02. matrix op test with CUDA

target
목표는 약 1억개 bytes 의 점을 Matrix 한 개로 변환할 예정.
/* CUDA_Util.h */
#ifndef __CUDA_UTIL_H__
#define __CUDA_UTIL_H__
typedef unsigned long DWORD;
typedef unsigned long long UINT64;
typedef wchar_t WCHAR;- 약 1억개 bytes 의 점을 사용할 예정.
const DWORD VERTEX_COUNT = 1024 * 1024 * 100;design matrix
- 점 배열과 matrix 한 칸이 있어야 한다.
- CPU memory 에 값을 써 놓고, transfer 시켜서 GPU 에 일을 시켜야 한다.
- Matrix memory 를 할당하기 위해 Matrix structure 만들자.
- float 가 들어가는 64 byte memory 이다.
struct MATRIX4
{
union
{
struct
{
float _11;
float _12;
float _13;
float _14;
float _21;
float _22;
float _23;
float _24;
float _31;
float _32;
float _33;
float _34;
float _41;
float _42;
float _43;
float _44;
};
struct
{
float f[4][4];
};
};
};memory handling with CUDA
MATRIX4* pMatHost = nullptr;
MATRIX4* pMatDev = nullptr;- 기본적으로 system memory 영역과 GPU memory 영역이 따로 있다.
- cuda device, GPU 가 어떤 일을 처리하려면, GPU memory 에서 읽어야 한다.
- GPU Memory 에는 CPU 에 연결된 system memory 가 포함되지 않는다.
- CPU 는 system memory 만 access 하고, GPU 는 GPU memory 만 access 한다.
- 그 둘 사이의 통신은 PCI bus 를 통해서 한다.
- cudaMallocHost
cudaMallocHost(&pMatHost, sizeof(MATRIX4));- system memory 를 할당 하는 것. 어떤 함수던, "Host" 가 붙으면 system memory 와 관련 있다.
- malloc, new 와 상관 없이 별 차이가 없는데, paging 이 안되는 메모리로 잡는 차이가 있다.
- system 에서 작업할 때는 "Host" 에 작업하고 GPU 로 copy 한다.
- GPU 에서 연산 작업이 끝난 다음 다시 CPU 쪽으로 copy 를 한다.
- 보통 Host, Device 가 pair 로 들어가서 같은 size memory 를 짝으로 만든다.
- 이 작업이 디버깅이 어렵다.
- cudaMallocHost 를 사용하여 CPU 에서 사용할 수 있는 system memory 에 matrix 를 만든다.
- FillMatrix
void FillMatrix(MATRIX4* pOutMat)
{
SetIdentityMatrix(pOutMat);
for (DWORD y = 0; y < 4; y++){
for(DWORD x = 0; x < 4; x++){
pOutMat->f[y][x] = (float)((rand() % 10) + 1)/10.0f;
}
}
}FillMatrix(pMatHost);- 64 개의 숫자를 채워주는 함수를 design.
- random 으로 64 개의 숫자를 채워주는 것 뿐.
- cudaMalloc 를 호출한다. 이와 같이 Host 가 안 붙은 함수들은 GPU Memory 가 된다.
cudaMalloc(&pMatDev, sizeof(MATRIX4));- cudaMallocHost 에서 만든 것과 대응되는 똑같은 size 로 gpu memory 를 만든다.
- device 간 data 이동을 위해 cudaMemcpy 를 호출한다.
// CPU -> GPU : Matrix 를 copy 해준다.
cudaMemcpy(pMatDev, pMatHost, sizeof(MATRIX4), cudaMemcpyHostToDevice);- 일반적인 c 함수 에서의 memcpy design 은
NAME
memcpy - copy memory area
SYNOPSIS
#include <string.h>
void *memcpy(void *dest, const void *src, size_t n);1st param 이 destination. 2nd param 이 source.
- cudaMemcpy 도 똑같이 design.
// cuda_runtime_api.h
/**
...
* \param dst - Destination memory address
* \param src - Source memory address
* \param count - Size in bytes to copy
* \param kind - Type of transfer
...
**/
extern __host__ cudaError_t CUDARTAPI cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);- 맨 마지막 parameter 가 중요. 어느 방향으로 갈 것이냐 정의 되어 있다.
// driver_types.h
/**
* CUDA memory copy types
*/
enum __device_builtin__ cudaMemcpyKind
{
cudaMemcpyHostToHost = 0, /**< Host -> Host */
cudaMemcpyHostToDevice = 1, /**< Host -> Device */
cudaMemcpyDeviceToHost = 2, /**< Device -> Host */
cudaMemcpyDeviceToDevice = 3, /**< Device -> Device */
cudaMemcpyDefault = 4 /**< Direction of the transfer is inferred from the pointer values. Requires unified virtual addressing */
};create data
1억개의 점을 모두 random 으로 채우면 시간이 오래걸리므로, Sampling 할 점을 1024 개 만든 다음에 그 1024 개를 돌려가면서 사용.
const DWORD SAMPLE_VERTEX_COUNT = 1024;
float4* pSampleVertexList = new float4[SAMPLE_VERTEX_COUNT];
for (DWORD i = 0; i < SAMPLE_VERTEX_COUNT; i++)
{
FillVector4(pSampleVertexList + i);
}- FillVector4
void FillVector4(float4* pf4Out)
{
float* pf = &pf4Out->x;
for (DWORD i = 0; i < 4; i++) {
pf[i] = (float(rand() % 10) + 1) / 10.0f;
}
}Random 하게 숫자를 채워가능 함수. 이와 같이 1024 개의 점을 채워 넣은 다음 데이터를 변환.
transfer data to CUDA
float4* pSrcVertexListHost = nullptr;
float4* pDestVertexListHost = nullptr;
float4* pSrcVertexListDev = nullptr;
float4* pDestVertexListDev = nullptr;- float4 는 CUDA 에서 지원해 주는 built-in type. align 되는 16byte.
// vector_types.h
struct __device_builtin__ __builtin_align__(16) float4
{
float x, y, z, w;
};size : 16byte VERTEX_COUNT
- 전달할, 입력 전 시스템 배열 : pSrcVertexListHost
- 출력, 결과가 들어갈 Vertex 시스템 배열 : pDestVertexListHost
- cudaMallocHost 를 사용하여 system memory 로 잡는다.
cudaMallocHost(&pSrcVertexListHost, sizeof(float4) * VERTEX_COUNT);
cudaMallocHost(&pDestVertexListHost, sizeof(float4) * VERTEX_COUNT);- 전달할, 입력 전 CUDA 배열 : pSrcVertexListDev
- 출력, 결과가 들어갈 Vertex GPU 배열 : pDestVertexListDev
- cudaMalloc 를 사용하여 GPU memory 로 잡는다.
cudaMalloc(&pSrcVertexListDev, sizeof(float4) * VERTEX_COUNT);
cudaMalloc(&pDestVertexListDev, sizeof(float4) * VERTEX_COUNT);- pSampleVertexList 에 전부 Random 하게 값을 뽑으면 너무 느려서 1024 개를 따로 만든다.
- 이것을 pSampleVertexListHost 에 돌아가면서 계속 채워 넣는다.
- 1억 개의 점들을 Source 의 System memory 에 넣는다.
for (DWORD i = 0; i < VERTEX_COUNT; i++){
pSrcVertexListHost[i] = pSampleVertexList[i % SAMPLE_VERTEX_COUNT];
}- CUDA code 를 호출하기 위해서 공급을 해주어야 한다.
- GPU 에서 사용할 Memory 는 확보하였지만, 거기에 값을 채워야 한다.
- GPU 에서 작업 시킬 데이터를 CPU memory 에서 GPU memory 로 옮기는 작업.
// CPU -> GPU : 입력으로 들어갈 Vertex 배열, source 배열을 copy 해준다.
cudaMemcpy(pSrcVertexListDev, pSrcVertexListHost, sizeof(float4) * VERTEX_COUNT, cudaMemcpyHostToDevice);- CPU GPU
- Matrix 를 copy 해준다.
sizeof(MATRIX4)- 입력으로 들어갈 Vertex 배열, source 배열을 copy 해준다.
sizeof(float4) * VERTEX_COUNT
이제 Data 가 준비 되었다.
cuda code
지금부터 나오는 code 는 kernel.cu 파일 안에 있는 코드이다.
- cpp 파일은 clang (gcc) 등의 c-compiler 가 컴파일을 한다.
- cu 파일은 nvcc (Nvidia Compiler) 가 한다.
- CUDA code 가 들어가야 하는 것은 모두 .cu 로 따로 파일을 빼서 작업한다.
- CUDA code 와 상관 없는 부분들은 최대한 분리 시킨다.
- 이들은 묶어서 dynamic library 로 빼서 관리하는 것이 좋겠지..
(func) LaunchKernel_ConstMemory
- GPU memory 를 일을 시키는 함수.
LaunchKernelConstMemory(pDestVertexListDev, pSrcVertexListDev, pMatDev, VERTEX_COUNT);- pDestVertexListDev : Destination, GPU Memory.
- pSrcVertexListDev : Source, GPU Memory
- pMatDev : Matrix pointer
- VERTEX_COUNT : Number of vertices
현재 이 함수는
각각의 Thread 는 src vertex 하나를 읽어서 matrix 에 곱한 다음, dest 에 써놓은 것.
- 점이 1억개 인데, 쓰레드 1억개를 GPU 쓰레드가 쓸 수 있긴 하지만..
- 그렇게 사용하지는 않고, 동시에 돌릴 수 있는 갯수는 당연히 한정 되어 있다.
- 돌릴 수 없는 것은 Queue 에 대기 시켜 사용하는 것이 일반적, 약 65만으로 제한 걸었다.
- 10 억개를 한 번에 호출하면, crash 가 날 수도 있고, driver 가 내려갔다 올라올 수도 있다.
const DWORD MAX_VERTEX_NUM_PER_ONCE = 65536 * 10;while 로 loop 을 돌면서, 제한 갯수인 65만개씩 잘라서 쓰고 있다.
- 한 번에 scheduling 될 수 있는, 한 번에 GPU 한테 일을 시키는
( 동시에 실행 되는 것은 절대 아니다. cuda core 는... ) - 한 번에 던져서 활성화 될 수 있는 pending 되는 thread 자체는 약 65만개가 Max.
while (dwVertexNum)
{
DWORD dwVertexNumPerOnce = dwVertexNum;
if ( dwVertexNumPerOnce > MAX_VERTEX_NUM_PER_ONCE ) {
dwVertexNumPerOnce = MAX_VERTEX_NUM_PER_ONCE;
}block 당 thread 개수, 여기서는 max 가 1024 개 이다.
- 알고리즘과 관련된 부분, 예시라서 그런데, Thread 하나당 점 한개를 맡기로 했다.
- 나중에 더 다양한 테스트 프로그램을 만들면서, 올라가면서 최적화가 필요하다.
- 현재는 최대한 block 당 쓸 수 있는 만큼의 thread 를 준 것이다.
const DWORD THREAD_NUM_PER_BLOCK = 1024; // 32 - 1024 threads.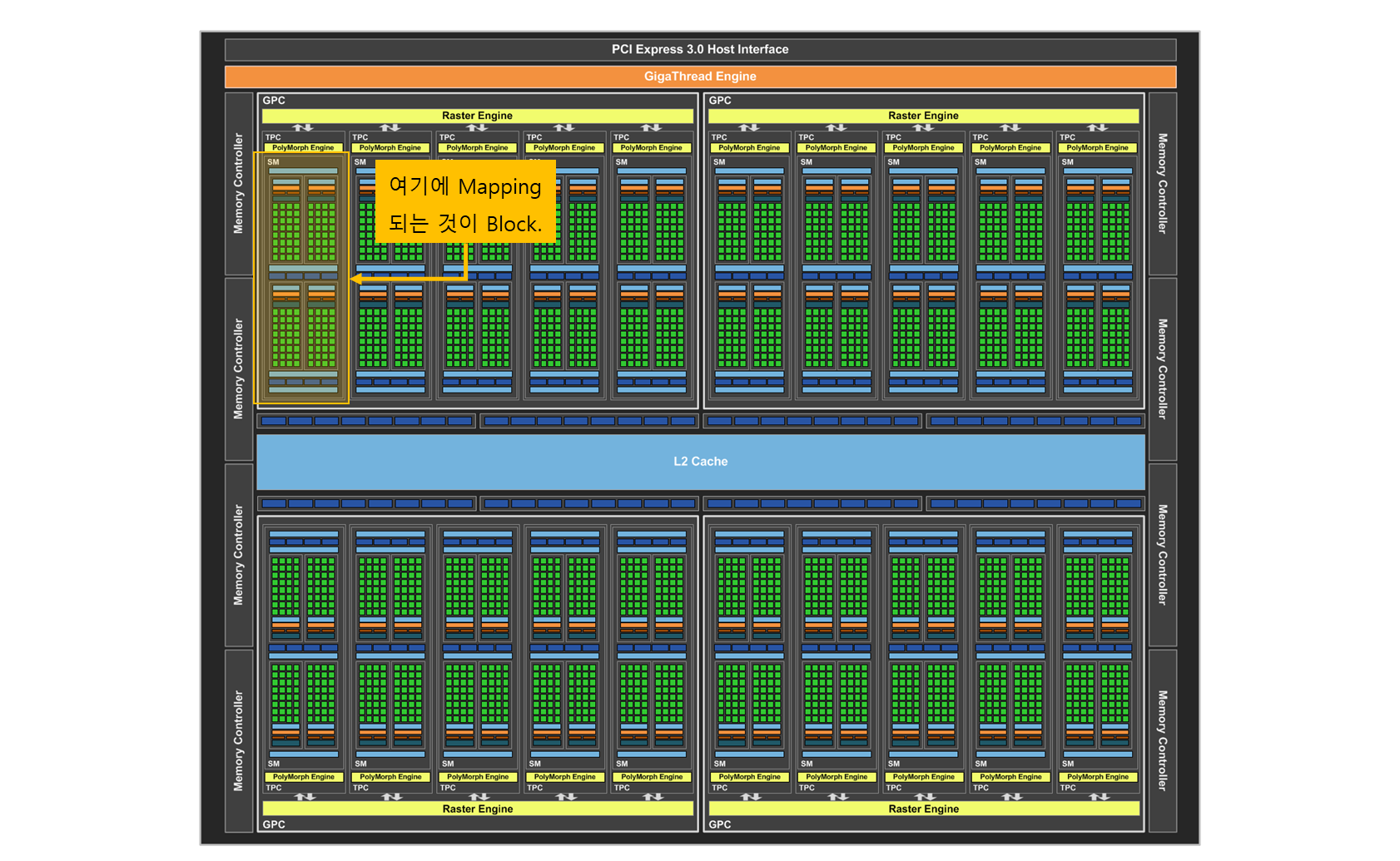
- 이 안에서 몇 개의 thread 를 사용할 지 결정해야 하는데, 최대 1024 개를 사용할 수 있다.
- 이런 코드 같이 한 번에 thread 를 잡을 경우 최대로 잡아 주는 것이 효과가 좋다고 한다.
- block 활용은 경험치, 조정하면서 몸으로 체득해야 하는 부분인 듯 하다.
Memory type 이 Global, Constant, Texture memory 으로 구성되어 있다. (물론 더 있지만..)
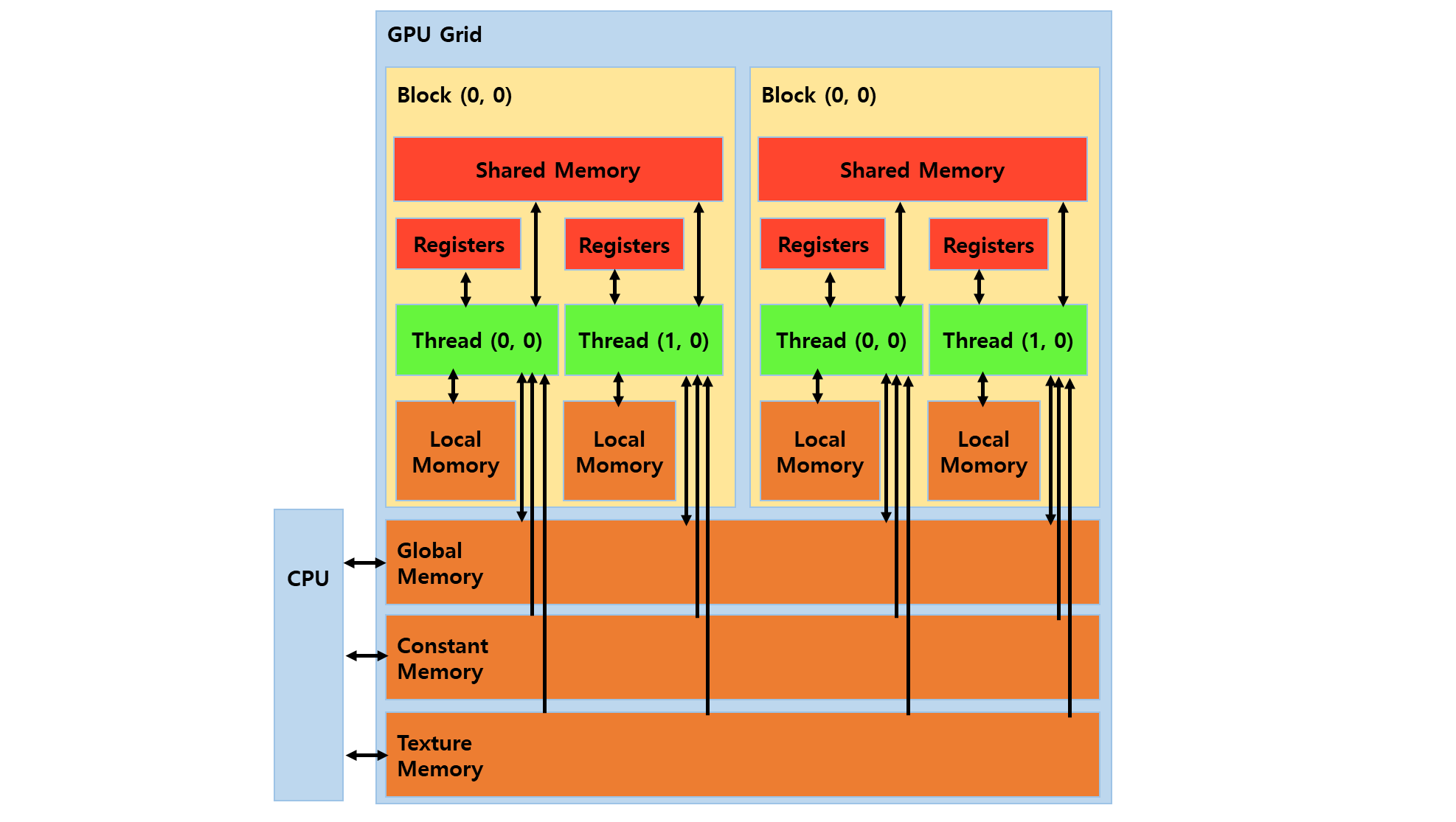
이들 memory 가 물리적으로 다르지는 않지만
- constant memory : GPU 하드웨어에 구현된 읽기 전용 64KB mem (caching)
- 가능하면 constant memory 에 기록하려 한다.
- matrix 같은 경우, 그 않에 쓸 것이 아니라 읽기만 할 것이다.
- caching 되므로, 속도가 조금이라도 빠르기 때문이다.
constamt memory 에 넣기 위해서 API 를 호출한다. (VerifyCudaError 는 나중에..)
VerifyCudaError(cudaMemcpyToSymbolAsync(g_mat, pMatDev, sizeof(MATRIX4), 0, cudaMemcpyDeviceToDevice));constant memory 에 넣을 데이터는 constant 로 선언을 한다.
// kernel.cu
__constant__ MATRIX4 g_mat;- thread 계산에 있어서 pixel 당 thread 로 고정하는 것 보다는 단위적으로 계산할 갯수를 thread 로 정하는 것이 좋다. 그 후에 architecture 내의 block 내의 thread 를 고민.
- 1억 개의 vertex 를 처리 할 때까지 loop 를 돌면서 호출할 것이다.
while (dwVertexNum)
{
DWORD dwVertexNumPerOnce = dwVertexNum;
if ( dwVertexNumPerOnce > MAX_VERTEX_NUM_PER_ONCE ) {
dwVertexNumPerOnce = MAX_VERTEX_NUM_PER_ONCE;
}
dim3 threadPerBlock(1, 1);
dim3 blockPerGrid(1, 1, 1);- dim3 : dimension 3. 항목 3개.
reference
// vector_types.h
struct __device_builtin__ dim3
{
unsigned int x, y, z;
#if defined(__cplusplus)
#if __cplusplus >= 201103L
__host__ __device__ constexpr dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
__host__ __device__ constexpr dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
__host__ __device__ constexpr operator uint3(void) const { return uint3{x, y, z}; }
#else
__host__ __device__ dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
__host__ __device__ dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
__host__ __device__ operator uint3(void) const { uint3 t; t.x = x; t.y = y; t.z = z; return t; }
#endif
#endif /* __cplusplus */
};
물론, 현재 RTX 40 series 는 block 수가.. 엄청 많겠지... 만..
- 이 board design 은 block 이 총 20개가 있으므로, 1024 * 20 개의 thread 를 동시에 사용 가능.
- 필요한 block 갯수가 640 개가 필요하다.
- 1024 개수로 나누어 떨어지지 않으면 한 block 을 더 써야 하므로...
- 뒤에 나머지를 구해서 block 을 하나 더 추가하는 코드를 붙였다.
thread 가 1024 개 쓸것이라 정하고, 약 65만개를 처리해야 하므로, 640 개의 block 이 정해진다. 정확히는, 이라는 계산이 나온다.
threadPerBlock.x = THREAD_NUM_PER_BLOCK;
threadPerBlock.y = 1;
blockPerGrid.x = (dwVertexNumPerOnce / THREAD_NUM_PER_BLOCK) + ((dwVertexNumPerOnce % THREAD_NUM_PER_BLOCK) != 0);
blockPerGrid.y = 1;- threadPerBlock : 1024 개를 쓸 것이다고 정하였다. (1024, 1, 1)
- blockPerGrid : 이 GPU 에서 block 을 몇 개 쓸 것인가. (640, 1, 1)
인데, 실제 개수는 이다. 여기서는 총 개수가 중요하다. 프로그램 짜기 편하라고 3차원으로 되어 있다.
- scheduler 에 대기시키는 block 수 : 1024 개의 thread 가 묶여 있는 640 개를 pending.
- 그 중에 scheduler 가 허용하는 것은 연산 하고, 못 돌아 가는 것은 대기 queue 에 있다.
- memory latency 가 발생하면, 그 때, 대기중에 있는 block 을 올려서 scheduling 한다.
(func) VerifyCudaError
Kernel 함수 호출은 비동기적으로 호출 되어서, 엄밀히 따지면 호출하고 나서 끝난 것이 아니다. 실행 조차 안되어 있을 수 있다. Kernel 함수 호출이 끝난 것을 어떻게 알 수 있을까?
- Kernel function call check
KernelTransformVector4ConstMemory <<< blockPerGrid, threadPerBlock, 0 >>> (pf4DestDev, pf4SrcDev, dwVertexNumPerOnce);
VerifyCudaError(cudaDeviceSynchronize());- cudaDeviceSynchronize
- 함수를 호출하면, 끝날 때 까지 block 이 걸리고 wait 이 된다.
- return 값이 있는데, error 값 별로 분리를 해두었다. 0 (success) 아니면 모두 에러.
reference
// driver_types.h
/**
* CUDA error types
*/
enum __device_builtin__ cudaError
{
/**
* The API call returned with no errors. In the case of query calls, this
* also means that the operation being queried is complete (see
* ::cudaEventQuery() and ::cudaStreamQuery()).
*/
cudaSuccess = 0,
/**
* This indicates that one or more of the parameters passed to the API call
* is not within an acceptable range of values.
*/
cudaErrorInvalidValue = 1,
/**
* The API call failed because it was unable to allocate enough memory or
* other resources to perform the requested operation.
*/
cudaErrorMemoryAllocation = 2,
// (.. 중략 ..)이 enum error 선언을 handling 하는 함수를 구현.
void VerifyCudaError(cudaError _err)
{
std::string wchErr = "Unknown";
switch(_err) {
case cudaErrorMemoryAllocation:
wchErr = "cudaErrorMemoryAllocation";
break;
case cudaErrorLaunchFailure:
wchErr = "cudaErrorLaunchFailure";
break;
case cudaErrorLaunchTimeout:
wchErr = "cudaErrorLaunchTimeout";
break;
case cudaErrorMisalignedAddress:
wchErr = "cudaErrorMisalignedAddress";
break;
case cudaErrorInvalidValue:
wchErr = "cudaErrorInvalidValue";
break;
case cudaSuccess:
wchErr = "cudaSuccess";
break;
}
if (cudaSuccess != _err) {
printf("cuda error = %s(%d)\n", wchErr.c_str(), _err);
}
}문제없이 돌아가면 멈추지 않고 연산을 하면서,
pDestDev += dwVertexNumPerOnce; // 써 놓을 vertex 위치를 뒤로 옮긴다.
pSrcDev += dwVertexNumPerOnce; // 읽을 vertex 위치를 뒤로 옮긴다.
dwVertexNum -= dwVertexNumPerOnce; // 처리 할 vertex 갯수도 줄여나간다.1억개의 vertex 갯수 완료 될 때 까지 loop 이 돈다.
(Kernel) Kernel_TransformVector4_ConstMemory
다시 돌아와서 문제 없을 시 Kernel 관련 코드를 보자.
KernelTransformVector4ConstMemory <<< blockPerGrid, threadPerBlock, 0 >>> (pf4DestDev, pf4SrcDev, dwVertexNumPerOnce);"<<<" 3 개를 붙여서 KernelTransformVector4ConstMemory 함수에 parameter 를 집어 넣는다.
__global__ void KernelTransformVector4ConstMemory(float4* pf4Dest, float4* pf4Src, DWORD dwVertexNum)
{
DWORD ThreadIndex = blockIdx.x * blockDim.x + threadIdx.x;
if (ThreadIndex >= dwVertexNum){
return;
}
cuTransformVector4(pf4Dest + ThreadIndex, pf4Src + ThreadIndex, &gMat);
}- global 이 붙은 것은 kernel 함수이다. 모든 thread 가 이 함수를 호출하게 된다.
- 개념적, 이론적으로는 동시에 호출 된다고 하지만, real world 에서는 동시는 아니다.
blockIdx, blockDim, threadIdx 등은
// device_launch_parameters.h
uint3 __device_builtin__ __STORAGE__ threadIdx;
uint3 __device_builtin__ __STORAGE__ blockIdx;
dim3 __device_builtin__ __STORAGE__ blockDim;에 정의 되어 있으며,
- blockPerGrid : {x=640, y=1, z=1} : blockDim = 640 : [0 ~ 639]
- threadPerBlock : {x=1024, y=1, z=1} : [0 ~ 1023]
수치는 위에서 정의하였다.
- dest 와 src 는 둘 다 global memory 에 있다.
- global memory 는 보통 말하는 video memory.
- rtx 4090 Ti 8G : 여기서 8G 를 말한다.
DWORD ThreadIndex = blockIdx.x * blockDim.x + threadIdx.x;- blockIndex 가 0 이면
- blockIdx.x : 0, blockDim.x : 640, threadIdx.x : 0 = 0
- 따라서 vertexIndex : 0
cuTransformVector4(pDest + ThreadIndex, pSrc + ThreadIndex, &g_mat);- 0 번 vertex 를 load 를 해서 ( ThreadIndex = 0 )
(func) cuTransformVector4
__host__ __device__ __inline__ void cuTransformVector4(float4* pf4Dest, float4* pf4Src, MATRIX4* pMat)
{
float4 r;
r.x = pf4Src->x * pMat->_11 + pf4Src->y * pMat->_21 + pf4Src->z * pMat->_31 + pf4Src->w * pMat->_41;
r.y = pf4Src->x * pMat->_12 + pf4Src->y * pMat->_22 + pf4Src->z * pMat->_32 + pf4Src->w * pMat->_42;
r.z = pf4Src->x * pMat->_13 + pf4Src->y * pMat->_23 + pf4Src->z * pMat->_33 + pf4Src->w * pMat->_43;
r.w = pf4Src->x * pMat->_14 + pf4Src->y * pMat->_24 + pf4Src->z * pMat->_34 + pf4Src->w * pMat->_44;
*pf4Dest = r;
}- 4 차원 vector 하나를 Matrix 를 곱하는 함수이다.
- 0 번 vertex 를 변환 후 pDest + ThreadIndex ( 0th destination ) 에 저장.
- 1023 번 vertex 를 변환 후 pDest + ThreadIndex ( 1023 번째 destination ) 에 저장.
- blockIndex 가 1 이면
- blockIdx.x : 1, blockDim.x : 640, threadIdx.x : 0 = 0
- 따라서 vertexIndex : 640
- 실제 ThreadIndex 는 65만 까지 갈 것, 각각의 Vertex 들한테 쓰레드 하나씩 붙어서 처리.
- 한 번에 처리하므로 loop 가 없다. 65 만개의 vertex 가 동시에 행렬에 대해 곱해진다.
Conclusion
- GPU Memory, CUDA malloc 로 할당한 GPU Memory 에 각 Vertex 들의 Matrix 를 곱한 값으로 들어갔다.
LaunchKernelConstMemory(pDestVertexListDev, pSrcVertexListDev, pMatDev, VERTEX_COUNT);
- 그것을 CPU 에서 읽을 수 있게 cudaMemcpy 로 가져오면 끝난다.
cudaMemcpy(pDestVertexListHost, pDestVertexListDev, sizeof(float4) * VERTEX_COUNT, cudaMemcpyDeviceToHost);
- 이 예시는 cpu 최적화, intel SSE (SIMD) 최적화 코드 와 cpu multi-core thread 를 사용하면 따라잡을 수 있는 코드라고 한다. 실제, cpu 최적화 부분도 중요하다.
Appendix
CudaMallocManaged
자료 구조 (예를 들어 Tree 등) 를 GPU 상으로 구현할 때가 있다.
- 메모리 pointer 를 child 로 가지고 있는데, 그것을 gpu 구조로 옮기려면 복잡해진다.
- system memory pointer 를 GPU 로 copy 할 때 GPU address 로 변환 해야 한다.
- 수동으로 변환하기 귀찮고, 짜기 힘들어서 CUDA Unified Memory 라는 것이 있다.
통합 Address system (아직 안해봐서 잘 모른다.. 해볼 예정.)
- CUDA Malloc Managed 를 호출하면 address 가 나오는데 cpu, gpu 모두에서 사용 가능.
- page falut 를 이용해서 내부적으로 copy 가 일어난다.
- 그러나 프로그래머가 봤을 때는 하나의 address 인데 GPU 에서 가능하고, CPU 에서도 가능한 메모리이다. (와...;;)
- 이와 같은 경우 CudaMemcpu 를 호출 할 필요가 없다.
- 문제는 좀 있을듯.. 속도면도 그렇겠지만.. 4090 까지 나오면서 업뎃 되었겠지만..
