A
1.0824 - R
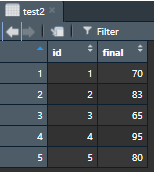
🌱 데이터 읽어오기와 저장 설치 엑셀 읽을 패키지와 라이브러리 설치 읽기 엑셀 csv 파일로 저장 먼저 값이 너무 많으니까 6열 까지만 df에 저장 저장 실행시 파일 이름이 한글인 경우 안읽히는 경우가 있다. 이럴때는 read.csv()나 read.tab
2.0825 - R
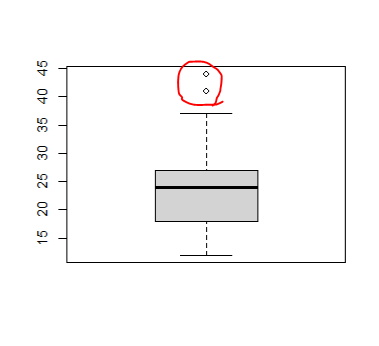
자료가 누락되어있는 상태출력시 NA라 표시된다어떤 분석이나 통계 등을 할때 결측치가 많으면 결과를 신뢰하기 힘들어지기 때문에, 영향이 크다mean(df$score, na.rm = T)1 4sum(df$score, na.rm = T)1 16mean(air$Ozone, n
3.0826 - R
g + labs(title="<배기량 연비비교>")x와 y에도 달아주기 당연 가능g + labs(title="<배기량 연비비교>", x="배기량", y="고속도로 연비")g + labs(title="배기량 연비비교") + xlab("배기량") + ylab(
4.0829 - R
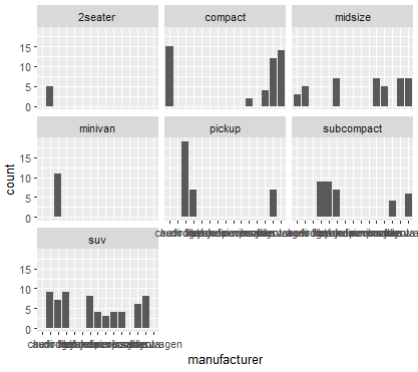
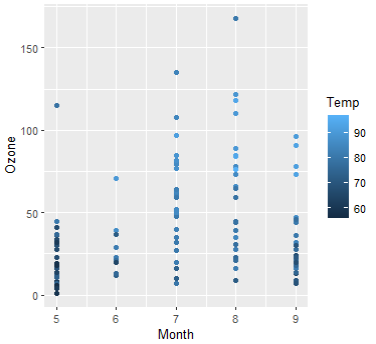
gapminder data국가별 경제 수준과 의료 수준 동향을 정리한 DataSet으로 세계 각국의 기대수명, 1인당 국내총생산, 인구 데이터 등을 집계해놓은 것이다.bar 형태로 출력해보기박스플롯 형태로 출력해보기범례(=legend)를 제거하고 싶을 때가 있다.위 그
5.0830 - R
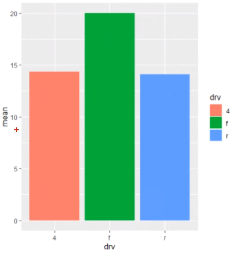
한국복지패널 데이터를 활용한 분석 문제데이터 타입보기class(welfare$birth)table(welfare$birth)1907 1911 1914 1915 1917 1918 1919 1920 1921 1 1 1 1 1 3 5
6.0831 - R
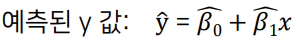
복습문제
7.0901 - Python
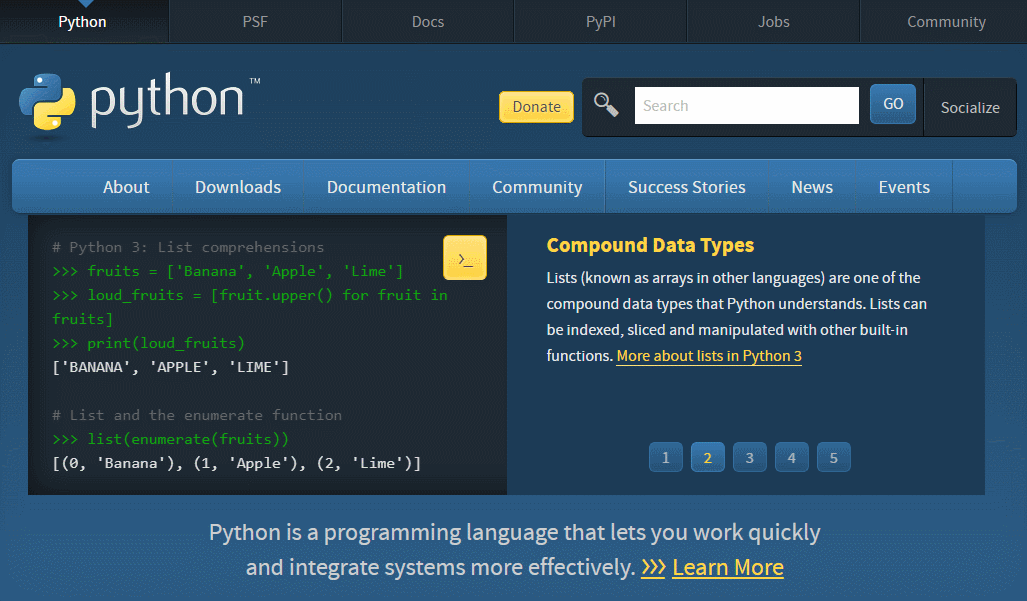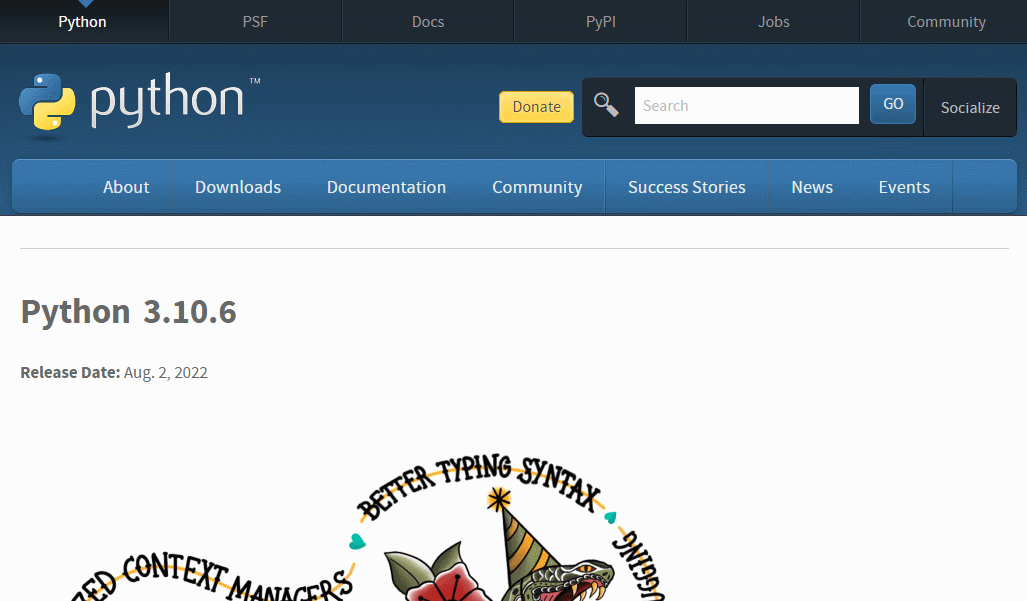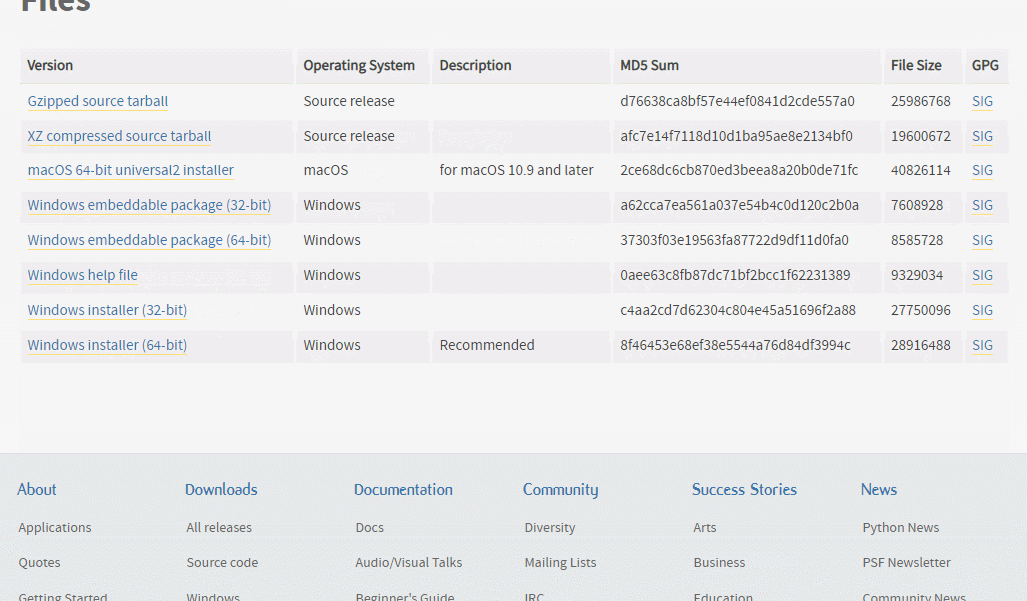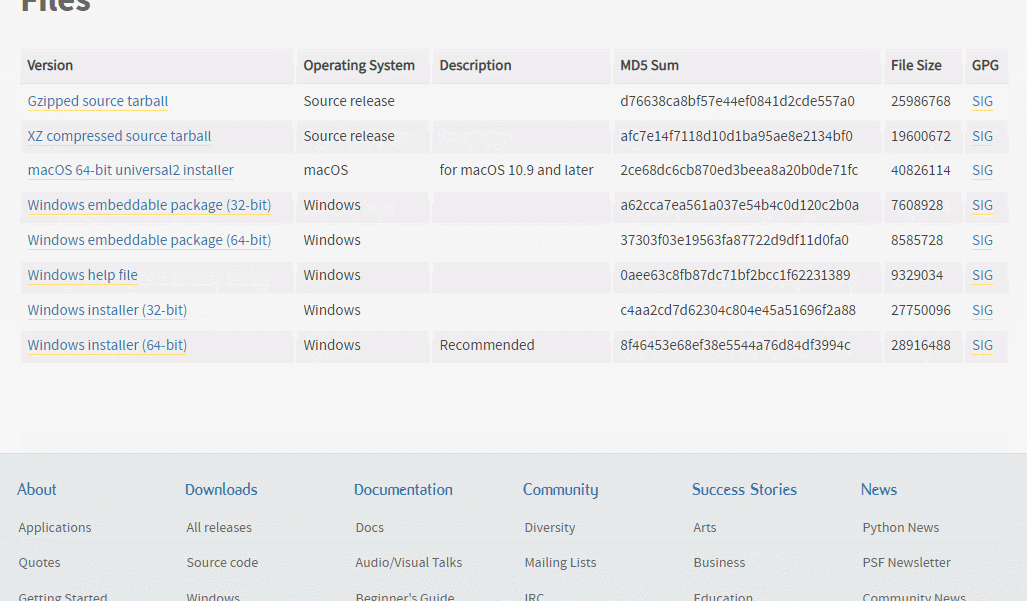
주로 코랩에서 확인을 할 것 같지만파이썬 공식 홈페이지의 다운로드 페이지1) 다운로드할 버젼 다운로드2) 인스톨러 실행3) 설치 완료 후을 실행해도 되고 cmd에서 python을 선택해도 된다1) pip를 이용해 주피터랩 설치pip install jupyterlab2)
8.0902 - Python
문제를 풀다보니 갑자기 min, max 함수가 작동하지 않는 일이 있었다.TypeError: 'int' object is not callable<에러 발생 원인>해당 오류가 발생한 이유는 예약어를 변수명으로 사용 하였기 때문이였다. 예약어들은 각각의 기능들이 있는
9.0905 - Python

복습문제 용어의 혼용 많이 사용되는 혼용 입력값 = 함수의 인수 = 매개변수 결과값 = 출력값 = 반환값 문제 함수 lambda 백준 reverse, reversed 파이썬 reverse, reversed의 차이 reverse() 값을 반환하지 않는다. li
10.0907 - Python

파일을 생성하기 위해 내장함수 open을 사용해볼 것이다.파일 객체 = open(파일이름, 파일 열기 모드)파일 열기 모드에는 다음과 같은 것이 있다r : 읽기모드w : 쓰기모드a : 추가모드만약 이미 있는 파일을 쓰기모드로 열 경우, 이미 존재하던 내용이 모두 사라지
11.0908 - Python
복습문제 클래스 변수 클래스 안에 변수를 선언하여 생성하는 것 오류없이 접근이 가능하다. 함수가 아니기때문에 ()표기는 하지 않는다. [특징] 클래스 변수는 클래스로 만든 모든 객체에 공유된다는 특징이 있다. 내부 함수에서 self로 접근할 수도 있다. 아래에서
12.0913 - Python
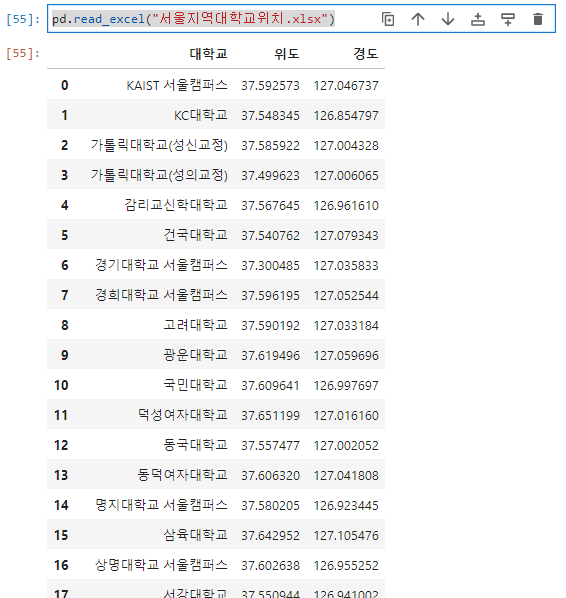
int : 안에 들어온 값을 정수형태로 돌려주는 함수int(x, 진수단위) : radix 진수로 표현된 문자열 x를 10진수로 변환하여 돌려준다isinstance(object, class) : 첫번째 인수로 인스턴스 명, 두번째 인수로 클래스 이름을 받는다. 입력으로
13.0914 - Python
복습문제 문제 하위 디렉토리에 있는 py파일을 검색하는 함수 만들기 (jupyter lab) 🌱 정규표현식 정규식을 연습하거나 테스트를 해볼 수 있다 ( RegExr ) re 모듈 re모듈은 파이썬을 설치할 때 자동으로 설치되는 기본 라이브러리 이다. re.co
14.0915 - Python
match()객체를 사용하다보면 궁금할 수 있다. 어떤 문자열이 매치되었는가. 이때 사용할 수 있는 메서드가 있다1) 전화번호 골라내기2) 문자열에서 span()메타문자 dot(.)은 \\n을 제외한 모든 문자와 매치된다는 규칙이 있다. 그런데 만약 \\n도 포함하여
15.0916 - Python
복습문제 문제 다음 긁어서 내용만 간추려보기 아래 문자열 text 에서 ['http:', 'https:', 'ftp:'] 리스트를 뽑아주세요 ['50.24', '35.25', '100'] 만 뽑아주세요 numpy 과학계산을 위한 라이브러리로 행렬/배열 처리 및
16.0919 - Python
복습문제 Broadcasting 일반적으로 numpy 에서는 shape가 다른 배열끼리의 연산이 불가능하다. 하지만 조건을 맞춘다면 모양이 다른 배열끼리도 연산을 수행할 수 있는데 이를 Broadcasting 이라 한다. 부족한 부분은 알아서 확장하여, 더 작은 배열
17.0920 - Python
복습문제 파일과 운영체제 파일을 읽고 쓰기 위해 열 때는 내장함수인 open을 이용하여 파일의 상대경로나 절대 경로를 넘겨주어야 한다. 기본적으로 파일은 읽기 전용 모드인 'r'로 열린다. 파일 핸들 f를 리스트로 생각할 수 있으며 파일의 매 줄을 순회할 수 있다.
18.0921 - Python
복습문제 유니버셜 함수 배열의 각 원소를 빠르게 처리하는 함수를 유니버셜 함수라 부른다. ufunc라고 불리기도 하는데, ndarray 안에 있는 데이터 원소별로 연산을 수행한다. 단항 유니버셜 함수는 간단한 변형을 전체 원소에 적용할 수 있다. 이항 유니버셜 함수
19.0922 - Python
복습문제 np.random.? numpy의 np.random 에는 여러 함수들이 있는데 (numpy 페이지) 이 중 몇가지만 살펴보려 한다. np.random.rand 0부터 1 사이의 균일 분포, 균등분포라고 불리는 난수 matrix array를 생성한다. 그냥 r
20.0923 - Python
복습문제 relplot? 산점도(scatterplot()) 와 lineplot()의 상위 개념 함수이다. relplot()을 이용하면 산점도와 선 그래프 모두를 그릴 수 있고, 두 그래프의 문법을 그대로 다 사용할 수 있다. 단지 scatter plot을 그리고 싶다
21.0926 - Python
복습문제 enumerate 열거하다라는 뜻으로 순서가 있는 자료형(리스트, 튜플, 문자열)을 받아 인덱스 값을 포함하는 객체를 돌려준다. (0908 - Python) 리스트 표기법(List Comprehension) 간결한 표현으로 새로운 리스트를 만들 수 있다
22.0927 - Python
복습 문제
23.0928 - Python
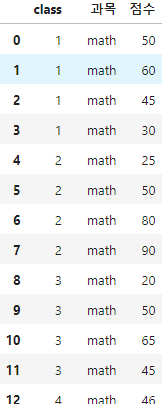
복습문제 데이터 형태 변환하기 컬럼 하나 추가하기 Series의 map 메서드 사전류 객체나 어떤 함수를 받을 수 있다. 값 치환하기 fillna 메서드가 누락된 값을 채우는 값 치환 작업이라면, replace 메서드는 같은 작업에 대해 좀 더 간단하고 유연한
24.0929 - Python
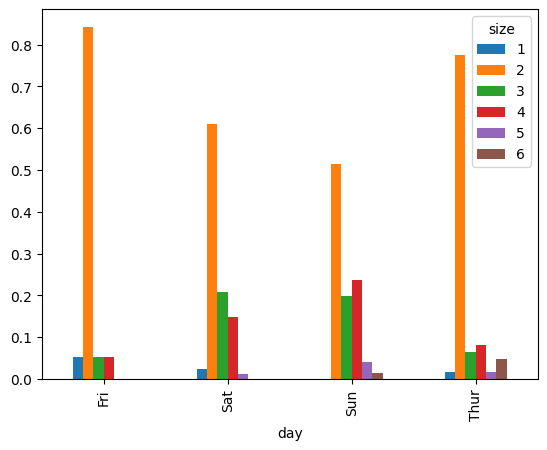
위 결과를 보면 알겠지만 matplot에서는 x축을 정해줘도 되지만, 기본적(자동)으로 x축은 index로 잡혀있다.그리기 전에 요약을 해야하는 데이터는 seaborn 패키지를 이용하면 헐씬 간단히 처리 가능하다다양한 범주형 값을 가지는 데이터를 시각화하는 한가지 방법
25.0930 - Python
복습 문제 피벗 테이블 스페레드시트 프로그램과 그 외 다른 데이터 분석 소프트웨어에서 흔히 볼 수 있는 데이터 요약화 도구. 데이터를 하나 이상의 키로 수집해 어떤 키는 로우에, 어떤 키는 컬럼에 나열하며 데이터를 정렬한다. pandas에서의 피벗테이블은 grou
26.1004 - Python
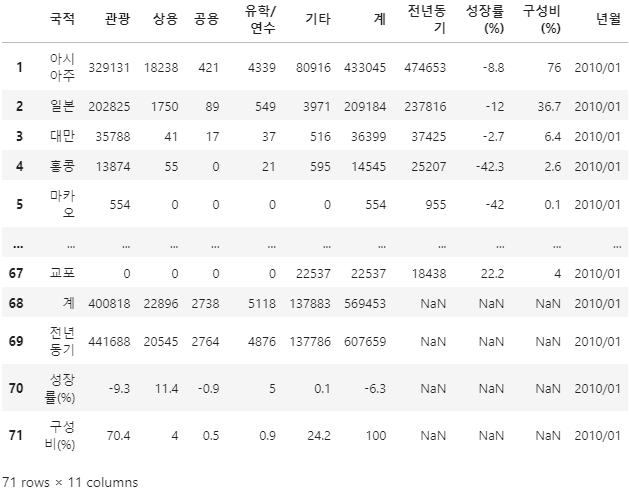
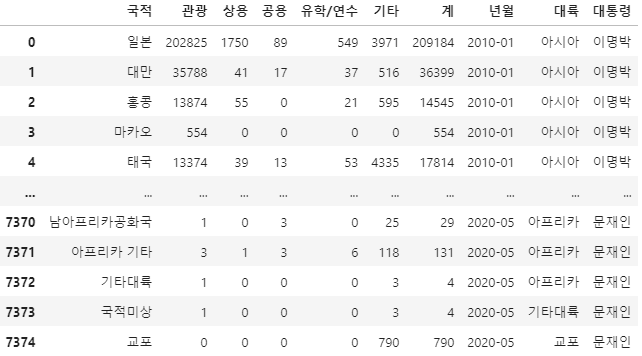
파일 읽어오기파이 결합하기concat으로 해줘도 되는데.. 뭔가 중복되는 게 있을 것만 같아서 combine_first 로 해주었다세어보기카카오 API 접속테스트위 경도 가져오기7DataFrame배경이 될 제주 지도 만들기MarkerCluster 찍기Pandas 기초
27.1005 - Python
복습문제 Seaborn 으로 heatmap 그리기 heatmap 데이터의 배열을 색상으로 표현해주는 그래프 두 개의 카테고리 값에 대한 값 변화를 한눈에 알기 쉽다. 대용량 데이터도 heatmap을 사용하여 시각화한다면 이미지 몇 장으로 표현이 가능하다 필요 모듈과
28.1006 - Python
복습문제
29.1007 - 머신러닝

복습문제 scikit-learn 설치하기 환경 : jupyter lab 붓꽃 품종 분류하기 data set 을 train data 와 test data로 분류 학습 데이터를 기반으로 머신러닝 알고리즘을 적용해 모델 학습 학습된 머신러닝 모델을 이용하여 data se
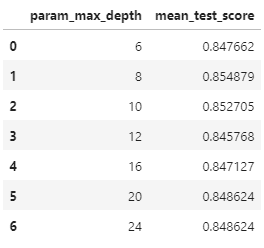
30.1011 - 머신러닝
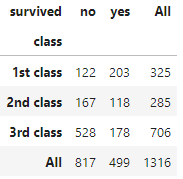
(위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다.)머신러닝 알고리즘은 데이터를 기반으로 하고 있기 때문에 어떤 데이터를 가지느냐에 따라 결과가 크게 달라질 수 있다. 따라서 데이터 전처리는 알고리즘만큼 중요한 부분.결손값, NaN, Null
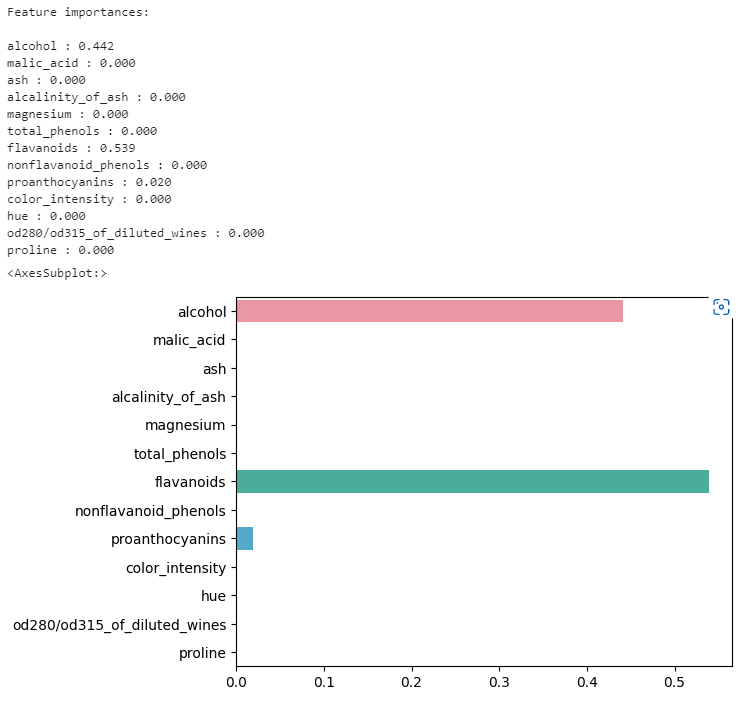
31.1012 - 머신러닝
데이터를 살펴보며 해줬던 전처리들을 한번에 모아 처리해주는 함수 transform_features(df) 를 만들어준다.이후 정답값이라 할 수 있는 Survived 속성만 별도로 분리해 클래스 결정값 데이터 셋으로 만들어준다.train data set을 기반으로 tra
32.1013 - 머신러닝
복습문제 (위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다.) 피마 인디언 당뇨병 예측 먼저 이전에 사용한 getclfeval()함수에 AOC AUC 값을 측정하는 로직을 추가하면서, 함수의 인자를 늘려준다. 사용할 라이브러리들 로드
33.1013 - 머신러닝
(위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다.)여러개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 하는 기법. 전통적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 세 가지로 나눌 수 있
34.1017 - 머신러닝
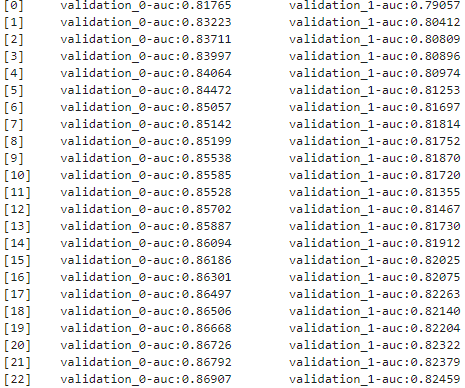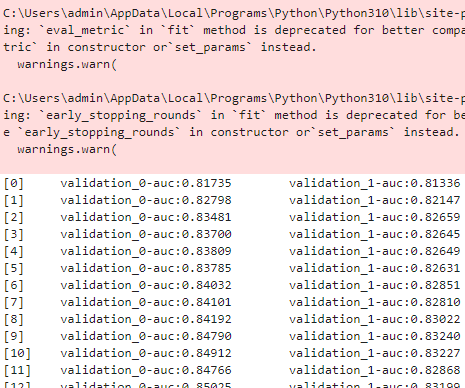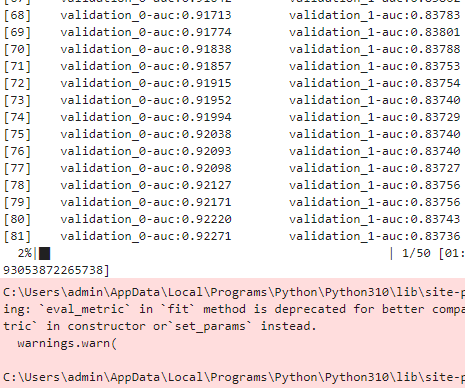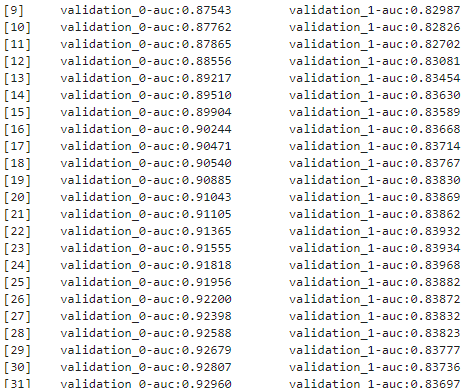
복습 LightGBM XGBoost와 동일하게 조기 중단(early stopping)이 가능하다. XGBClassifier와 동일하게 LGBMClassifier의 fit()에 조기 중단 관련 파라미터를 설정해주면 된다. [장단점] XGB보다 학습에 걸리는 시간이 훨
35.1018 - 머신러닝
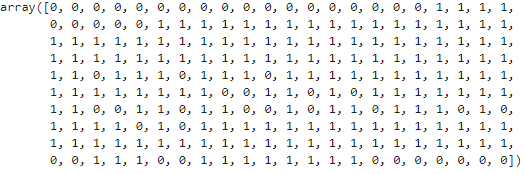
위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다. 실습 과정과 이해에 따라 내용의 누락 및 코드의 변형이 있을 수 있습니다.레이블이 불균형한 분포를 가진 Data set를 학습 시킬 때 예측성능의 문제가 발생할 수 있다. 이살 레이블을 가지는
36.1019 - 머신러닝
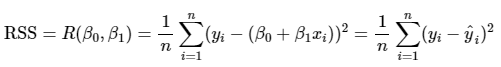
복습문제 위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다. 실습 과정과 이해에 따라 내용의 누락 및 코드의 변형이 있을 수 있습니다. 회귀(regression) 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계적 기법이
37.1020 - 머신러닝
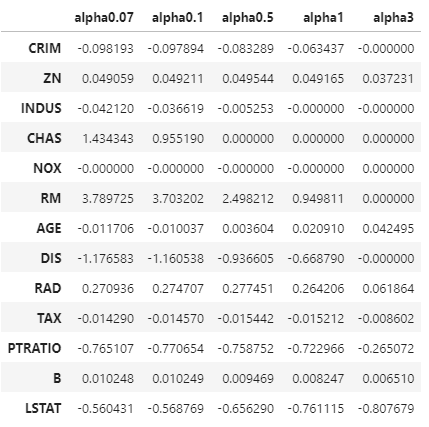
복습문제 위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다. 실습 과정과 이해에 따라 내용의 누락 및 코드의 변형이 있을 수 있습니다. 회귀 라쏘 회귀 W의 절대값에 페널티를 부여하는 L1 규제를 선형 회귀에 적용한 회귀이다. L2규제가 회
38.1021 - 머신러닝
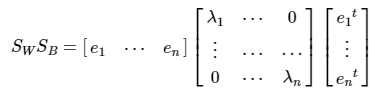
선형 판별 분석법으로 불리며 PCA와 매우 유사하지만 비지도 학습인 PCA와는 다르게 LDA는 지도학습이다. 분류에서 사용하기 쉽도록 개별 클래스를 분별할 수 있는 기준을 최대한 유지하면서 차원을 유지한다PCA : 입력데이터의 변동성이 가장 큰 축을 찾는다. 공분산 행
39.군집평가
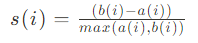
분류(Classification)와 비슷해 보일수는 있지만 그 성격이 많이 다르다.붓꽃 데이터 세트의 경우 결과값이 저장된 타깃 레이블이 있었지만 대부분의 군집화 데이터 세트는 이런식으로 비교할 만한 타깃 레이블을 가지고 있지 않다.데이터 내에 숨어있는 별도의 그룹을
40.1024 - 머신러닝
머신러닝이 보편화 되면서 NLP(natural language processing)와 텍스트 분석(Text Analytics, 이하 TA)을 구분하는 것이 큰 의미는 없어보이지만, 굳이 구분하자면 NLP는 머신이 인간의 언어를 이해하고 해석하는 데 더 중점을 두고 기술
41.1025 - 머신러닝
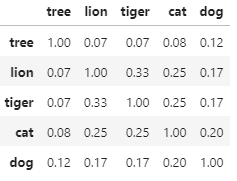
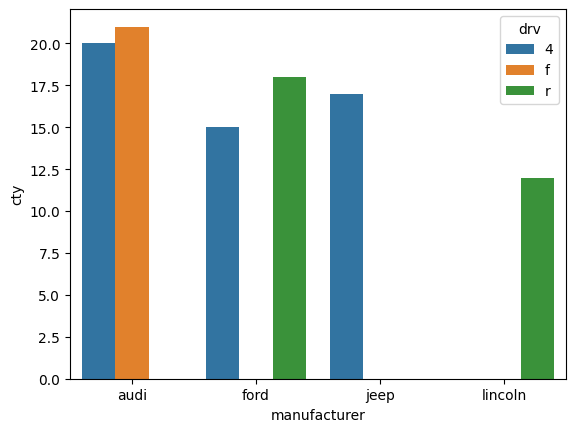
DTM문서x 단어행렬 Document Term Matrix특정 문서에 등장하는 특정 단어의 빈도를 나타낸 행렬가로줄(행)에 문서, 세로줄(열)에 단어 배치DocumentTermMatrix()TDM단어x문서 행렬TermDocumentMatrix()IDF역문서 빈도Inve
42.문서 유사도
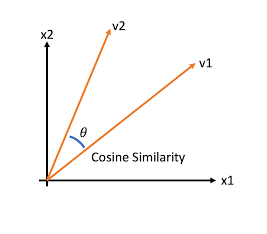
문서와 문서 간의 유사도 비교는 일반적으로 코사인 유사도(Cosine Similarity)를 사용한다. 이는 벡터와 벡터 간의 유사도를 비교할 때 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반한다. 즉, 코사인 유사도는 두 벡터 사이에 사잇각을 구해서
43.한글 텍스트 처리
네이버 영화 평점 데이터를 기반으로 분석을 해보기로 한다. 한글 NLP 처리의 어려움 일반적으로 한글의 언어처리는 '띄어쓰기'와 '다양한 조사'로 인해 처리가 어렵다고 한다. 띄어쓰기를 잘못하면 의미가 왜곡되어버리기 쉽상이고, 조사는 경우의 수가 너무 맘ㄶ기 때문에
44.1026 - 머신러닝

크게 콘텐츠 기반 필터링(Content based filtering) 방식과 협업 필터링(Collaborative Filtering) 방식으로 나뉜다.협업 필터링 방식은 다시 최근접 이웃 협업 필터링 과 잠재 요인(Latent Factor)으로 나뉜다.사용자가 특정 아
45.1028 - 읽어오기
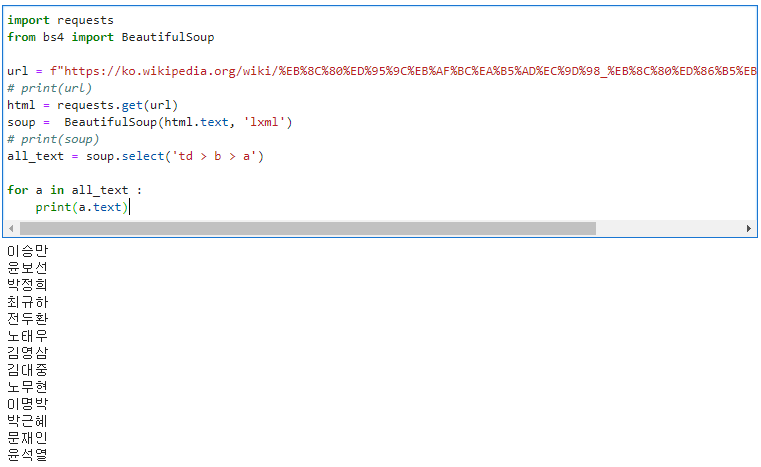
다음네이버접근 후 잘 로그인 되는 거 확인날씨 API를 이용하여 정보를 가져와 출력해보려 한다. OpenWeatherMap 사이트를 이용할 것이고, 가입후 API키를 받아 이용하면 된다. 완전 무료는 아니고 부분적으로 유료이기 때문에 필요한 정보를 잘 확인하고 접근하자
46.1031 - MNIST
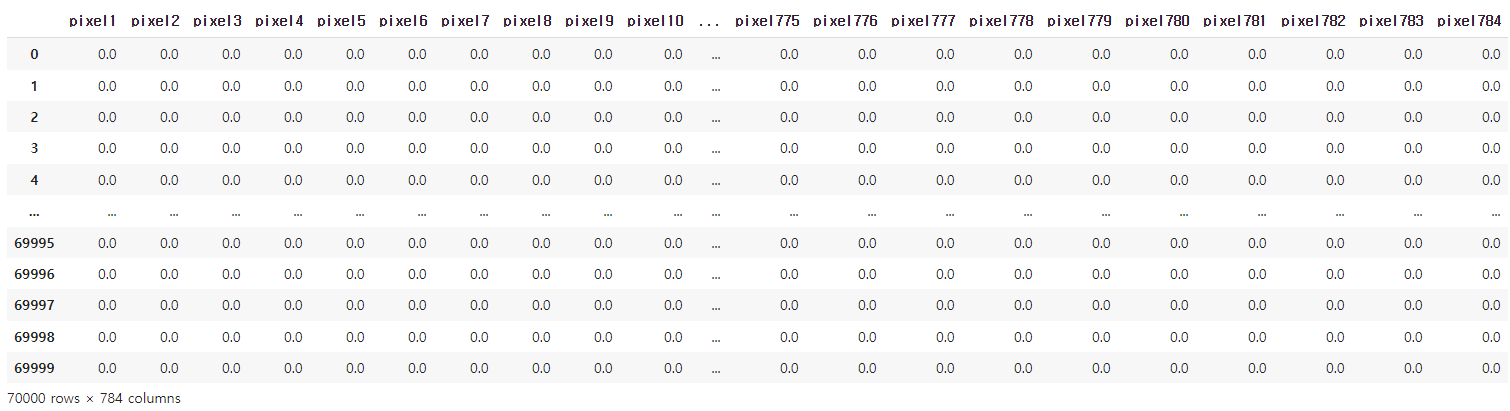
복습문제