policy iteration
- Policy Iteration 이란, Policy Evaluation 과 Policy Improvement 가 계속해서 반복되는 과정.
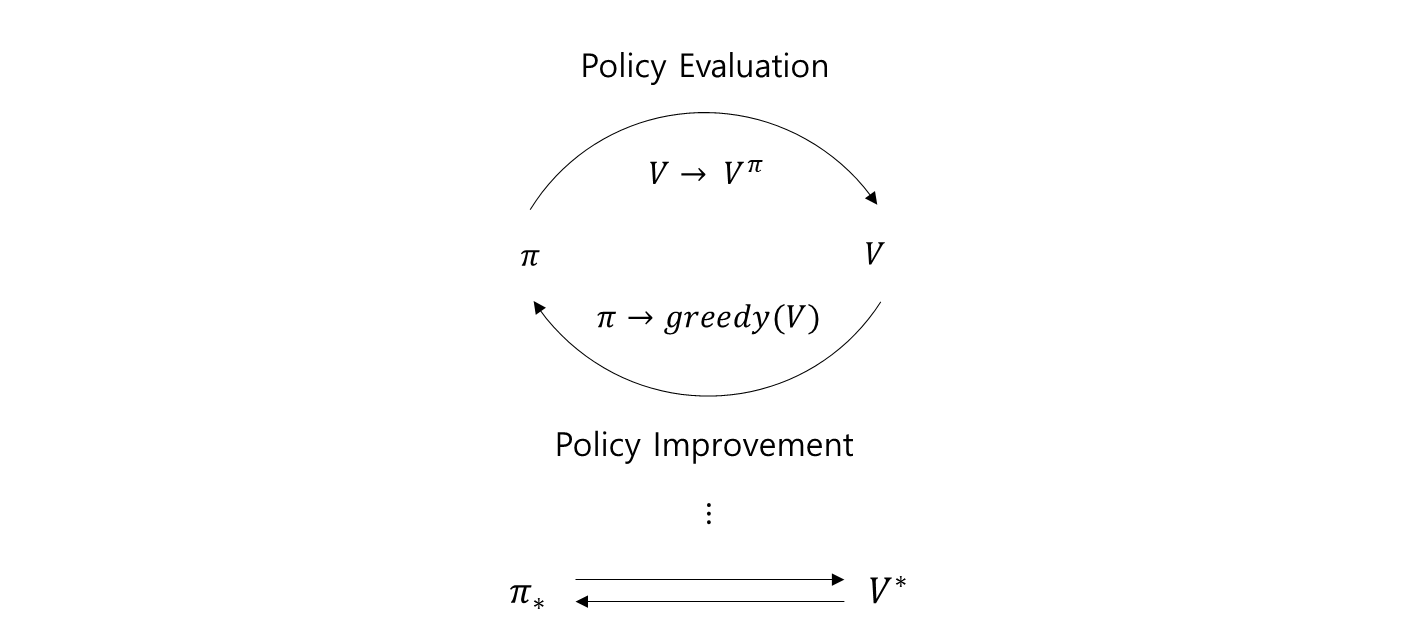
- Policy Evaluation 은 아래의 Value function 이 수렴하도록 특정 policy π 에 대해 Value function 으로 수렴하도록 여러 스텝을 진행.
- 그 후 Policy Evaluation 을 1-step 혹은 짧게 k-step 만 진행한다고 이야기 했다.
value iteration
- Value Iteration 이란, Policy iteration 의 한 가지 방법.
- Value Iteration 이 바로 Policy Evaluation 을 1 step 만 진행한다.
Vk+1(s)=a∑s′∑p(s′∣s,a)π(a∣s)[R(s,a,s′)+γVk(s′)]for all s∈S 이와 같이 Policy Evaluation 식을 1-step 만 진행한다.
- Policy Improvement 는 아래와 같이
위 두 가지 식을 결합해서 하나의 식으로 쓸 수 있다.
- 1-step policy evaluation +
argmax policy improvement→Vk+1(s)=amaxs′∑p(s′∣s,a)[r+γVk(s′))]
- Vk 에 대해서 Action-Value function 을 최대화 하는 action 에 대한 값으로 설정.
- 1-step policy evaluation 과 argumax policy improvement 가 합쳐져서 나온 식.
- Value Iteration 의 업데이트 식이라고 할 수 있다.
deep dive on value iteration
-
π0(a∣s)⎩⎪⎨⎪⎧10if a=aargmaxQπk(s,a)else
Action-Value function 값. Qπk(s,a)=s′∑p(s′∣s,a)[r+γV0(s′)]
이 값을 최대화 하도록, π0(a∣s) 를 모든 state 에 대해서 만들 것이다.
π0(a∣s)⎩⎪⎪⎨⎪⎪⎧10if a=aargmaxs′∑p(s′∣s,a)[r+γV0(s′)]else
-
V1(s)=a∑s′∑p(s′∣s,a)π0(a∣s)[R(s,a,s′)+γV0(s′)]for all s∈S
V1(s) 가 위의 식에 대해서 계산되는데, π0(a∣s) 를 뜯어보면
V1(s)=a∑ s′∑p(s′∣s,a) π0(a∣s) [R(s,a,s′)+γV0(s′)]
이 추출된 식을 최대화 하는 행동만, 확률이 1 이 된다.
따라서 a∑ 가 모든 a 에 대해서 따질 필요가 없고, 이 값을 최대화 하는 행동 하나만 따지면 된다.
V1(s)=a∑s′∑p(s′∣s,a)[r+γV0(s′)]
Value Iteration 식과 동일하다. V1(s) 를 가지고 π1(s) 를 만들 수 있고, V2(s) 를 만들 수 있다.
이와 같이 반복적으로 하다보면, a∑πi(a∣s) 의 값이 똑같이 max operator 로 바뀐다.
어떤 k 에 대해서도 결과적으로 Value Iteration 식이 표현된다.
- 1-step policy evaluation +
argmax policy improvement 가 결합된 식이다..→Vk+1(s)=amaxs′∑p(s′∣s,a)[r+γVk(s′))]
pseudo code
한 번에 업데이트 하는 것처럼 식이 보인다. Value Iteration 을 표현하면 아래와 같이 표현된다.
Initialize V0(s) for all s∈S
Set δ>0,Δ=δ and k=0
While Δ≥δ
Set Δ=0
For s∈S
Vk+1(s)=amaxa′∑p(s′∣s,a)[r+γVk(s′)]
Δ=max(Δ∣Vk+1(s)−Vk(s)∣)
k=k+1
Output a deterministic policy π
For s∈S
amax=aargmaxs′∑p(s′∣s,a)[r+γVk(s′)]
π(amax∣s)=1
-
모든 State 에서 정의 되는 Value Function 을 초기화 한다.
Initialize V0(s) for all s∈S
-
Value Iteration 이 충분히 수렴했는지 판별하기 위한 값인 δ 를 설정 ( threshold ).
k 는 얼마나 value iteration step 이 돌았는지 저장하는 변수.
Set δ>0,Δ=δ and k=0
-
Value Iteration 이 수렴하지 않았다고 하고, value iteration 을 반복.
While Δ≥δ
-
Δ=0 은 Value Function 의 변화량을 계속해서 저장할 변수.
Set Δ=0
-
모든 State 에 대해서 Iteration 식을 적용한다.
For s∈S
-
이 변화량 중에, 모든 State 에 대해서, 가장 큰 값이 Δ 에 저장.
-
이 식은 policy improvement 와 one-step policy evaluation 이 동시에 합해진 식.
Vk+1(s)=amaxa′∑p(s′∣s,a)[r+γVk(s′)]
-
Δ 의 Value Function 의 변화량 중 가장 큰 값을 저장하기 위해 max 를 취해 Δ 를 업데이트.
Δ=max(Δ∣Vk+1(s)−Vk(s)∣)
- 모든 State 에 대해서 이 과정이 끝나면, k 를 1 증가 시켜준다.
k=k+1
Value Function 의 변화량이 크지 않을 때, threshold 미만으로 떨어졌을 때.
Output a deterministic policy π : deterministic policy π ( optimal policy ) 를 출력.
For s∈S
이때 얻게되는 value function 이 Optimal Value function 이라고 생각할 수 있다.
amax=aargmaxs′∑p(s′∣s,a)[r+γVk(s′)]
π(amax∣s)=1
- 모든 State 에 대해서, 마지막으로 얻은 Value Function 을 최대화하는 행동을 얻고,
- 그 행동에 대해서만 그 State 에서 확률을 1 로 설정해준다.
이러면 나머지 모든 행동에 대한 확률은 자동으로 0 이 된다. 확률은 모든 행동에 대해서 합하면 1 이 되어야 하기 때문이다. 이렇게 해서 최종적으로 Optimal Policy 와 Optimal Value function 을 출력해준다.
Policy Evaluation 을 한 스텝만 진행하면서 Policy Improvement 를 진행하는 이 과정을 계속해서 반복하면, Optimal Value Function 을 얻을 수 있을까?
possible in just 1-step?
Value Iteration 은 Policy Evaluation 을 1-step 만 진행함.
- 그럼에도 불구하고, optimal policy 와 optimal value function 으로 수렴.
Value Iteration 업데이트 식은 아래와 같다.
Vk+1(s)=amaxs′∑p(s′∣s,a)[r+γVk(s′)] for all s∈S
Vk 을 가지고 Vk+1 을 만들었다. Vk 가지고 얻을 수 있는 action value 중에 가장 큰 값을 Vk+1 에 Value 로 설정해주었다. 이것을 모든 state 에 대해서 반복했다.
- 모든 state 에 대한 value function Vk 로부터 Vk+1 을 얻는 함수 (mapping) 을 T∗ 라 표현 하면 아래와 같이 표현 가능하다.
Vk+1=T∗(Vk),Vk∈Rn 한 state 에 대한 value function 이 아니라, 모든 state 에 대한 value function 을 나타내는 이 vector Vk 가 T∗ 를 거쳐서 Vk+1 이 된다.
이 과정을 모든 state 에서 반복한 것을 T∗ 라고 표현한 것.
- 이때 (complete) metric space (Rn,d∞) 에 대해 T∗ 는 contraction mapping 이다. → Contraction mapping theorem 적용 가능!
d∞(x,y)=∥x−y∥∞=p→∞lim(∣x1−y1∣p+⋯+∣xn−yn∣p)p1=max(∣x1−y1∣,⋯,∣xn−yn∣) 어느 두 점 사이의 거리에 대한 metric 으로 사용될 수 있다.
contraction mapping
-
Contraction mapping theorem 이란?
Let (X,d) be a complete metric space with a contraction mapping T:X→X.
Then ( 이 2 개가 Contraction mapping theorem 의 명제 )
-
there exists a unique vector x∗ satisfying x∗=T(x∗)
- 유일한 fixed point x∗ 를 갖는다. transformation 을 적용해도, 값이 같다.
-
x∗ can be obtained from an arbitrary point x0=T(x∗)
Define xn+1=T(xn)
then n→∞limxn=x∗.
- transformation 을 임의의 점에서 시작하여, 무한히 계속 적용하면 결국에는 x∗, fixed point 로 수렴한다.
-
Contraction mapping theorem 에 의해 아래의 결과가 성립.
-
T∗ 의 유일한 fixed point 는 optimal value function V∗ 이다.
-
k→∞limVk=V∗
- 시작점은 어느 지점이든 간에 상관 없다. 어떻게 초기화된 Value Function 에서 시작해도,
- 계속해서 T∗ 를 적용하면, 결과적으로 Optimal Value Function 을 얻을 수 있다.
그래서 Value Iteration 을 계속 반복하면 Optimal Value Function 으로 수렴한다.
T∗ 가 (Rn,d∞) 에서 contraction mapping 인가?
Vk+1(s)=amaxs′∑p(s′∣s,a)[r+γVk(s′)] for all s∈S
⟶T∗(Vk)(s)=amaxs′∑p(s′∣s,a)[r+γVk(s′)]
contraction mapping 이 되는지 확인해보자.
- 임의로 초기화 된 두 Value Vector 가 있다고 가정하자.
V1,V2 여기서 ∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣ 차이의 절대 값을 살펴보자.
mathematical proof
∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣
=∣∣∣∣∣amaxs′∑p(s′∣s,a)[r+γV1(s′)]−amaxs′∑p(s′∣s,a)[r+γV2(s′)]∣∣∣∣∣
- T∗(V1(s))≥T∗(V2(s))≥C2
-
∣∣∣T∗(V1(s))−C2∣∣∣≥∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣
-
amax1=aargmaxs′∑p(s′∣s,a)[r+γV1(s′)]
-
뒤의 항 amaxs′∑p(s′∣s,a)[r+γV2(s′)] 을 최대화로 만드는 행동은 따로 있는데, 대신 amax1 로 최대화 하는 행동을 넣으면 원래 값보다 작아지게 된다.
-
앞의 항에 대해서는 최대화 하는 행동은 당연히 amax1 이 된다.
T∗(V1(s))≥T∗(V2(s))≥ s′∑p(s′∣s,amax1)[r+γV2(s′)]
A≥B≥C 일 때, ∣A−B∣≤∣A−C∣ 가 되는데, 사이가 더 벌어졌기 때문이다.
∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣≤∣∣∣T∗(V1(s))−C2∣∣∣=∣∣∣∣∣T∗(V1(s))−s′∑p(s′∣s,amax1)[r+γV2(s′)]∣∣∣∣∣=∣∣∣∣∣s′∑p(s′∣s,amax1)[r+γV1(s′)]−s′∑p(s′∣s,amax1)[r+γV2(s′)∣∣∣∣∣=γ∣∣∣∣∣s′∑p(s′∣s,amax1)[V1(s′)−V2(s′)]∣∣∣∣∣
- 원래 V1(s′)−V2(s′) 은 양수 혹은 음수가, s′∑p(s′∣s,amax1) 이런 식으로 평균 내어진 것.
- 이 값을 전부 양수로 바꾸어 버리면, 평균 값도 크거나 같아지게 된다.
∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣≤γ∣∣∣∣∣∣s′∑p(s′∣s,amax1)[V1(s′)−V2(s′)]∣∣∣∣∣∣
≤γs′∑p(s′∣s,amax1)∣∣∣V1(s′)−V2(s′)∣∣∣ : [ 차이 값의 평균 ]
≤γs′max∣∣∣V1(s′)−V2(s′)∣∣∣ : [ 차이 값 중에 가장 큰 것 ]
=γ∥V1−V2∥∞ : [ vector 의 표현이므로 s′ 이 빠지게 된다. ]
- C1≤T∗(V1(s))≤T∗(V2(s))
C≤A≤B 일 때, ∣A−B∣≤∣C−B∣ 가 되는데, 위와 마찬가지로 사이가 더 벌어졌기 때문.
∣T∗(V1(s))−T∗(V2(s))∣≤∣C1−T∗(V2(s))∣
∣T∗(V1(s))−T∗(V2(s))∣=∣∣∣∣∣amaxs′∑p(s′∣s,a)[r+γV1(s′)]−amaxs′∑p(s′∣s,a)[r+γV2(s′)]∣∣∣∣∣
-
amax2=aargmaxs′∑p(s′∣s,a)[r+γV2(s′)]
-
s′∑p(s′∣s,amax2)[r+γV1(s′)]≤T∗(V1(s))
T∗(V1(s))=amaxs′∑p(s′∣s,a)[r+γV1(s′)] 를 보면, 최대화 하도록 행동을 고른다.
-
앞의 항 amaxs′∑p(s′∣s,a)[r+γV1(s′)] 를 최대화로 만드는 행동은 따로 있는데, 대신 amax2 로 최대화 하는 행동을 넣으면, 원래 값보다 작아지게 된다.
-
뒤의 항에 대해서는 최대화 하는 행동은 당연히 amax2 가 된다.
∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣≤∣∣∣C1−T∗(V2(s))∣∣∣=∣∣∣∣∣s′∑p(s′∣s,amax2)[r+γV1(s′)]−T∗(V2(s))∣∣∣∣∣=∣∣∣∣∣s′∑p(s′∣s,amax2)[r+γV1(s′)]−s′∑p(s′∣s,amax2)[r+γV2(s′)]∣∣∣∣∣≤γ∣∣∣∣∣s′∑p(s′∣s,amax2)[V1(s′)−V2(s′)]∣∣∣∣∣
- V1(s′)−V2(s′) 양수 혹은 음수가, γs′∑p(s′∣s,amax2) 이런 식으로 평균 내어진 것.
- 이 값을 전부 양수로 바꾸어 버리면, 평균 값도 거 크거나 같아지게 된다.
∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣≤γ∣∣∣∣∣∣s′∑p(s′∣s,amax2)[V1(s′)−V2(s′)]∣∣∣∣∣∣
≤γs′∑p(s′∣s,amax2)∣∣∣V1(s′)−V2(s′)∣∣∣ : [ 차이 값의 평균 ]
≤γs′max∣∣∣V1(s′)−V2(s′)∣∣∣ : [ 차이 값 중에 가장 큰 것 ]
=γ∥V1−V2∥∞ : [ vector 의 표현이므로 s′ 이 빠지게 된다. ]
conclusion
따라서 결론적으로
∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣≤γ∥V1−V2∥∞
이건 특정 state s 가 정해진 것이 아니라, 임의의 state s 에 대해서 항상 성립 하는 것.
- ∥T∗(V1)−T∗(V2)∥∞ 중 제일 큰 것,
즉, ∣∣∣T∗(V1(s))−T∗(V2(s))∣∣∣ 여기서 s 가 될 수 있는 값 중에 제일 큰 것을 가져와도,
- ∥T∗(V1)−T∗(V2)∥∞≤γ∥V1−V2∥∞ 이 성립한다.
여기서 T∗ 가 의미하는 것은 (Rn,d∞) 에 대해서, Contraction Mapping 이 된다.
Transformation 을 거친 두 점 사이의 거리,
d∞(T∗(V1),T∗(V2))≤γd∞(V1,V2)
여기서 0≤γ<1 로 설정되면, Contraction Mapping 이 될 수 있다. 그래서, T∗ 즉, Value Iteration 에 쓰이는 Mapping 이 Contraction Mapping 이라는 것을 확인했다.
