📖 Tutorial
Using Pandas to Get Familiar With Your Data
모든 기계학습 프로젝트의 첫 번째 단계는 데이터에 익숙해지는 것입니다. 당신은 이를 위해서 판다 라이브러리를 사용할 것입니다. 판다는 데이터 과작하들이 데이터를 탐색하고 조작하기 위해서 사용하는 주요 도구입니다. 대부분의 사람들은 판다를 pd로 줄여서 말합니다. 이 명령어를 통해 해당 작업을 수행할 수 있습니다.
import pandas as pd판다 라이브러리에서 가장 중요한 부분은 DataFrame입니다. DataFrame은 테이블처럼 생각할 수 있는 데이터들이 저장됩니다. 이는 Excel의 시트나 SQL 데이터베이스와 유사합니다.
판다는 이러한 타입의 데이터로 여러분이 하고 싶어하는 대부분의 것들에 대한 강력한 툴을 제공합니다.
예시로, 호주 멜버른의 주택 가격에 대한 데이터를 살펴보겠습니다. 실습에서는 동일한 프로세스를 아이오와 주의 주택 가격이 있는 새로운 데이터 세트에 작용합니다.
예시(멜버른)의 데이터가 ../input/melbourne-housing-snapshot/melb_data.csv에 위치한다고 해봅시다.
데이터를 로딩하고 확인하기 위해서 다음 명령어들을 입력합니다:
# 쉬운 접근을 위하여 파일 경로를 저장
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# melbourne_data이라는 DataFrame에 데이터를 읽고, 쓴다
melbourne_data = pd.read_csv(melbourne_file_path)
# Melbourne data의 요약정보를 출력한다
melbourne_data.describe()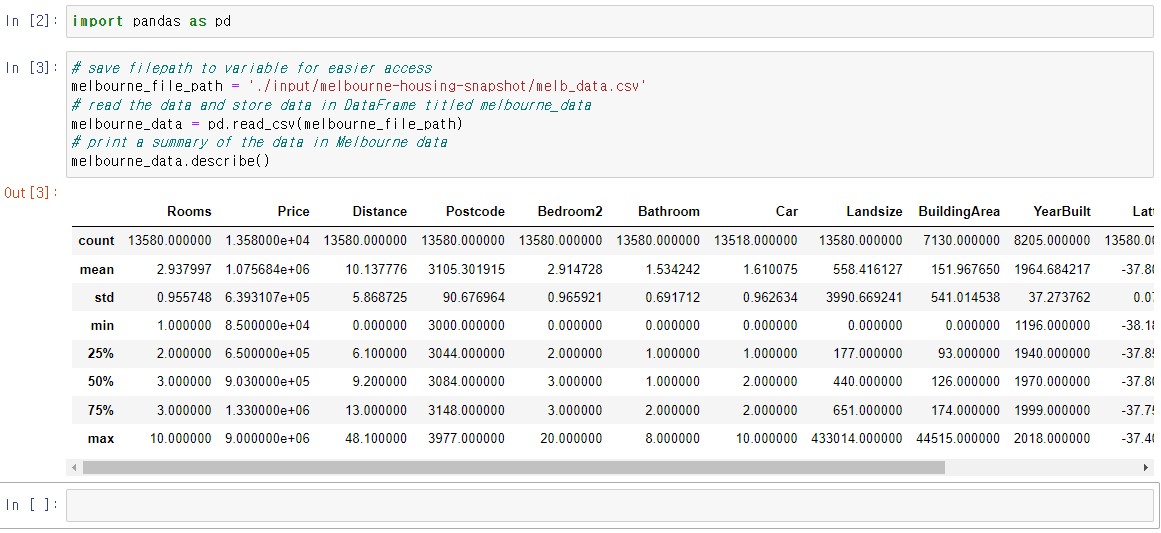
Interpreting Data Description
결과에는 원래 데이터 집합의 각 열에 대한 8개의 숫자가 표시됩니다. 첫 번째 숫자인 count는 결측값이 없는 행의 수를 나타냅니다.
결측값은 여러 이유에 의해 발생합니다. 예를 들어, 두 번째 침실의 크기는 침실이 하나뿐인 주택에서는 데이터가 수집되지 않습니다. 이는 다음에 누락된 데이터에 대한 주제로 더 상세하게 다룰 예정입니다.
두 번재 값은 평균값을 의미하는 mean입니다. 이 아래에 있는 std는 값들이 얼마나 분산되어있는지를 알려주는 표준 편차값을 의미합니다.
min , 25% , 50% , 75% 및 max 값을 이해하기 위해서는 우선 값들을 작은 수부터 큰 수로 나열한다고 가정합니다. 이 때 가장 처음 값(최소)이 min 값입니다. 전체 목록의 1/4를 통과하면 전체 값의 25% 보다는 크고 75% 보다는 작은 값을 찾을 수 있습니다. 이 값이 25%의 값입니다(25th percentile 로 발음됨). 50% 와 75%또한 비슷한 방식으로 정의되며 max는 가장 큰 값을 나타냅니다.
Your Turn
여러분의 첫 코딩 예습을 시작하세요.
