성능과 정확도를 평가하기 위한 지표

Variance (성능의 편차)
같은 알고리즘, 하이퍼 파라미터의 값을 사용하더라도 학습 데이터가 다를 때 발생하는 예측 값(성능)의 편차(variance)
예측 값이 흩어진 정도
Bias (오차, 편향)
예측값(평균)과 실제 값의 차이의 평균
데이터의 양이 증가할 수록 Variance와 Bias는 감소한다. (성능 증가)
-> 일반적으로 어느 정도 수준에서 성능 증가량은 줄어들고 일정한 수준으로 유지된다 (성능 증가량 감소)
-> 적절한 데이터 크기를 찾아야한다 (Learning Curve)
성능의 편차와 오차의 원인 및 해결책
- 여러번의 테스트를 통해 편차가 있는 성능이 아니라 평균 성능으로 비교한다.
- 랜덤 샘플링 N회 반복 후 평균 성능 테스트
- K-fold Cross Validation
- 학습용 데이터의 양 증가 Learning Curve
- 머신 러닝에서 varicance(성능의 편차, 분산)와 bias(오차, 편향)의 발생은 잘못된 데이터 선정
Learning Curve
학습 데이터셋의 크기가 커지면(=데이터가 많아지면) 모델 성능이 향상된다.
모델 복잡도와 과적합
모델의 복잡도
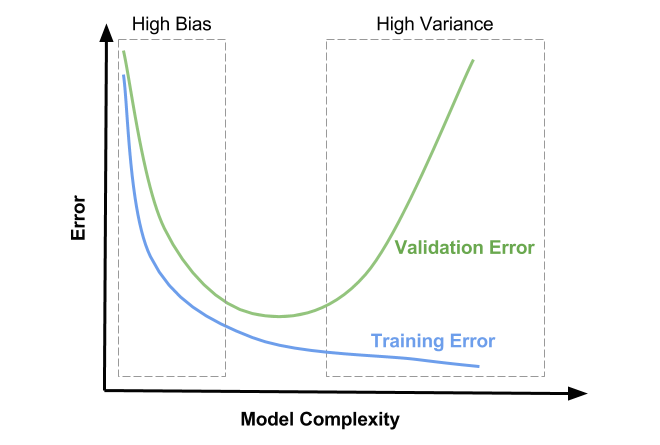
- 모델의 복잡도를 결정 할 때 Variance(성능의 편차, 분산)과 Bias(오차, 편향)은 서로 반대 방향으로 증감한다.
- 적당한 수준의 Bias와 Variance를 찾기 위해 노력해야한다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import *
# K개의 샘플을 사용
for k in range(1, X_train.shape[0]): # 0 ~ 데이터의 feature 갯수
# 테스트 코드는 KNN Algorithm
model = KNeighborsClassifier(n_neighbors=k)
# 검증용 데이터의 예측과 훈련용 데이터의 예측값을 구함
Validation_pred = model.predict(X_val)
Training_pred = model.predict(X_train)
# 검증용 데이터의 정확도와 훈련용 데이터의 예측값 계산
Validation_Acc = accuracy_score(y_val, Validation_pred)
Training_Acc = accuracy_score(y_train, Training_pred)
# 예상되는 결과
# K가 1일 때 훈련용 데이터의 정확도는 100%이지만 검증용 데이터는 낮게 나올 것임.
# K가 증가하면서 훈련용 모델은 평균 모델을 그리게 될 것
# 두 테스트의 정확도의 차이가 가장 적으면서 모델의 복잡도가 가장 낮은(K가 큰) 수치를 찾아서 선정한다.KNN 모델 기준, K의 개수(하이퍼 파라미터)를 조절하며 모델의 학습 데이터 정확도와 검증 데이터의 정확도를 비교해가며 모델의 복잡도를 조절한다.
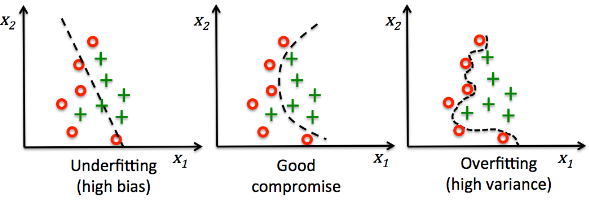
과적합이 문제가 되는 이유
- 모델이 복잡해지면 학습 데이터에만 존재하는 가짜 패턴을 학습하게 됨.
- 모집단에는 존재하지 않는 패턴, 특성이기 때문에 학습 데이터에서는 높은 성능을 보여주지만 실제 테스트에선 성능이 떨어짐
회귀 모델 (Regression)
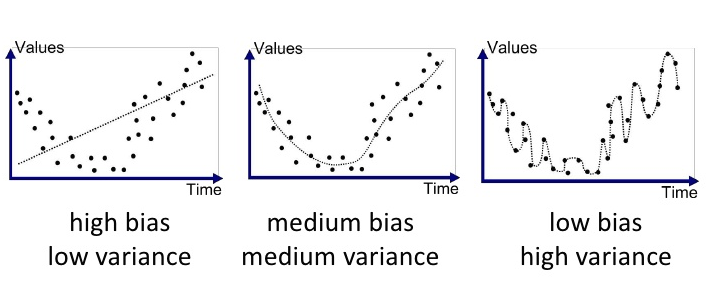
분류 모델 (Classification)
여러번 반복 실행, 평균 성능으로 비교
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import *
import numpy as np
X, y = np.arange(10).reshape((5, 2)), range(5)
result = []
for _ in range(100):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=.3)
# 이후 테스트 진행
# model = LinearRegression()
# model.fit(X_train, y_train)
# pred = model.predict(X_val)
# result.append(1 - mean_absolute_percentage_error(y_val, pred))
# 평균 정답률(1 - 평균 오차율)의 평균
# np.mean(result)데이터를 100번의 랜덤 분할 후 학습-검증 후 성능 평균 성능 산정K-fold Cross Validation
# 전처리
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# 모델링
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
# K-fold Cross Validation
from sklearn.model_selection import cross_val_score
# 모델 생성
model = KNeighborsRegressor()
# data 생성
X, y = np.arange(10).reshape((5, 2)), range(5)
# cross validation 실행
score_result = cross_val_score(model, X, y, cv=5) # 보통 데이터가 적으면 5, 많으면 10까지 사용함
print(score_result)
# cv에 넣은 숫자 만큼의 교차 검증의 정확도 점수를 리스트로 반환
print(score_result.mean(), score_result.std())
# 정확도 점수들의 평균, 분산
# RandomizedSearchCV, GridSearchCV을 사용할 때 기입하는 cv값이 cross validation에 해당함
데이터 셋을 5등분 하여 학습-검증 후 평균 성능 산정모든 데이터가 한 번씩 검증(Validation)에 사용 할 수 있도록 학습 데이터를 분할하여 학습-검증을 한다.
참고
머신러닝에서의 Bias와 Variance - 2019, APR 13
교차 검증 (cross validation)

기술을 공부하는 기술자