네트워크 5 - Network layer - control plane (1)
지난 Data plane에 이어서 control plane을 정리해보자
network-layer function에는 forwarding과 routing이 있다고 언급했었다. forwarding을 담당하며, buffer관리 등을 data plane에서 신경쓰며, Routing은 control plane에서 담당한다.
control plane의 구조는 2가지 접근법이 있다.
1. Per-router control (traditional)
- 각각의 router에 있는 control plane들이 서로와 상호작용하여 독립적인 routing algorithm을 통해 routing을 진행하는 것.
- 각각의 router가 path를 결정한다.
- logically centralized control (software defined network)
- Remote controller가 전체 forwarding table을 계산하고 각 router에 설치한다.
- router 내부의 control agent가 remote controller와 상호작용해서 해당 과정을 진행
Routing Protocols
link state, distance vector에 대해서 먼저 알아보자.
라우팅 프로토콜의 목표는 src에서 dest까지의 좋은 path를 결정하는 것
- 여기서 path는 패킷이 src-dest까지 갈 때 지나가는 router들의 순서
- good은 뭐... cost도 낮고, 빠르고, congestion없는 그런게 좋은 것

link cost는 이렇게 그냥 방향 그래프로 보면 더 쉽다.
각 edge가 갖는 cost가 바로 link cost이며, 만약 연결이 없다면 INF(infinate)로 설정된다.
cost는 network operator에 의해서 설정되는데, 1일수도 있고, bandwidth의 역으로 설정될 수 있고 congestion 상태의 역으로 설정될 수 있다. (congestion이 good이면 low cost)
구체적으로 routing protocol의 분류는 아래와 같다.

글로벌은 모든 라우터가 네트워크 전체 topology와 link cost를 알고 있는 경우이며, link state 알고리즘을 사용한다.
분산형에서는 라우터가 물리적으로 연결된 이웃의 cost만 알고 있으며, 이웃의 정보를 받아 옴으로써 조금씩 업데이트한다. distacne vector algorithm을 사용한다.
-> 차이점은 맨 처음에 router가 전체 정보를 알고 있냐, 자기 정보만 알고 있냐의 차이
정적 알고리즘은 시간에 따른 경로 변경이 매우 느린 것을 의미하고, 동적은 시간에 따라서 휙휙 주기적으로 업데이트 하는 것을 말한다. 주기적으로 link cost를 업데이트 하는 것을 말함.
link state
link state 알고리즘은 우리가 익히(?) 알고있는 다익스트라 알고리즘을 사용한다.
모든 노드가 전체 network topology와 link cost를 알고 있으며, 이는 link state broadcast에 의해서 알게 된다. (모든 노드가 아는 정보가 같음)
- 한 노드에서 최소 비용 경로를 계산하기 위해 다른 전체 노드에 대한 경로를 계산해 forwarding table에 기록한다.
- k iteration후에, 최소 k만큼 떨어진 destination들까지의 거리를 계산할 수 있다.

알고리즘은 다익스트라와 같다.

간단히 설명하면, 시작 노드에서 모든 노드들에 대한 비용을 구한다. 이후 N'에 포함되지 않은 모든 노드들에 대해서 최소비용을 탐색한다. (최소라면 N'에 추가)
이후 해당 노드의 주변 노드를 다시 탐색한다.
원래 경로와 새로 추가된 경로를 거쳐서 가는 경로의 cost를 비교해 더 작은 걸로 업데이트한다.
저런 pesudo code가 이해가 안될 때가 더 많아서 아래와 같은 python 코드를 제공해봤다.
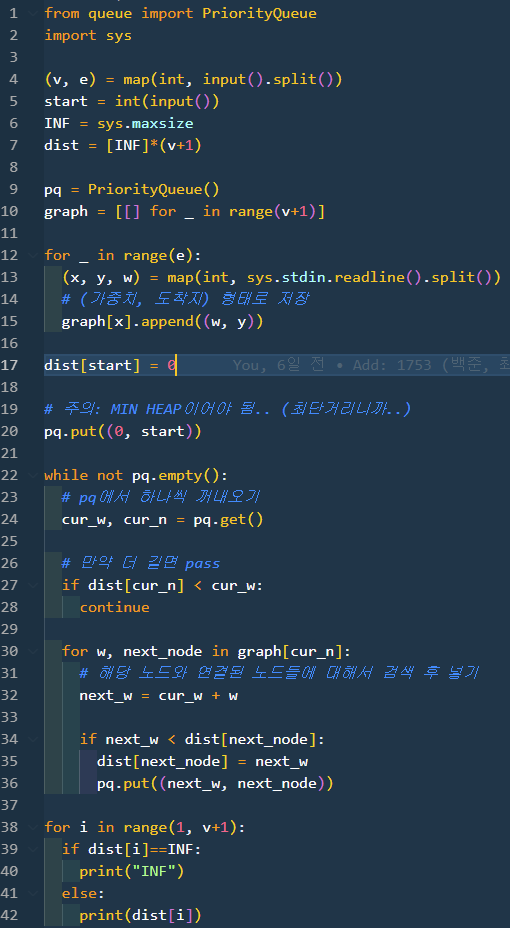
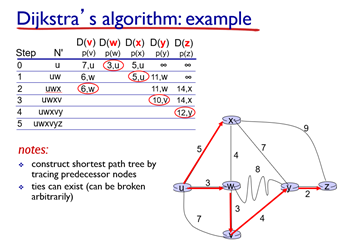
이건 다익스트라가 발생하는 과정을 표로 나타낸 것.
1. u에서 모든 노드로의 cost 업데이트
2. 그중 가장 작은 D(W) (3, u)선택 (같은게 여러개 있으면 아무거나 선택)
3. w를 거쳐 각 노드로 갈 수 있는 cost 업데이트 (기존의 것과 비교해 더 작은 것만 남긴다.)
4. 또 남은 것 중 가장 작은 D(X) (5, u)선택
5. 반복
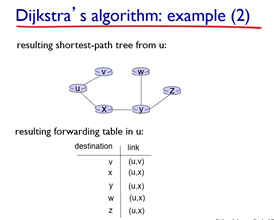
최종으로 남은 그래프는 위와 같고, 표로 나타낸 것도 포함했다. (표에는 시작 router u와 연결된 것 중 가장 첫 번째 router를 기록해둔 것이다.
시간복잡도는 O(n^2)인데, 가장 작은 노드 찾는 과정을 위 코드처럼 heap이나 priority queue에 넣고 하면 O(nlogn)으로 가능하다.
또한 각 router는 link state 정보를 다른 n개의 router에 broadcast해야 한다. 이 과정을 효율적인 broadcast algorithm을 사용하면 O(n)만에 link crossing이 가능하다.
- 각 라우터의 메세지가 O(n)개의 링크를 교차하면, 전체가 모두의 메세지를 받는 데는 O(N^2)이 든다.
또한, link cost를 traffic volume에만 의존하도록 설계하면 route oscilation이 발생할 수 있다..
- 아래 그림을 보자. 이렇게 불필요한 반복을 통해 route가 계속 변동할 수 있다.
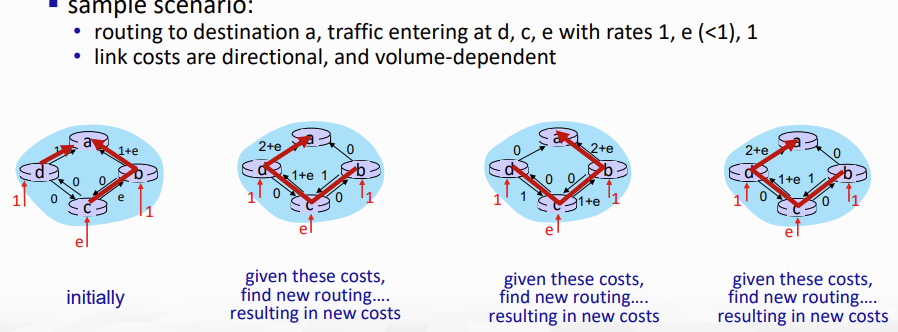
- solution이 있긴 한데, synchronization이 바로 그것.
- 하나를 update하면 모두를 같이 update하는 것!
Distance Vector
Distance vector 알고리즘은 Bellman-Ford(BF) equation을 사용한다. (Dynamic programming의 한 종류)
- 하나를 update하면 모두를 같이 update하는 것!

간단히 설명하자면, 이웃 노드로 가는 비용 + 이웃에서 목적지로 가는 비용을 비교해서 최소값을 선택하는 것이다.
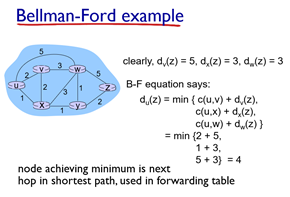
그림을 보면 이해가 더 쉽다. u에서 z로 가는 비용을 계산할 때, 인접한 라우터들 중 어떤 걸 거쳐서 가는 것이 가장 빠를지만 결정하는 것
key point
각 노드가 자신의 distance vector를 계산결과를 이웃에게 보낸다.
각 노드가 이웃으로부터 새로운 DV 결과를 받으면, BF방정식을 사용해 자신의 DV를 업데이트
보통 실제 상황에서 DV는 실제 최소비용 DV로 수렴한다.

즉, 각 노드는 자신의 link state를 모니터링하면서, 이웃들이 notify하는 것을 받는다. 주변의 notify가 오면 estimate를 다시 계산하고, DV가 바뀐 경우에만 이웃에게 알린다.
특징:
- iterative, asynchronous: 반복적으로 local link cost가 변하고, 계산하며, 변화가 생기면 이웃에게 update message를 날린다.
- distributed, self-stopping: 각각의 노드가 DV 변화가 있을 때만 알린다.
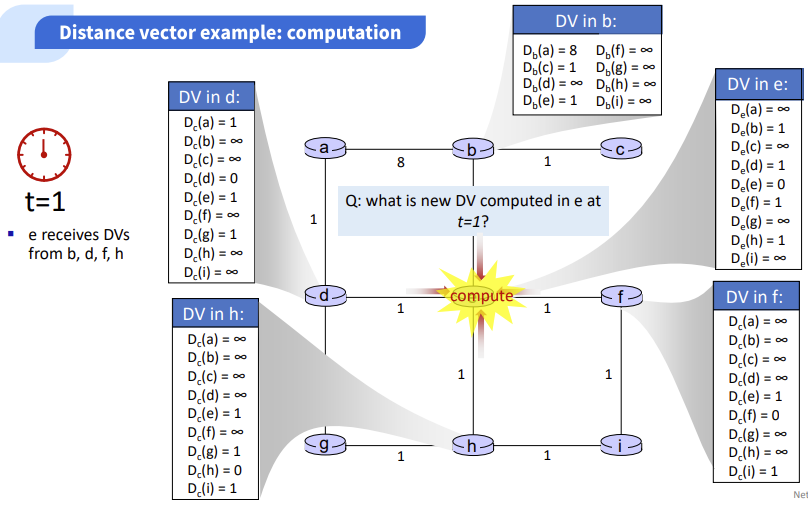
위는 t=1일 때의 DV정보 값들이다. 1일때는 바로 이웃 라우터의 정보를 받아서 거기서 갈 수 있는 정보까지 업데이트된 모습을 확인할 수 있다.
최종적으로 t만큼의 시간이 흘렀다면, t만큼 떨어진 router까지의 최단거리 정보를 계산할 수 있다.
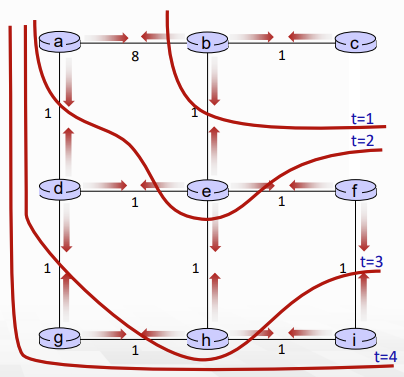
distance vector는 link가 긍정적으로 변하는 경우 빨리빨리 전파되는데, 부정적으로 변하는 경우 엄청나게 느린 속도로 전파된다. 이를 count-to-infinity problem이라고 한다.

이렇게 있을 때, 4가 60으로 바꼈다면 y는 x로 가는 최단 루트를 업데이트 해야됨.
주변을 보니, z를 통해서 x로 가는 루트 (z->y->x)가 5니까, 5+1을 해서 6으로 업데이트하고, 그럼 z는 또 업데이트하고...
z->x로 가는 길이 51이 될 때까지 1씩 반복하면서 업데이트한다. (51이 되면 z->x로 직접 가는 link cost가 50이라 멈춤, 하지만 만약.. cost가 1000이라면?)
해당 문제는 z가 어떤 path를 통해서 x로 가는지를 말해주지 않기 때문임.
- poisoned reverse: 만약 z가 y를 통해서 x로 간다면, z는 y에게 z->x의 cost가 INF라고 알려줌
- 가는 path에 대해서는 진짜 값을, 돌아오는 path에서는 가짜 값을 알려줌
- 해당 방법을 사용해도 완전히 해결 X
LS vs DV
Message Complexity
LS: N개의 노드일 때 O(n^2)만에 메시지 전달
DV: 이웃들 하고만 교환, 각 노드가 최소 cost로 수렴하기까지의 시간은 다양함.
Speed of convergence
LS: O(n^2) 알고리즘 O(n^2)메시지 요구 사용
- Oscillation 문제 발생 가능
DV: 다양한 시간이 걸림. - 라우팅 루프 문제 가질 수 있음
- Count infinity 문제도..
Robustness(라우터가 이상동작할 때 어떤일 이 일어나는지)
LS: 노드가 잘못된 링크 cost 브로드 캐스트 가능
- 그걸 기반해서 자기 자신의 테이블 계산
- 제한적으로 잘못된 결과
DV: 잘못된 링크가 아니라 잘못된 PATH를 전파 - black-holing
- 각 라우터의 테이블은 다른 것에 사용됨.. 오류가 네트워크를 통해 급격하게 전파
속도
LS: 브로드 캐스트로 모든 노드에게 일시에 교환, 전체 네트워크 상황을 아는 상황에서 작동
DV: 이웃하고만 정보 교환해서 시간 오래걸림
Intra-ISP routing: OSPF
사실 지금까지의 routing에 대한 공부는 약간 이상적인 상황이었다. 모든 라우터가 식별 가능해야하며, network가 flat하다는 가정 하에 계산한 것.
실제로는 당연히 그렇지 않으며, 그렇지 않은 이유가 2가지 있다.
- Scale(billions of destinations):
- routing table에 모든 destination의 정보 저장 불가
- routing table 교환은 link를 마비시킬 수 있음.
- Administrative autonomy:
- Internet: network들의 network
- 각 network admin은 자신의 network내부의 routing을 control하길 원함..
한 지역에 있는 router들의 집합체는 Autonomous System(AS, domains)라고 부른다. 이 AS 내외의 통신에는 두 가지 종류가 있다.
- intra-AS (intra-domain, 같은 AS에서의 routing)
- AS 내부의 모든 라우터들은 반드시 같은 intra-domain protocol으로 동작해야 함.
- 다른 AS의 router는 다른 intra-domain routing protocol으로 동작할 수도 있음.
- gateway router: AS의 edge에는 다른 AS의 router와 연결된 놈이 있다. 그놈이 gateway router
- inter-AS (inter-domain, AS들 사이에서의 routing)
- gateway는 intra-domain routing뿐만 아니라 inter-domain routing도 수행한다.
interconnected AS
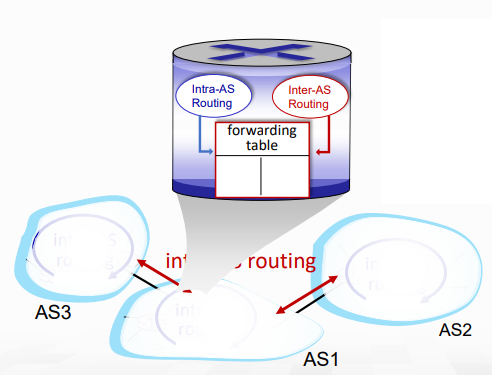
Forwarding table은 intra-AS와 inter-AS routing 알고리즘을 통해서 구성된다.
- intra-AS routing은 AS 안에서의 destination을 위한 entry을 결정해줌
- inter-AS & intra-AS는 external destination을 위한 entry을 같이 결정함.

안녕하세요. 좋은 자료 감사합니다.
OSPF이후의 내용에 대해서 정리계획은 없으신가 문의 드립니다
감사합니다