복습문제
# 웹 페이지에 http 요청을 보낼수 있도록 기능제공하는 라이브러리 두가지
urllib.request / requests
# 웹 페이지의 정보를 쉽게 스크랩할 수 있도록 기능을 제공하는 라이브러리
BeautifulSoup
# URl 처리시 한글을 잘 인식하도록 해주는 함수는 무엇인가?
quote_plus
# 동적으로 변하는 웹 페이지의 데이터들까지 설정하여 크롤링할 수 있다
셀레니움(selenium)
# 다음음 웹에서 이미지를 검색해 폴더에 저장하는 코드 중 일부를
# 무작위 나열한것이다. 순서대로 서술하시오
ㄱ. driver.get(url)
ㄴ. driver = webdriver.Chrome("-")
ㄷ. time.sleep(5)
ㄹ. html = driver.page_source
ㅁ. soup = BeautifulSoup(html, 'html.parser')
ㄴ-ㄱ-ㄷ-ㄹ-ㅁ
# 접근시 로봇으로 인식되어 페이지에 제대로 접근이 안되는 경우
# 어떻게 해야하는가?
헤더정보를 담아 보낸다. {UserAgent : - }
# request.get(url)._?
text
# Html에서 페이지 이동시 주소창에 데이터를 포함하여 전달하는 방식을()라고 한다.
Get
# soup = Beautifulsoup(html, 'html.parser')
# images = soup.find_all(class='_image _listImage')
# 위 코드가 제대로 실행되지 않는 이유는?
class(x) class_
# soup.find_all() 말고 다른 것으로 괄호안에 해당하는 모든것을 긁어오는 것은 무엇인가
soup.select()
# https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EB%8C%80%ED%86%B5%EB%A0%B9_%EB%AA%A9%EB%A1%9D
# 페이지에서 역대 대통령들의 이름만 추출하세요
import requests
from bs4 import BeautifulSoup
url = f"https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EB%8C%80%ED%86%B5%EB%A0%B9_%EB%AA%A9%EB%A1%9D"
# print(url)
html = requests.get(url)
soup = BeautifulSoup(html.text, 'lxml')
# print(soup)
all_text = soup.select('td > b > a')
for a in all_text :
print(a.text)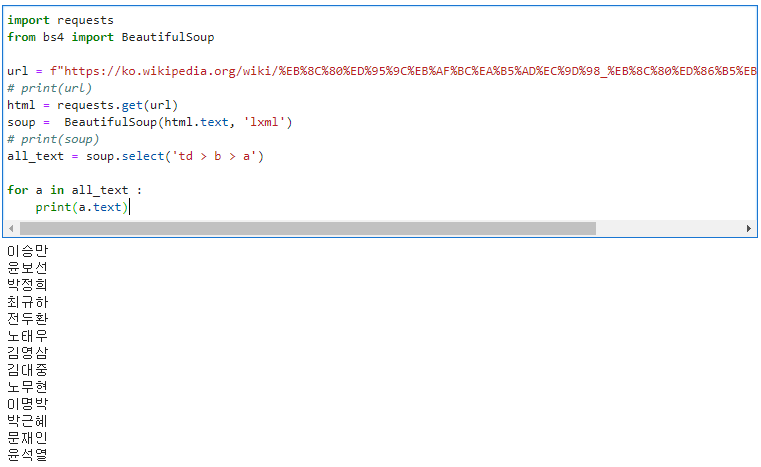
# 이미지를 뽑아주세요
url = f"https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EB%8C%80%ED%86%B5%EB%A0%B9_%EB%AA%A9%EB%A1%9D"
# print(url)
html = requests.get(url)
soup = BeautifulSoup(html.text, 'lxml')
image_rink = soup.select('td > a > img')
# print(image_rink)
link_list = []
for img in image_rink :
link_list.append(img.attrs['src'])
# print(link_list)
import os
if not os.path.isdir("./test1"):
os.mkdir("./test1")
from urllib.request import urlretrieve
count = 0
for link in link_list :
a = 'http:'+ link
urlretrieve(a, f"./test1/{count}.jpg")
count += 1
로그인하기
다음
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
# 드라이브 연결
driver = webdriver.Chrome("./chromedriver.exe")
url = f"https://accounts.kakao.com/login?continue=https%3A%2F%2Flogins.daum.net%2Faccounts%2Fksso.do%3Frescue%3Dtrue%26url%3Dhttps%253A%252F%252Fwww.daum.net"
# 키워드가 들어간 주소에 접근
driver.get(url)
# 로딩 될때까지 잠시 지연시켜주기
driver.implicitly_wait(20)
user_id = "본인 ID를 입력"
user_passwd = "본인 비밀번호 입력"
# ID element 중 '_'에 접근하여 키를 보내겠다.
# id가 랜덤으로 변경되는거 같길래 두가지로 테스트
driver.find_element(By.ID,'id_email_2').send_keys(user_id)
# driver.find_element(By.ID,'input-loginKey').send_keys(user_id)
driver.find_element(By.ID,'id_password_3').send_keys(user_passwd)
# driver.find_element(By.ID,'input-password').send_keys(user_passwd)
# 해당 경로에 있는 element에 접근하여 클릭해줘라
driver.find_element(By.XPATH, '//*[@id="login-form"]/fieldset/div[8]/button[1]').click()
# driver.find_element(By.XPATH, '//*[@id="login-form"]/fieldset/div[8]/button[1]').send_keys(Keys.ENTER)네이버
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 드라이브 연결
driver = webdriver.Chrome("./chromedriver.exe")
url = f"http://naver.com"
# 키워드가 들어간 주소에 접근
driver.get(url)
# 로딩 될때까지 잠시 지연시켜주기
driver.implicitly_wait(20)
# 2. 로그인 버튼 클릭
elem = driver.find_element(By.CLASS_NAME,'link_login')
elem.click()
user_id = "id"
user_passwd = "password"
driver.find_element(By.ID,'id').send_keys(user_id)
driver.find_element(By.ID,'pw').send_keys(user_passwd)
driver.find_element(By.XPATH, '//*[@id="log.login"]').send_keys(Keys.ENTER)접근 후 잘 로그인 되는 거 확인
네이버 검색
driver = webdriver.Chrome("./chromedriver.exe")
url = f"http://naver.com"
driver.get(url)
driver.implicitly_wait(20)
driver.find_element(By.ID,'query').send_keys("김연아")
enter = driver.find_element(By.ID,'search_btn')
enter.send_keys(Keys.ENTER)마이페이지 마일리지 가져오기
import requests
from bs4 import BeautifulSoup
# 세션, 서버쪽에 보관되어있다.
session = requests.session()
login_info = {"m_id":"id를 적어주세요","m_passwd":"비밀번호를 적어주세요"}
#(2)
url ="https://www.hanbit.co.kr/member/login_proc.php"
res = session.post(url, data = login_info)
# Response200 그러니까 반환된게 OK 코드가 아니라면 에러발생
res.raise_for_status
#(3)
my_page = "https://www.hanbit.co.kr/myhanbit/myhanbit.html"
res = session.get(my_page)
res.raise_for_status
soup = BeautifulSoup(res.text,"html.parser")
# #container > div > div.sm_mymileage > dl.mileage_section1 > dd > span
mileage = soup.select_one('.mileage_section1 span').get_text()
ecoin = soup.select_one('.mileage_section2 > dd > span').text
print("마일리지: ", mileage)
print("이코인: ", ecoin) 마일리지: 2,000
이코인: 0날씨정보(json)
날씨 API를 이용하여 정보를 가져와 출력해보려 한다. OpenWeatherMap 사이트를 이용할 것이고, 가입후 API키를 받아 이용하면 된다. 완전 무료는 아니고 부분적으로 유료이기 때문에 필요한 정보를 잘 확인하고 접근하자
import requests
import json
# api 키 지정
apikey = "지급받은 APIKey"
# api 지정
api = "http://api.openweathermap.org/data/2.5/weather?q={city}&APPID={key}"
# 날씨를 가져올 도시 지정
cities = ['Seoul,KR', 'Tokyo,JP', 'New York,US']
# 저기는 캘빈온도를 사용하니까
# 보기 편하려면 우리가 사용하는 섭씨 온도로 변환해주ㅓ야한다
K2C = lambda k : k-273.13
# 지정한 도시 정보 추출하기
for city in cities :
url = api.format(city=city, key=apikey)
json_data = requests.get(url)
# 가져온 json 데이터를
data = json.loads(json_data.text)
# print(data)
print(f'---------\n도시 : {data["name"]}')
print(f'날씨 : {data["weather"][0]["description"]}')
print(f'최저 기온 : {K2C(data["main"]["temp_min"]):.3f}')
print(f'최저 기온 : {K2C(data["main"]["temp_max"]):.3f}')
print(f'습도 : {data["main"]["humidity"]}')
print(f'기압 : {data["main"]["pressure"]}')
print(f'풍향 : {data["wind"]["deg"]}')
print(f'풍속 : {data["wind"]["speed"]}')
print()---------
도시 : Seoul
날씨 : clear sky
최저 기온 : 14.710
최저 기온 : 19.680
습도 : 42
기압 : 1025
풍향 : 260
풍속 : 2.06
---------
도시 : Tokyo
날씨 : few clouds
최저 기온 : 15.810
최저 기온 : 19.800
습도 : 58
기압 : 1022
풍향 : 110
풍속 : 1.54
---------
도시 : New York
날씨 : clear sky
최저 기온 : 6.050
최저 기온 : 11.120
습도 : 60
기압 : 1029
풍향 : 360
풍속 : 8.75네이버 구매물품 타이틀
# 네이버 로그인 하기 (CLASS_NAME-send_keys(Keys.ENTER))
# (1)설치
#!pip install selenium
# (2) import
import requests
from bs4 import BeautifulSoup
import selenium
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
# (3) setup Driver|Chrome : 크롬드라이버를 사용하는 driver 생성
driver = webdriver.Chrome("C:/Users/admin/chromedriver.exe")
# (4) 네이버 로그인 URL로 이동하기
url = "https://order.pay.naver.com/home?tabMenu=SHOPPING"
driver.get(url)
# (5) 아이디,패스워드,입력
driver.find_element(By.ID, "id").send_keys("")
# class,name은 여러개 접근 가능함. ID는 하나만 접근할때
driver.find_element(By.ID, "pw").send_keys("")
driver.find_element(By.CLASS_NAME,"btn_login").send_keys(Keys.ENTER)
#--------------------------------------------------------------------------
#로그인 하기
# (6) 페이지의 elements모두 가져오기
html = driver.page_source
soup = BeautifulSoup(html,"html.parser") # BeautifulSoup사용하기
# (7)
title= soup.select('div.goods_info > a.goods > p.name')
# (8)
for a in title :
print(a.text.strip()) 
올바른 경로로 가져오기는 하나 '네이버플러스 멤버십' 이라는 문구가 신경 쓰인다. 이를 제거 하고 가져오고 싶다. 그런데 코드를 살펴보면
<p>
<span>
<span>네이버플러스 멤버십</span>
<span>'
구매한제품의타이틀
</p>의 형식이라서 경로로만 걸러내는 데에는 한계가 있다는 생각이 들었다. 왜냐면 '구매한제품의타이틀'이 더 안쪽에 있다면 더 상세하게 경로를 지정해주면 되지만 이와 같은 경우에는 제거하고 싶은 text가 더 안쪽에 있기 때문에. 생각해 낸 방법은 두가지 이다.
1. replace
title= soup.select('div.goods_info > a.goods > p')
for a in title :
print(a.text.replace("네이버플러스 멤버십", " ").strip()출력시 replace로 제거하고 싶은 문장을 제거해주는 것이다. 간단하고 잘 먹힌다.
2. decompose()
title= soup.select('div.goods_info > a.goods > p')
for a in title :
if (a.find(class_ = "blind") != None) :
a.find(class_ = "blind").decompose()
print(a.text.strip())제거하고 싶은 text가 더 안쪽에 있는 '자식 태그'의 text이기 때문에 이를 없애주면 되지 않을까 싶었다. 만약 이게 오류가 난다면 제일 먼저 앞에 있는 find의 내용물이 비어있지는 않은지 확인해봐야한다. 만약 None으로 나온 것을 decompose() 해주려 한다면 필시 오류가 나기 때문이다.
따라서 여기에 적용시킬 때도 만약 a에서 class_"blind" 가 비어있지 않은지 (네이버플러스 멤버십 이라는 문장이 모든 목록에 있는 것이 아니라 일부 목록에서 나타나는 태그였기 때문에) 확인 먼저 하고 None이 아니라면 그것을 없애주라고 한것이다.

두 방법 모두 원하는 대로 출력되는 모습을 확인할 수 있었다.
+) extract() ---- 코드로 실험해보기
decompose()와 비슷하나 decompose()는 완전히 없애는 거고 extract()는 반환할때만 없어진 것처럼 하는거라한다.
XPATH 경로 가져오는 방법
아래 움짤과 같이 하면 된다.
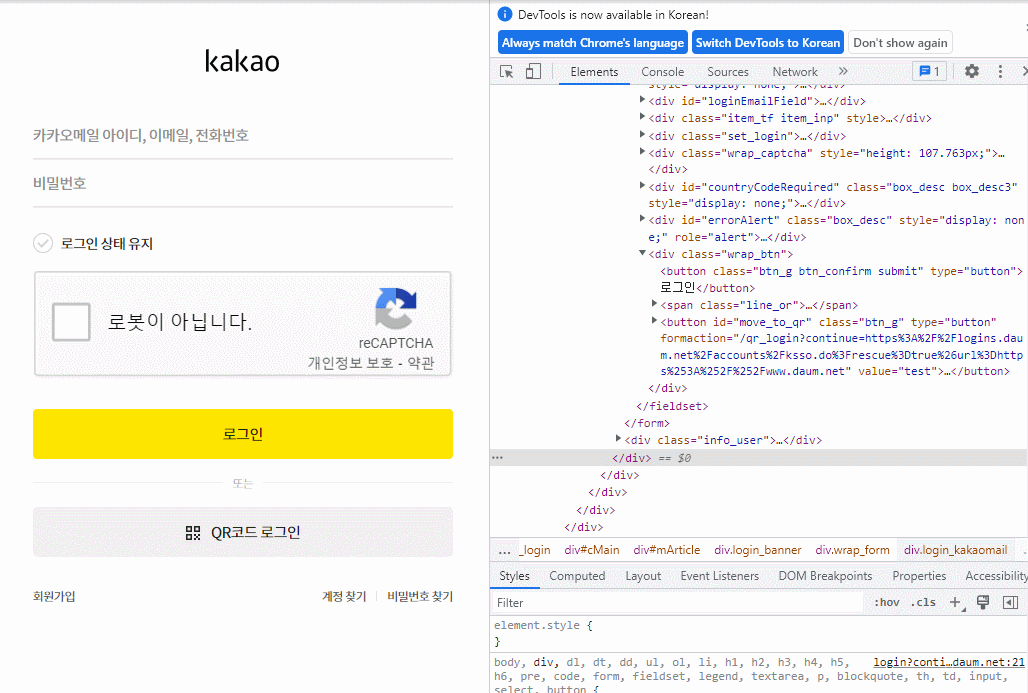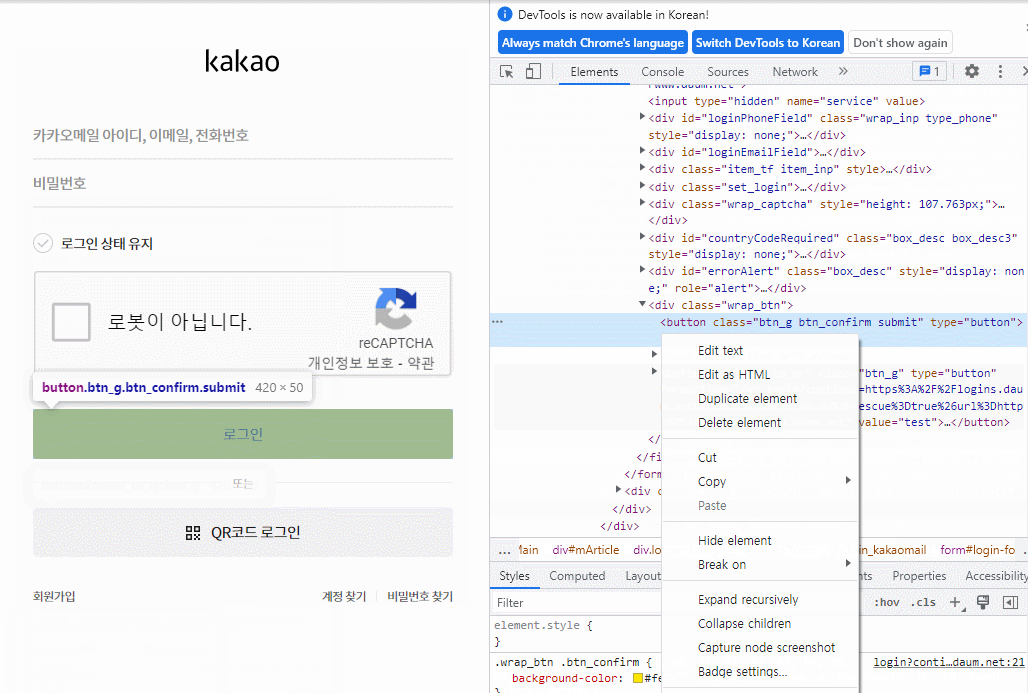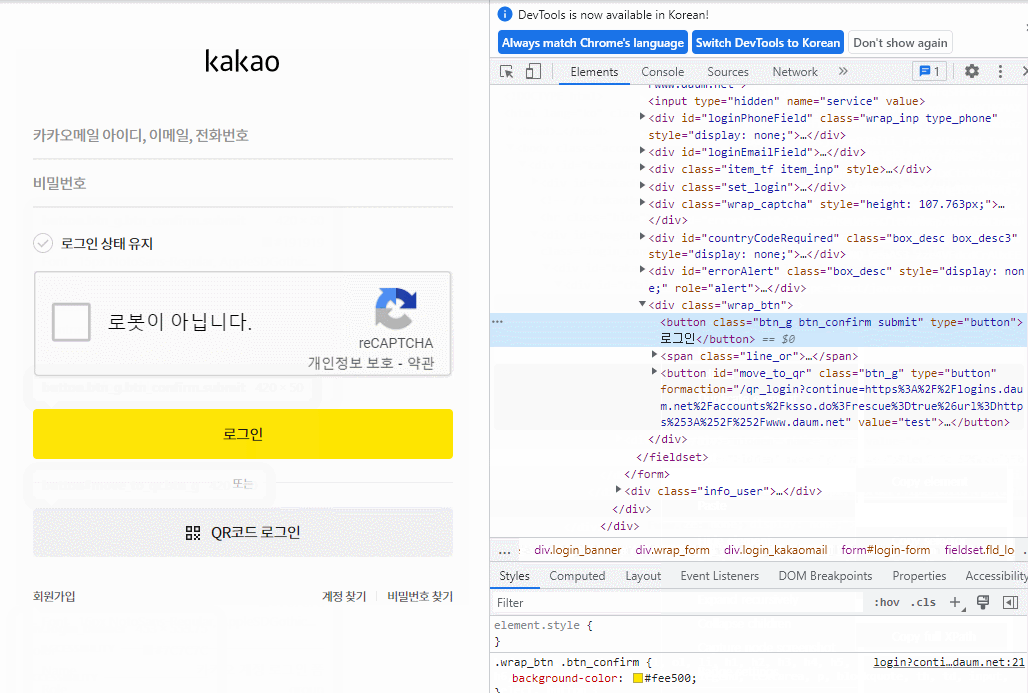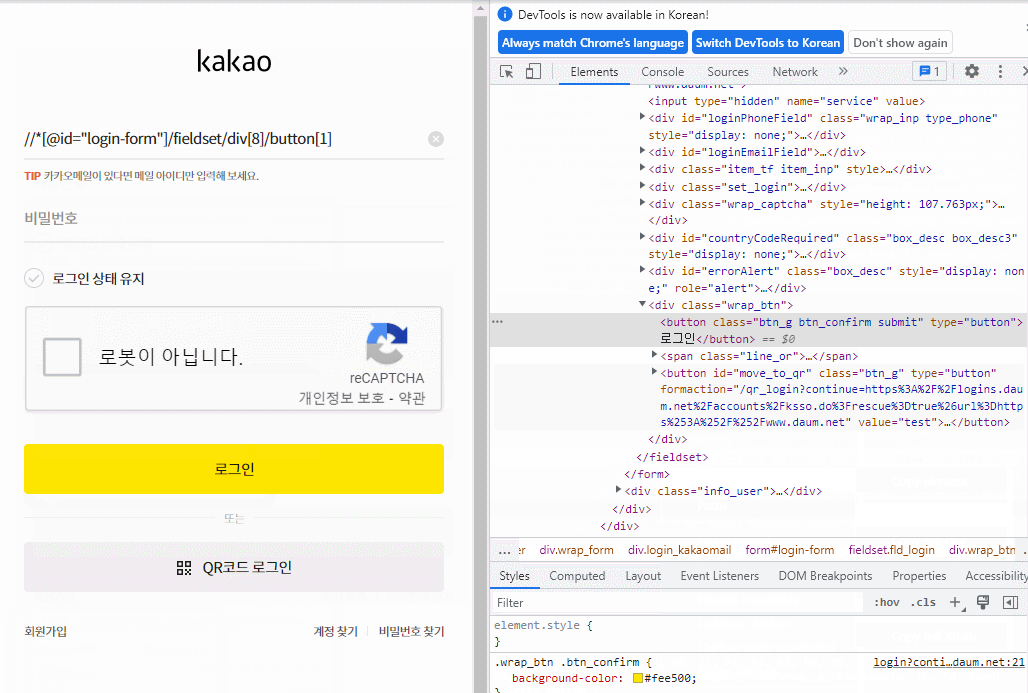
경로를 가져올 것(버튼, 라벨, input 등등)의 코드 위치를 찾아주기
→ 오른쪽버튼 클릭
→ copy
→ copy Xpath
→ 원하는 곳에 붙여넣기
AttributeError: 'WebDriver' object has no attribute 'find_element_by_css_selector'
처음에 실행하려 했을때 났던 오류였다. 이는 셀레니움 WebDriver에서 날 수 있는 오류로 말 그대로 find_element_by_css_selector()를 사용으로 인해 발생된 것이였다.
WebDriver에는 이제 위와 같은 함수가 없다. 예전 코드들을 보면 사용하고 있는 모습을 확인할 수 있었으나 업데이트 된 것인지 더이상 없기 때문에 없는 함수를 사용하겠다 하여 오류가 난것이였다.
대신 find_element라는 함수를 사용한다.
from selenium.webdriver.common.by import By
driver.find_element(By._,'__')종류들
| By.ID | 태그의 id값으로 추출 |
| By.NAME | 태그의 name값으로 추출 |
| By.XPATH | 태그의 경로로 추출 |
| By.LINK_TEXT | 링크 텍스트값으로 추출 |
| By.PARTIAL_LINK_TEXT | 링크 텍스트의 자식 텍스트 값을 추출 |
| By.TAG_NAME | 태그 이름으로 추출 |
| By.CLASS_NAME | 태그의 클래스명으로 추출 |
| By.CSS_SELECTOR | css선택자로 추출 |
json.loads(json_data.text)
- json : JavaScript Object notation 의 약자로 데이터 포멧 중 하나이다. 많은 정보를 경량화하여 보낼 수 있어 많이 사용된다.
이 json 파일을 python 에서 다루기 쉽도록 딕셔너리 형으로 불러올 때 loads()를 사용한다. 만약 Python 객체를 JSON 문자열로 변환할때는 dumps()를 사용한다.
requests.session()
- session = requests.Session()으로 생성
- header, adapter등을 설정가능
- 설정값이 유지된다.
만약 로그인 상태로 http request를 보내고 싶다면 session의 쿠키에 값을 저장하면 됨
→ 설정이 유지되니까(연결 재사용이 되니까) 속도 개선이 된다
→ 같은 host의 경우 연결을 주고 받을 때 그냥 request.get보다 좋을 수 있다는 이야기
but. 계속 연결하고 있을 필요가 없는데 켜놓고 있으면 굳이..