머신 러닝
1.머신러닝 개요

데이터로부터 패턴(규칙)을 찾아 수학식으로 정리하는 것,모델링 : 오차가 적은 모델을 만드는 과정지도 학습비지도 학습회귀 (Regression)분류 (Classfication)함수-데이터 불러오기선언(설계, 데이터 전처리)학습(모델링)검증 (예측 + 평가)
2.회귀 모델
회귀 평가 기준 R2 스코어 MAE : 평균 오차 MAPE : 평균 오차율 MSE : 오차의 제곱 RMSE : 오차의 제곱
3.머신러닝 준비 과정
데이터 수집데이터분할test 데이터 분리EDA & CDA불필요한 변수 제거NaN 행 제거데이터 분할 X(feature), Y(target) 행 제거와 데이터 분할은 순서를 데이터 수를 맞추기 위해 순서를 지키거나 drop X, Y 둘다 drop을 해야한다.Featur
4.KNN 모델
KNN (k-Nearest Neighbor)
5.로지스틱 회귀
원하는건 0, 1 의 범주형 데이터 이지만 -∞, ∞의 범위를 가진 숫자형 데이터로 나오게됨이미지$$P{+}(x) : 일어날 확률$$$$\\Large{P{+}(x)} \\over { 1 - {P\_{+}(x)} }$$승산으로 Y의 범위를 -∞, ∞ 에서 0, ∞ 까지
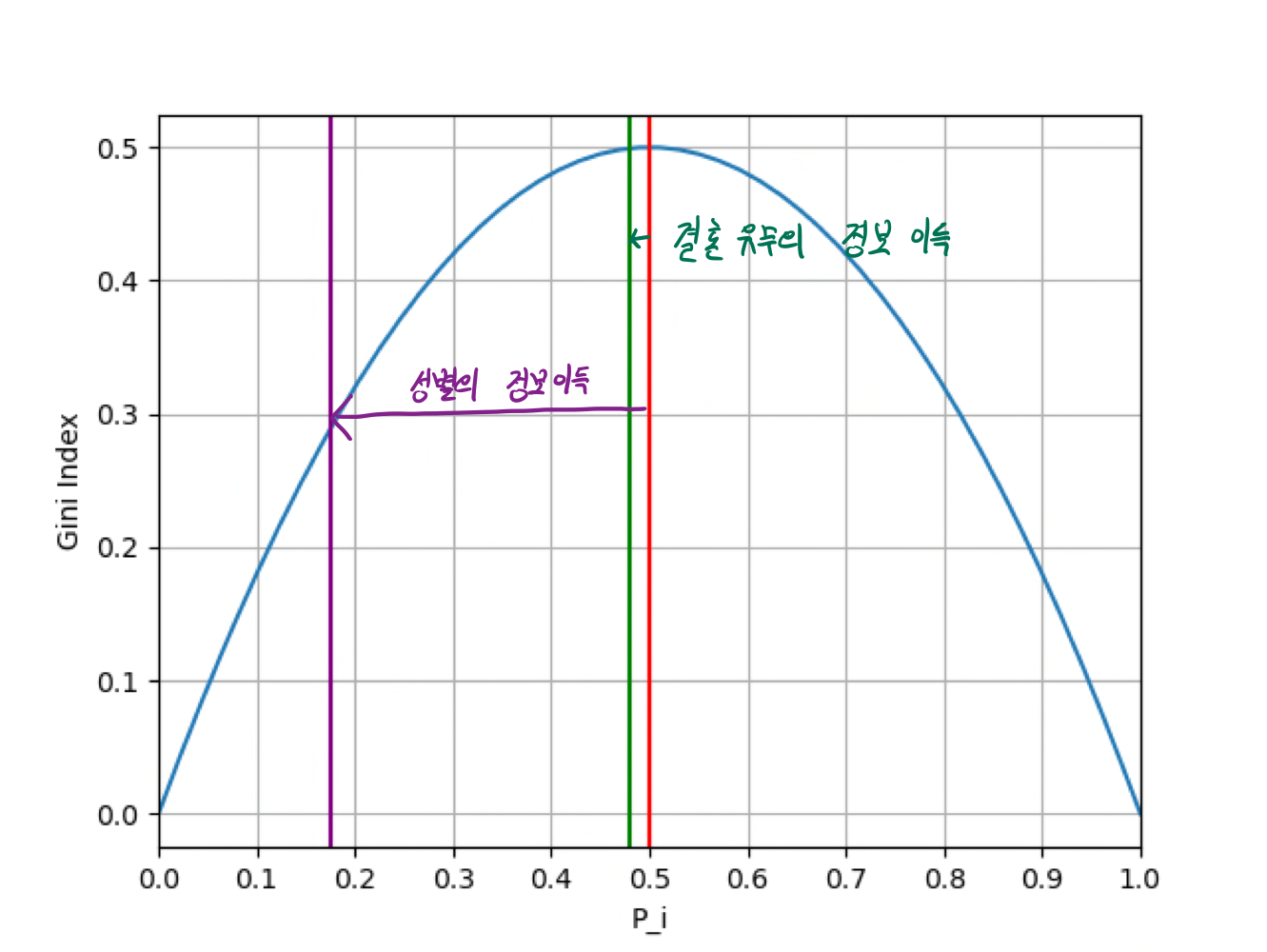
6.분류모델 평가
1. Accuracy 정분류율 전체 데이터 중에서 정상을 정상으로, 불량을 불량으로 정확하게 예측한 비율 $$ $$ Recall 재현율 실제 불량률에 맞춘 비율 Precision 정밀도 예측 불량
7.성능과 정확도
편차와 분산같은 알고리즘, 하이퍼 파라미터의 값을 사용하더라도 학습 데이터가 다를 때 발생하는 예측 값(성능)의 편차(variance)여러번의 테스트를 통해 편차가 있는 성능이 아니라 평균 성능으로 비교한다. \- K-fold Cross Validation머신 러닝에
8.의사 결정 트리
Decision Tree ( 의사 결정 나무 ) 의사 결정나무의 특징 특정 변수에 대한 의사 결정(분기, 분류) 규칙을 Tree의 형태로 분류하는 분석 기법 분석 과정 자체를 시각화 할 수 있는 화이트박스 모델 KNN과 마찬가지로 회귀/분류형 데이터에 사용할 수
9.SVM (Support Vector Machine)
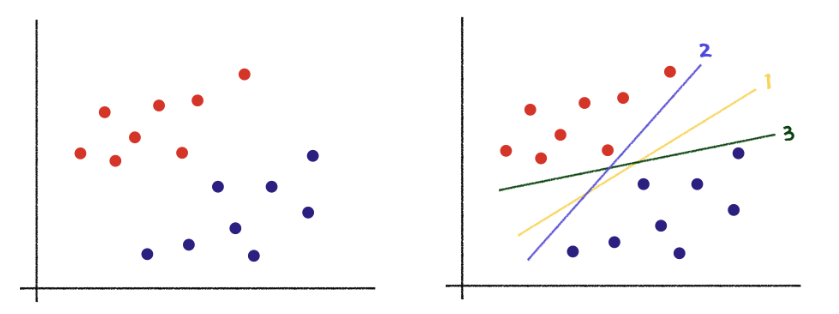
범주형 데이터나 수치(회귀)형 데이터에 모두 사용 가능한 모델기본적으로 분류 모델을 기준으로 설명한다.서포트 벡터 머신서포트 벡터 머신은 그래프의 데이터를 설명하기 위해 1, 2, 3번의 직선 모드 사용 할 수있다. 그렇지만 직관적으로 봤을 때 1번 직선이 가장 최적의
10.성능 튜닝
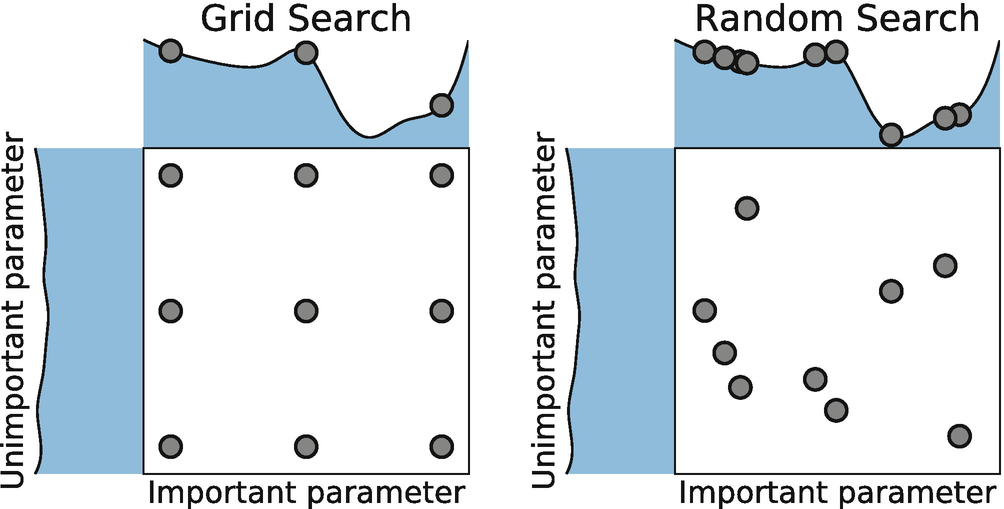
선형 모델링에서 많은 변수의 채택은 다중공선성의 문제가 발생할 가능성이 높아지기 때문에 선형 모델을 선택할 때 모델의 복잡도 또한 모델링을 할 때 고려해야한다.모델이 Train Set을 잘 설명할 수 있으면서 모델에 대한 과적합이 되지 않도록 주의해야한다.선형 모델링
11.앙상블(Ensemble): 배깅과 부스팅
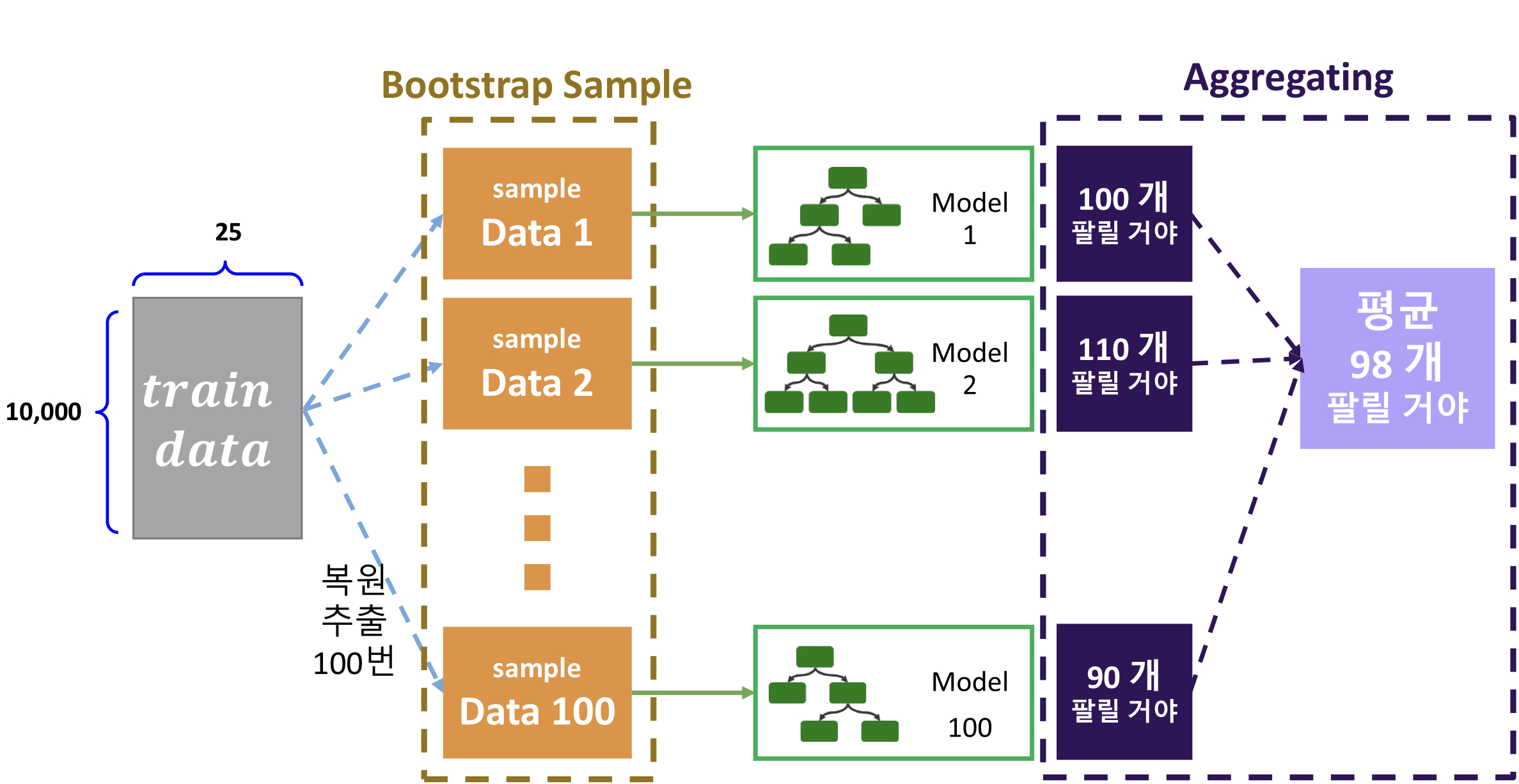
앙상블 학습은 여러 개의 모델을 생성하고, 예측을 합성하면서 정확한 예측을 하는 방법단일 모델을 사용하는 것이 아니라 여러가지 모델을 합성하는 방식이다.앙상블에는 보팅, 배깅, 부스팅 추가로 스택킹의 방식이 있지만 강의에선 배깅과 부스팅의 설명만 들었으니 먼저 배깅과
12.시계열 데이터 모델링
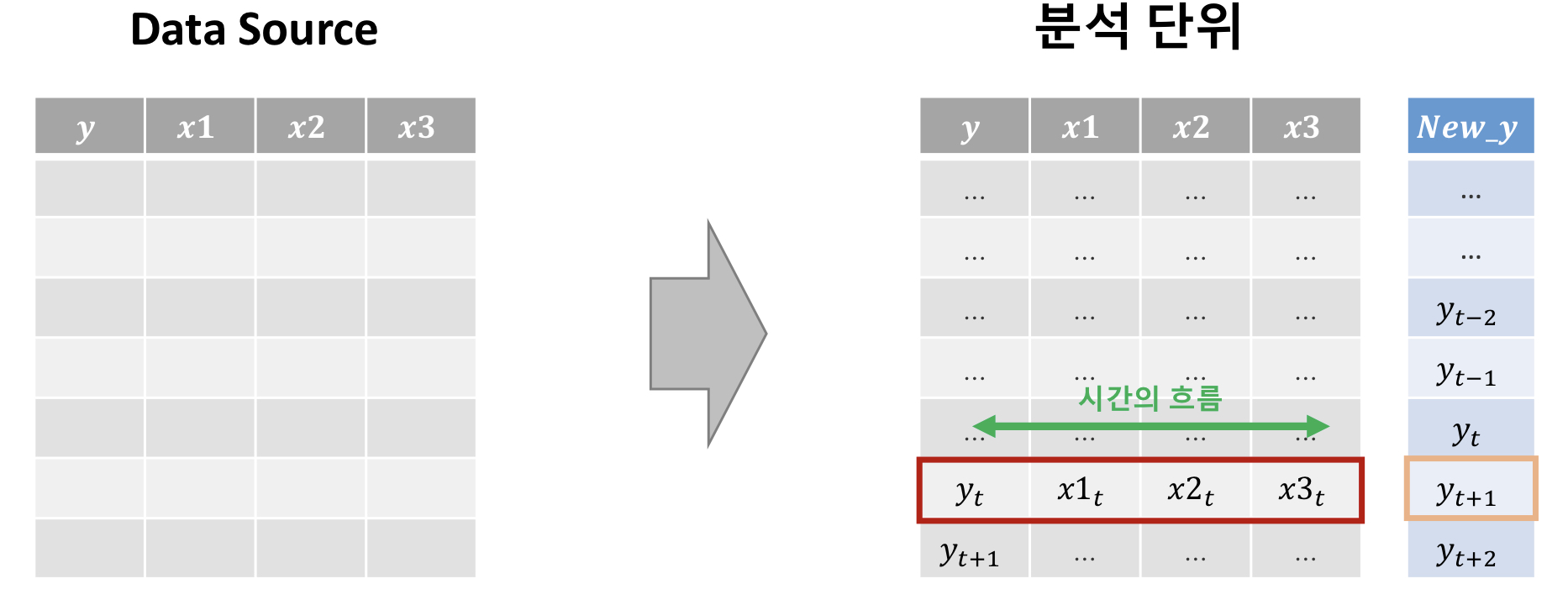
|날짜|종가|환율|거래량| |---|----|----|----| |8/1|91000|1200|10 |8/2|90500|1205|20 |8/3|82000|1205|25 |8/4 전통적인 시계열 머 잔차 정상