녹음을 진행하면서 wav 파일을 획득하다보면 종종 overrun이 발생한 부분을 확인해서 걸러내기도 하고, timestamp를 확인하고 원하는 시간대의 음성데이터를 추출할 필요성을 느꼇다.
이 외에도 몇몇 이슈가 있지만 raw data를 얻은 그대로 사용하는 것은 통제 영역에서 벗어난 상황이기 때문에 바람직하지 않다고 생각한다.
그래서 필요에 의한 몇 가지 예시를 포스트로 남겨본다.
라이브러리 선정
맨땅에 헤딩하기엔 시간이 부족하고 작업 효율이 안나오기 때문에 작성된 모듈을 이용.
pydub, wave같은 라이브러리도 있지만 Sample Rate 조작이나 원하는 샘플 수만큼 데이터를 나누는 것이 어려워보여 librosa, soundfile사용함.
사용 예시
초기 설정
import numpy as np
import librosa
import soundfile as sf
file_name = 'test.wav'
sample_rate = 192000 # 192KHz
data_length = sample_rate * 60 # 192KHz * 60파일 불러오기
데이터 가져올 때 re-sample을 원하는 경우
def open_wav_with_resample(file_name, bit, origin_rate, new_rate):
data, rate = sf.read(file_name, dtype=bit)
data = data.T
data = librosa.resample(data, origin_rate, new_rate)
return data, new_rate# 변경된 데이터와 샘플레이트 받아옴
wav_data, sample_rate = open_with_resample(file_name, 'float32', sample_rate, 48000)원본 데이터를 원하는 경우
def open_wav(file_name, origin_rate):
data, rate = librosa.load(file_name, sr=origin_rate)
return data, rate# 원본 데이터와 샘플레이트 받아옴
wav_data, sample_rate = open_wav(file_name, sample_rate)파일 조작
특정 부분만 잘라내기
List의 split 함수를 활용하면 간단하게 사용가능.
def split_wav(data, sample_rate, start, end):
start *= sample_rate
end *= sample_rate
return data[start:end]# 3초부터 21초 까지의 데이터만 추출
edited_data = split_wav(data, sample_rate, 3, 21)overrun 검출하기
overrun이 발생할 경우 해당 구간의 데이터는 0이 된다.
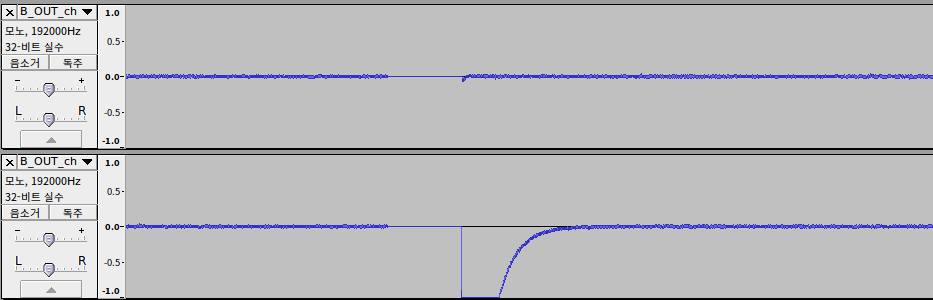
대략 1ms 동안 overrun이 발생하면 초당 192KHz을 한다 가정할 때,
이론상 음성데이터 내부에 192개의 연속적인 0 값이 기록된다.
그렇기 때문에 특정구간에서 0이 반복되는 패턴을 찾으면 overrun 검출이라고 볼 수 있다.
특정 데시벨 이상으로 올라가는 값을 검출하기 위한 솔루션을 찾는다면 아래의 예시보다 더 쉽게 작성할 수 있음.
단순히 음성데이터(현재는 np.array 타입) 내부에 n 이상의 값이 존재하는지 확인만 하면 됨.
def check_overrun(data, sample_rate, runtime)
overrun_size = sample_rate * runtime
target = np.zeros(overrun_size)
snapshot = list()
window = len(target)
possibility = np.where(data == target[0])[0]
for case in possibility:
check = data[case:case+window]
if np.all(check == target):
return True
else:
return False# 0.001초 정도의 길이로 overrun 판단.
runtime = 0.001
# overrun일때 True
is_overrun = check_overrun(data, sample_rate, runtime)저장
librosa 사용하는 경우
16bit 데이터를 열어놨는데 아래와 같이 저장하면 32bit로 fix된 결과물이 나오는 것 같다..?
result_file_name = 'result.wav' librosa.output.write_wav(result_file_name, data, sample_rate)
soundfile을 사용한 경우
나쁘지않은듯
result_file_name = 'result.wav' sample_format = 'PCM_16' # PCM_24, PCM_16 PCM_s8 등 옵션있음. sf.write(result_file_name, data, sample_rate, subtype=sample_format)

웹 백엔드 합니다.