Parameter-Efficient Fine-Tuning) 기법이 존재한다. 그 대표적인 예시로는 입력값이 들어가는 프롬프트를 수정하여 학습시키는 1) 프롬프트 튜닝, 기존 모델에 새로운 어댑터 레이어를 추가해 학습시키는 2) 어댑터 튜닝 이 있겠다.
LoRA (Low-Rank Adaptation) 기법 은 기존 파라미터 행렬 옆에 추가적인 소형 파라미터 행렬을 붙여 추가 학습을 하는 방법이다.
기존 weights 행렬이 입, 출력에 대해 100x100 행렬을 가진다면 추가적인 소형 행렬은 100x10, 10x100 꼴로 이루어지는 것.
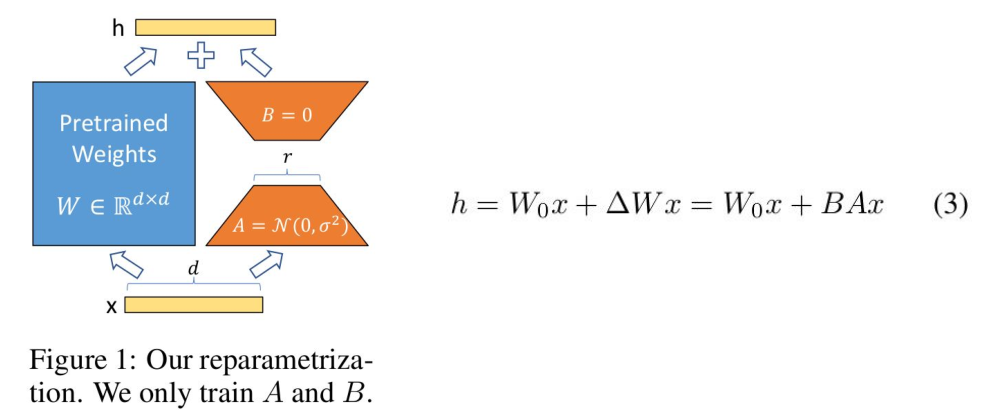
이 LoRA 방법을 통해 파인튜닝 과정을 살짝만 훔쳐보자.
LoRA를 이용한 파인튜닝
파인튜닝을 하기 전 가장 기초가 되는 작업은 base model 설정과 추가 학습시 사용할 새로운 데이터 셋이다.
base model의 경우 한국어 학습이 잘 되어있고 크기가 너무 크지 않은 파운데이션 모델로 kakao의 kabana 모델을 사용하였다.
이를 토대로 뉴스 기사를 통해 특정 기업의 주가 변화를 예측하는 모델을 만들어보자.
데이터 셋 준비
모델의 목적이 Input : 뉴스 기사 / Output : 특정 기업명+주가 변화 여부+근거 이므로 새로운 데이터 셋을 만들어주어야 한다.
from datasets import load_dataset
# 뉴스기사 데이터셋 불러오기
dataset = load_dataset("daekeun-ml/naver-news-summarization-ko", split="train")
type(dataset)
>>> <class 'datasets.arrow_dataset.Dataset'>
dataset.features
>>> ['date', 'category', 'press', 'title', 'document', 'link', 'summary']
# Input 만들기
pd_dataset = dataset.to_pandas()
input_dataset = pd_dataset['title']+'\n'+pd_dataset['document'] # 제목과 내용만 추출
input_dataset[0][:10]
>>> '추경호 중기 수출지원 총력 무역금융 40조 확대\n앵커 정부가 올해 하반기'뉴스 기사는 HuggingFace 에 존재하는 데이터를 사용하였으며 제목과 내용만을 추출하였다.
반면, Output 의 경우 새롭게 만들고자 하는 모델은 원하는 데이터셋이 존재할리 만무하므로 새로이 만들어야한다. 주가 변화 여부를 판단해야하는 주제 특성상 LLM 을 이용하여 Output을 만들어보자.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from textwrap import dedent
model = ChatOpenAI(model='gpt-4o-mini')
prompt_template = PromptTemplate.from_template(
template=dedent("""### Instruction:
당신은 주가분석전문가입니다.
주어진 뉴스를 읽고 주가 변화 기업과 변화 여부, 그 근거를 출력하세요.
### Context:{context}
### Output Indicator:{indicator}""").....나머지는 나중에 알아보자.... 잠깐 스킵 ㅎ
