네트워크 - 4. Network Layer (2)
지난번의 챕터 목표를 다시 recall하자
Goal
- Network layer service 뒤에 있는 principle 이해하기 (특히 data plane)
- network layer service model
- forwarding versus routing
- how a router works
- addressing
- generalized forwarding
- internet architecture
- Internet의 instantiation, implementation
- IP protocol
- NAT, middleboxes
이렇게 보면 위에 건 싹다하고 맨 아래 NAT와 middlebox만 남은 것이 보인다. 고지가 눈앞이다.
Network Address Translation (NAT)
사실 local network에 있는 모든 device가 밖에서 볼 땐 결국 하나의 IPv4 address를 쓰는 것처럼 보이게 공유한다.
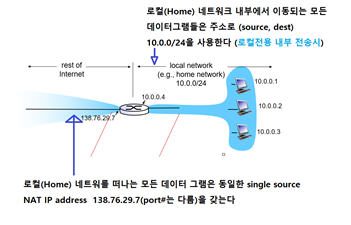
위 그림에서 오른쪽에 있는 모든 host들은 subnet 외부에서 볼때 다 같은 public IP (138.76.29.7)로 보인다.
- 단 port 번호는 다른데, 이는 내부 네트워크의 어떤 Host가 보냈는지는 식별할 수 있도록 하기 위함이다.
- 외부에서 온 datagram은 해당 port번호를 통해서 local network의 host에 전달된다.
왜 쓰는건지는 사실 지난번 게시글에서 언급하긴 했다. 하지만 더 많은 장점들이 있다.
NAT의 장점
- Subnet 내부의 모든 device를 위해서 provide ISP에게 단 하나의 IP address만 받으면 됨
- Outside world에 알리지 않고도 local network내부의 host address를 변경할 수 있음
- Local network 내부의 device의 주소 변경 없이 ISP 바꾸는 것도 가능
- 외부에서 볼때는 local address가 어떤 주소를 쓰는지 모르기 때문에 외부의 공격자로부터 더 안전하다. (Security)
이렇게 좋은 NAT, 어떻게 구현해야 될까?
NAT 구현
NAT router는 반드시(투명하게) 아래의 사항들을 지원해야된다.
- outgoing datagram들은 (source Ip address, port #)을 모두 (NAT IP address, new port #)으로 변경해야됨.
- NAT translation table에 모든 (source IP, port #)을 (NAT IP, new port#)의 translation pair를 저장해야 된다.
- incoming datagram들의 (NAT IP address, new port #)을 NAT table에 저장된 (source IP address, source port #)으로 바꿔줘야 된다.
이렇게 NAT table의 정보를 사용하기 때문에 외부에서 먼저 NAT 내부로 접근할 수는 없다. (내부에서 외부로 보내는 packet이 있어야 NAT table에 entry가 생긴다.) 즉, 반드시 local network에서 먼저 communication이 시작되어야 한다!
- 보안이 아주 증대되겠는걸..
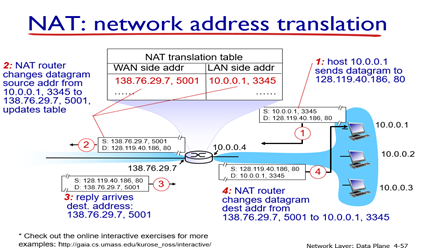
전체적인 과정은 위 그림과 같다.
여기서 조금 걸리는 점들이 있다. 아래서 살펴보자.
- 통신은 end-to-end 통신으로 각각의 layer는 캡슐화되어 다른 layer의 정보를 참조하면 안되는데 대놓고 참조한다... (end-to-endt argument를 위반한다..)
- 근데 Router는 l3(layer 3)라서 반드시 network layer까지만 건드려야 된다!
- 설령 port 번호를 바꾸지 않는다고 해도, 이미 그 정보를 읽기 때문에 위반이다.
- 또한, client가 NAT 뒤에 있는 server에 연결하고 싶을 땐 어떻게 해야돼...
- 마지막으로 address 부족 문제는 이런 NAT같은 middlebox가 아니라 IPv6를 통해 해결해야 된다!
이런 문제들이 있음에도 NAT는 여전히 많이 사용되고 있다..
- 특히 집, 기관내부망, 4G/5G cellular net 등에서 사용된다.
middlebox에서 이런 문제들에 대해서 다시 다룰 것이다.
middlebox로 넘어가기 전에 잠깐, 자꾸 IPv6가 언급되는데 정작 이게 뭔지는 설명하지 않았다. IPv6를 먼저 보고, middlebox로 향하자.
IPv6
지난 번에도 언급했듯, 스마트폰, 랩탑, 태블릿... 심지어 IoT device들까지 등장하며 32bit IPv4 address space는 고갈되기 시작했다.
또 다른 이유로는 IPv4에는 TTL field가 있어 쓸때없이 매번 router에서 checksum을 새로이 계산해줬어야한다. 또, option field가 있어서 속도가 저하됐다. (어디서부터가 payload인지 몰라서 시간 이 좀 더 걸림)
이런 것들을 전부 해결하기 위해서 IPv6가 등장했다.
IPv6 Datagram format
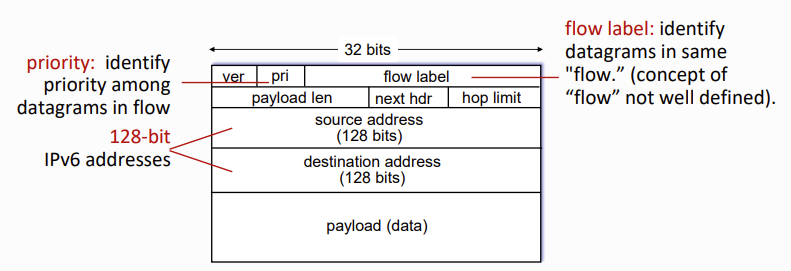
가볍게 format 한컷. 전체 헤더 사이즈를 대충 계산해보면 4 + 4 + 16 + 16, 즉 40으로 고정. 새로 생긴 field들도 있고 사라진 field들도 있다.
- priority: flow의 datagram들 사이에서 priority를 지정
- Next hdr: 데이터에 전한달할 상위 layer 식별 + 옵션 등의 기능으로 사용함.
- hop limit: 라우터 거칠 수 있는 횟수. 초과시 drop
- flow label: 같은 flow 안의 datagram임을 명시
- 128bit의 주소들
아래는 IPv6가 단순화를 하기 위해 한 노력들..
- checksum 삭제!: checksum 계산으로 인한 overhead 감소
- fragmentation/reassembly 삭제: 긴 packet은 그냥 drop함
- option field 삭제: header 사이즈를 40byte로 고정할 수 있게 됐음.
근데 이렇게 다르면 IPv6랑 IPv4랑 서로 호환이 될까? 지금 core에 있는 모든 router를 IPv6에 맞는 라우터로 바꾼 것도 아닐거고, 모든 라우터가 그런건 아닐텐데 그럼 어떻게 상호간에 전송될까...? 를 알아보자.
Transition from IPv4 to IPv6
간단히 요약하자면 터널링을 통해 전송한다. (너무 빠른 요약..)
역시 앞서 말했듯 모든 router를 통시에 upgrade할 수 있는 것도 아니고, network 상에는 둘이 섞여있다.
Tunneling: IPv6 datagram은 IPv4 datagram의 payload로써 실려서 IPv4 router를 통해 전송된다.
- IPv4 header를 붙여 IPv4 network을 지난 후 IPv6 network에서는 다시 해당 header를 제거한다.
- 당연히 이후 IPv6 network을 통과해야되니까 IPv6 header는 남아있어야 한다.
- tunneling은 4G/5G 등의 다른 context들에서도 자주 사용되는 기법이다.
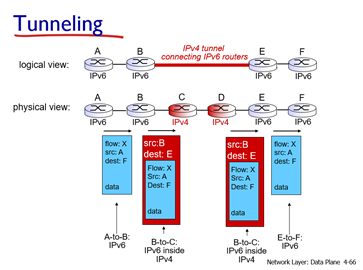
중요한 것은 tunneling packet에 header가 새로 부착됐다는 점이다. source, destination address가 모두 새로이 지정된다. (A-to-F -> B-to-E -> A-to-F)
- 이때 IPv6 router들은 상대편의 ip address도 알고 있어 이를 통해 header를 생성할 수 있다.
현재 구글의 30% client가 IPv6를 사용하며, NIST 등의 전체 미국 정부 domain의 1/3은 IPv6 도메인을 사용가능하다.
- 이 속도라면 전체를 다 IPv6로 바꾸는데 대충 25년 이상이 걸릴 것이라 생각된다.
- 모든 router와 장비가 IPv6로 업그레이드 되야 하며, 특히 core router는 업그레이드 하기가 더 빡세다..!
Generalized Forwarding, SDN
잠깐, 갑자기 왜 SDN이 나오는지 모르겠는가? 나도 그렇다. 일단 시험공부하고, 나중에 앞쪽에 forwarding 파트로 다시 옮길 예정이다.
destination-based forwarding에서는 dest IP주소와 port 정보만 보고 forwarding했다. 반면 SDN에서는 논리적으로 중앙 집중된 Remote Controller에 의해서 route를 계산하고 flow table을 만들어 그걸 다시 router에 뿌리는 방식이다.
- SDN에서는 많은 header field들이 action을 결정할 수 있다.
- 또한 그냥 forwarding이 아니라 drop/copy/modify/log packet 등 여러 action이 가능하다!
flow table
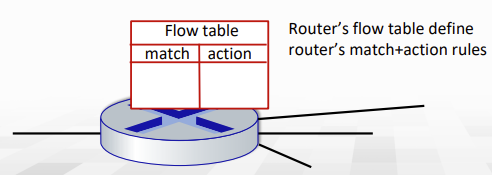
flow table은 모든 header(link-, network-, transport-layer header)의 몇몇 field value들에 의해서 결정된다.
flow table은 packet handling rule에 따라서 generalized forwarding을 지원한다.
- match: packet header field들의 value들을 pattern을 matcht시킴
- actions: matched packet에게 사용된다. matched packet을 drop, forward, modify하거나 controller에게 해당 패킷을 전송한다.
- counters: byte수와 packet수
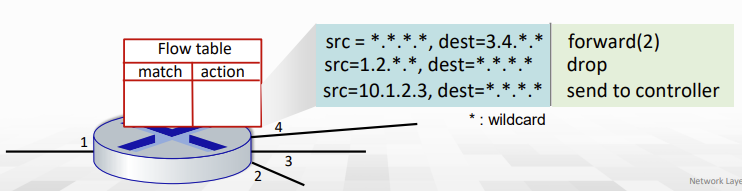
예를 들어 위 사진에서 forward(2)는 destination ip가 3.4.으로 시작한다면 2번 interface로 보낸다는 뜻이고, 1.2.으로 시작하는 src에서 온 pakcet은 drop한다는 뜻이다. (차단)
Openflow: flow table entries
Openflow란 SDN에서 사용하는 오픈소스이다. 지금 설명은 version 1.0에 기반하지만, 현재 사용하는 버전은 그것보단 더 높다.
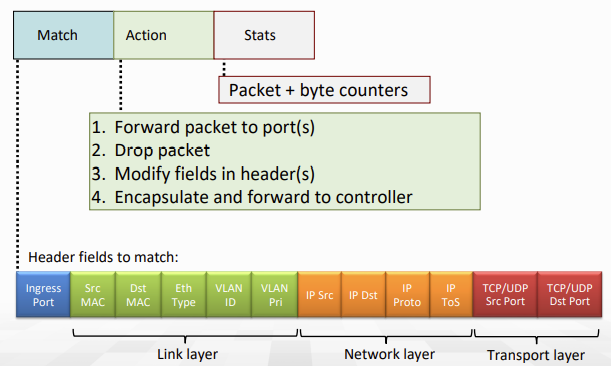
아래 match에 사용하는 header field의 값들을 보면, link layer, network layer, transport layer 정보 모두 있다. (ToS는 Type of Service)
- Router는 L3인데 왜 또 L2, L4정보까지 건드냐? layering principle 침해 아니냐?
- 맞다. 이상한거 맞고, 그냥 쓴다..
- 최근 version은 12개가 아니라 41개의 정보를 사용한다.
Generalized에선 모든 정보를 사용한다.
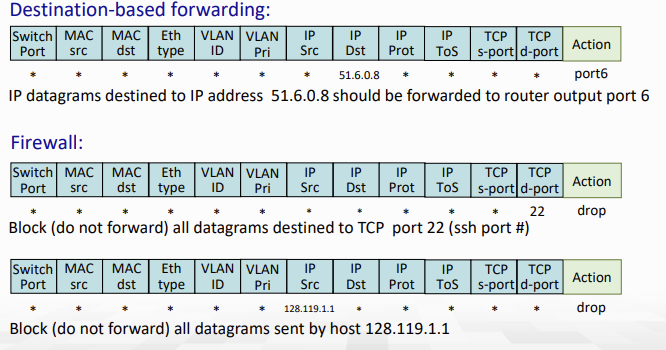
그렇게 match된 packet에 대해서 이렇게 action을 지정해준다. 때문에 match+action인 것.
다른 종류의 device들에서도 abstraction은 일치한다.

이렇게 action을 달리함으로써 여러 종류의 device처럼 행동할 수 있다..!
- switch에서는 모든 Host에 broadcast하는 과정이 있는데, 이를 action으로 넣어둔 것이다. 나중에 Link layer에서 다룬다.
이렇게 만들어진 table은 network-wide의 행동을 만들 수 있다.
- 예를 들어 아래 그림에서 h5, h6 host에서 와 h3, h4로 가는 datagramdms 무조건 s1과 s2를 거쳐가게끔 할 수 있는 것이다.
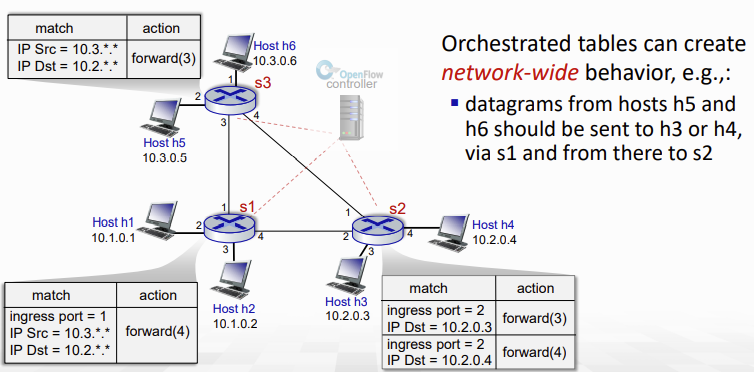
여기서 알아야될 것은 Match Plus Action이라는 점이다. 즉 도착한 packet의 어떤 layer의 header 값이든 bit를 match하고, action을 취한다.
- link, network, transport 모든 layer의 field 값에 matching할 수 있다.
- drop, forward, modify, controller에게 matched packet 보내기 등의 local action을 취할 수 있다.
- 또한 network-wide의 global action까지도 "programming"할 수 있다!
때문에 이는 network programmability의 간단한 형태이다.
- packet당 processing을 통해 프로그래밍 할 수 있다.
- 이를 active networking이라고도 한다.
- 오늘날에는 더 일반적인 프로그래밍까지 할 수 있다. (P4)
- P4: Programming Protocol-indepent Packet Processors
드디어 돌고 돌아 middlebox이다. 사실 앞에서 다뤘던 NAT도 Middlebox의 한 종류인데, 더 general한 범위에서 공부해보자.
MiddleBoxes
RFC 3234에선 Middlebox를 다음과 같이 정의한다.
Middlebox (RFC 3234)
Any intermediary box performing functions apart from normal, standard functions of an IP router on the data path between a source host and destination host
간단히 말하자면 source에서 dest까지의 data path에 있는 IP router에서 수행되는 normal function들(forwaring, routing)을 제외한 다른 기능들을 의미하는 것이다.
사실 이런 middlebox는 어디에나 존재한다. 아래 그림을 보자.
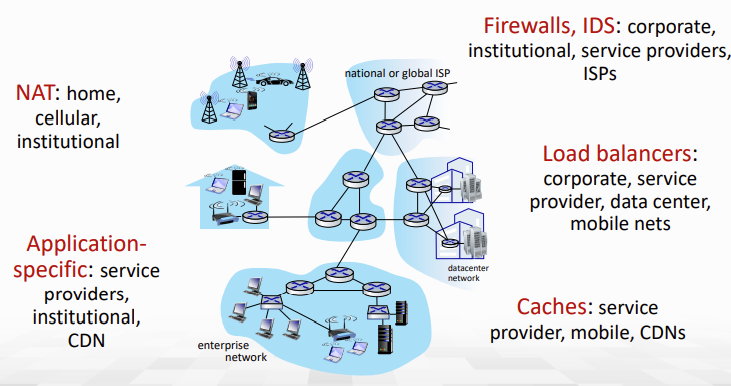
일전에 다뤘던 NAT는 물론이고 Firewall이나 Load balancer, Web Cache 등 익숙한 서비스들이 보이는데, 이들이 모두 middlebox의 한 종류이다.
사실 처음에는 Middlebox는 hardware에서만 관리되는 독점적인(proprietary) solution이었다가 이후 open API를 구현하는 whitebox hardeware로 이동했다. 그 과정을 통해서 hardware에서 독점하는 solution에서 벗어났으며,match+action을 통해 local action들은 프로그래밍 가능해졌다.
- 이는 software의 혁신/차별화를 향한 움직임이라고 할 수 있다.
SDN은 private/public cloud안에서 관리하는 centralized control 및 configuration이다.
Network functions virtualization(NFV)는 whitebox networking, computation, storage를 통한 programming 가능한 서비스이다 ?
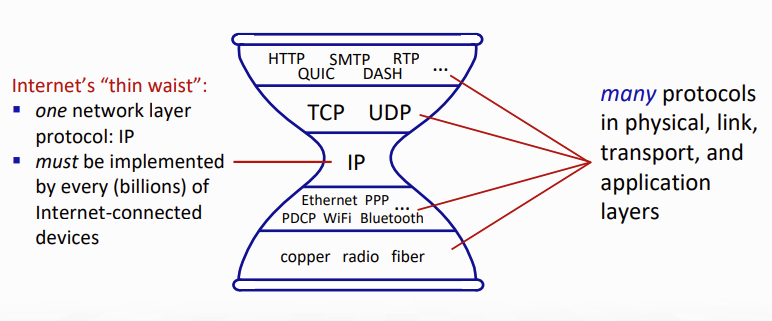
위 그림에서 볼 수 있듯 지금까지는 양 끝만 뭔가 많았고, 가운데 network layer에는 단 하나의 protocol만 존재했다. 때문에 모든 internet-connected device는 해당 protocol이 구현되어있어야 했다.
- 위쪽은 edge에서 사용되는 protocol들이고, 아래쪽은 hop 단위에서 사용되는 기능들이다.
- IP는 network core에서 사용되는 기능.
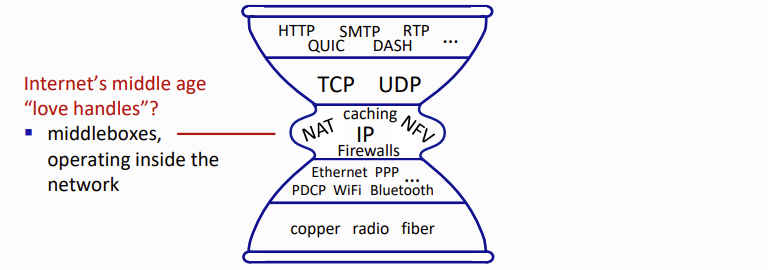
이제는 middlebox들 덕분에 가운데에도 이렇게 풍부한 protocol들이 생겼다..
- 사실 network는 simple해야되는데, 점점 더 많은 function들이 추가되고 있다.
- core는 simple해야되는데...

또한 많은 기능들이 생기긴 했지만, 이는 end-end argument에 위배되는 기능들이다. 아래의 end-end argument를 살펴보면 알 수 있다..

하지만 결국 이건 흐름이다.
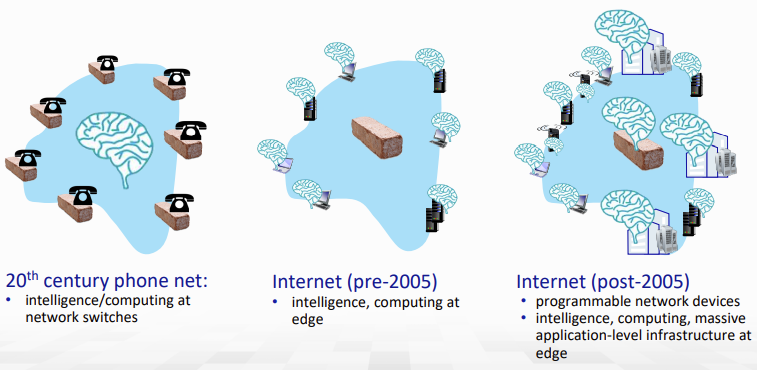
처음에는 중앙에만 intelligence가 있었다가, 인터넷 초기엔 intelligence가 다시 host로 옮겨졌다. 이후 지금은 core에도 intelligence들이 추가되고 있다. (SDN 등)
그렇다면 이러한 forwording table, flow table은 어떻게 생성되는 것일까? 이는 Network layer - control plane편에서 다루자 (다음 게시글이라는 뜻..)

감솨감솨 감솨해룡〰️〰️🎶 너무 감솨해서 이리갔다👈 저리갔다👉 왔다리 갔다리🤘🎤🎶 🙈🙉🙈🙉 까꿍까꿍 😚 박수도 짝짝짝❗🙌🙏감솨감솨 감솨해룡〰️〰️🎶 너무 감솨해서 이리갔다👈 저리갔다👉 왔다리 갔다리🤘🎤🎶 🙈🙉🙈🙉 까꿍까꿍 😚 박수도 짝짝짝❗🙌🙏감솨감솨 감솨해룡〰️〰️🎶 너무 감솨해서 이리갔다👈 저리갔다👉 왔다리 갔다리🤘🎤🎶 🙈🙉🙈🙉 까꿍까꿍 😚 박수도 짝짝짝❗🙌🙏감솨감솨 감솨해룡〰️〰️🎶 너무 감솨해서 이리갔다👈 저리갔다👉 왔다리 갔다리🤘🎤🎶 🙈🙉🙈🙉 까꿍까꿍 😚 박수도 짝~