1. 개요
1.1 정의
-
일반적으로 CPU가 주기억장치보다 더 속도가 빠르기 때문에 속도 차이로 인한 CPU 대기 시간이 생긴다.(=병목현상) 이 CPU 대기 시간을 최소화하기 위해 CPU와 주기억장치 사이에 설치하는 고속 반도체를 Cache Memory 라고 한다.
-
주기억장치에서 자주 사용하는 프로그램과 데이터를 저장하여 속도를 빠르게 하는 메모리
-
주기억장치에 접근하는 횟수를 줄여서 컴퓨터 처리속도를 향상시키는 메모리
1.2 특징
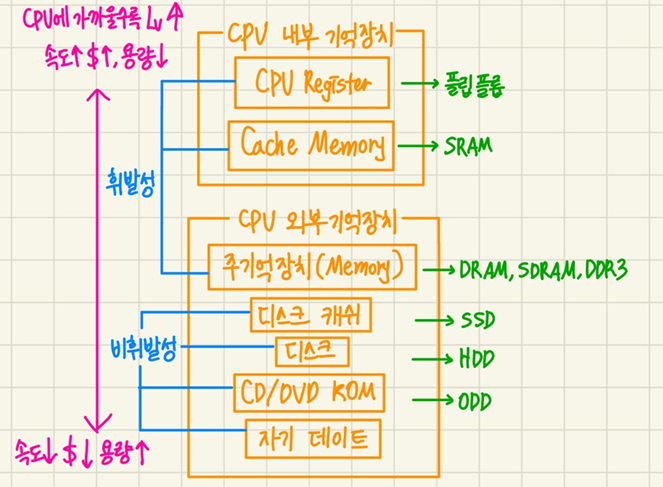
1) 메모리 계층 구조에서 가장 빠른 소자. (CPU 속도에 근접할 정도)주기억장치보다 액세스 속도가 높은 고속 반도체 칩 사용.
2) 가격 및 제한된 공간 때문에 용량이 적음. 일반적으로 수십 Kbyte - 수백 Kbyte
3) Locality 활용: 시간적/공간적 지역성의 원리에 의한 블록 단위 메모리 참조
4) 캐시 일관성: 멀티 프로세서 멀티 캐시 컴퓨터에서 캐시 일관성 유지 문제가 중요
- 사상(Mapping 방식): 캐시 & 주기억장치 사이에서 정보를 옮기는 과정
- 직접 매핑 (Direct Mapping)
- 연관 매핑 (Associate MApping)
- 집합 연관 매핑 (Set Associate Mapping)- 인출 방식
- 교체 알고리즘
- 쓰기 정책
- 다중 캐시
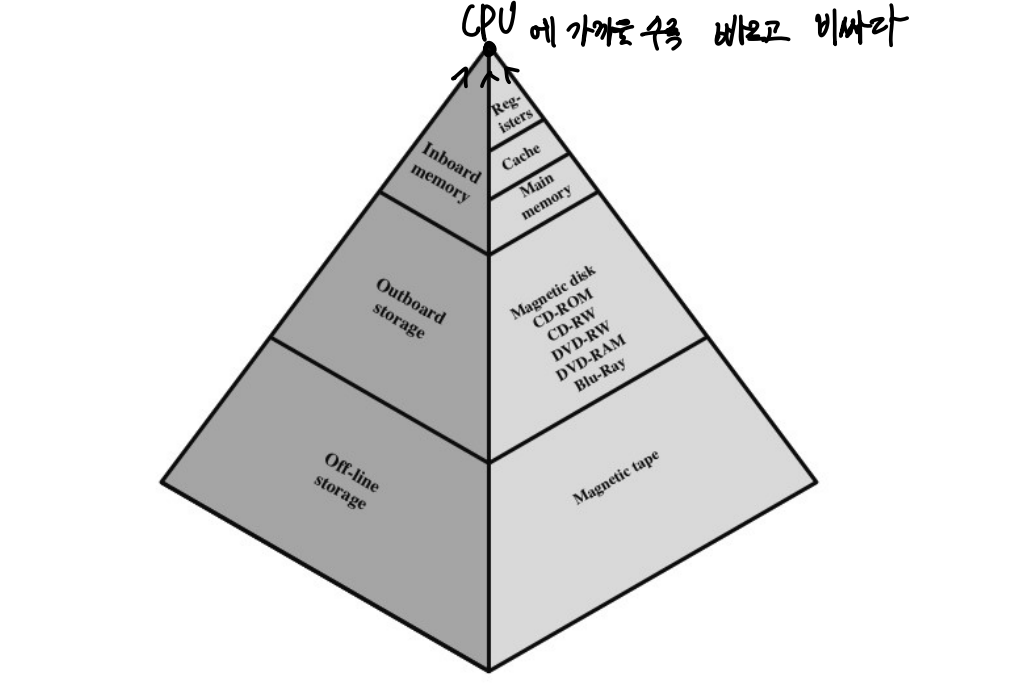
1.3 메모리 계층 구조
1.4 메모리 계층 구조 극대화를 위한 Locality

지역성
- 메모리 계층 구조 특성 상 하위 메모리에서 데이터 전송 횟수가 많으면 많을 수록 성능 저하
- 따라서 하위 메모리에서 데이터를 가져오는 횟수를 최소한으로 하게 하는 원리
- 프로그램이 기억 장치 내 정보를 균일하게 접근X, 한 순간에 특정 영역을 집중적으로 참조하는 특성
1.4.1 시간적 지연성 temporal locality
- 최근에 액세스된 프로그램이나 데이터가 가까운 미래에 또 한번 다시 액세스될 가능성이 높음
- 메모리 상의 같은 주소에 여러 차례 읽기 쓰기를 수행할 경우, 상대적으로 작은 크기의 캐시를 사용도 효율적
1.4.2 공간적 지연성 spatial locality
- 기억 장치 내 인접하여 저장되어 있는 데이터들이 연속적으로 액세스 될 가능성 높음
- 특정 데이터와 가까운 주소가 순서대로 접근되었을 경우
- CPU 캐시나 디스크 캐시의 경우 한 메모리 주소에 접근할 때 그 주소 뿐만 아니라 해당 블록을 전부 캐시에 가져오게 됨
- 메모리 주소를 오름차순/내림차순으로 접근한다면, 캐시에 이미 저장된 같은 블록의 데이터를 접근하게되므로 캐시의 효율성이 크게 향상됨
1.4.3 순차적 지연성 sequential locality
- 분기가 발생하지 않는 한, 명령어들은 기억 장치에 저장된 순서대로 인출되어 실행됨
- 분기 확률 약 20%
1.5 Memory Design Issue
1.5.1 placement(mapping)
CPU 로부터 가져온 내용을 memory의 어느 위치에 둘 것인가
1.5.2 identification
CPU가 원하는 것이 메모리에 있는지 없는지 여부를 어떻게 판단할 것인가
hit/miss 를 어떻게 판단할 것인가
1.5.3 Write Strategy
Cache와 Memory의 inconsistent가 발생하기 때문에 고려해야하는 문제
1.5.4 Replacement Policy
새로운 내용을 가져오기 위해서 기존의 것 중 어떤 것을 뺄것인가
2. PROCESS / DESIGN ISSUE 해결
2.1 Mapping
사상(Mapping): 캐시 & 주기억장치 사이에서 정보를 옮기는 과정
- 블록: 주기억장치로부터 동시에 인출되는 데이터 그룹
- 라인: 캐시 메모리에서 각 블록이 저장되는 장소
- 태그: 라인에 적재된 블록을 구분해 주는 정보
2.1.1 direct mapping
- 주기억장치 블록들이 정해진 캐시 라인으로만 적재되는 방식
- 특정 주소에 해당하는 캐시에 놓고, 몇번 블록에서 가져왔는지 명시
- (+): HW 구조 간단, 비용 저렴
- (-): 라인 공유 중인 블록 적재될 때 swap-out 발생
- (-): 특정 line 특정 num data 반복 사용될 경우 성능 저하
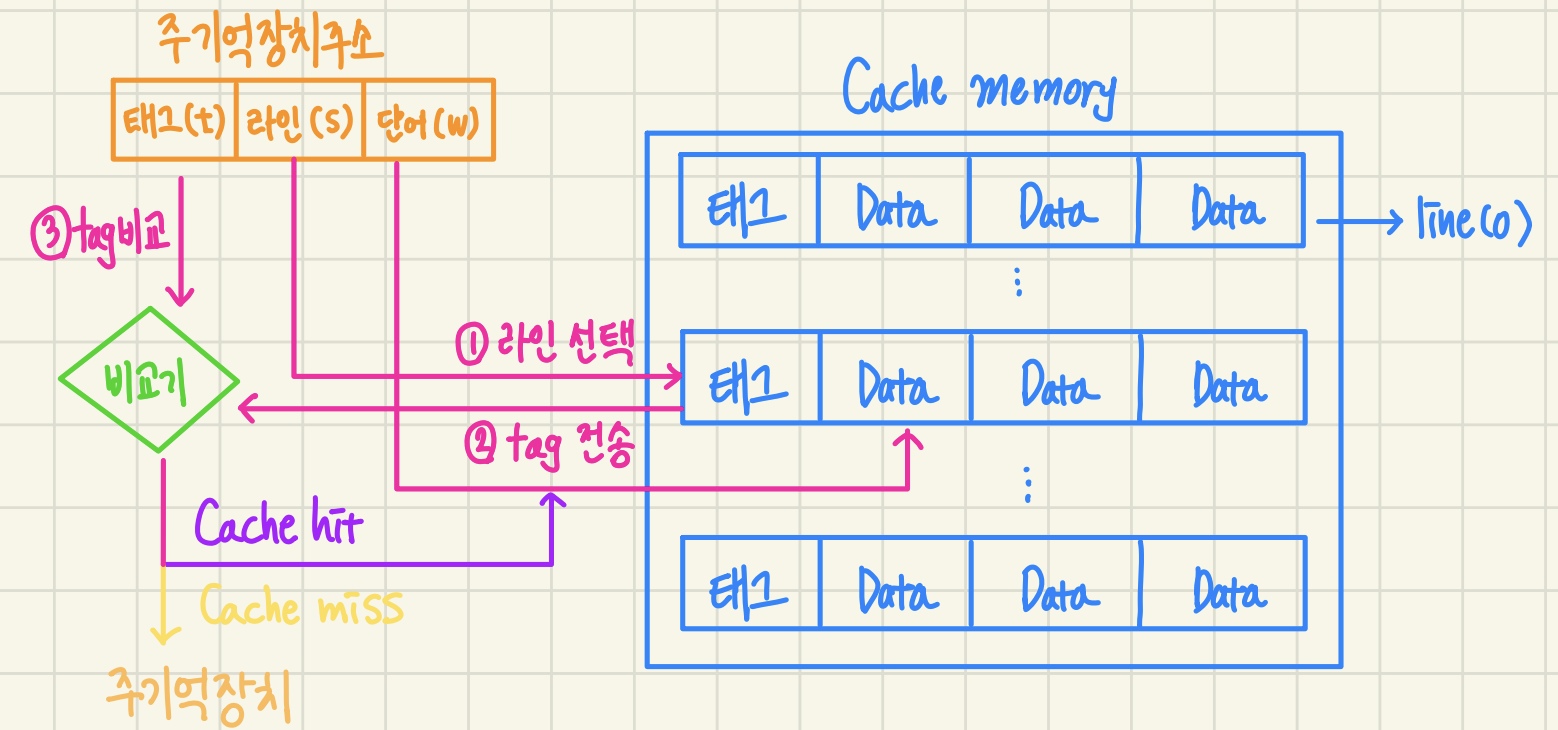
1) 캐시로 기억장치 주소가 보내지면, 그 중 라인 번호를 이용하여 캐시의 라인을 선택
2) 선택된 라인의 태그 비트들을 읽어서 기억 장치 주소의 태그 비트들과 비교.
- 두 태그 값이 일치하면(캐시 hit) 주소를 이용하여 라인 내의 단어들 중 하나를 인출하여 cpu로.
- 두 태그 값이 일치하지 않으면 캐시 miss
3) 주소를 주기억장치로 보내어 한 블록을 액세스
4) 인출된 블록을 지정된 캐시 라인에 적재하고 주소의 태그 비트들을 라인의 태그 필드에 기록
5) 만약 그 라인에 다른 블록이 이미 적재되어 있다면, 그 내용은 지워지고 새로이 인출된 블록을 적재

2.1.2 associative mapping
- 주기억장치의 블록이 적재될 캐시 라인이 정해지지 않음
- 주기억장치의 모든 블록들이 캐시의 어느 슬롯(블록)에도 저장됨
- (+): 신규 블록 적재될 때 캐시라인 선택 자유로움, 적중률 향상(swap-out 개선)
- (-): 캐시 라인 모든 태그들을 병렬로 검사하기 때문에 HW 복잡하고 구현비용 높음.
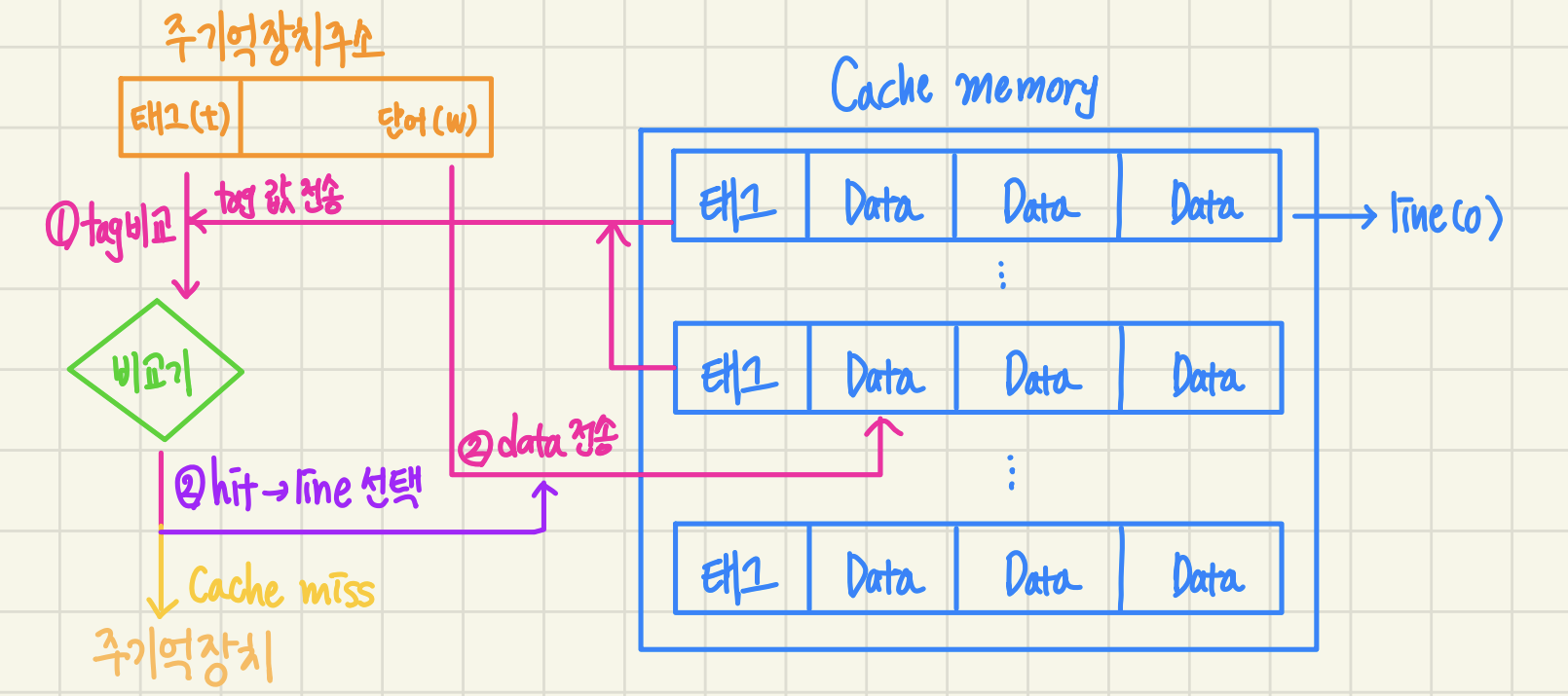
1) 주기억장치 블록은 캐시의 어느 블록이든 적재가능 태그 필드 내용을 비교하여 일치하는 것이 있으면 캐시 hit. cpu로 데이터를 전송
2) 태그 값이 일치하지 않으면 캐시 miss. 주기억장치로부터 데이터 인출.
3) 주기억장치로부터 인출된 데이터 블록을 캐시의 어느 라인에 적재할 것인지를 결정해야함. 캐시에 빈 라인들이 있따면 라인 번호에 따라 차례대로 적재하면되지만, 비어있는 라인이 없을 때는 적절한 교체 알고리즘을 이용해서 라인들 중 하나를 선택한 다음에 새로운 블록을 적재

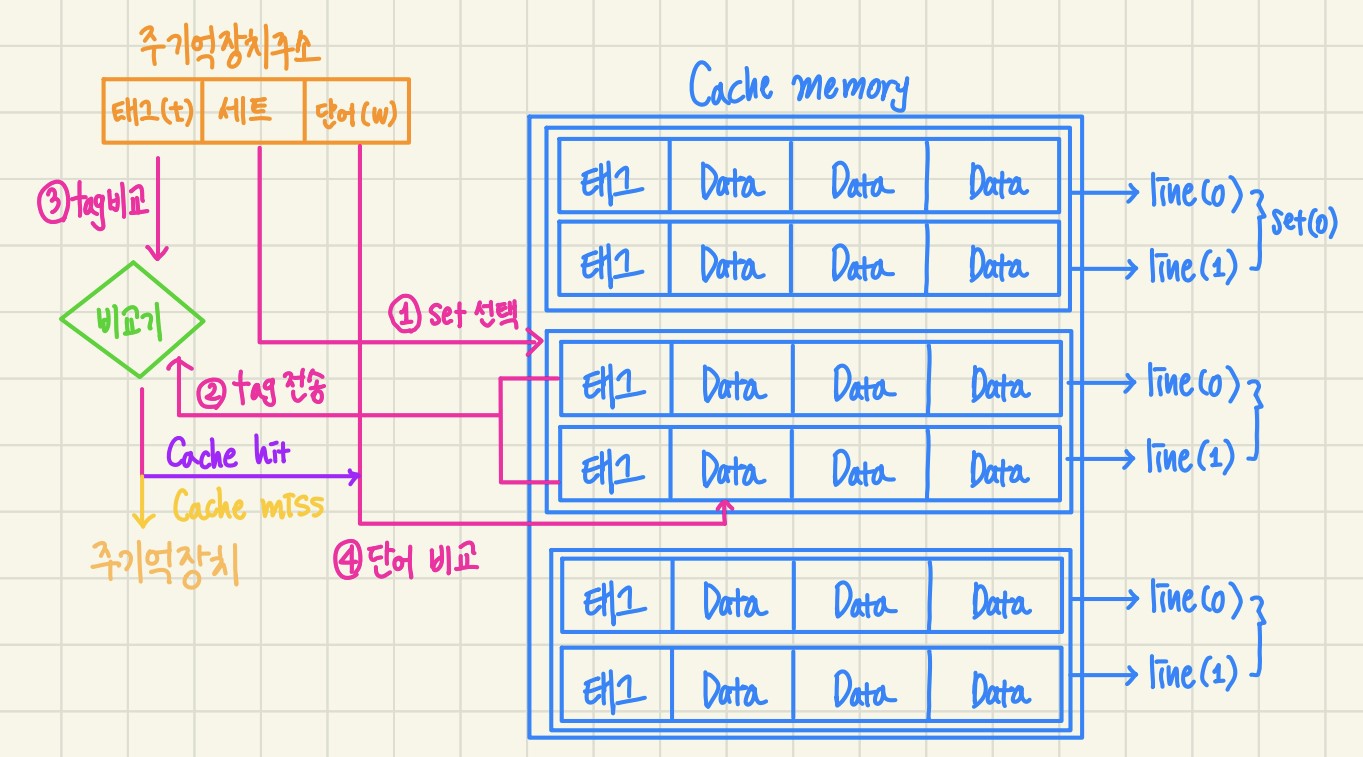
2.1.3 Set-Associative mapping
- 주기억장치 블록 그룹이 하나의 세트를 공유 ( 1set 당 2개 이상의 라인 적재 ok)
- 동일한 태그를 가진 블록들이 저장되는 캐시 슬롯 그룹을 집합으로 관리
- 만약 하나의 set이 2개의 block으로 이루어져있다면 2-way set-associative cache
하나의 set이 3개의 block으로 이루어져있다면 3-way set-associative cache- 즉, n-way set-associative cache는 block들을 n열 종대로 배열한 것
- (+): 주기억장치의 각 블록은 특정 세트 안의 어느 라인에나 적재 가능하다는 융통성
- (-): 회로 구현 복잡 및 구현 비용 높음
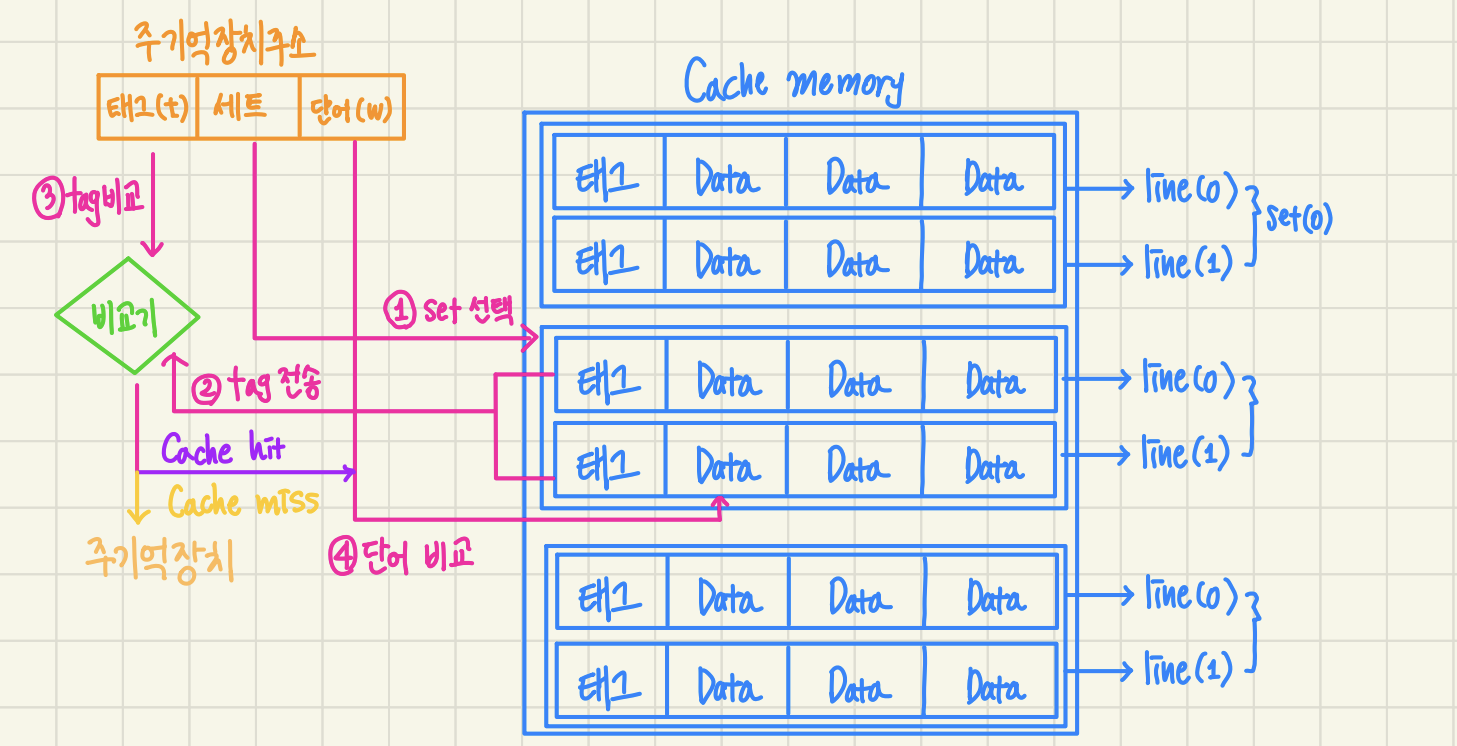
1) 기억장치 주소의 세트 비트들을 이용해서 캐시 세트들 중 하나를 선택
2) 주소의 태그 필드 내용과 그 세트 내의 태그들을 비교하여 일치하는 것이 있으면 캐시 적중
- 그 라인 내의 한 단어를 단어 필드에 의해 선택하여 인출
3) 일치하는 것이 없으면 캐시 miss
- 주기억장치를 액세스 라인들 중의 어느 라인에 새로운 블록을 적재할 것인지를 결정하여 교체

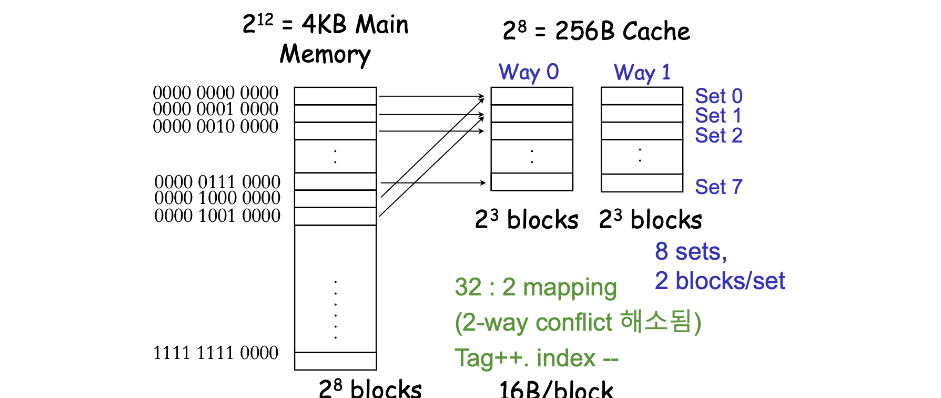
2.1.4 Two-way Set-Associative mapping
- Cache에서 하나의 set은 2개의 block으로 이루어져있다.
- Main memory의 각 block은 들어갈 set이 정해져있다.
- 32:2 mapping : main memory의 32개 block 중 2개의 block이 하나의 set에 올 수 있다.
- tag : 5bit
- main memory의 32(2^5)개의 block을 구분해야 하므로 5bit이 필요
- index : 3bit
- cache에는 8(2^3)개의 set이 존재하므로 3bit이 필요
3. Replacement Algorithms
3.0 Random Replacement
3.1 LPU (Least Recently Used)
-
최근에 사용되지 않은 set를 뺀다.
-
temporal locality에 기반
-
Reference Bit
- LRU를 사용하기 위해 reference bit를 축 - 최근에 사용된 것의 reference bit를 1로 만든다.
3.2 LFU(?) (Least Frequently Used)
- 사용 빈도수가 가장 낮은 set를 뺀다.
3.3 FIFO (First-in First-out)
- Cache에 들어온지 가장 오래된 set부터 우선 교체
3.4 Least Recently Used
- 사용된지 가장 오래된 set를 우선 교체
4. Write Policy
Cache에 write를 할 때 cache의 내용과 memory의 내용이 변형이 생겨 달라진다.(inconsistent)
이를 맞춰주기 위한 방법들이다.
4.1 Write Through 바로 쓰기
Cache에 write할 때 main memory에도 write하기
변경 사항을 메모리에 즉각 반영
main memory는 access 속도가 매우 느리다. CPI 증가
If) CPI=1, 10% 의 instruction이 sw, memory access time=50cycleThen) effective CPI= 1+ 0.1*5 = 64.1.1 Write Buffer 이용하기
캐시보다 작은 크기의 메모리
- CPU는 Cache와 write buffer에 병렬로 write한 후, write buffer에서 main memory에 write
- (+): cache와 write buffer에 병렬로 write하기 때문에 시간 손실 X
- (-): write buffer에서 main memory에 다 안 썼는데 또 들어올 경우, 즉 write buffer가 이미 차있는 경우에는 stall 발생
4.2 Write Back
cache에만 write한 후, 더 미룰수 없을 때 main memory에 나중에 write
4.2.1 Dirty Bit
cache에 write 하지 않았다면, 이후에 main memory에 write할 필요가 없다. 이를 구분하기 위한 flag의 의미.
-
dirty bit=1(dirty) : 내용이 변경됨. 이후 main memory에 write해야함
-
dirty bit=0(clean) : main memory와 cache가 같은 값을 가지므로 write할 필요 없음. memory fetch로 새로 cache line이 쓰였거나, 캐시가 초기화된 시점에서 dirty bit는 false여야함.
-
main memory에서 caching 하면 clean 상태, cache에 write 하면 dirty 상태
4.2.2 Write Buffer 이용하기
이후 다른 block들과 교체될 때 dirty bit=1 이면 memory에 wirte를 수행
이 때 main memory access속도가 느리기 때문에 miss penalty 증가. 이를 방지하기 위한 buffer
- cache에서 write buffer로 write를 하고, write buffer에서 main memory로 write.
- cache->write buffer로 write하는 시간이 걸리긴하지만, cache->main memory로 write하는 것보다 빠름
[+]
- 평소에 cache에만 write하면 되고, 평소 cache속도로 진행 가능(메모리 액세스를 줄이기 때문에 가능한 일)
- block 단위 write
- 블록 별 X, 블록 채로 한 번에 write 가능. block transfer 가능
- high-bandwidth transfer를 더 효율적으로 사용 가능
[-]
- overhead가 발생
- cache miss 가 나서 block을 교체할 때 해당 block이 dirty 인지 아닌지 판단할 필요가 있음.

혜윤님 글씨도 정말 잘쓰시고 필기도 꼼꼼히 하셨네요~:)