복습문제
# 다음은 비정형 데이터를 머신러닝에 적용시키기 위한 텍스트 분석의 일환이다
# 알맞은 순서대로 배열하시오
# ㄱ. 피처 벡터화/추출
# ㄴ. 머신러닝 모델 수립 및 학습/예측/평가
# ㄷ. 텍스트 전처리
ㄷ ㄱ ㄴ
from nltk import word_tokenize
from nltk.stem import PorterStemmer
text = "Now I am going to have dinner with my wife. Thanks for having me here."
# 위 text를 단어 토큰화 시켜주세요
words = word_tokenize(text)
stemmer = PorterStemmer()
li = []
for i in words:
li.append(stemmer.stem(i))
print(li)
[다른 방법]
porter = PorterStemmer()
[porter.stem(word) for word in words]
# PorterStemmer²
sentence = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop. "
# 를 토큰화하면 단어가 몇개 나오는가?
words = word_tokenize(sentence)
print(len(words))
print(words)
# 25
# ['do', "n't", 'be', 'fool', 'by', 'the', 'dark', 'sound', 'name', ',', 'mr.', 'jone', "'s", 'orphanag', 'is', 'as', 'cheeri', 'as', 'cheeri', 'goe', 'for', 'a', 'pastri', 'shop', '.']
[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 5 2 0]
[0 0 3 0 0 0]
[0 0 0 0 0 0]]
# 형태의 희소행렬을 만들어주세요
from scipy import sparse
# COO 형식
data = ([5,2,3])
row = ([2,2,3])
col = ([3,4,2])
print(sparse.coo_matrix((data, (row, col)), (5, 6)).toarray() )
# CSR 형식
data = [5, 2, 3]
row_index = [0, 0, 0, 2, 3, 3]
col = [3, 4, 2]
print(sparse.csr_matrix((data, col, row_index), (5, 6)).toarray() )
[근데!]
# COO형식과 동일하게 넣어줘도 csr_matrix로 원하는 출력물이 나와버린다.
# 뭐가 다른거지?
data = [5, 2, 3]
row_index = [2, 2, 3]
col = [3, 4, 2]
print(sparse.csr_matrix((data, col, row_index), (5, 6)).toarray() )
# 문서와 문서간의 유사도 비교는 일반적으로 _을 사용
코사인 유사도
# 문서 집합에 숨어있는 주제를 찾아내는 모델링 방법?
토픽 모델링
# 텍스트 분석 패키지 중 주로 소셜 미디어 텍스트에 대한 감성분석을 제공하고,
# 뛰어난 감성 분석 결과 및 빠른 수행시간으로 대용량 텍스트 데이터에 잘 사용되는 패키지는?
VADER
# 두 문장에서 같은 단어가 자주 나타나면 코사인 유사도가 높다/낮다
높다
# KMeans 객체의 clusters_centers 속성은 0에서 1의 값을 가지며 0에 가까울수록 중심에 가까운 값이다. (O,X)
x
[[1 2 0 0 0]
[0 0 0 0 0]
[0 0 4 5 2]
[0 0 0 0 0]
[0 0 3 0 0]]
# csr 형식으로 희소행렬을 만드세요
data = ([1, 2, 4, 5, 2, 3])
row = ([0, 0, 2, 2, 2, 4])
row_index = ([0, 2, 2, 5, 5, 6])
col = ([0, 1, 2, 3, 4, 2])
print(sparse.csr_matrix((data, col, row_index),).toarray())
추천시스템의 유형
크게 콘텐츠 기반 필터링(Content based filtering) 방식과 협업 필터링(Collaborative Filtering) 방식으로 나뉜다.
협업 필터링 방식은 다시 최근접 이웃 협업 필터링 과 잠재 요인(Latent Factor)으로 나뉜다.
콘텐츠 기반 필터링
사용자가 특정 아이템을 선호하는 경우 그와 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식이다. 예를 들어 트정 영화에 높은 평점을 줬다면 그 영화의 장르, 출연 배우, 감독, 영화 키워드 등의 콘텐츠와 유사한 다른 영화를 추천해주는 방식
실습 - TMDB 5000 영화 데이터 세트
실습에 이용할 캐글의 TMDB 5000 데이터는 유명한 영화 데이터 정보 사이트인 IMDB의 많은 영화 중 주요 5000개 영화에 대한 메타 정보를 새롭게 가공해 캐글에서 제공하는 데이터 셋이다.
데이터 불러오기
import pandas as pd
movies = pd.read_csv('./tmdb_5000_movies.csv')
movies[:3]
데이터 확인 및 가공
movies.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 budget 4803 non-null int64
1 genres 4803 non-null object
2 homepage 1712 non-null object
3 id 4803 non-null int64
4 keywords 4803 non-null object
5 original_language 4803 non-null object
6 original_title 4803 non-null object
7 overview 4800 non-null object
8 popularity 4803 non-null float64
9 production_companies 4803 non-null object
10 production_countries 4803 non-null object
11 release_date 4802 non-null object
12 revenue 4803 non-null int64
13 runtime 4801 non-null float64
14 spoken_languages 4803 non-null object
15 status 4803 non-null object
16 tagline 3959 non-null object
17 title 4803 non-null object
18 vote_average 4803 non-null float64
19 vote_count 4803 non-null int64
dtypes: float64(3), int64(4), object(13)
memory usage: 750.6+ KB4803개의 레코드와 20개의 피처로 구성되어 있는 모습이다. 영화 제목, 개요, 인기도 등 영화에 대한 다양한 메타 정보를 가지고 있는데 이중 콘텐츠 필터링 추천 분석에 사용할 주요 칼럼만 추출해 새롭게 DataFrame으로 만들자
추출할 주요 할럼은 genres(id, title, 영화의 여러 속성), vote_average(평균 평점), vote_count(평점 투표수), popularity(영화의 인기), keywork(영화를 설명하는 주요 문구), overview(영화 개요 설명)
# movies_df = movies.iloc[:, [3, 17, 1, 18, 19, 8, 4, 7]]
# movies_df
movies_df = movies[['id', 'title', 'genres', 'vote_average', 'vote_count', 'popularity', 'keywords', 'overview']]
movies_df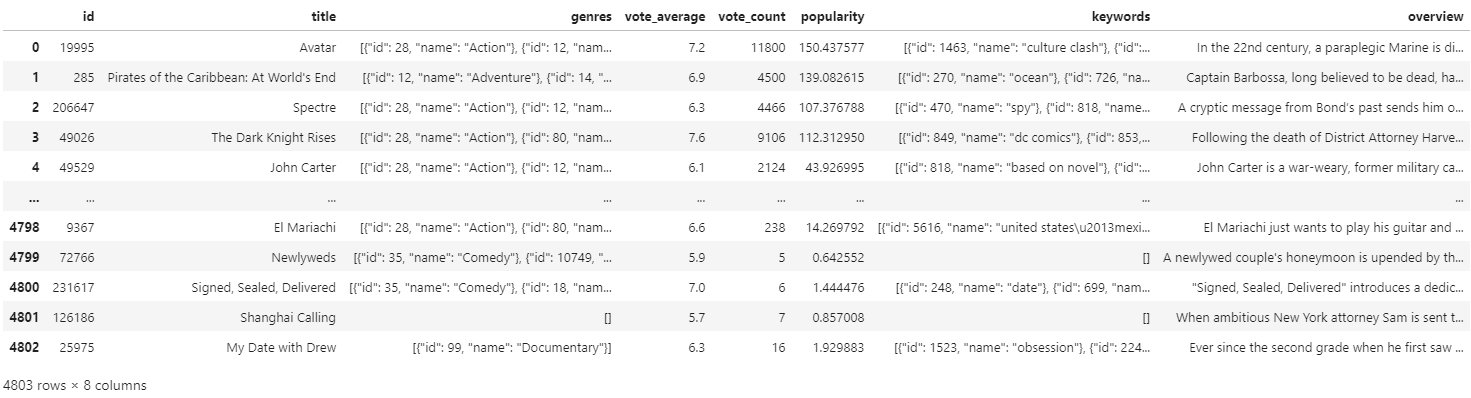
DataFrame을 살펴보면 주의해야할 칼럼이 있다. 'genres', 'keywords' 와 같은 칼럼을 보면
movies_df['keywords'][0]'[{"id": 1463, "name": "culture clash"}, {"id": 2964, "name": "future"}, {"id": 3386, "name": "space war"}, {"id": 3388, "name": "space colony"}, {"id": 3679, "name": "society"}, {"id": 3801, "name": "space travel"}, {"id": 9685, "name": "futuristic"}, {"id": 9840, "name": "romance"}, {"id": 9882, "name": "space"}, {"id": 9951, "name": "alien"}, {"id": 10148, "name": "tribe"}, {"id": 10158, "name": "alien planet"}, {"id": 10987, "name": "cgi"}, {"id": 11399, "name": "marine"}, {"id": 13065, "name": "soldier"}, {"id": 14643, "name": "battle"}, {"id": 14720, "name": "love affair"}, {"id": 165431, "name": "anti war"}, {"id": 193554, "name": "power relations"}, {"id": 206690, "name": "mind and soul"}, {"id": 209714, "name": "3d"}]'위와 같이 파이썬 리스트 내부에 여러개의 딕셔너리(dict)가 있는 형태의 문자열로 표기 되어 있는걸 확인할 수 있다. 이는 한번에 여러개의 값을 표현하기 위한 표기 방식으로 한 영화내에서도 장르는 여러개로 구성될 수 있기 때문에 이런 식으로 표현된 것이다.
따라서 이 칼럼들의 문자열을 분해해 개별 장르를 파이썬 리스트 객체로 추출하려 한다. ast 모듈의 literal_eval()¹ 함수를 이용한다.
from ast import literal_eval
# movies['genres']의 것이 apply안의 것에 영향을 받는다
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
movies_df['genres'][0][{'id': 28, 'name': 'Action'},
{'id': 12, 'name': 'Adventure'},
{'id': 14, 'name': 'Fantasy'},
{'id': 878, 'name': 'Science Fiction'}]이제 genres 칼럼은 문자열이 아니라 실제 리스트 내부에 여러 장르 '딕셔너리'로 구성된 객체를 가진다. 이제 여기서 name의 'Action', 'Adventure'과 같은 장르명만 리스트 객체로 추출하겠다
movies_df['genres'] = movies_df['genres'].apply(lambda x : [i['name'] for i in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x : [i['name'] for i in x])
movies_df['genres']0 [Action, Adventure, Fantasy, Science Fiction]
1 [Adventure, Fantasy, Action]
2 [Action, Adventure, Crime]
3 [Action, Crime, Drama, Thriller]
4 [Action, Adventure, Science Fiction]
...
4798 [Action, Crime, Thriller]
4799 [Comedy, Romance]
4800 [Comedy, Drama, Romance, TV Movie]
4801 []
4802 [Documentary]
Name: genres, Length: 4803, dtype: objectmovies_df['keywords']0 [culture clash, future, space war, space colon...
1 [ocean, drug abuse, exotic island, east india ...
2 [spy, based on novel, secret agent, sequel, mi...
3 [dc comics, crime fighter, terrorist, secret i...
4 [based on novel, mars, medallion, space travel...
...
4798 [united states–mexico barrier, legs, arms, pap...
4799 []
4800 [date, love at first sight, narration, investi...
4801 []
4802 [obsession, camcorder, crush, dream girl]
Name: keywords, Length: 4803, dtype: object장르 콘텐츠 유사도 측정
현재 여러개의 개별장르가 리스트로 구성되어 있는 genres 칼럼으로 장르별 유사도를 측정하는 가장 간단한 방법은 무엇일까? 아마 문자열로 변경한 뒤 이를 CountVectorizer로 피처 벡터화 한 후, 행렬 데이터 값을 코사인 유사도로 비교하는 것일 것이다.
리스트 객체 내의 개별 값을 연속된 문자열로 변환하려면 일반적으로 '구분문자'.join(리스트 객체)를 사용하면 된다.
# CountVectorizer를 적용하기 위해 공백 문자로 word 단위가 구분되는 문자열로 반환
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x: ' '.join(x))
movies_df['genres_literal']0 Action Adventure Fantasy Science Fiction
1 Adventure Fantasy Action
2 Action Adventure Crime
3 Action Crime Drama Thriller
4 Action Adventure Science Fiction
...
4798 Action Crime Thriller
4799 Comedy Romance
4800 Comedy Drama Romance TV Movie
4801
4802 Documentary
Name: genres_literal, Length: 4803, dtype: objectfrom sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
print(genre_mat.shape)(4803, 276)리스트 객체를 문자열로 변경후 Count 피처 벡터화를 적용했다. 사이킷런의 cosine_similarity() 함수는 기준행과 비교행의 코사인 유사도를 행렬 형태로 반환하는 함수이다. 이를 이용해 장르 유사도 행렬을 생성한 후 피처 벡터화된 행렬에 아래와 같이 적용해 볼 수 있다.
from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)
print(genre_sim.shape)
print(genre_sim[:2])(4803, 4803)
[[1. 0.59628479 0.4472136 ... 0. 0. 0. ]
[0.59628479 1. 0.4 ... 0. 0. 0. ]]genre_mat을 기준으로 genre_mat을 비교했기 때문에 하나하나 전체를 비교해준다.
cosine_similarity 호출로 생성된 genre_sim 객체는 movies_df이 genre_literal 칼럼을 피처 벡터화할 행렬genre_mat) 데이터의 행(레코드)별 유사도를 가지고 있으며, 이는 결국 movies_df DataFrame의 행별 장르 유사도를 가지고 있는 것이 된다.
이제 기준 행별로 비교 대상이 되는 행의 유사도 값이 높은 순으로 정렬된 행렬의 위치 인덱스 값을 추출해보자. 값이 높은 순으로 정렬된 비교 대상 행의 유사도 '값'이 아니라 비교대상 행의 '위치 인덱스'임을 또 한번 주의하자. 넘파이의 argsort()[:, ::-1]함수를 이용하면 유사도가 높은 순으로 정리된 genre_sim 객체의 비교 행 위치 인덱스 값을 가져온다
(예시)
a = np.array([11, 10, 13, 25])
np.argsort(a)array([1, 0, 2, 3], dtype=int64)0번 레코드의 비교 행 위치 인덱스 값만 샘플로 추출해보자
genre_sim_sorted = genre_sim.argsort()[:, ::-1][:1]
genre_sim_sortedarray([[ 0, 3494, 813, ..., 3038, 3037, 2401]], dtype=int64)장르 콘텐츠 필터링을 이용한 영화 추천
장르 유사도에 따라 영화를 추천하는 함수를 생성하자. 인자로 기반 데이터인 movies_df DataFrame, 레코드별 장르 코사인 유사도 인덱스를 가지고 있는 genre_sim_sorted_ind, 고객이 선정한 추천 기준이 되는 영화 제목, 추천할 영화 건수를 입력하면 추천 영화 정보를 가지는 DataFrame을 반환한다.
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
# 인자로 입력된 movies_df DataFrame에서 'title' 컬럼이 입력된 title_name 값인 DataFrame추출
title_movie = df[df['title'] == title_name]
# title_named을 가진 DataFrame의 index 객체를 ndarray로 반환하고
# sorted_ind 인자로 입력된 genre_sim_sorted_ind 객체에서 유사도 순으로 top_n 개의 index 추출
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n)]
# 추출된 top_n index들 출력. top_n index는 2차원 데이터 임.
#dataframe에서 index로 사용하기 위해서 1차원 array로 변경
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes] 영화를 평점순으로 정렬해보려 한다. 유명한 영화가 아님에도 평가 횟수는 적고 점수는 높아 평점이 높은 경우가 있다. 평가 회수와 평점을 모두 고려해 가중치가 부여된 평점(Weighted Rating) 방식을 사용해보자
가중평점의 공식은 아래와 같다
가중 평점(Weighted Rating) = v/(v+m)) * R + (m/(m+v)) * C
v : 개별 영화에 평점을 투표한 횟수
m : 평점을 부여하기 위한 최소 투표 회수
R : 개별 영화에 대한 평균 평점
C : 전체 영화에 대한 평균 평점여기서 V는 movies_df의 'vote_count'값이며, R값은 'vote_average' 값에 해당한다
C = movies_df['vote_average'].mean()
# 상위 60%
m = movies_df['vote_count'].quantile(0.6)
print(f'C : {round(C, 3)}, m : {round(m, 3)}')C : 6.092, m : 370.2기존 평점을 새로운 가중 평점으로 변경하는 함수를 생성하고 이를 이용해 새로운 평점정보인 'vote_weighted'값을 만들으려 한다.
percentile = 0.6
def weighted_vote_average(record) :
v = record['vote_count']
R = record['vote_average']
return ((v/(v+m))*R) + ((m/(m+v))*C)
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df['weighted_vote']0 7.166301
1 6.838594
2 6.284091
3 7.541095
4 6.098838
...
4798 6.290894
4799 6.089611
4800 6.106650
4801 6.084894
4802 6.100782
Name: weighted_vote, Length: 4803, dtype: float64이제 새롭게 부여된 'weighted_vote'평점이 높은 순으로 상위 10개의 영화 추출
movies_df[['title', 'vote_average', 'weighted_vote', 'vote_count']]\
.sort_values('weighted_vote', ascending=False)[:10]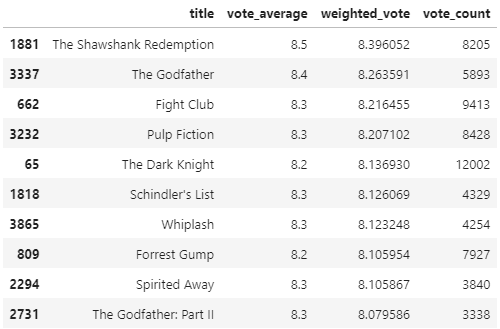
새롭게 정의된 평점 기준에 따라 영화를 추천해보기로 한다.
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
# top_n의 2배에 해당하는 쟝르 유사성이 높은 index 추출
similar_indexes = sorted_ind[title_index, :(top_n*2)]
similar_indexes = similar_indexes.reshape(-1)
# 기준 영화 index는 제외
similar_indexes = similar_indexes[similar_indexes != title_index]
# top_n의 2배에 해당하는 후보군에서 weighted_vote 높은 순으로 top_n 만큼 추출
return df.iloc[similar_indexes].sort_values('weighted_vote', ascending=False)[:top_n]
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average', 'weighted_vote']] 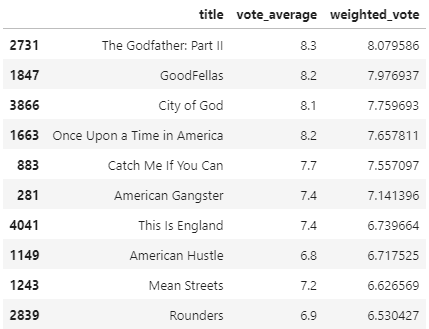
협업 필터링
사용자가 아이템에 매긴 평점 정보나 상품 구매 이력과 같은 '사용자 행동 양식(User Behavior)'만을 기반으로 추천을 수행하는 것이 협업 필터링(collaborative Filtering)이다.
최근접 이웃 협업 필터링과 잠재 요인 협업 필터링으로 나뉜다. 협업 필터링은 사용자가 매긴 평점이나 상품 구매 이력 등 사용자의 행동 양식만을 기반으로 추천하는 방식. 주된 목표는
최근접 이웃 협업 필터링
일반적으로 사용자 기반과 아이템 기반으로 다시 나눠볼 수 있다.
- 사용자 기반 : 사용자-사용자 / 나와 비슷한 성향의 사람이 재미있게 본 영화등을 추천하는 방식
- 아이템 기반 : 아이템에 대한 평가가 유사한 아이템을 추천하는 방식. 일반적으로 사용자 기반보다 정확도가 더 높다고 한다.
아이템 기반 실습
데이터 불러오기
import pandas as pd
import numpy as np
movies = pd.read_csv('./ml-latest-small/ml-latest-small/movies.csv')
ratings = pd.read_csv('./ml-latest-small/ml-latest-small/ratings.csv')
movies[:3]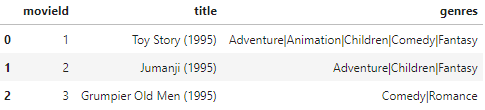
ratings[:3]
movies 파일은 영화의 제목과 장르 정보를, rating 파일은 사용자 별 영화에 대한 평점 정보를 가지고 있다. 평점은 0.5 ~ 5점 사이로 매겨져 있으며, 두 파일은 movieId로 연결하여 살펴볼 수 있을 것 같다.
협업 필터링은 이 'ratings' 파일 같이 사용자와 아이템 간 평점(혹은 별점 같은 유형의 액션)에 기반하여 추천하는 시스템이다. 이를 이용하여 아이템 기반 최근접 이웃 협업 필터링을 구현해보려면 먼저 행(row) 레벨 형태의 원본 데이터 세트를 다음 그림과 같이 모든 사용자를 로우로, 모든 영화를 칼럼으로 구성한 데이터 셋으로 변경해야 한다.
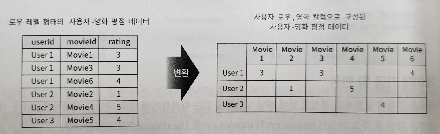
이와 같은 변환은 DataFrame의 pivot_table()함수를 이용하면 된다.
→ 결론적으로 컬럼이 movieId여서 무슨 영화인지 직관적으로 알아보기 힘들어 이름을 변경한다.
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
ratings_matrix[:3]
pivot_table을 적용한 후에 movieId 값이 칼럼명으로 변환 되었다.
# title 칼럼을 얻기 위해 movies와 조인
rating_movies = pd.merge(ratings, movies, on='movieId')
# columns='title'로 피벗 수행
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# NaN 값을 모두 0으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix[:3]
영화 간 유사도 산출
변환된 사용자-영화 평점 행렬 데이터 셋을 이용해 유사도를 측정하려 한다. 영화간 유사도는 코사인 유사도를 기반으로 하여 cosine_similarity()를 이용해 측정할 것이다. 이 함수는 행을 기준으로 비교해 유사도를 산출하는데 현재 ratings_matrix는 userId 가 기준인 행 레벨 데이터 이므로 전히 해준다.
ratings_matrix = ratings_matrix.T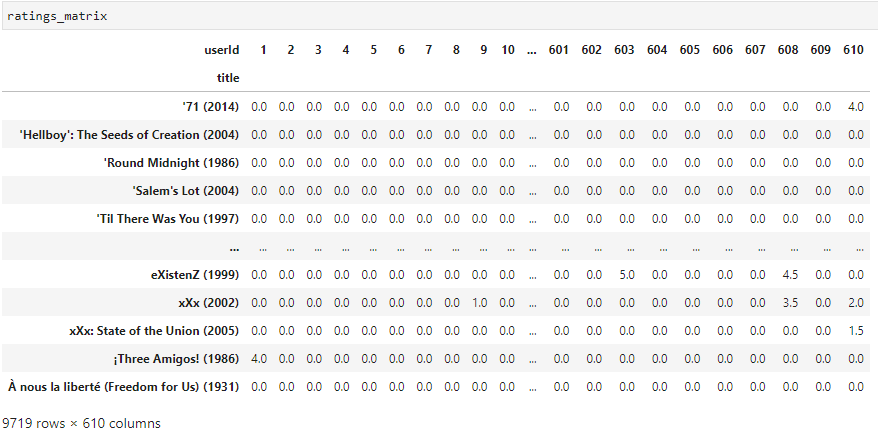
이제 코사인 유사도 값을 구해보자
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix, ratings_matrix)
item_sim_df = pd.DataFrame(data=item_sim, index=rating_matrix.columns, columns=rating_matrix.columns)
print(item_sim_df.shape)(9719, 9719)item_sim_df[:3]
유사도 행렬 데이터 프레임인 item_sim_df가 생성되었다. 이를 이용해 대부와 유사도가 높은 상위 6개 영화를 추출해보면
item_sim_df["Godfather, The (1972)"].sort_values(ascending=False)[:6]title
Godfather, The (1972) 1.000000
Godfather: Part II, The (1974) 0.821773
Goodfellas (1990) 0.664841
One Flew Over the Cuckoo's Nest (1975) 0.620536
Star Wars: Episode IV - A New Hope (1977) 0.595317
Fargo (1996) 0.588614
Name: Godfather, The (1972), dtype: float64아무래도 본인이 포함되는건 정확한 결과가 아니라고 생각되어 (유사도 100이니가) 슬라이싱을 다시 해줌
item_sim_df["Godfather, The (1972)"].sort_values(ascending=False)[1:7]title
Godfather: Part II, The (1974) 0.821773
Goodfellas (1990) 0.664841
One Flew Over the Cuckoo's Nest (1975) 0.620536
Star Wars: Episode IV - A New Hope (1977) 0.595317
Fargo (1996) 0.588614
Star Wars: Episode V - The Empire Strikes Back (1980) 0.586030
Name: Godfather, The (1972), dtype: float64대부 2편이 가장 유사도가 높다는 결과가 나왔으며 스타워즈와 같이 장르가 완전히 다른 영화도 높게 나왔다는 건 의아할 수도 있지만, 평점에 따른 유사도 이기때문에 이런 결과가 나올 수 있었다.
영화 추천
이제 이 데이터로 영화추천이 가능하지 않을까? 최근접 이웃 협업 필터링으로 개인에게 맞는 영화추천을 구현해봐야한다. 개인이 아직 관람하지 않은 영화와 아이템 유사도와 기존에 관람앴던 영화의 평점 데이터를 기반으로 하여 아예 새로운 영와 예측 평점을 계산, 높은 예측 평점을 가진 영화를 개인에게 추천하는 방식으로 진행해 볼 것이다.
아이템 기반 협업 필터링에서 개인화된 예측 평점은 아래와 같은 식으로 구해볼 수 있다.
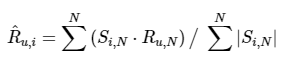
^Ru,i : 사용자 u, 아이템 i의 개인화된 예측 평점 값
Si,N : 아이템 i와 가장 유사도가 높은 Top-N개 아이템의 유사도 벡터
Ru,N : 사용자 u의 아이템 i와 가장 유사도가 높은 Top-N개 아이템에 대한 실제 평점 벡터
N : 아이템의 최근접 이웃 범위 계수로 유사도가 가장 높은 Top-N개의 아이템을 추출하는데 사용N의 범위에 제약을 두지 않는다면 사용자별 영화 예측 평점(Ru,i)는 사용자 u의 모든 영화에 대한 실제 평점과 영화 i의 다른 모든 영화와의 코사인 튜사도를 벡터 내적 곱(dot)한 값을 정규화를 위해 ∑n(|Si,n|)으로 나눈것을 의미한다. 말로 하니 너무 복잡한데 아래와 같은 코드로 구현해볼 수 있다.
def predict_rating(ratings_arr, item_sim_arr) :
ratings_pred = ratings_arr.dot(item_sim_arr)/np.array([np.abs(item_sim_arr).sum(axis=1)])
return ratings_pred사용자별 예측 평점 함수를 생성해주었다. 이제 이를 이용해 개인화된 예측 평점을 구해보면
# 모양을 맞춰줘야 하기 때문에 다시 전치해주었다.
ratings_matrix = ratings_matrix.T
ratigns_pred = predict_rating(ratings_matrix.values, item_sim_df.values)
ratings_pred_matrix = pd.DataFrame(data=ratigns_pred, index=rating_matrix.index, columns = rating_matrix.columns)
ratings_pred_matrix[:3]
사용자별 영화의 실제 평점과 영화의 코사인 유사도를 내적(dot)한 값이기 때문에 기존에 영화를 관람하지 않아 0에 해당했던 평점이 예측에서는 값이 부여될 수도 있다. 이는 내적 결과를 코사인 유사도 벡터합으로 나누었기 때문에 생기는 현상
예측 성능 평가 함수
평점이 있는 실제 영화만 추출하려 한다. NaN값은 영화 평점이 없는 것이기 때문에 0으로 변환해주려 한다. 배열의 nonzero()를 이용해주었다.
from sklearn.metrics import mean_squared_error
# 사용자가 평점을 부여한 영화에 대해서만 예측 성능 평가 MSE를 구할 것이다
def get_mse(pred, actual) :
# 평점이 있는 실제 영화만 추출
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
MSE1 = get_mse(ratigns_pred, ratings_matrix.values)
print(f'아이템 기반 모든 인접 이웃 MSE: {MSE1:.4f}')아이템 기반 모든 인접 이웃 MSE: 9.8954교재는 ratings_pred인데 ratigns_pred로 오타낸걸 이제야 봤다. 하지만 변수 명이니 그냥 진행하도록 하겠다ㅎ
MSE는 약 9.89의 결과가 도출되었다. 상대적으로 값이 크고 예측이 떨어지는 결과를 보였으니 MSE를 감소시키는 방향으로 개선해보자.
def predict_rating_topsim(ratings_arr, item_sim_arr, N=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기(아이템 수)만큼 반복 (row: 사용자, col: 아이템)
for col in range(ratings_arr.shape[1]):
# 특정 아이템의 유사도 행렬 오름차순 정렬시 index
# 를 역순으로 나열시 상위 N개의 index = 특정 아이템의 유사도 상위 N개 아이템 인덱스 반환
temp = np.argsort(item_sim_arr[:, col])
top_n_items = [ temp[:-1-N:-1] ]
# 개인화된 예측 평점을 계산: 반복당 특정 아이템의 예측 평점(사용자 전체)
for row in range(ratings_arr.shape[0]):
# 유사도 행렬
item_sim_arr_topN = item_sim_arr[col, :][top_n_items].T # N x 1
# 실제 평점 행렬
ratings_arr_topN = ratings_arr[row, :][top_n_items] # 1 x N
# 예측 평점
pred[row, col] = ratings_arr_topN @ item_sim_arr_topN
pred[row, col] /= np.sum( np.abs(item_sim_arr_topN) )
return pred만들어준 predict_rating_topsim(ratings_arr, item_sim_arr, N=20) 함수는 N인자를 가지고 있어서 TOP-N 유사도 벡터의 예측값을 계산하는데 적용할 수 있다.
# 사용자별 예측 평점
ratings_pred = predict_rating_topsim(ratings_matrix.values , item_sim_df.values, N=20)
# 성능 평가
MSE2 = get_mse(ratings_pred, ratings_matrix.values )
print(f'아이템 기반 인접 TOP-20 이웃 MSE: {MSE2:.4f}')
# 예측 평점 데이터 프레임
ratings_pred_matrix = pd.DataFrame(data=ratigns_pred, index= ratings_matrix.index, columns = ratings_matrix.columns)아이템 기반 인접 TOP-20 이웃 MSE: 3.6950MSE 가 좀 전에 9대가 나왔던 거에 비하면 현재 3.69로 많이 향상된 모습니다.
# userId 9가 높은 평점을 준 영화 (실제 평점)
user_rating_id = ratings_matrix.loc[9, :]
user_rating_id[ user_rating_id > 0].sort_values(ascending=False)[:10]userID 9번이 높은 평점을 준 Top-10의 영화를 뽑아보았다. 이 영화들이 userId 9번이 좋아하는 영화들인 것이다. 이제 9번 유저가 이미 평점을 준(이미 본) 영화를 제외하고 추천할 수 있도록 평점을 주지 않은 영화를 리스트 객체로 반환하는 함수를 만들어보자
# 아직 보지 않은 영화 리스트 함수
def get_unseen_movies(ratings_matrix, userId):
# user_rating: userId의 아이템 평점 정보 (시리즈 형태: title을 index로 가진다.)
user_rating = ratings_matrix.loc[userId,:]
# user_rating=0인 아직 안본 영화
unseen_movie_list = user_rating[ user_rating == 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# 한줄 for + if문으로 안본 영화 리스트 생성
unseen_list = [ movie for movie in movies_list if movie in unseen_movie_list]
return unseen_list
# 보지 않은 영화 중 예측 높은 순서로 시리즈 반환
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 아직 보지 않은 영화 리스트
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 최근접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 데이터 프레임 생성
recomm_movies = pd.DataFrame(data=recomm_movies.values, index=recomm_movies.index, columns=['pred_score'])
recomm_movies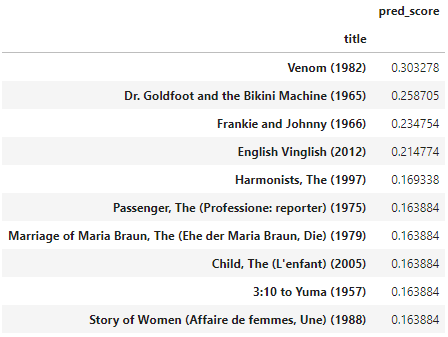
다양하고 흥행성이 높은 작품들이 추천되었다.
literal_eval¹
문자열을 문자열이 의미하는 list [dict1, dict2] 객체로 만들수 있다. Series 객체의 apply()에 이 함수를 적용하면 문자열을 객체로 변환한다.
→ 딕셔너리 형태를 가진 '문자열'을 딕셔너리로 변환시켜준다
import ast
str_dict = "{'key_1': 'value_1', 'key_2': 'value_2'}"
# str_dict는 딕셔너리 형태를 가진 문자열임
real_dict = ast.literal_eval(str_dict)
# real_dict는 딕셔너리 형태로 변환되었기 때문에 key-value를 사용할 수 있음PorterStemmer²
영어 동사를 예로 들었을 때, 굴절어미인 -s, -ing, -(e)d 등을 제거하여 어간(stem)만을 추출해내기 위한 도구가 Stemmer라고 이전에 공부했다. 그 중 가장 유명한 것이 1980년도에 Porter씨가 제안한 PorterStemmer라 한다.
다른 stemmer들과 마찬가지로 자연어 처리 라이브러리인 NLTK에서 제공한다.