가장 처음으로 할 일은,
- 현재 nvidia 그래픽 카드가 장착 되어 있고, 드라이버가 설치 되어 있다.
- nvcc (nvidia cuda compiler) 가 버전에 맞게 설치 되어 있다.
- nvidia 그래픽 카드의 정보와 데이터를 내 프로그램으로 읽어 온다.
그러면 그래픽 카드에 matrix 연산을 cpu 가 아닌 cuda 를 통한 gpu 에서 할 준비가 된다.
main
int main(int argc, char *argv[])
{
InitCUDA();
return 0;
}로 시작해보자.
InitCUDA()
check cuda device
bool bResult = false;
int nDevID;
int nDeviceCount = 0;
// cuda device count 를 가져온다.
if (cudaSuccess != cudaGetDeviceCount(&nDeviceCount)){
return false;
}
// cuda property 를 구조체로 설정하고,
struct CUDA_DEVICE_PROPERTY {
cudaDeviceProp prop;
int iDeviceID;
};
// 갯수 만큼의 배열을 만들어
CUDA_DEVICE_PROPERTY devProp[nDeviceCount] = { 0, };
std::cout << "# of Cuda device [" << nDeviceCount << "]" << std::endl;
for ( int i = 0; i < nDeviceCount; i++ ){
// property 의 정보를 가져온다.
if (cudaSuccess != cudaGetDeviceProperties(&devProp[i].prop, i)){
return false;
}
if (devProp[i].prop.major < 2){
continue;
}
// PCI : Peripheral Component Interconnect
std::cout << "===========================" << std::endl;
std::cout << "ID : [" << i << "] \n"
<< "Name : [" << devProp[i].prop.name << "] \n"
<< "PCI Bus ID : [" << devProp[i].prop.pciBusID << "] \n"
<< "Clock Rate : [" << devProp[i].prop.clockRate << "] \n"
<< "with compute : [" << devProp[i].prop.major << "." << devProp[i].prop.minor << "]"
<< std::endl;
}
Compute capability (version)
- 현재, 나의 테스트 환경은 RTX 3060 이므로, major 8, miner 6 으로 표시된다.
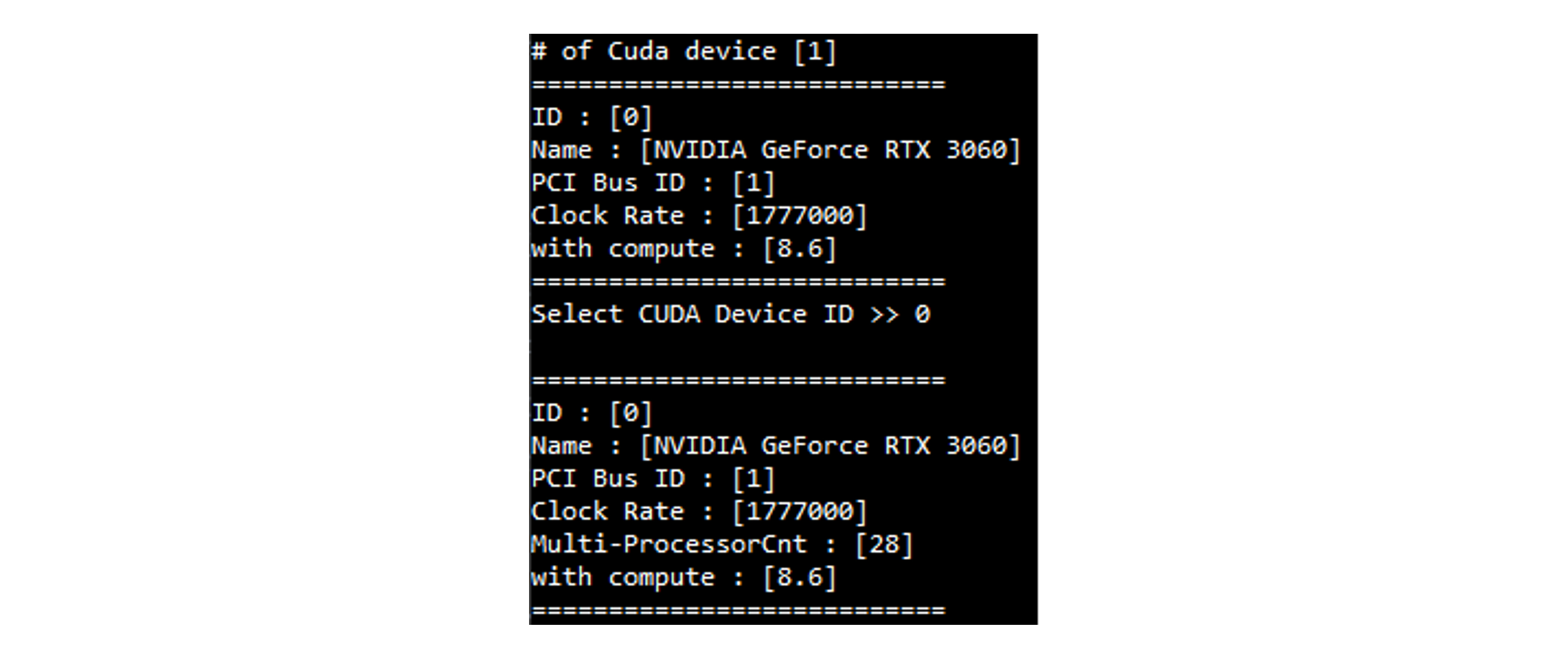
$ ./main
# of Cuda device [1]
===========================
ID : [0]
Name : [NVIDIA GeForce RTX 3060]
PCI Bus ID : [1]
Clock Rate : [1777000]
with compute : [8.6]Select device and load property
int nSelectedDeviceID;
std::cout << "===========================" << std::endl;
std::cout << "Select CUDA Device ID >> ";
std::cin >> nSelectedDeviceID;
// Device 선택 후
if (cudaSuccess != cudaSetDevice(nSelectedDeviceID)) {
return false;
}
cudaDeviceProp propSel;
// 선택된 device 의 property 를 loading 한다.
cudaGetDeviceProperties(&propSel, nSelectedDeviceID);
// PCI : Peripheral Component Interconnect
// 가저온 device 의 정보를 가져온다.
std::cout << std::endl;
std::cout << "===========================" << std::endl;
std::cout << "ID : [" << nSelectedDeviceID << "] \n"
<< "Name : [" << propSel.name << "] \n"
<< "PCI Bus ID : [" << propSel.pciBusID << "] \n"
<< "Clock Rate : [" << propSel.clockRate << "] \n"
<< "Multi-ProcessCnt : [" << propSel.multiProcessorCount << "] \n"
<< "with compute : [" << propSel.major << "." << propSel.minor << "]"
<< std::endl;
std::cout << "===========================" << std::endl;property 가 잘 load 되었다.
-
이제 선택된 device 에 작업을 진행 할 예정이다.
-
cudaDeviceProp 정보.
/** * CUDA device properties */ struct __device_builtin__ cudaDeviceProp { char name[256]; /**< ASCII string identifying device */ cudaUUID_t uuid; /**< 16-byte unique identifier */ char luid[8]; /**< 8-byte locally unique identifier. Value is undefined on TCC and non-Windows platforms */ unsigned int luidDeviceNodeMask; /**< LUID device node mask. Value is undefined on TCC and non-Windows platforms */ size_t totalGlobalMem; /**< Global memory available on device in bytes */ size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */
현재 check 된 CUDA device 에서 번 선택.
Select CUDA Device ID >> 0
===========================
ID : [0]
Name : [NVIDIA GeForce RTX 3060]
PCI Bus ID : [1]
Clock Rate : [1777000]
Multi-ProcessorCnt : [28]
with compute : [8.6]
===========================select device
- 일단 device 에 대해 global variable 로 두고 가져다 사용할 수 있게 한다.
/* CUDA_Util.h */
enum GPU_SELECT_MODE
{
FIRST_PCI_BUS_ID,
LAST_PCI_BUS_ID,
MAX_GFLOPS,
MIN_GFLOPS,
SPECIFY_DEVICE_ID,
GPU_SELECT_MODE_LAST = SPECIFY_DEVICE_ID
};
struct GPU_INFO
{
char szDeviceName[256];
DWORD smPerMultiproc;
DWORD clockRate;
DWORD multiProcessorCount;
float TFlops;
};
/* main.cpp */
// Initialize GPU_INFO
GPU_INFO g_GPUInfo = { 0, };
/* ... */
strcpy(g_GPUInfo.szDeviceName, propSel.name);
// propSel.kernelExecTimeoutEnabled;
DWORD smPerMultiProc;
if ( 9999 == propSel.major && 9999 == propSel.minor ) {
smPerMultiProc = 1;
} else {
smPerMultiProc = (DWORD)_ConvertSMVer2Cores(propSel.major, propSel.minor);
}
g_GPUInfo.smPerMultiproc = (DWORD)smPerMultiProc;
g_GPUInfo.clockRate = (DWORD)propSel.clockRate;
g_GPUInfo.multiProcessorCount = (DWORD)propSel.multiProcessorCount;
UINT64 KFlops = (UINT64)(DWORD)propSel.multiProcessorCount *
(UINT64)(DWORD)smPerMultiProc *
(UINT64)(DWORD)propSel.clockRate * 2;
// FLOPS, FLoating point Operations Per Second
// per second 부동 소수점 연산 횟수. (11.8628)
g_GPUInfo.TFlops = (float)KFlops / (float)(1024 * 1024 * 1024);
if (0 != propSel.concurrentManagedAccess) {
g_bCanPrefetch = propSel.concurrentManagedAccess;
}
return true;