
이전 자료조사를 통해 Chat Completions API를 사용하기로 결정하였다. 이제 해야할 일은 프로젝트에 ChatGPT 서비스를 적용시키는 일이다.
⚙️ 기본 환경 설정
OpenAI에서 제공하는 API를 사용하기 위해서 openai 를 설치하고,
환경변수를 관리하기 위해서 @nestjs/config를 설치하였다.
npm i openai
npm i --save @nestjs/config ChatGPT를 사용하는 서비스 이름을 GptSevice라 설정하고, Chat Completions API를 사용하기 위해 OpenAI config를 설정해주었다.
import { Injectable } from '@nestjs/common';
import { ConfigService } from '@nestjs/config';
import { JwtService } from '@nestjs/jwt';
import { Configuration, OpenAIApi, ChatCompletionRequestMessage } from 'openai';
@Injectable()
export class GptService {
private readonly openAiApi: OpenAIApi;
constructor(
private configService: ConfigService,
private jwtService: JwtService,
) {
const configuration = new Configuration({
organization: this.configService.get<string>('CHAT_GPT_ORGANIZATION_ID'),
apiKey: this.configService.get<string>('CHAT_GPT_API_KEY'),
});
this.openAiApi = new OpenAIApi(configuration);
}
}Nest에서 제공하는 @nestjs/config를 사용하기 위해서는 app.moudle.ts에 ConfigModule을 설정해주어야 한다.
//app.module.ts
@Module({
imports: [
GptModule,
ConfigModule.forRoot({
isGlobal: true,
envFilePath: '.env',
}),
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}그렇게 .env에서 설정한 CHAT_GPT_ORGANIZATION_ID 와 CHAT_GPT_API_KEY로 OpenAI API 사용을 위한 설정을 마친다.
🔎 Chat Completions 사용하기
GPT 응답 요청
Chat Completions API를 사용하기 위해 설정해두운 OpenAiApi를 통해 새로운 Chat Completion을 생성할 수 있다.
async getResFromGpt(prompt: string, context?: any) {
const reqToGpt = [
...context,
{ role: 'user', content: this.replacingText(prompt) },
];
const resFromGpt = await this.openAiApi.createChatCompletion({
model: this.configService.get<string>('CHAT_GPT_MODEL'),
messages: reqToGpt,
temperature: 1.5,
max_tokens: 300,
});
const chatLog = [...reqToGpt, resFromGpt.data.choices[0].message];
return {
messages: resFromGpt.data.choices[0].message,
chatLog,
};
}getResFromGpt는 GPT에게 요청사항을 보내 응답을 받아오는 API이다. 그 중, 가운데 resFromGpt가 실제 OpenAI API를 통해 응답을 받아오는 함수이다. createChatCompletion의 매개변수로 GPT 모델과 설정값을 포함시킬 수 있다.
(* 파라미터에 대한 자세한 설명은 Open AI Doc을 참고하세요)
CHAT_GPT_MODEL은 .env에 gpt-3.5-turbo로 설정해두었고, messages는 위 reqToGpt로 받아오며, temperature은 GPT의 동일한 답변을 방지하기 위해 설정했으며, max_tokens는 돈이 없어 적게 설정하였다.
사용자의 요청에 대한 응답값은 resFromGpt.data.choices[0].message을 통해 받아올 수 있으며, 이 값을 요청한 객체에 포함하여 채팅 로그를 저장하였다. ( GPT가 다음 응답을 하기 위해 이전 채팅에 대한 경험이 필요하기에 )
그렇다면, GPT에게 요청하기 앞서 GPT를 어떻게 길들였을까?
GPT 길들이기
야생의 GPT에게 받아오는 응답들은 내가 원하는 응답의 형식과는 매우 멀기 때문에, 초기에 GPT에게 메세지를 전달하여 길들일 필요가 있다.
이번 프로젝트에서 GPT에게 요구하는 응답 형식을 작성하여 나열해보았다.
요청은 여행지와 여행 일수에 대해서 올 것이고 너는 요청에 맞춰 추천하는 여행 계획을 세워줘.
응답하기 전에 지켜야하는 규칙들이 몇 가지 있어.
1. n일 여행을 요구받을 때, 각 요일 앞에 'n Day:' 를 붙여줘.
2. JSON 형식으로 답변해야해
3. `n Day`와 장소 이름을 제외하고 띄어쓰기나 \n을 제거해줘
4. 구체적인 장소만 명시하고 추가적인 설명을 붙이지마
5. 단순히 계획만 답변하고 서론이나 결론은 답변하지마
6. 모든 장소 이름은 영어로 답변해
출력 예시)
{"Day 1": [ first day recommended places ],"Day 2": [ second day recommended places],"Day 3": [ third day recommended places ]}`한국어가 영어보다 더 많은 토큰을 소모하기 때문에 영어로 작성했고,
물론 이것보다 더 구체적으로 작성하였다.
이렇게 적은 요청사항이 GPT에게 보내는 메세지 중 system의 role을 갖는 content에 해당한다.
그리고 한 번 더 명확히 하기 위해 user role을 갖는 content에는
너는 최고의 여행 계획을 세워주는 planner bot이야 이런 식으로 적었으며,
GPT의 응답으로 assistant role을 갖는 모든 규칙을 따르겠다는 답변을 적었다.
basePromptCmd() {
const context: Array<ChatCompletionRequestMessage> = [
{
role: 'system',
content: this.replacingText(
this.configService.get<string>('CHAT_GPT_SYSTEM'),
),
},
{
role: 'user',
content: this.configService.get<string>('CHAT_GPT_USER'),
},
{
role: 'assistant',
content: 'Sure, I will follow all rules.',
},
];
return context;
}각 content는 프로젝트 계획에 따라 중요도가 생길 수 있을 뿐더러, 깔끔하게 보기 위해서 환경변수로 설정하였다.
GPT랑 대화하기
마지막으로 우리가 길들인 GPT와 대화할 시간이다. 하지만 그 전에 생각해봐야할 것이 있다.
우리는 Chat Completions API를 통해 GPT에게 응답을 받아오기 때문에 우리는 GPT가 이전 메세지를 저장해야 하는 경우와, 저장하지 않아도 되는 경우로 구분지어 요청할 수 있다.
즉, 처음 요청을 할 경우에는 이전 채팅이 없으니, basePromptCmd만 보내면 되고 그 이후, 채팅을 이어갈 경우에는 첫 요청에 GPT의 응답과 두번째 요청을 담아 다시 GPT한테 보내게 된다.
async chatCompleGpt(prompt: string, context?: any) {
if (!context) {
const baseCmd = this.basePromptCmd();
const { messages, chatLog } = await this.getResFromGpt(prompt, baseCmd);
return { messages, chatLog };
} else {
const { messages, chatLog } = await this.getResFromGpt(prompt, context);
return { messages, chatLog };
}chatCompleGpt 함수는 개변수에 따라 첫 요청인지, 그 이후 요청인 지 구분할 수 있다.
첫 매개변수인 prompt는 사용자의 요청을 담으며, context는 이전 채팅 로그를 담는다. context는 매개변수로 포함되거나 안될 수 있으며, 포함이 된 경우에는 첫 채팅, 포함이 안된 경우에는 그 이후 채팅으로 구분한다.
그렇게 getResFromGPT로 매개변수를 담아 보내면 GPT는 이전 요청에 대한 정보를 갖는 context에 다음 요청 prompt를 담아 GPT에게 응답을 받고, 그 응답을 다시 chatLog에 담아 messages 와 함께 response로 보내준다.
⭐뽀나스
돈이 없는 학생들은 개발 비용을 최대한, 최대한 줄여야 한다. 하지만 이전 채팅에 대한 기억을 담아 요청을 할 수록 점차 토큰은 배로 불어나기 시작하고 지갑 또한 홀쭉해지기 시작한다.
그래서 토큰 수를 최대한 줄이기 위한 비법아닌 비법을 적용했다.
1. 최대한 영어로 대화하자.
생각보다 한국어가 많은 토큰을 잡아먹는다.
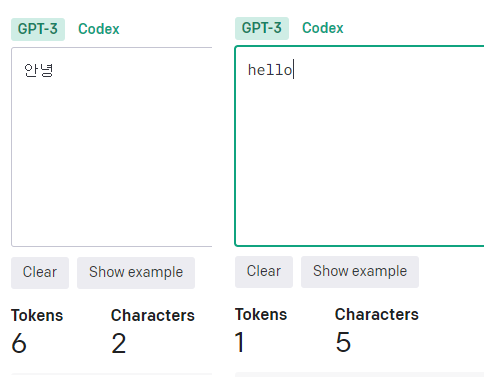
물론 이것만으로는 비교할 수 없겠지만, 매 요청마다 한국어와 영어를 비교해서 토큰 수를 비교한 결과, 항상 두 배 이상은 차이가 난 것 같다. 그렇기 때문에, 영어로 처리할 수 있는 부분은 최대한 처리하면 좋을 것 같다.
파파고 API를 사용하여 번역처리를 넣을까 했지만, 파파고 또한 요금 을 내야하고 파파고의 번역에서 발생한 오류는 직접 수정할 수 없기에 포기하였다.
그래서 최대한 GPT를 활용하기로 결정하였다. system에 설정한 값을 다시 보면, 모든 응답은 영어로 답변하며 구체적인 장소이름을 JSON 형식으로 응답하는 것이다. 우리는 구체적인 장소명을 통해 Google Maps에 표시할 계획이었기 때문에 다행히 한국어의 중요도가 높지는 않았던 것 같다.
2. 최대한 공백을 없애자.
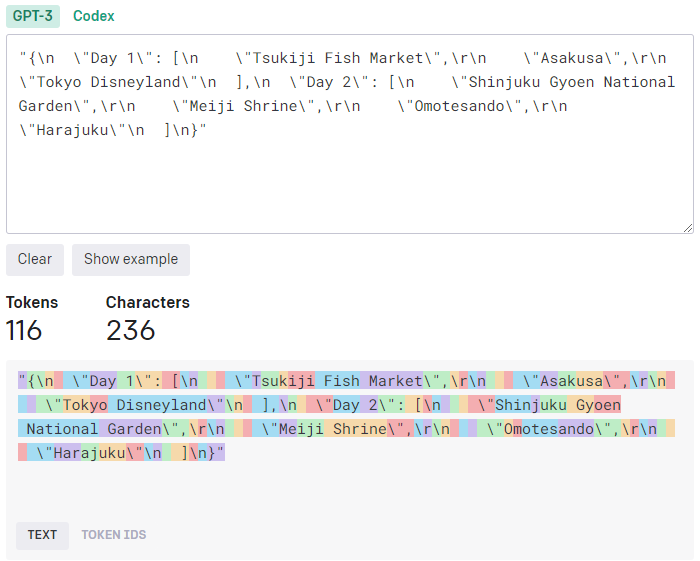
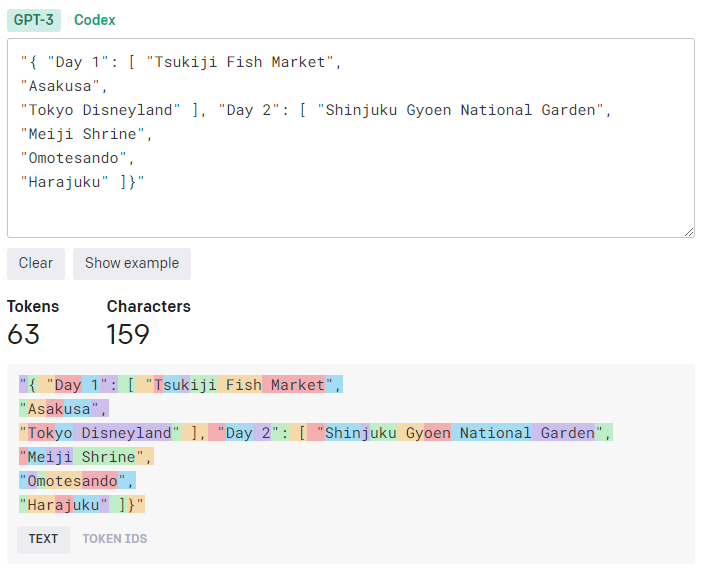
사용자의 요청 또는 GPT의 응답에 불필요한 공백이 많다면 이 또한 토큰으로 정산될 수 있다.
GPT의 응답은 JSON 형식으로 오기 때문에, 사실상 필요없는 공백과 띄어쓰기가 많다. 어차피 JSON 형식의 데이터는 프론트 상에서 장소 데이터를 가져오기 위해 중요하지만, 백에서는 딱히 사용할 일이 없다.
하지만 GPT와의 통신은 백에서 하기 때문에 JSON 형식에서 필요한 부분을 제외한 공백과 띄어쓰기는 제거하고 응답을 받도록 system에 설정하였다.
이렇게 최대한 토큰 수를 줄이는 방법을 고민해보았지만, 난 아직도 과금이 두렵다..!
