1. 개요
- 명령어 처리 과정을 여러 단계로 세분화해서 동시에 서로 다른 작업들이 수행되도록하여 병렬성을 높이는 기법
- CPU 처리 속도를 높이기 위해 CPU 내부 하드웨어를 여러 단계로 나누어 동시에 처리하는 기술
2. 수행 과정
- Fetch Instruction
- Decode Instruction
- Execute Instrcution
- Write Back
3. 유형
- pipeline
- super pipeline
- super scalar
- super pipelined super scalar (결합)- VLIW(제 2세대 RISC)
3.1 단일 파이프라인
3.1.1 원리
- 효과적인 병렬처리를 위해 몇 가지 동작을 명령어 수행과정에서 각 단계를 한번만 중첩하는 기술
- 앞 단계가 끝났는지 일일이 확인하는게 아니라, 애초에 설계 시 계산되어있는 가장 오래 걸리는 단계에 맞춰서 일괄적으로 진행
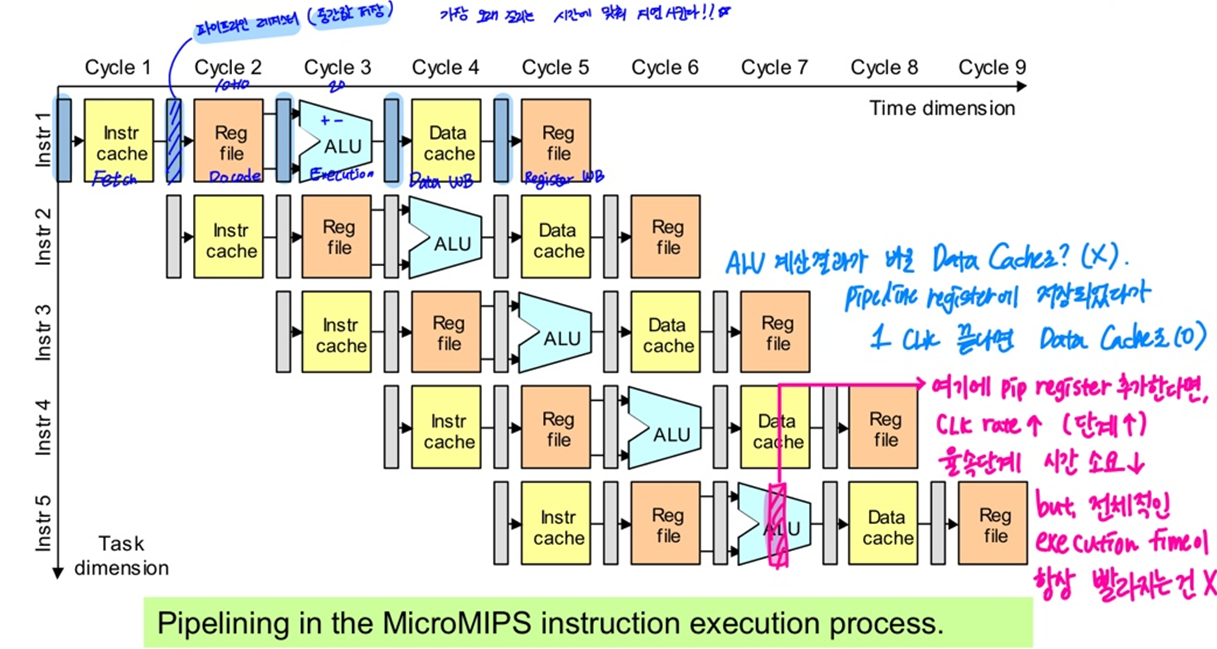
3.1.2 문제점
- 근본적 문제점 (필연적으로 감수해야하는 문제)
- 모든 명령어가 파이프라인을 거칠 필요는 없지만 단순화하기 위해 다 거쳐야한댯
- 어떤 명령어는 operand 인출할 필요 없는데도 불구하고 4단계 파이프라인 모두 통과
- 클럭 스피드는 가장 긴 파이프라인 단계를 기준으로 설정됨
- 구조적 문제점 structure hazard = resource conflict
- FI 단계와 EI 단계가 동시에 기억 장치를 사용할 경우 기억 장치 충돌에 따른 지연 시간
- 특정 resource를 여러 단계에서 동시에 사용하려고 하면 resource conflict
- 메모리 access는 한 순간에 하나의 레지스터만 할 수 있기 때문.(BUS의 조건: 메모리 접근시 bus master는 단 하나의 레지스터만 될 수 있다.) 그러나 명령어를 병렬처리하는중에 동시에 두 개의 segment에서 메모리에 access라고 한다면 resource conflict가 발생.
- (modified) harvard architecture 로 해결됨
- 데이터 문제점 data hazard = data dependence conflict
- 이전 명령어의 실행 결과를 다음 명령어가 사용할 때 생기는 데이터 의존성에 따른 문제
- data가 마련되지도 않았는데 미리 사용되는 문제
- 예를 들면 일렬의 명령어가 순차적으로 동일한 레지스터 R2를 쓰고, 읽는다고 가정해보자. 각각 execute, decode 단계에 있는 경우 decode 단계의 명령어는 앞선 명령어가 레지스터에 연산의 결과를 저장하지 않은 상태로 decode에서 그 값을 읽어버린다. execute 단계에 있는 '쓰기' 명령어가 writeBack 단계에 가서야 레스터에 값을 저장하기 때문이다.
- 제어 문제점 control hazard = branch instruction 문제
- 분기(특히 조건분기)의 경우, 미리 인출한 명령어를 사용할 수 없는 문제
- 갑자기 어떤 명령어로 branch하게되면 PC가 변하면서 이전까지 파이프라인에 뒤따라오던 명령어들을 다 무산시키고 branch한 명령어를 수행해야 함.
- branch를 수행하면 일단 현재 주소를 저장해두고 브랜치대상 PC로 가서 명령 처리 후 원래 주소로 돌아온다. 그럼 원래 많은 명령이 진행되던 파이프라인은 pipeline stage만큼 stall이 발생하여 당연히 성능 문제 발생
- 이때 pipeline flushing 할 경우, 그 사이에 생성된 것들이 전부 무의미해짐.
3.1.3 structure / data hazard 해결방안
1) resource conflict 해결: Instructin & data Cache 분리
- 기존에는 1개였던 메모리를 Instruction Cache / data Cache 로 분리
- 하나의 segment는 insturction cache에 access하게 하고, 다른 segment는 data cache로 access하게 하면 resource confilt를 생기지 않게 할 수 있다. (리소스가 분리되어있다)
- memory와 관련된 structure hazard conflict 해결, data hazard 해결
2) Stall
- 의존이 없어지거나 분기 여부가 결정될 때까지 delay 시키는 것
- 처리되어야하는 명령어의 처리 사이클은 동일
- STALL을 함으로써 앞 명령어가 WB단계를 거쳐서 레지스터에 값을 저장할 때까지 충분히 기다려준 이후에, 실행하려는 명령어의 Read가 순차적으로 실행되도록.
- 매번 RAW Hazard가 발생될 때마다 STALL -> CPU의 성능이 저하
- 앞 단계의 유효하지 않은 명령어의 controlSignal에 valid 비트를 추가하여 invalid의 경우 Memory Access와 WriteBack 단계를 무시
3) Data forwarding
- 계산결과를 바로 쓸 경우 data hazard 발생. 따라서 데이터 의존성을 해결하자는 의도.
- HW 측면의 data hazard 해결책
- 앞으로 n클럭 후에 register(ALU)에 써질 값을 미리 보내준다.
- write Back에 저장될 값이 결정되는 시점의 값을 앞당겨서 ALU에서 처리를 마친 결과값 또는 memoryAccess단계에서 메모리를 읽은 값을 직접 다음 명령어 ALU에 들어갈 input으로 대입하는 방식
- WB(Write Back)하려고 들어오는 값을 그대로 받아서 ID단계에서 사용하도록 Forwarding 함으로써 Hazard를 해결.
- LW 이후에 바로 레지스터가 겹칠 경우 4단계에서 결정되는 레지스터 값은 같은 사이클에서, 즉 바로 다음 이어지는 명령어의 ALU 인풋으로 할 수 없기 때문에 하나의 stall은 필연적.
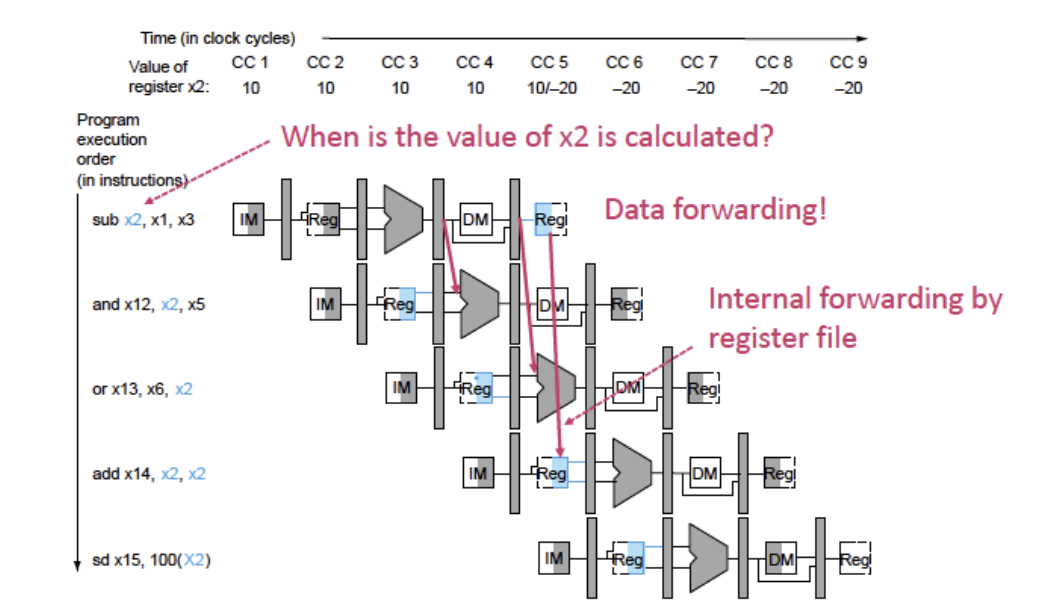
4) Insert BUBBLE : data가 update될 때까지 1클럭 쉰다.
- 속도가 느려진다는 단점
- delayed load 삽입 방식 (Freezing the pipeline) (stall)
- 하드웨어적으로 no-operation(nop) instruction이라는 더미 명령을 통해 한 클락을 진전시켜 data dependency를 해소한다.
5) REORDER
- compiler 가 instruction reordering 수행
- SW 측면의 해결책
- 예를 들면, 다음과 같은 기존 연산 순서가 있었다면
a=b+c => 1
d=a+3 => 2
b=c+5 => 3- 2 과 3의 연산 순서를 교환하여 a가 준비될 시간을 버는 맥락(?)
6) delayed Branch :
- 프로그램 내 명령어들을 재배치함으로써 파이프라인의 성능 개선
a=b+c -1)
d=a+c -2)
b=c+5 -3)
if(a==b){jump} -4)-
1234 -> 1243
-
컴파일러가 branch명령을 적절한 위치에 재위치시켜서, conditional branch의 조건을 판단할 때 다른 하나 이상의 명령어를 진전시킬 수 있게 한다.
-
branch의 조건을 따지는 동안 stall되는 문제를 방지
-
conditional branch에 대한 영향을 최소화할 수 있다.
-
컴파일러의 최적화 능력에 따름
-
(만약 branch 조건문이 참으로 나와서 점프해야 한다면, 점프한 곳에 있는 명령어를 실행해야 하므로 원래 실행해야 했을 명령어를 nop으로 쭉 밀어버린다.)
3.1.4 Control(Branch) Hazard 해결 방안
Branch Prediciton 분기 예측
- 분기 결과를 execution stage의 실제 계산을 통한 값이 아닌, 예측 전략에 의한 결과로 생각하고 다음 pc 값을 결정.
- 계산한 분기결과와 예상한 결과가 일치하면 1-2개 cycle에서 이득을 볼 수 있음
- 일치하지 않더라도 예측에 의해 미리 fetch된 1-2cycle 명령어가 무의미해지는 것은 같으나, 예측의 실패를 분기 예측 전략에 반영하여 다음번 분기 예측의 가능성을 높임.
1) Branch를 예측하기 위해 알아야할 정보
- 지금 fetch 한 명령어가 branch냐 아니냐. decode 단계에서 해당 명령어가 분기 명령어인지 아닌지를 확인
- branch direction (cocondition 만족 여부)
- condition을 만족했다면, 다음 목적지는 어디?
2) Static Branch Prediction
-
Always taken: 항상 분기가 일어난다고 예측
-
Always not taken: 항상 분기가 일어나지 않는다고 예측
-
Backward taken, Forward not taken: 분기의 방향이 후방인 경우에는 분기가 일어남, 전방인 경우에는 분기가 일어나지 않는다고 예측
3) Dynamic Branch Prediction
: 분기를 예측하는 전략에 대한 예측&검증이 진행되면서 이전 예측 성공 여부가 다음 예측에 반영되는 방식. bit counter를 이용하여 이전 결과가 다음번 예측에 반영될 수 있도록 함
- single bit counter prediction
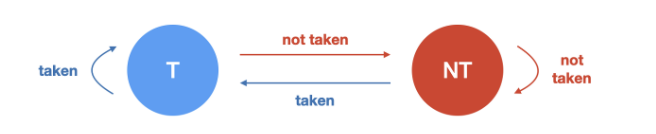
-
saturation two bit counter prediction
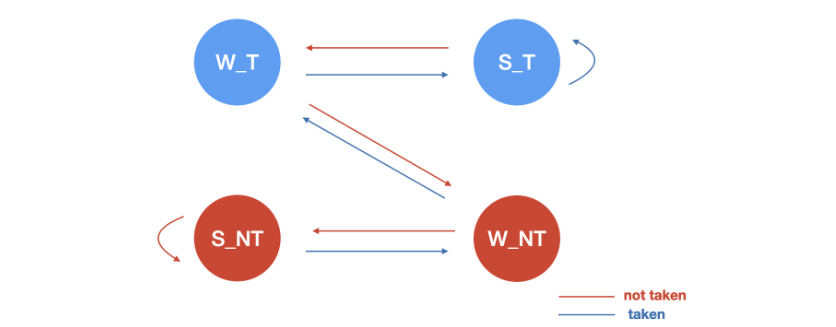
-
Hysteresis two bit counter prediciton
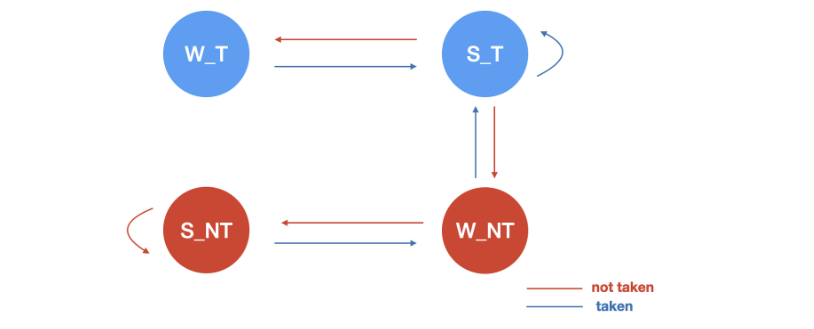
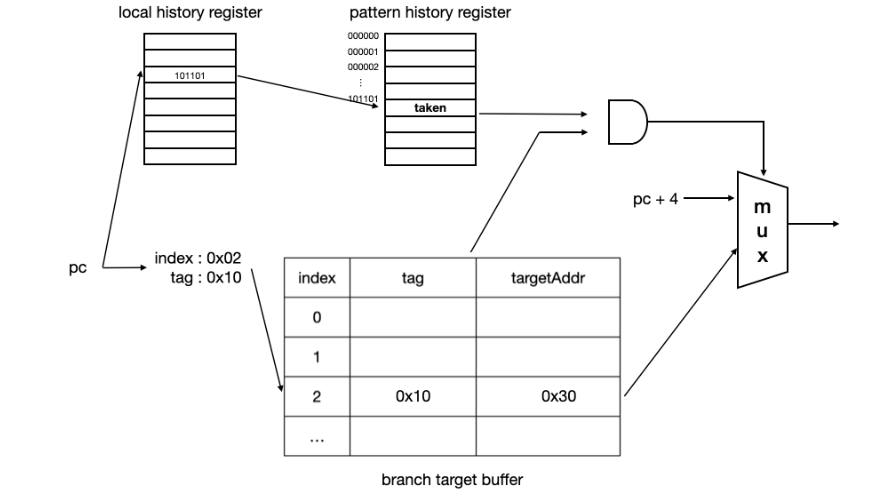
4) Branch target buffer
-
PC만을 이용하여 분기예측을 하기위해 사용하는 버퍼.
-
명령어가 분기명령어인지 확인한 후, 분기하고자하는 다음 pc값을 다음 fetch의 pc로 사용. 명령어가 분기명령어가 맞으면 분기 예측 실행. taken으로 예측된다면 해석한 next PC를 다음 fetch의 pc로 사용. 1개 cycle 이득
-
decode 단계가 아닌 fetch 단계에서 바로 분기 예측 실행 후 다음 사이클의 fetch에 그 결과를 사용할 수 있음. taken으로 예측되고 예측이 맞을경우, execution단계에서 결과를 예측하는 것보다 2개 cycle 이득
-
분기 명령어의 pc값과 target PC 값을 저장하고 다음 번에 같은 PC가 수행될 때 그 값을 참고하여 분기 예측 가능
-
모든 pc값을 다 담을수 없기 때문에 pc 주소 일정 부분을 index, 나머지를 tag로. 이후 다른 pc가 들어왔을 때 index에 해당하는 tag 데이터를 비교하여 해당 인덱스에 같은 명령어 정보가 존재하는지 확인하는 식으로 hit/miss 결정
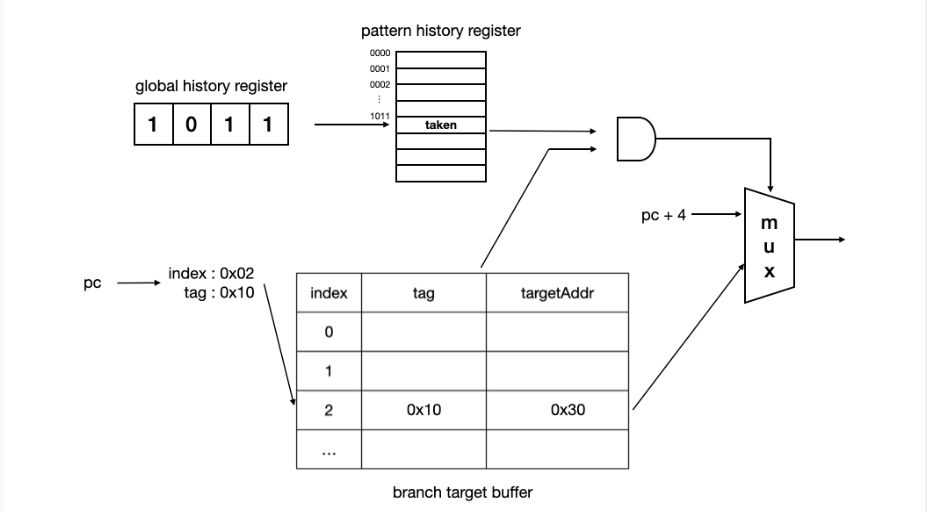
5) Two-level global history branch predictor
- 특정 명령어의 기록이 아닌 최근에 실행된 분기 명령어의 전역적인 행동의 기록을 global branch history라고 함.
- 어떤 분기 패턴에서 기존에 어떤 분기 예측 결과가 있었는지 저장하기 위해 pattern(global) history register 필요
- global history register의 n개 비트를 인덱스로 하는, 즉 2^n개의 라인 수를 갖고 있는 분기 예측 결과 표가 필요
- two bit counter prediction은 pattern history register의 각 라인이 2bit씩 할당되어, strongly taken/weakly taken/weakly not taken / strongly not taken을 저장
- 즉, global history register와 branch target buffer를 결합하여 최근 4개 분기 결과에 따른 분기 예측, Nexp pc를 얻는 구조.
6) Two-level local history branch predictor
- Global history와 반대로 특정 명령어에 따른 행동을 기록하고 이 패턴을 통해 분기 예측
- Global history branch predictor은 프로그램 전체의 분기 패턴을 기록한다면, local history branch predictor은 반대로 명령어마다 이전 분기 패턴을 기록하여 예측에 활용하는 방식
3.2 슈퍼 파이프라인
- 하나의 pipeline을 여러 부분으로 나누어 연속적인 흐름 과정으로 처리
- 단계를 세분화하여 clock cycle time을 줄임
- 무조건 하나의 클럭 X, 반 클럭으로도 파이프라인 가능하도록
- clock 수가 높아지면(cycle time이 짧아지면) 단계를 나누기 어려움
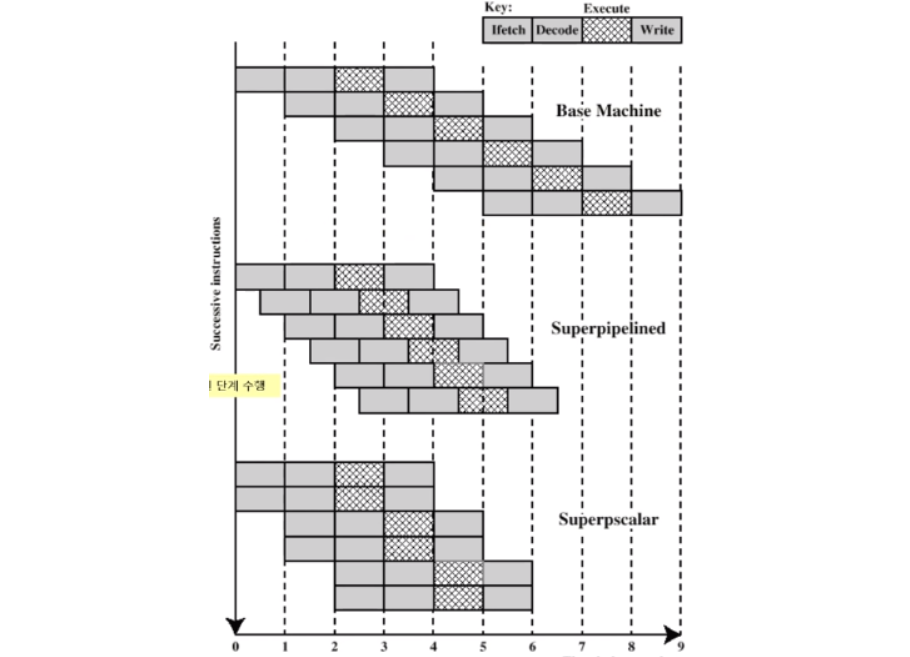
3.3 슈퍼 스칼라
- 프로세서 내에 pipeline된 ALU를 여러 개 포함시켜서 매 사이클마다 복수의 명령어들이 동시에 실행될 수 있도록하는 병렬 처리
- CPU 내에 파이프라인을 여러개 두어 여러 명령어를 동시에 처리
3.3.1 슈퍼 스칼라의 한계
1) true data dependency

ADD r1, r2 (r1=r1+r2)
MOVE r3,r1 (r3=r1)- ADD의 r1과 MOVE의 r1은 서로 의존적.
- pipeline에서 타이밍을 맞추지 못하면 MOVE에서 잘못된 r1값(add되기 전의 r1)을 받아서 틀린 연산 결과 나올수도
2) Procedural Dependency
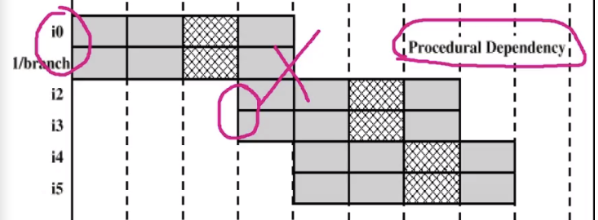
if(~) ...
else(~) ...- branch가 존재할 경우 branch 이전/이후는 상황이 다를텐데
- branch 이전과 이후를 병렬로 진행하는 것은 의미 없음
3) Resource Conflict
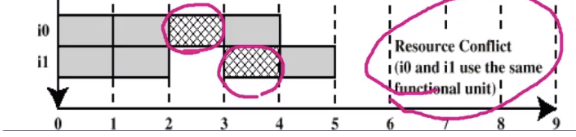
- execution resource가 하나밖에 없으므로 서로 경쟁을 해서 가져감
- 한 instruction 때문에 다른 instruction이 영향을 받아.
- i0과 i1을 병렬처리한다고하면, i1이 i0이 끝날때까지 기다려주어야해.
4) Antidependency ( True dependency와 반대 )
- Write-after-read dependency. 쓰기 전에 읽어라
R3=R3+R5 (I1)
R4=R3+1 (I2) : 읽기
R3=R5+1 (I3) : 쓰기
R7=R3+R4 (I4)5) output dependency
3.3.2 - (2) 에서 설명
3.3.2 슈퍼 스칼라 해결 방안
Instruction Issue Policy: 명령어를 실행시키기위해 준비하는 과정
- 실행 할 수 있는 엔진이 여러 개인데 활용을 안할 이유가 업자나
- 고려할 요소들
- 명령어를 어떤 순서로 가지고 올거야?
- 가지고온 명령어. 어떤 순서로 실행할거야? ******
- 명령에 의하 레지스터 메모리에 변화는 없는지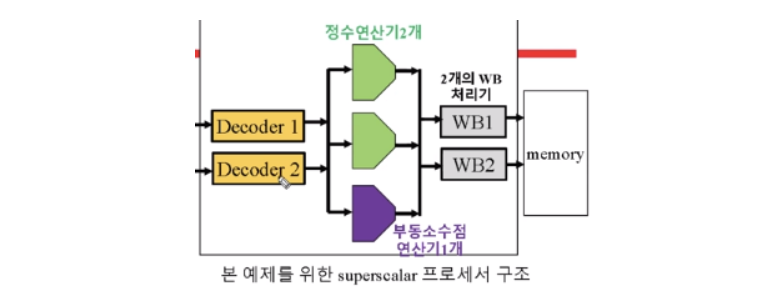
- 가정
- 두개의 명령어를 동시에 fetch하여 decoding할 수 있음
- 실행 unit은 두 개의 정수 연산과 한 개의 부동 소수점 연산 동시 수행
- 두 개의 WB 파이프라인 단계 가짐. 즉 두 개의 결과값을 동시에 WB할 수 있음- 제한
- I1을 실행하는데 2 cycle 필요
- I3/I4, I5/I6 모두 각각 resource conflict. 동일한 functional unit 사용.
- I5는 I4의 결과값을 사용함.
- I1과 I2는 data dependency를 가지지않음1) In-order issue and in-order completion
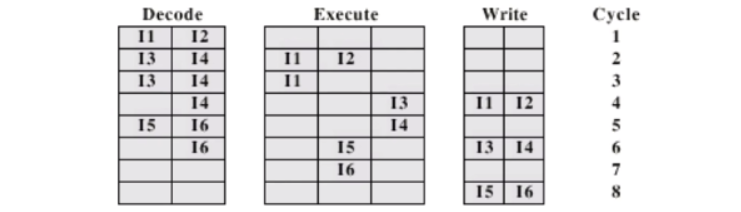
- 어떤 프로그램이 있으면 원래 순서를 유지하되, 바인딩, CPU에서는 받은 순서대로 실행을 시켜서 끝을 내겠다.
- 그렇~게 복잡하지도 않고, 그렇~게 효율적이지도 않고..
- decode를 해보면 어떤 명령어와 명령어가 dependency가 생기고 control hazard가 생기는지 알 수 있다. 그것을 scheduling 해서 execute 수행. WB도 마찬가지로.
- fetch 한 순서대로 실행
- I1과 I2는 동시에 실행시킴, I3는 2clock, I4는 3 clock 소요됨. 해당 순서대로 이슈잉.
2) In-order issue and out-of-order completion
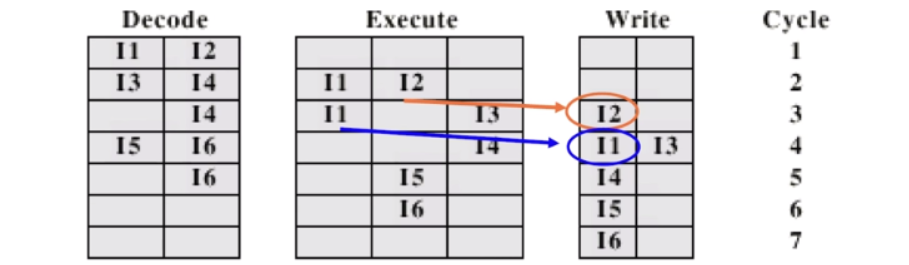
-
I1과 I2가 같이 WB 되는 1)과는 달리, Data dependency가 없다는 사실을 고려하여 I1,I2를 동시에 issuing하긴하지만 I2 결과를 cycle3에서 먼저 WB. I1보다 이전에 실행종료함. I2가 먼저 끝나기 때문에.
-
이는 결과적으로 I3 실행을 더 빨리할 수 있도록 하여, I3의 결과를 I1의 결과와 함께 cycle4에 WB할수 있게됨
-
true dependency : 어떤 결과물이 있을 때까지 그걸 읽으면 안됨
-
I1과 I2가 동시에 수행돼도 data dependency가 없기 때문에 동시에 실행해도 상관X
-
원래 순서대로 받고 순서를 바꿔서 효율적으로 실행시킴

- output dependency 때문에 out-of-order completion을 수행하면 안되는 예시.
- 즉, 결과가 바뀌기 때문에 코드의 실행 순서를 바꾸면 안되는 예시.
3) Out-of-order issue and out-of-order completion
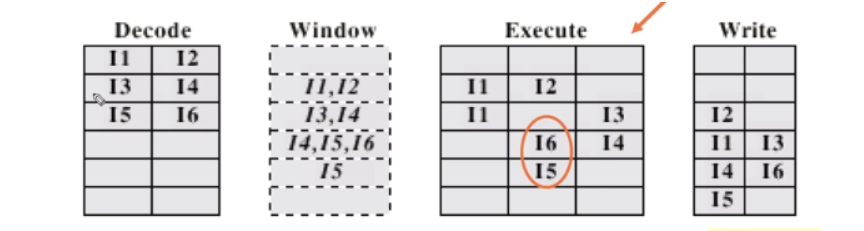
- 처음에 issuing 할 때부터 순서 바꾸고 실행도 순서 바꿔서.
- (decode와 execute 사이) window 에서 스케줄링하고, 그 결과에 따라 write back
- 1),2)에서는 decode가 되면 그 순서대로 fetch 했었는데, 이제는 window를 도입해서 순서를 바꾼 후 execute한다.
- I5는 I4에 의존하지만, I6는 I4에 의존하지않음. 따라서 I6이 I5보다 먼저 issuing이 되어 실행될 수 있음. 그럼 I5와 I6의 순서를 바꿔서 수행하쟙. Execute 및 write 단계에서 1 cycle save 가능
- organization for out-of-order issue: 내가 fetch했던 명령어를 buffer에 담아서 depending 계산, 이후 스케줄링 다시해.
- fetch한 순서에서 reordering
+) Register Renaming
- 필요할 때 레지스터를 추가하라.
- R3 register가 여러 개 있다면, 이를 필요할 때 사용하라.
rename 전
R3=R3+R5 (I1)
R4=R3+1 (I2)
R3=R5+1 (I3)
R7=R3+R4 (I4)- 순서대로 실행시켜야 오류가 없기 때문에 super scalar 방식 적용할 수 X
rename 후
R3b=R3a+R5a (I1)
R4b=R3b+1 (I2)
R3c=R5a+1 (I3)
R7b=R3c+R4b (I4)- 실제로는 R3 3개
- Antidependency 와 output dependency 해결
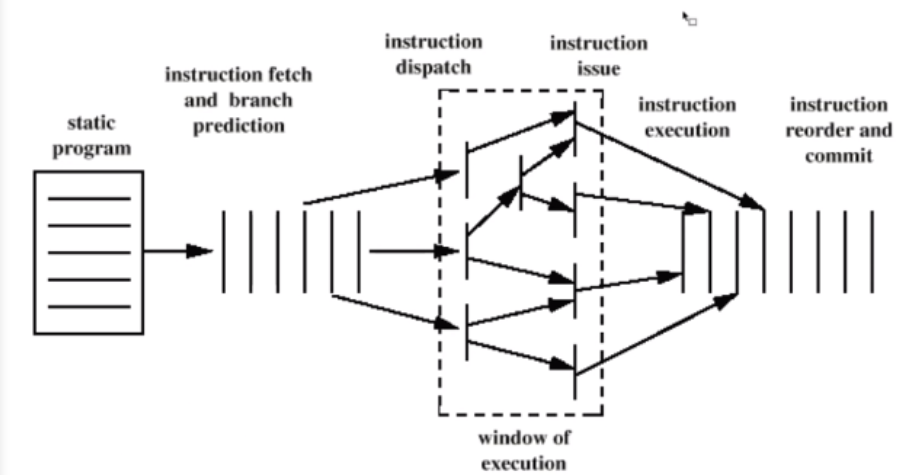
3.4 슈퍼 파이프라인 슈퍼 스칼라
(=modified harvard architecture)
3.5 VLIW (Very Long Instruction Word)
- 실행 cycle이 여러 개의 기능 unit으로 나누어져 동시에 수행됨
- 동시에 수행될 수 있는 명령어들을 컴파일러 수준에서 추출하여 하나의 명령어로 압축
- EPIC: 컴파일러가 소스 코드로부터 명시적 병렬성을 찾아 병렬처리가 가능하도록 기ㅖ어 코드 생성. 병렬 수행됨
- 정적 다중처리, 인출/해독은 하나의 회로에서 처리됨. 실행만 여러 ALU에서 수행

시험 삐숑빠숑 구르미 누나 화이팅입니당 🫰