DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras
✍️ 논문 정보
저자: Zachary Teed, Jia Deng
소속: Princeton University
🔗 깃허브 링크
https://github.com/princeton-vl/DROID-SLAM
📄 Abstract

본 논문에서는, 새로운 딥러닝 기반 SLAM 시스템인 DROID-SLAM을 소개한다.
DROID-SLAM은 Dense Bundle Adjustment Layer를 통해 카메라 자세(camera pose)와 픽셀 단위 깊이(pixelwise depth)를 반복적으로 업데이트하는 구조를 갖고 있다.
정확도와 강인성(robustness)이 뛰어나 이전 방식보다 성능이 훨씬 향상되었고, 치명적인 실패율(catastrophic failures)이 훨씬 적다.
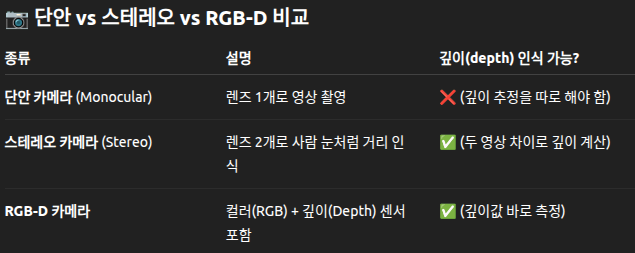
단안 카메라(monocular video, 렌즈가 하나인 일반 카메라)로 훈련했지만, 스테레오(stereo)나 RGB-D 비디오 입력도 활용 가능하여 테스트 단계에서 더 나은 성능을 보여준다.
📄 Introduction

🔍 SLAM?
SLAM (Simultaneous Localization and Mapping)은 다음 두 가지를 동시에 수행하는 기술:
1. 환경의 지도(Map) 를 생성
2. 그 환경 내에서 자신의 위치(Localization) 를 추정
이는 Structure-from-Motion(SfM) 기법의 일종으로, 장기간 경로 추적의 정확도를 높이는 데 중점을 둔 기술이다. 특히 자율주행 차량, 로봇 등의 분야에서 핵심 역할을 한다.
📚 기존 SLAM 방식들
초기 SLAM 시스템은 다음과 같은 방식으로 구현:
- 확률 기반 기법 및 필터링 방식
- 지도와 카메라 자세(pose)를 번갈아 최적화하는 방식
최근, 정확도를 높이기 위해 최소제곱 최적화(Least-Squares Optimization) 기반의 시스템이 주로 사용되고 있다. 이 중 Bundle Adjustment (BA) 는 가장 핵심적인 요소로, 카메라 포즈와 3D 맵을 동시에 최적화하는 역할을 한다.
🧩 기존 시스템 예시 – ORB-SLAM3
대표적인 기존 시스템인 ORB-SLAM3는 다음과 같은 센서를 지원:
- Monocular (단안)
- Stereo (스테레오)
- RGB-D
- IMU
이처럼 최적화 기반 SLAM 시스템은 다양한 입력을 쉽게 처리할 수 있다는 장점이 있다.
⚠️ 기존 방식의 한계
많은 발전에도 불구하고, 현재의 SLAM 시스템들은 다음과 같은 강인성 문제를 겪고 있다:
- 피처 트랙 손실 (lost feature tracks)
- 최적화 수렴 실패 (divergence in optimization)
- 드리프트 누적 (accumulation of drift)

💡 기존 딥러닝 기반 SLAM의 접근과 한계
최근에는 기존 SLAM의 한계를 극복하기 위해 딥러닝 기반 접근법이 활발히 연구되고 있다.
주요 시도들은 다음과 같다:
- 수작업 특징(hand-crafted features)을 학습 기반 특징(learned features)으로 대체
- Neural 3D representation을 이용한 방법
- 학습된 에너지 항(energy terms)을 고전적 최적화 백엔드와 결합하는 방식
- 완전한 end-to-end SLAM 학습 시스템 개발
하지만 이러한 딥러닝 기반 방법들조차도 여전히 한계가 있다:
- 강인성(robustness) 면에서는 나아졌지만,
- 정확도(accuracy) 측면에서는 기존 전통 기법(classical method)을 넘지 못하는 경우가 많음
-
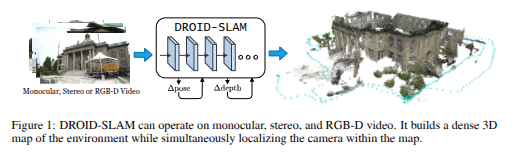
입력(Input) : 단안(Monocular), 스테레오(Stereo), 또는 RGB-D 카메라에서 캡처된 비디오 스트림
-
DROID-SLAM 처리 (DROID-SLAM Processing): 입력 비디오는 DROID-SLAM의 핵심 신경망 아키텍처를 통과한다. 이 부분은 여러 개의 계층으로 표현되어 있으며, 반복적인(recurrent) 처리를 수행함을 보여준다.
반복적 업데이트 (Δ pose, Δ depth): 핵심 처리 블록에서 출력되는 Δ pose (카메라 자세의 변화량)와 Δ depth (픽셀별 깊이의 변화량)는 다시 입력으로 피드백되는 구조로 그려져 있다. 이는 DROID-SLAM이 카메라 자세와 깊이 추정값을 반복적으로 개선해 나가는 과정을 나타낸다. 논문에서는 이를 Differentiable Recurrent Optimization-Inspired Design이라고 설명하며, 특히 Dense Bundle Adjustment 레이어를 통해 이러한 업데이트가 이루어진다고 언급한다 -
출력(Output) : 시스템의 최종 출력은 두 가지이다.
1) Dense 3D Map (밀집 3D 지도): 입력 비디오로부터 재구성된 환경의 3차원 지도이다. "Dense"는 환경의 구조가 조밀한 점이나 표면으로 표현됨을 의미한다. 그림의 오른쪽 부분에 건물의 상세한 3D 모델로 시각화되어 있다.
2) Estimated Trajectory (추정된 궤적): 비디오가 캡처되는 동안 카메라가 이동한 경로이다. 그림에서는 3D 지도 주변의 파란색 점선으로 표현되어 있다. SLAM의 주요 목표 중 하나인 에이전트(카메라)의 위치 추정 결과를 보여준다.


DROID-SLAM 성능
High Accuracy
-
TartanAir SLAM Competition:
- 단안 입력: 기존 최고 성능보다 오차 62% 감소
- 스테레오 입력: 오차 60% 감소
- → 모든 트랙에서 1위 기록
-
ETH-3D RGB-D SLAM:
- AUC 기준으로 2등보다 35% 우수
- (AUC는 에러 + 치명적 실패율까지 고려하는 종합 지표)
-
EuRoC Dataset:
- 단안 입력, 실패 0인 방법들 중에서 오차 82% 감소
- ORB-SLAM3 기준으로는 43% 감소 (11개 시퀀스 중 10개에서 성공한 경우 기준)
-
Stereo 입력 시:
- ORB-SLAM3 대비 오차 71% 감소
-
TUM-RGBD:
- 실패 0인 방법들 기준 오차 83% 감소
High Robustness
DROID-SLAM은 기존 시스템들에 비해 치명적인 실패(catastrophic failure)가 현저히 적다.
-
ETH-3D RGB-D:
- DROID-SLAM은 32개 중 30개 시퀀스를 성공적으로 추적
- 반면, 다음으로 성능 좋은 시스템은 19/32만 성공
-
TartanAir, EuRoC, TUM-RGBD:
- 모든 테스트에서 실패 0건(zero failures) 기록
👉 이는 SLAM 시스템의 실용성에서 매우 중요한 요소로, 실제 환경에서도 신뢰성이 높다는 것을 의미.
Strong Generalization
단안 영상(monocular video)만으로 훈련한 하나의 모델이,
별도의 재학습 없이 스테레오 또는 RGB-D 입력에서도 높은 성능을 보인다.
- 4개의 데이터셋 + 3가지 입력 모달리티(단안, 스테레오, RGB-D)에서
- 단 하나의 모델, 한 번의 학습(TartanAir 단안 영상)으로 성능 달성
📌 즉, 모델 재학습 없이도 다양한 입력에 일반화되는 능력을 보여주는 것이 DROID-SLAM의 강력한 특징 중 하나이다.

DROID-SLAM 아키텍처
🔧 핵심 개념: Differentiable Optimization-Inspired Design
- 기존 전통적인 최적화 방식과 딥러닝 네트워크의 장점을 결합한 구조
- 이를 통해 recurrent iterative updates (반복 최적화)를 수행
- Optical flow 기반의 RAFT 방식에서 영감을 받았지만, optical flow가 아니라 카메라 자세(pose)와 깊이(depth)를 직접 업데이트

recurrent iterative update
1) optical flow를 반복적으로 업데이트하는 RAFT와 달리 카메라 포즈와 깊이를 반복적으로 업데이트한다. RAFT는 두 프레임에서 작동하지만, 저희 업데이트는 임의의 수의 프레임에 적용되어 모든 카메라 포즈와 깊이 맵의 joint global refinement(공동 전역 정밀화)를 가능하게 하며, 이는 긴 궤적과 루프 클로저에 대한 드리프트를 최소화하는데 필수적이다.
- 모든 프레임을 함께 고려하여 최적화하기 때문에 다음과 장점을 가진다.
- 오차 누적 최소화: 단일 프레임 또는 짧은 시퀀스에 기반한 업데이트는 시간이 지남에 따라 작은 오차가 누적되어 전체 궤적의 정확도가 떨어지기 쉽다. **DROID-SLAM은 전역적인 최적화를 통해 이러한 오차 누적을 효과적으로 줄인다.
- 루프 클로저 처지(Loop closures): 로봇이나 카메라가 이전에 방문했던 장소로 돌아왔을 때, 이를 인지하고 과거 데이터를 활용하여 현재 위치 및 지도 정보를 보정하는 과정을 루프 클로저라고 한다. DROID-SLAM의 전역 업데이트 방식은 과거의 프레임과 현재 프레임간의 연결(Frame-graph의 장거리 연결)을 활용하여 루프 클로저를 통해 map의 일관성을 높일 수 있다.

2) DROID-SLAM에서 카메라 포즈와 깊이 맵의 각 업데이트는 optical flow의 현재 추정치와의 호환성을 최대화하기 위해 카메라 포즈와 dense per-pixel 깊이에 대한 Gauss-Newton 업데이트를 계산하는 미분 가능한 Dense Bundle Adjustment(DBA) 레이어에 의해 생성된다. 이 DBA 레이어는 기하학적 제약 조건을 활용하고 정확도와 견고성을 향상시키며, 단안 시스템이 재학습 없이 스테레오 또는 RGB-D 입력을 처리할 수 있도록 한다.

핵심 모듈: DBA (Dense Bundle Adjustment) Layer
- Gauss-Newton 최적화 기법을 딥러닝 구조에 포함
- 카메라 포즈와 픽셀 단위 깊이 정보를 함께 업데이트
- 이 과정은 다음을 보장함:
- 기존 추정 결과와의 정합성
- 강인한 제약 조건
- 다양한 입력 타입(monocular, stereo, RGB-D)에 대한 일반화
🔍 기존 방법과의 차이점 – DeepV2D, BA-Net
DeepV2D : 깊이 추정과 카메라 자세 추정을 반복적으로 수행하지만, SLAM 전체 구조는 아님
- bundle adjustment 대신 깊이 업데이트와 카메라 포즈 업데이트 사이를 번갈아 수행함
BA-Net : 번들 조정이 포함되어 있지만, depth basis를 사용하는 다른 구조이며 확장성이 떨어짐
- bundle adjustment 레이어가 있지만, 해당 레이어는 상당히 다름, 깊이 basis(미리 예측된 깊이 맵 세트)를 선형적으로 결합하는데 사용되는 적은 수의 계수를 통해 최적화하는 반면, 깊이 basis(기저)에 의해 제한되지 않고 per-pixel 깊이를 직접 최적화하기 때문에 "dense"하지 않는다. 또한 BA-NET은 photometric reprojection error(feature space에서)를 최적화하는 반면, DROID-SLAM은 최첨단 flow estimation을 활용하여 기하학적 오류를 최적화한다.
📌 DROID-SLAM은 BA layer를 직접적으로 네트워크 내에 구성해, 전통적인 구조를 그대로 가져오면서도 end-to-end 학습이 가능하게 만든 점이 가장 큰 차별점 !
학습과 실험
- 다양한 데이터셋(4개)과 입력 모달리티(3가지)에서 평가 수행
- 실험 외에도 아키텍처 설계와 하이퍼파라미터에 대한 ablation study도 포함
(Ablation Study는 딥러닝 모델의 성능에 영향을 미치는 구성 요소의 중요도를 분석하기 위해, 해당 요소를 제거하거나 변경하여 모델의 성능 변화를 관찰하는 실험 방법)
➡️ 이로써, DROID-SLAM은 성능, 안정성, 확장성 세 요소 모두를 만족하는 현대적 SLAM 시스템이라 할 수 있다.
Related Work

1. SLAM의 통합 최적화
Modern SLAM systems treat localization and mapping as a joint optimization problem.
현대 SLAM 시스템은 위치 추정(Localization)과 지도 작성(Mapping)을 동시에 처리하는
통합 최적화 문제(joint optimization)로 다룬다. 이로써 두 문제의 상호 의존성을 고려해 더 정확한 결과를 얻을 수 있다.
💡 왜 중요한가?
예전 방식은 위치 먼저 추정 → 지도 구성처럼 순차적이었다. 하지만 지금은 "내가 어디 있는지를 잘 알아야 지도를 잘 만들고", "지도가 정확해야 위치도 정확히 알 수 있다"는 상호 의존성을 고려해서 둘을 동시에 최적화하는 구조가 더 정확하고 안정적이다.
2. Visual SLAM: 입력 형태와 분류
Visual SLAM은 영상 기반의 SLAM으로, 입력은 다음과 같다:
- 단안 영상 (Monocular)
- 스테레오 영상
- RGB-D 영상
이러한 방식은 일반적으로 두 가지 접근법으로 나뉩니다:- Indirect 방식
- Direct 방식
3. Indirect Approach (간접 방식)
- 입력 영상을 바로 쓰지 않고, 먼저 특징점(feature)을 추출함
- 추출된 특징점에 대해 디스크립터(descriptor)를 붙여 이미지 간 매칭
- 이후, 재투영 오차(reprojection error)를 최소화하도록
카메라 포즈와 3D 포인트 위치를 최적화함
→ "예상한 점과 실제 이미지에서 찍힌 점 사이 거리 최소화"
📌 장점: - 구조가 단순하고 비교적 안정적
📌 단점: - 영상의 풍부한 정보(밝기, 선 등)는 사용하지 않음
4. Direct Approach (직접 방식)
- 영상의 밝기(intensity)를 그대로 활용해 최적화 진행
- 전체 이미지의 밝기 차이(photometric error)를 최소화하는 목적함수를 사용
📌 장점: - 특징점 외에도 밝기 변화, 선, 텍스처 등 풍부한 정보를 활용 가능
📌 단점: - 왜곡(rolling shutter)이나 조명 변화에 민감
- photometric error 기반 최적화는 복잡하고 어려움
- 해결을 위해 coarse-to-fine 피라미드 등 정교한 최적화 기법 필요
✅ 요약 정리
| 구분 | Indirect | Direct |
|---|---|---|
| 입력 처리 방식 | 특징점 추출 후 매칭 | 원본 밝기 정보 직접 사용 |
| 최적화 기준 | 재투영 오차 | 밝기 오차 (Photometric error) |
| 장점 | 안정적, 빠름 | 정보 풍부하게 활용 |
| 단점 | 정보 손실 있음 | 왜곡에 민감, 최적화 어려움 |

DROID-SLAM의 접근 방식 – 기존 방식과의 차별점
Indirect/Direct 방식과의 비교
DROID-SLAM은 기존 방식인 Indirect 또는 Direct 중 하나로 딱 떨어지진 않는다.
- Indirect처럼 복잡한 전처리 과정 없이 작동하지만,
- Direct보다 더 넓은 영상 정보를 활용함 (예: 선, 가장자리 등)
- Photometric error 기반이지만, 간접 방식보다 더 부드럽고 안정적
📌 핵심 요약:
우리는 직접 방식의 장점을 가지면서도, 간접 방식보다 더 풍부한 이미지 표현과
효율적인 최적화 구조를 가진 하이브리드적 방식이다.
딥러닝 기반 SLAM의 도전과 한계
최근 연구들은 다음과 같은 방식으로 SLAM을 시도해 왔다:
- 최근 딥러닝이 SLAM 문제에 적용되었다. 많은 연구에서 특징 감지, 특징 매칭 및 이상치 제거, 그리고 localization과 같은 특정 하위 문제에 대한 시스템 훈련에 초점을 맞추었다.
- SuperGlue: 특징점 매칭 및 검증을 수행, 정교화 + 2-view 포즈 추정을 훨씬 더 강력하게 만들도록 설계
- DS2-SLAM: 단일 영상 기반 위치 추정
- DUSMANU et al.: Structure-from-Motion(SfM) 파이프라인을 딥러닝화
하지만 대부분은 다음과 같은 한계가 있다:
- 다른 연구에서는 SLAM을 end-to-end로 훈련하는 데 초점을 맞추었다. 이러한 방법은,
- Full SLAM 시스템이 아님
- 소규모 장면 재구성에 한정되어 있음
- Loop closure, global BA (Bundle Adjustment)와 같은 핵심 기능 없음
→ DROID-SLAM은 이를 모두 포함한 전체 파이프라인을 갖고 있음
DeepFactors와의 차이점
DeepFactors는 학습된 depth basis를 사용하여 장면을 표현한다.
- DeepFactors는 초기 CodeSLAM을 기반으로 구축된 가장 완전한 Deep SLAM 시스템이다. 포즈 및 깊이 변수의 공동 최적화를 수행하며 단거리 및 장거리 루프 클로저가 가능하다. BA-Net과 유사하게 DeepFactors는 추론 중에 학습된 깊이 basis의 매개변수를 최적화한다.
- 이는 학습 데이터에 과하게 의존하게 되고, 새로운 데이터셋으로의 일반화가 어려움
- 반면, DROID-SLAM은 픽셀 단위 depth 추정을 직접적으로 수행하여,
- 학습된 basis에 의존하지 않고 대신 픽셀 단위 깊이를 최적화한다.
- 이를 통해 깊이 표현이 훈련 데이터 세트에 묶여 있지 않기 때문에 새로운 장면이나 데이터셋에 더 잘 일반화됨
결론
DROID-SLAM은 다음을 동시에 만족하는 하이브리드 최적화 딥러닝 기반 SLAM 시스템:
- 간접 방식처럼 구조적이고 효율적이며
- 직접 방식처럼 풍부한 영상 정보 사용
- 기존 딥러닝 기반 시스템보다 더 정확하고 더 일반화 가능함
Approach
Approach – 입력 구조 및 상태 변수

DROID-SLAM은 연속된 영상 프레임을 입력으로 받아서 다음 두 가지를 추정:
1. 카메라의 궤적 (trajectory)
2. 환경의 3D 지도 (map)
내부 상태 변수 (for each frame t)\
네트워크는 시간 순으로 정렬된 영상 프레임 {Iₜ}을 입력으로 받는다.
각 시간 t에 대해 두 가지 상태 변수(state variable)를 유지한다:
- Gₜ (카메라 자세) ∈ SE(3): 위치 + 회전, t시점의 **카메라 자세 (pose)
- dₜ (역깊이 맵) ∈ ℝ+^{H×W}: 각 픽셀의 깊이 → "1 / 깊이" 형태로 사용, t시점 프레임의 역깊이 맵 (inverse depth)
이 두 변수는 영상 프레임이 들어올 때마다 점진적으로 최적화된다.
Frame Graph (𝓥, 𝓔): 프레임 간 연결 구조
DROID-SLAM은 프레임 간의 공시야성(co-visibility)을 표현하기 위해 프레임 그래프 (𝓥, 𝓔) 를 동적으로 구성한다.
- 정점 𝓥: 각 영상 프레임
- 간선 𝓔: 두 프레임이 같은 장면(같은 3D 지점)을 관측할 경우 연결됨
→ 즉, Iᵢ와 Iⱼ가 겹치는 시야를 가지면 (i, j) ∈ 𝓔
이 프레임 그래프는 학습 시와 추론 시 모두 실시간으로 구성된다.
업데이트와 루프 클로저(Loop Closure)
- 각 포즈(G) 또는 깊이(d) 업데이트 이후,
공시야성(co-visibility)에 따라 프레임 그래프를 재계산함 - 만약 카메라가 이전에 지나간 장소로 되돌아오면,
해당 프레임을 그래프 상에서 장거리 연결(long-range edge)로 추가함
→ 이를 통해 루프 클로저(loop closure) 를 수행할 수 있음
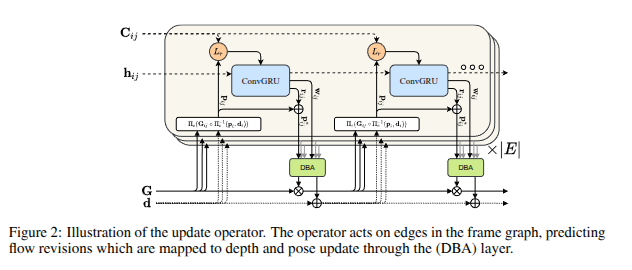
DROID-SLAM 핵심 구조 – Recurrent Bundle Adjustment
DROID-SLAM의 성능을 뒷받침하는 핵심 구조는
ConvGRU + DBA(Differentiable Bundle Adjustment)가 결합된 반복 최적화 구조
아래는 논문에 등장하는 모듈 구성도에 대한 설명:
- 영상 간 관계(hᵢⱼ)를 기반으로 반복적으로 카메라 포즈(G)와 깊이(d)를 업데이트하는 구조이다.
구성 요소
하단: 입력 상태 변수들
- G: 각 프레임의 카메라 포즈 (Pose)
- d: 각 프레임의 역깊이 맵 (Inverse Depth Map)
이 두 상태 변수는 초기에는 추정값으로 시작하며, 학습 및 추론 과정에서 반복적으로 업데이트된다.
초록 박스: DBA (Dense Bundle Adjustment)
- Gauss-Newton 기반의 번들 조정 모듈
- 여러 프레임 간의 2D-3D 대응 관계를 활용하여 카메라 포즈 G와 깊이 d를 공동 최적화
- 반복적으로 호출되며, gradient가 흐를 수 있도록 Differentiable하게 설계됨
파란 박스: ConvGRU (Convolutional GRU)
- 프레임 간의 상태 정보를 순환적으로 업데이트하는 구조
- Conv 연산 기반이므로 영상의 공간 정보를 보존함
입력:
- 현재 관계 상태 hᵢⱼ (i번 프레임과 j번 프레임 사이)
- 각 프레임 간의 photometric error, projection error
출력:
- 다음 상태(hᵢⱼ)
- 손실 함수 계산을 위한 항 Lₚ
Lₚ (Loss)
- 각 프레임 쌍(i, j)마다 포즈 G, 깊이 d를 기반으로 손실 함수 Lₚ를 계산
- 얼마나 잘 정렬되었는지를 평가하고, 이를 통해 학습이 진행됨
Cᵢⱼ, hᵢⱼ
- 프레임 간 연결(edge) 상태를 나타냄
- hᵢⱼ: 프레임 쌍의 숨겨진 상태값 (hidden state)
- Cᵢⱼ: 상태 업데이트를 위한 메시지/컨텍스트 정보
반복 구조 (× |E| 만큼 반복)
- 이 전체 구조는 프레임 간 연결 개수(|E|) 만큼 반복 수행됨
- 모든 프레임 쌍의 관계를 순환적으로 고려하여 카메라 위치와 깊이 지도를 점진적으로 정밀하게 조정함
요약
DROID-SLAM은 그래프 기반 구조 위에 ConvGRU → DBA → 상태 업데이트 → 반복 순서를 통해
정밀한 위치 추정과 맵 구성을 실현한다.

3.1 Feature Extraction and Correlation
DROID-SLAM은 각 프레임 이미지에서 특징(feature)을 추출하여 프레임 간의 관계를 계산(correlation)하는 구조를 갖고 있으며, 이 과정은 RAFT의 구조에서 차용되었다.
Feature Extraction: 특징 추출 네트워크
각 입력 이미지는 두 개의 네트워크를 통해 처리:
-
Feature network (g_θ):
각 이미지에서 dense feature map을 추출, 상관 관계 볼륨 세트를 구축하는 데에 사용
→ 이 feature map은 correlation volume 계산에 사용 -
Context network:
학습 중 내부 상태(state) 업데이트를 돕는 정보를 제공, 업데이트 연산자의 각 적용 중에 네트워크에 주입
→ 업데이트 연산이 수행될 때 context feature가 주입됨
네트워크 구성:
- 6개의 residual block(잔차 블록)과 3개의 downsampling layer(다운 샘플링 레이어)를 사용
- 출력 해상도는 입력 해상도의 1/8 수준 (조밀한 특징 맵을 생성)
Correlation Pyramid: 프레임 간 상관 피라미드
프레임 그래프의 각 edge (i, j) ∈ E 에 대해, 다음과 같이 4D 상관 볼륨 (correlation volume)을 계산:
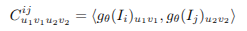
→ 두 이미지 gθ(Iᵢ), gθ(Iⱼ)의 feature map 간 모든 픽셀 쌍의 내적 (dot product) 계산
이후, 마지막 두 차원에 대해 average pooling을 적용하여 4단계 correlation pyramid를 구성한다.(RAFT와 유사)
Correlation Lookup: 상관 볼륨 탐색 연산자
- 주어진 위치 주변의 픽셀들을 대상으로 상관 볼륨 값을 추출하는 연산자
- H × W 격자에서 값을 bilinear interpolation(선형보간법을 2차원으로 확장)으로 얻어냄
bilinear interpolation 참고) https://ideadummy.tistory.com/88
- 모든 레벨의 correlation pyramid에 적용한 뒤, 최종적으로 feature vector를 얻기 위해 concat
이 lookup 연산자는 업데이트 네트워크의 입력으로 사용되며, 포즈/깊이 업데이트 시 상호 관계 정보를 정교하게 추출하는 데 사용된다.
