re.sub의 쓰임(feat.정규표현식)
#re.sub(기존규칙 / 어떤 규칙으로 바꿀지 / 대상)
#re.sub으로 return하는 함수 만들기
# [0-9] : 숫자와 매치
# "[^0-9]" : 숫자가 아닌것과 매치. ^은 not이라는 의미를 갖는다
def get_number(text):
return re.sub("[^0-9]", "", text)
get_number("#7265 접촉(추정)")조건을 걸떄 : and는 &을 쓰자!
df[df["접촉력"].str.contains("이태원") & (df["월"] == 6) ]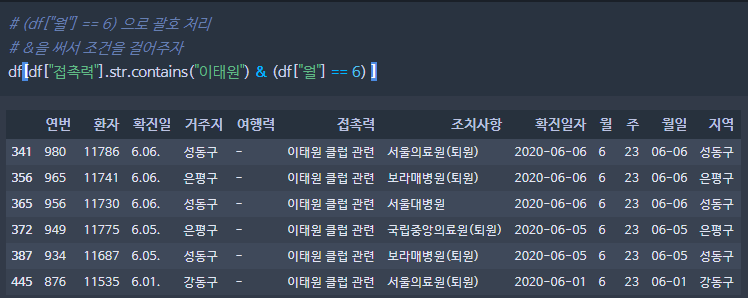
# 여러개의 and는 괄호를 쳐서 구분!
df[(df["퇴원"] == False) & (df["사망"] == False) & (df["지역"] != "타지역")].tail(5)merge는 데이터프레임에서 가능!
# df_days 테이블과 df_daily_case를 merge한다
# sql을 쓰듯이!! left join을 하고, on이 붙은 곳엔 sql처럼 해당하는 칼럼들을 적어주기
# (FROM df_days LEFT JOIN df_daily_case ON df_days.확진일자 = df_daily_case.index)
all_day = df_days.merge(df_daily_case, how="left", left_on="확진일자", right_on=df_daily_case.index)
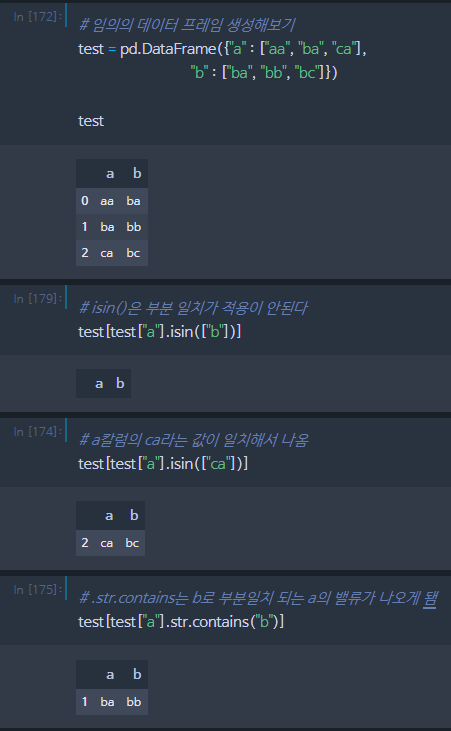
all_day.head()isin() 과 str.contains()의 차이
# isin은 다른 데이터 타입과도 대응하고, str.contains는 스트링에서만 일단 가능
# 표기 방식
print(df)
# a
# 0 aa
# 1 ba
# 2 ca
print(df[df['a'].isin(['aa', 'ca'])])
# a
# 0 aa
# 2 ca
print(df[df['a'].str.contains('b')])
# a
# 1 ba

가장 보통의 존재