(det)erminant
- determinant 가 0 이면, inverse matrix 가 존재하지 않는다.
- 0 에 가까워지면, 그 행렬이 inverse matrix 가 존재하지 않을 가능성이 크다.
det 의 특성
-
normalization
- I(n×n) 는 identity matrix.
- n×n 의 identity matrix 의 determinant 는 1, det(I)=1
-
row operations
- replacement : R1←R1+nR2 : det 가 변하지 않는다.
- interchange : R1↔R2 : det 의 부호 (sign) 가 바뀐다.
- scaling : R2←S⋅R2 : scaling 을 하게 되면 그 만큼 det 가 곱해진다.
-
이와 같은 성질은
임의의 주어진 행렬을 Gaussian Elimination 으로 Identity matrix 로 만든 다음, 위 성질에 대입해서 Original Matrix A 의 det 를 계산, 구하는데 사용한다.
-
예시 1
∣∣∣∣∣∣∣100020007∣∣∣∣∣∣∣
⇒∣∣∣∣∣∣∣100020007∣∣∣∣∣∣∣R2←21R22∣∣∣∣∣∣∣100010007∣∣∣∣∣∣∣R3←71R37⋅2∣∣∣∣∣∣∣100010001∣∣∣∣∣∣∣=14
-
예시 2
∣∣∣∣∣∣∣100220347∣∣∣∣∣∣∣
⇒∣∣∣∣∣∣∣100220347∣∣∣∣∣∣∣R2←21R22∣∣∣∣∣∣∣100210327∣∣∣∣∣∣∣R3←71R37⋅2∣∣∣∣∣∣∣100210321∣∣∣∣∣∣∣R2←R2−2R314∣∣∣∣∣∣∣100210301∣∣∣∣∣∣∣⟶14∣∣∣∣∣∣∣100010000∣∣∣∣∣∣∣=14
off-diagonal term 을 없애는 연산들은 모두 replacement. 따라서 det 가 변하지 않는다.
det 의 물리적인 의미
-
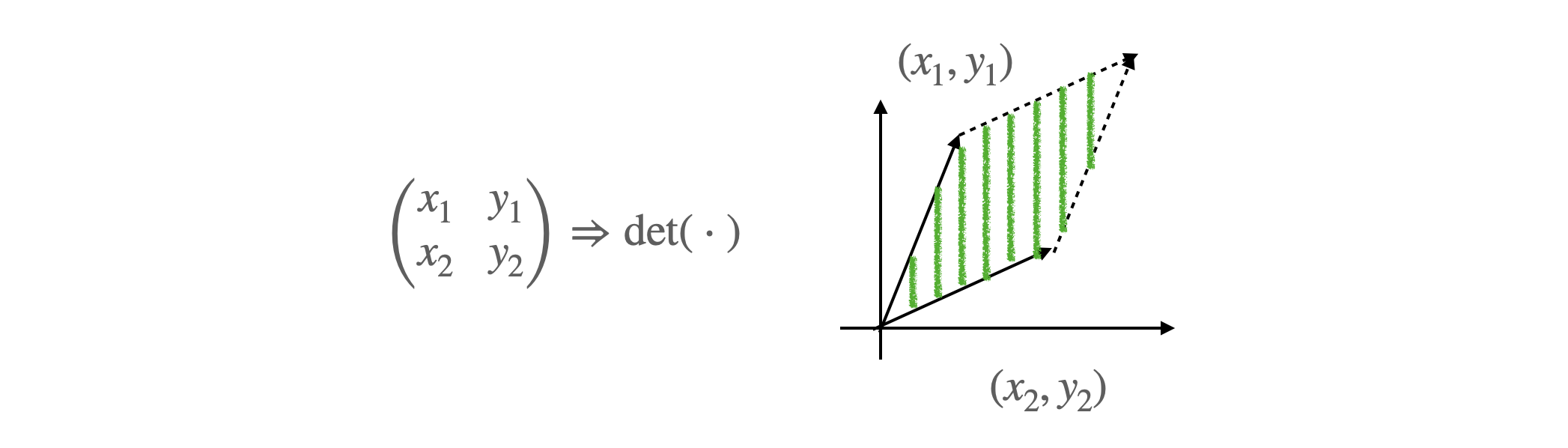
matrix 의 column 들이 이루어지는 공간의 면적을 의미.
-
2×2 matrix 의 det 는 2D 공간 속에서 (x1,x2),(y1,y2) 두 점으로 이루어진 평행 사변형의 면적. 3D, 4D 로 보게되면 generalize version
-
matrix 가 만들어 낼 수 있는 공간의 크기와도 이어져 물리적인 의미가 된다.
-
사용 예시로는
- Normalizing flow 에서 change of variable 이 존재하는데,
- 일반적인 det 를 계산하는 것도, n×n 도 오래 걸리는데,
이럴 때 upper triangle matrix 의 det 는 diagonal matrix 의 product 성질이고, linear 하게 풀 수 있다. computation efficiency.
-
Normalizing flow 는 추후에 다시 다룰 예정.
잘 사용하지 않았던 성질들이 최근 deep learning 에서 많이 사용.
- determinant (det) property
- det(A)=0⟺A 는 역행렬이 존재 하지 않는다.
- det(AB)=det(A)⋅det(B)
- det(A−1)=det(A)1
- det(A⊤)=det(A)
determinant (det) 란
- 행렬이 가질 수 있는 basis vector 들이 만들어내는 공간의 부피이다.
- matrix 의 column 들을 하나의 vector 로 본다면,
- column 이 2개면 평행 사변형의 공간 면적
- column 이 3개면 공간의 부피
- 어떤 두 개의 공간 A,B 가 있는데,
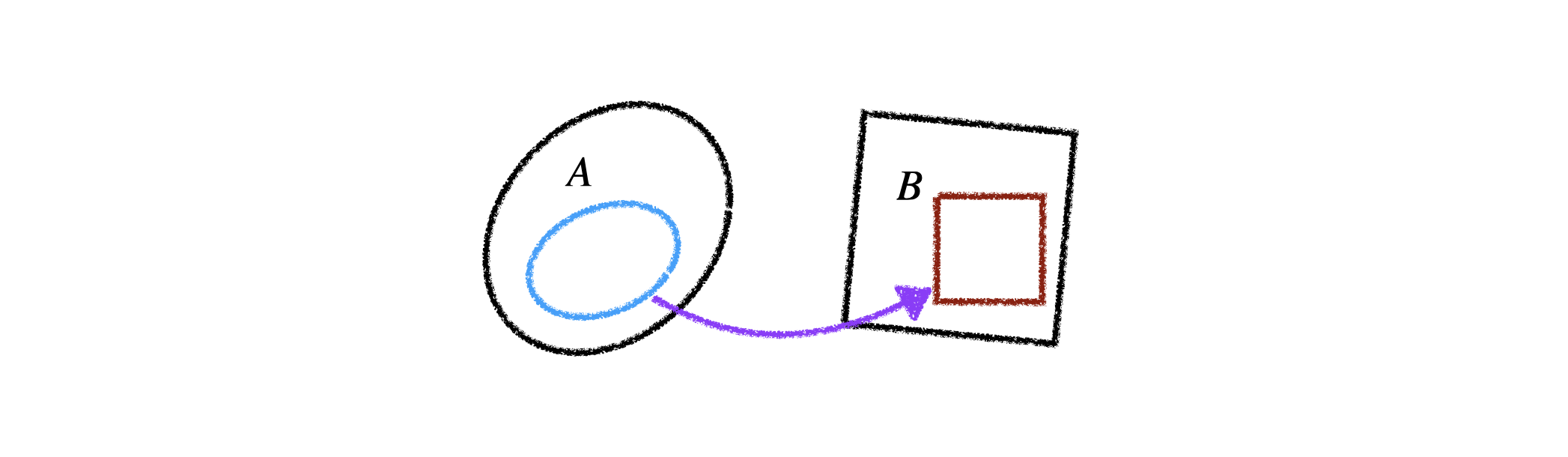
A 에서 B 로 넘어갈 때, A 의 (점, 선, 면적) 이 B 로 갔을 때, Linear map 이면 해당되는 matrix 가 determinant 만큼 늘어나게 된다. 이런 것이 면적, 부피에 해당한다.
eigenvalue, eigenvector
matrix 에 대해 생각을 할 때, 쉽게 이해하기 위해서 square matrix A∈Rn×n 이라고 가정하자.
definition
An eigenvector of A is a non-zero xs.t.Ax=λx for some scalar λ.
이 성질을 만족하는 것의 x 가 eigenvector 이고, 이 때의 λ 는 eigenvalue 이다.
example 1
-
eigenvalue 를 먼저 찾고, 각 eigenvalue 에 해당하는 eigenvector 를 찾는다.
-
eigenvalue 는 unique 하게 계산되지만, eigenvector 는 이것을 만족하는 모든 x 가 eigenvector 가 된다.
-
Example : A=[3113] 의 eigenvector 들을 찾는다.
⇒∣A−λI∣=∣∣∣∣∣3−λ113−λ∣∣∣∣∣=(AD−BC)=(3−λ)2−1=0
⇒λ2−6λ+8=(λ−2)(λ−4)=0∴λ1=2,λ2=4
-
λ1=2 에 해당하는 eigenvector 를 찾는다.
(A−2I)x1=0⇒[1111]x1=0 따라서 [1111] 에 대한 null space 에 해당하는 어떤 x1 을 잡아도 이것은 eigenvalue λ=2 에 대응되는 eigenvector 가 된다.
-
[1111]x1=0 에 만족하는 모든 x1 , [1−1], [2−2],⋯,[n−n] 모두 eigenvector 가 된다.
-
eigenvalue 가 2 에 해당하는 eigenvector 는 x1=[1−1] 혹은 이것으로 span 되는 모든 vector 들이다.
-
마찬가지로 λ2=4 역시 [11],⋯,[nn] 로 span 되는 span{[11]} 의 모든 vector 들이다.
-
이러한 span 되는 공간을 eigenspace 라고 부르기도 한다.
-
A−λI 가 있을 때, 이것의 null space 가 모두 eigenvectors 가 된다.
-
이때의 λ 는 characteristic polynomial 를 통해서 구해진 λ.
example 2
-
[acbd] 의 det 를 찾는다.
⇒∣∣∣∣∣acbd∣∣∣∣∣R2←R2−ac⋅R1∣∣∣∣∣a0bd−acb∣∣∣∣∣=a(d−acb)=ad−bc
이러한 operation 은 값을 변화 시키지 않는다.
- det 를 구할 때, upper triangular matrix 까지 구하면, det 는 diagonal elements 의 곱 이므로 a,b,c,d 인 2×2 차원 행렬이 있을 때, ad−bc 가 된다.
triangluar matrix 의 determiname 는 diagonal matrics 의 곱 이다.
example 3
-
3×3 matrix A=⎣⎢⎡3002603102⎦⎥⎤ 에 대해서 Eigenvector 를 찾는다.
full matrix 는 계산이 너무 어렵게 된다. null space, row space, column space 와 같은 개념을 잡는 것이 더 중요하다. triangle matrix 만 보자.
-
characteristic polynomial 을 계산해보면 ∣A−λI∣ 가 되고,
⇒∣A−λI∣=∣∣∣∣∣∣∣3−λ0026−λ03102−λ∣∣∣∣∣∣∣=(3−λ)(6−λ)(2−λ)=0
⇒λ1=3,λ2=6,λ3=2
-
det 를 계산하는 과정에서 (2,3,10) 과 같은 것은 replacement 로 없어진다.
-
replacement 는 det 값이 변하지 않으므로 무시해도 된다.
-
upper triangle-matrix 의 det 는 diagonal product 와 같다.
3개의 eigenvalue 가 있고, 이것을 ∣A−λI∣x=0 에 대입하면
-
∣A−3I∣x=0 로 놓고 null space 를 찾아보면 λ1=3→x1=[2−251]⊤
-
∣A−6I∣x=0 로 놓고 null space 를 찾아보면 λ2=6→x2=[100]⊤
-
∣A−2I∣x=0 로 놓고 null space 를 찾아보면 λ3=2→x3=[230]⊤
-
물론 이것만 되는 것이 아니라 span 되는 vector 들 모두 eigenvector 가 된다.
eigenvalue, eigenvector 의미.
-
(중요한 성질) 행렬 A 가 있을 때,
만약 다른 eigenvalues 에 속하는 n 개 x1,⋯,xn 의 eigenvetors 이 있다면, 그들은 독립적이다.
어떤 행렬의 eigenvector 들이 다른 eigenvalue 에서 온 것이면, 그 eigenvector 들은 모두 lineary independent 하다.
-
eigenvalue, eigenvector 가 어떤 의미가 있나?
- 공간이 바뀌어도 방향을 유지하는 vector 가 eigenvector.
공간이 바뀌어도 (공간이 바뀐다는 말을 이해하려면 행렬이 가지는 의미를 이해해야 한다.)
-
linear map 은 linearity 를 유지하는 조건.
-
f 함수, f(ax+by)=af(x)+bf(y) 가 되는 성질을 만족하는 임의의 함수 f 가 linear.
-
f:x→y mapping 이 linear 라고 만족을 하면,
- 어떤 임의의 mapping 을 예로 들면 미분을 들 수 있다.
- f 라는 mapping 은 행렬 A 로 표현 될 수 있다는 것이 중요한 theorem.
-
행렬 A 의 중요한 의미는 어떤 공간에서 다른 공간으로 넘어가는 transformation 변환을 의미한다.
-
2차원에서 넘긴 공간이 3차원으로 될 수도 있고, 그 반대도 가능한데 차원 축소라고 한다.
-
mapping 을 T 라고 하고, 이것에 대응되는 matrix 가 AT 라고 말할 수 있는 것.
크기에 변화하는 value, 방향을 유지하는 vector
-
A,B 공간이 (편의상 두 차원이 같은 차원) 일 때, A 공간에서 B 공간으로 넘어갈 때,
- vector 의 방향이 달라질 수 있지만, 특정 vector 는 같은 방향으로 유지가 되고 크기만 변한다.
- 크기의 변화가 eigenvalue 이고, 그 방향이 eigenvector 이다.
-
matrix 의 어떤 mapping 이라고 생각하면, eigenvalue 들만 가지고 그 matrix 의 설명이 가능하다.
-
차원 축소를 생각해보자.
- eigenvector 들은 scale 에 상관 없다.
- eigenvalue 는 A 공간에서 B 공간으로 넘어갈 때, 해당 축이 B 공간에서 얼마나 의미 있는지 나타낸다.
-
A 공간의 차원에서 B 공간의 차원으로 넘어가는 mapping
- eigenvalue 가 큰 것에 해당하는 eigenvector 들은 B 공간에서의 의미가 커진다.
- eigenvalue 가 0 이면 B 공간으로 transfer 되면 없어진다.
- 이 크기에 방향을 유지하는 eigenvector 를 보면, 이 공간의 확장과 축소를 알 수 있다.
-
A∈Rn×n 일 때,
- A vector 의 eigenvalue >1 이면, vector 의 방향에 A 를 계속 곱하게 되므로 Anx 는 divergence 한다.
- A vector 의 eigenvalue <1 이면, Anx 는 계속 공간을 줄여서 0 에 convergence 한다.
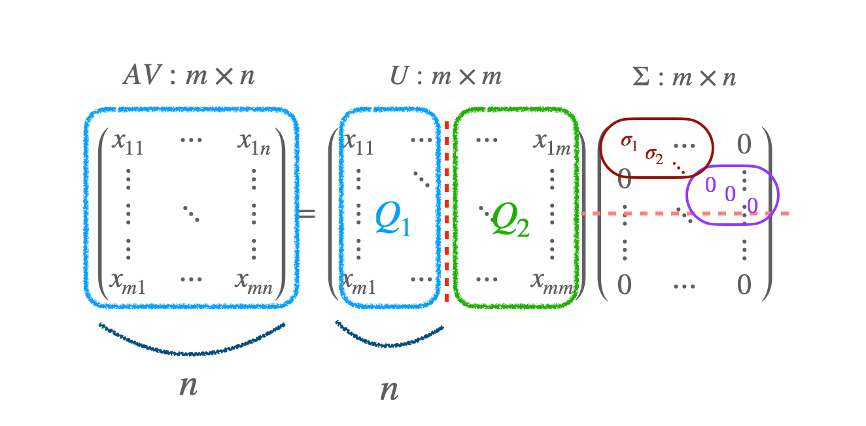
(S)ingular (V)alue (D)ecomposition
SVD 를 이해하는 논리적 흐름은 QR Decompostion 에서 시작.
QR Decomposition
Let A be an m×n matrix of rank n. Then the QR decomposition A=QR.
- rank n 의 m×n matrix 이 있다고 하자. 일반적으로 A 는 square or tall matrix 이고, fan matrix 는 복잡해진다.
- 예를 들어 10×3 행렬이 있다고 하면,
- column vector 가 3개 있고, rank 가 3 이면, 모든 column vector 는 linearly independent 하다.
Where Q∈Rm×n with orthonomal columns, R is upper-triangluer matrix, n×n, invertable.
이것이 QR decomposition.
-
tall matrix 의 full rank 가 아니면 A⊤A 자체가 invertable 하지 않기 때문에 linearly system 의 solution 이 존재하지 않는다고 해도, 쓸 수는 있지만 solution 을 찾기는 쉽지 않았다.
-
QR decomposition 에서는 rank 가 n 이라는 조건이 실제로 굉장한 제약 조건이 된다. 따라서 rank 가 n 보다 작으면 (rank difficient) 어떻게 풀 것인가?
QR Decomposition problem
-
Recall that A∈Rm×n⟶A=QR,
- where Q : orthogonal vector, R : upper-triangular matrix
-
tall or square matrix 에서 requires rank(A)=n 에서 모든 column vector 들이 independent 를 희망.
-
m 개의 기회를 갖는데, A 라는 행렬을 만들기 위해서 Q,R 이 필요했던 것.
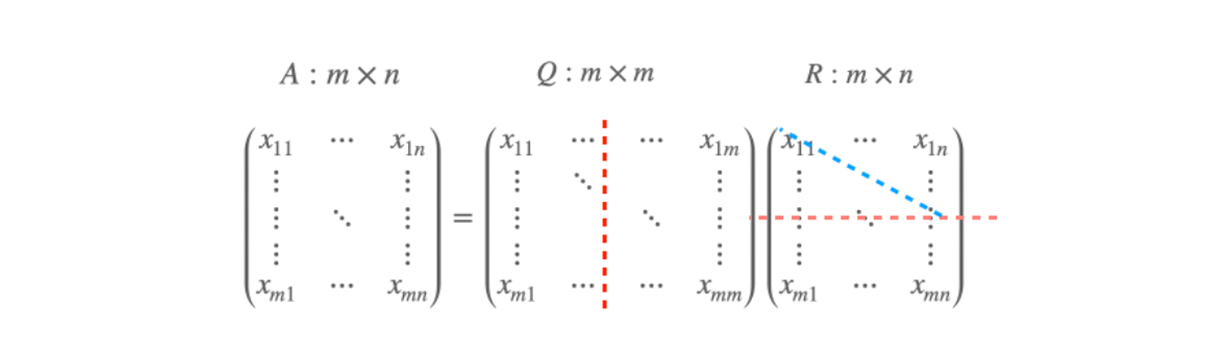
-
녹색 영역에 해당하는 것은 R 에 대한 basis 가 된다 ?
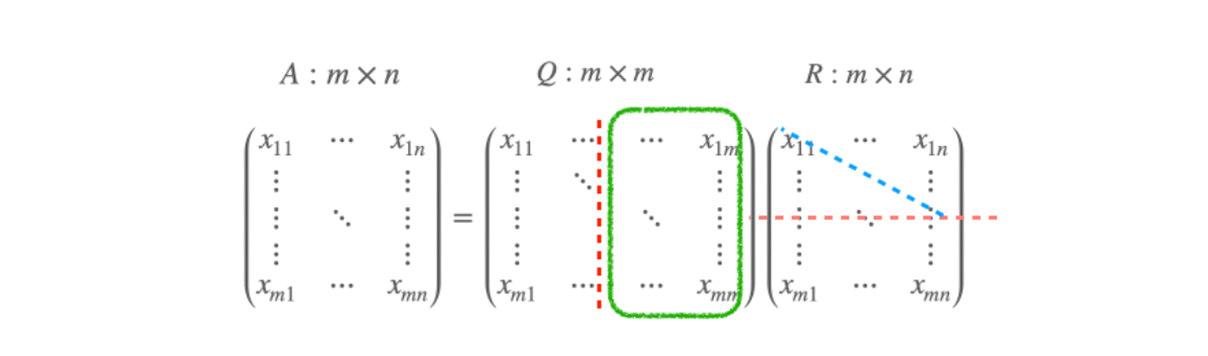
-
파란 영역 만큼 redundancy 가 있다고 하면, A 에 대한 basis 가 된다.
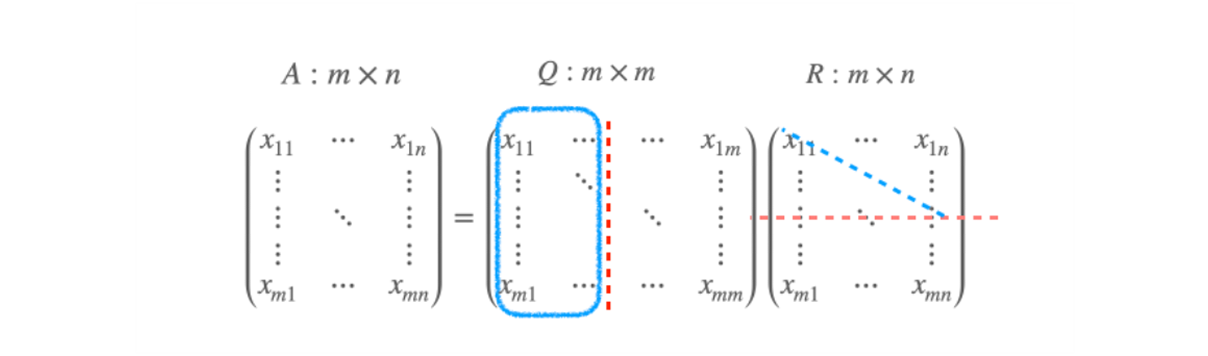
-
A 의 m=100 이라고 치면, 100 차원 전체를 span 할 수 있는 공간 속에 있지만, n=50 이라고 한다면 50 개 짜리 basis 밖에 못 가지고 있는 50 차원 subspace 가 된다.
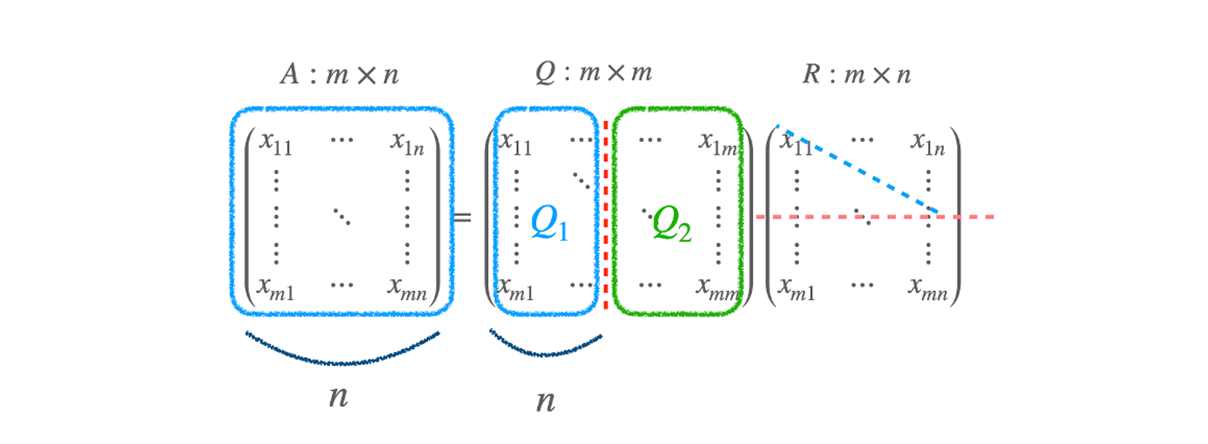
- Q 에서 Q1 은 원래 A 에 대응되는 basis vector 들, orthonomal 한 n 개의 vector 들이 있다.
- R 에 있는 파란 diagonal term 의 값 들은 모두 Q1 에 대응되는 값들 이다.
- 나머지 Q2 는 A column vector 들이 span 하지 못하는 공간들에 대응되는 어떤 vector 로 볼 수 있다.
-
A vector 가 cover 하는 공간 Q1 과 cover 하지 못하는 공간 Q2 로 볼 수 있다.
-
A vector 가 rank(A)=n 일 때, 어떤 일이 발생할지 생각해보면,
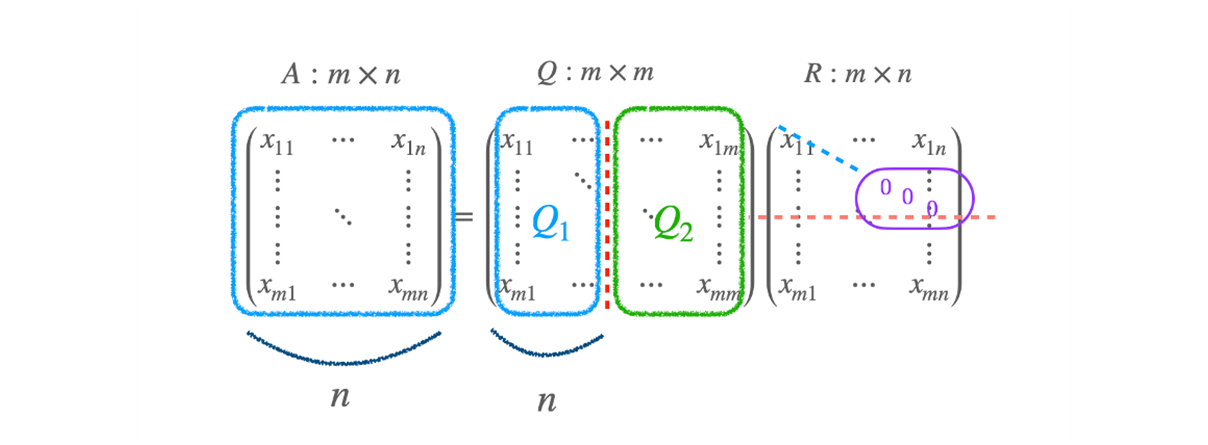
- R 의 diagonal term 의 뒷 부분이 0 으로 채워진다. 따라서 뒷 쪽의 singular value 가 0 이 된다.
- 그렇게 되면, Q 의 basis vector 를 못쓰게 되는데 어떻게 해야하나?
SVD
이와 같이 A 의 colummn vector 들이 모두 independent 가 아니라면?
A=UΣV⊤
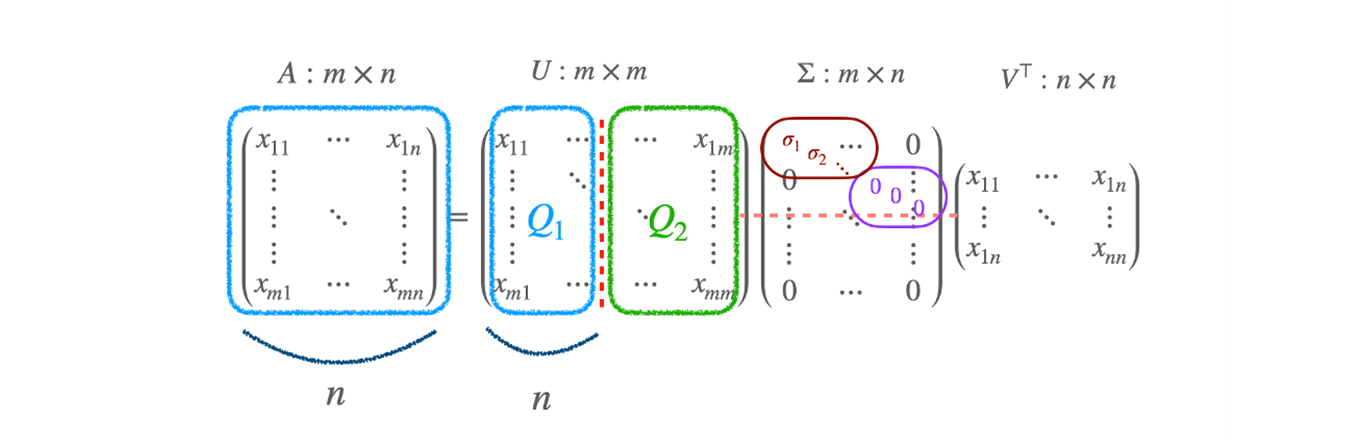
- singular values : σ1,σ2,⋯ 가 들어간다.
- Σ:m×n 행렬이고, rank(A)=3 이면, 3 까지만 non-zero 값이 들어있다.
- 4, 5, 6 element 는 0 이 들어가게 된다. 이렇게 U,Σ,V 가 된다.
- U,V 는 column vector 가 모두 orthonomal vector 인 matrices 이다.
- Σ 는 square matrix 는 아니지만, diagonal term 만 있는 matrix 이다.
- orthonomal vector 는 vector 의 inverse 가 vector 의 transpose 와 같다.
A=UΣV⊤=UΣV−1→AV=UΣ
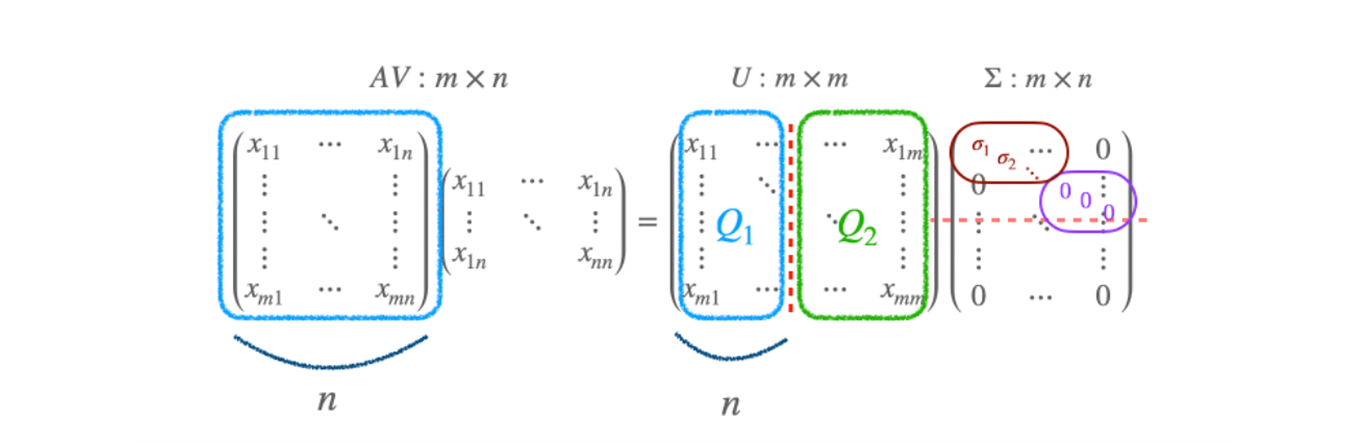
-
Σ matrix (Singular matrix) 는 A 에 대해서 unique 하다. 그러나 U,V 는 unique 하지 않다.
-
eigenvalue 는 unique 하지만, eigenvector 는 unique 하지 않는 것 처럼..
-
QR Decomposition 을 이야기 할 때는,
- A 의 rank 가 column 에 대해서 full rank 가 아니면 문제가 있었다.
- 한 쪽이 orthonomal vector 이므로, full rank 가 아니면 A=QR 로 표현할 수 없었기 때문.
-
SVD 의 수식만 놓고 보면, AV=UΣ 는 QR decomposition 과 비슷하다.
Result
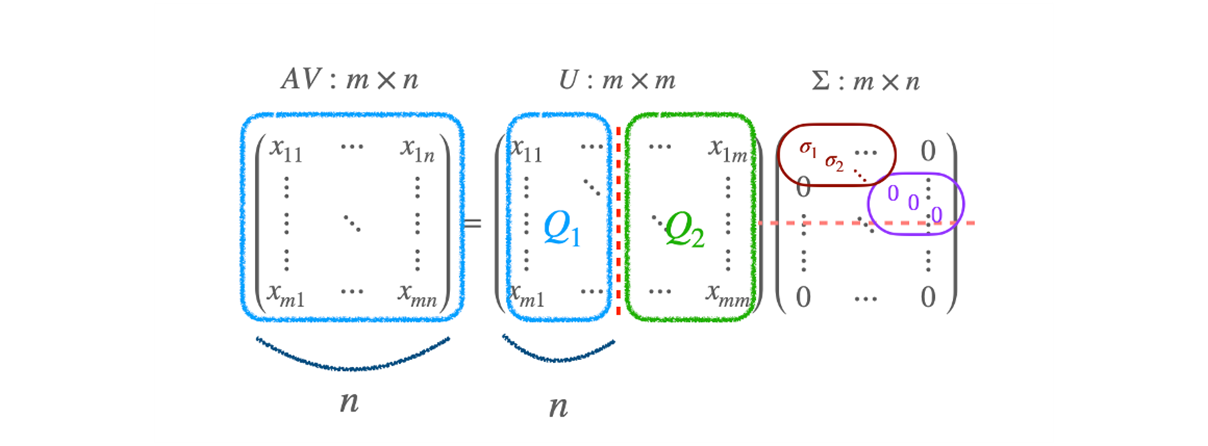
- QRD vs SVD
- A 와 똑같이 생긴 행렬이 있고,
- Q 행렬인 Orthonomal vector 와 R 행렬인 upper-triangular matrix 로 바꿀수 있다.
- 그런데 R 자리에 0 이 들어가는 것을 허용할 수 없었다.
- SVD 로 A 를 그냥 쓰는 것이 아니라 V 라는 orthonomal matrix 를 곱하면서 가능해졌다.
- U or V⊤
- orthonomal vector 로 되어 있는 square matrix
- 공간을 회전 행렬로 공간 회전 시킨다고 볼 수 있다.
- 회전 행렬이라고 불리는 공간을 SO(n) (Special Orthogonal Group).
- 공간의 양을 그대로 넣은 상태에서 회전을 시키는 것.
A=QR 에서 R 을 쓸 때, diagonal 에서 앞에 singular value 가 차고, 뒷 쪽에 0 이 떨어지게 만들 수 있어야 하는데, 임의의 A matrix 의 정보량이 모든 column 숫자 만큼의 차원을 커버할 수 없다 하더라도 약간 돌아가 있다.
- AV=UΣ 의 의미.
- 2 차원 공간이 있는데, line 은 rank 가 1 이므로, 한 값을 표현할 수 있고, (x,y) 2개로 표현이 가능.
- 이 공간을 적절히 회전 시켜서 1차원으로 만들게 되면 숫자 한 개만으로 표현할 수 있다.
- 이런 회전 역할을 AV=UΣ 에서 V 가 해주게 된다.
- 그래서 뒤에 있는 Σ 의 diagonal term 의 뒷 부분에 0 이 들어갈 수 있도록 한다.
- A 가 full rank 가 아니면,
- V 라는 orthogonal vector matrix 를 곱하므로써,
- Σ 라는 diagonal 뒷쪽 에 0 이 들어갈수 있게 회전을 곱해줄 수 있는 성질이 추가.
(SVD) Relation to..
SVD : A=UΣV⊤.
여기서는 계산을 편하게 하기 위해서 A,U,V 는 Square matrix 라고 하자.
- SVD 의 성질을 이용하기 위해서 A⊤A 를 계산해보자.
- U,V 는 orthonomal vector 이기 때문에 UU⊤=I
- A⊤A=VΣU⊤UΣV⊤=V(Σ⊤Σ)V⊤
EVD ( Eigenvalue Decomposition )
Ax=λx
-
X 는 scale 에 따라 상관 없기 때문에 이것은 orthonomal vector 로 볼 수 있어서 XΛX⊤ 로 쓸 수 있다.
-
SVD : A⊤A=V(Σ⊤Σ)V⊤ 수식과 EVD : A=XΛX⊤ 을 비교해보자.
-
X 는 eigen vector 이고, Λ eigen value 들이 diagonal term 에 들어가 있는 matrix 이다.
-
Σ 는 singular value 가 들어가 있는 diagonal matrix 이므로 Σ=Σ⊤ 이다.
Σ⊤Σ=Σ2=⎣⎢⎢⎢⎡σ12σ22⋱σn2⎦⎥⎥⎥⎤ singular value σn2 의 square 가 된다.
- Σ⊤Σ 는 A⊤A 에 대한 eigenvalue 로 볼 수 있다.
- singular value 의 제곱 (σn2) 은 A⊤A 행렬의 eigenvalue 로 볼 수 있다.
- A 의 eigenvalue 가 양수라면, singular 가 같아진다.
- A 의 eigenvalue 가 음수 여도 square root 를 취하므로 똑같은 양수 값이 나온다.
- [Σ]ii : square root of i th eigenvalue of A⊤A
- 따라서 singular value (특이값) 는 A⊤A 의 eigenvalue 의 square root 이므로 양수여야 한다.
PCA ( Principal Component Analysis )
PCA 는 SVD 와 같다.
SVD→A=Um×mΣm×nVn⊤
=⎣⎢⎢⎢⎢⎢⎢⎡⋮u1⋮⋮⋮u2⋮⋮⋯⋮um⋮⋮⎦⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎡σ10⋮00σ20⋮⋯⋯⋯0⋮σn0⎦⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎡⋯⋯⋮v1v2⋮⋯⋯⋮⎦⎥⎥⎤=i=1∑nσiui⋅vi⊤
-
ui⋅vi⊤ 은 m×n matrix 이지만, rank 는 1 이 된다.
-
vector 2 개만 곱해서 만들었기 때문에, m×n matrix 이지만 rank 는 1 이다.
- ∑i=1nσiui⋅vi⊤ 는 rank 1 짜리 n 개가 모여 있는 vector 로 볼 수 있다.
-
A matrix 를 n 개의 vector 로 보고, m 차원 공간 속에서 살고있는 n 개의 data 라고 본다면
A=⎣⎢⎢⎢⎡⋮a1⋮⋮a2⋮⋯⋮an⋮⎦⎥⎥⎥⎤
-
n 개의 vector {a1⋯,an} 의 Um×m vector 들 중의 r 개를 Principle Component 라고 부른다.
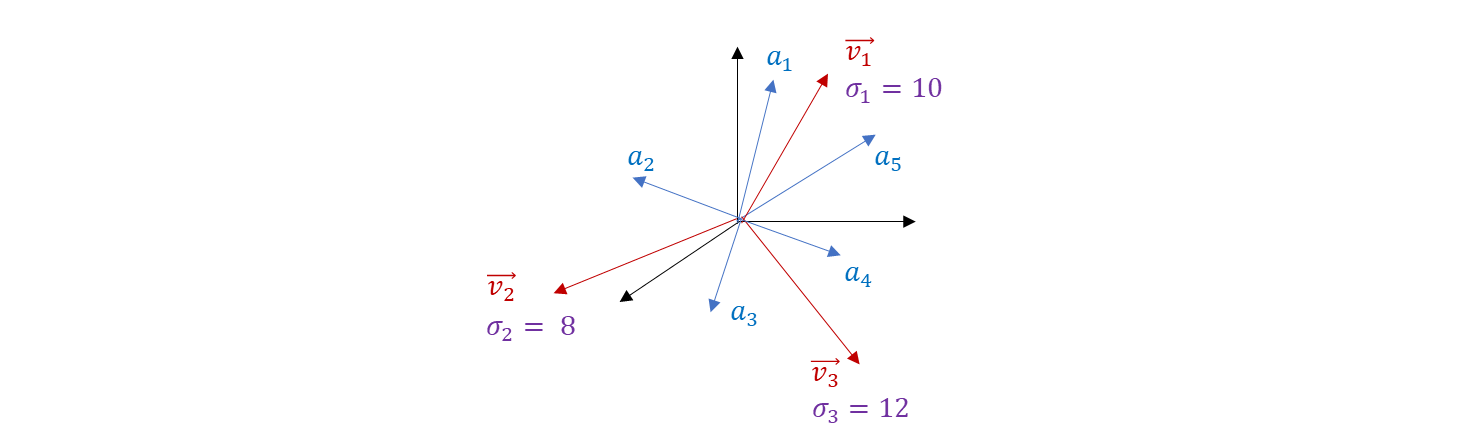
- 이 3차원 공간 속에는 여러 vector 들이 있다.(n 차원 공간이 가능)
- 이 데이터들을 잘 설명할 수 있는 vector 는 3개라고 하자. v1,v2,v3 는 orthonomal 하다.
- a1,a2,⋯,a5 의 모든 데이터들을 Principle Component 로 Projection 을 시킨다.
- 데이터는 n 차원 공간, r 개의 Principle Component 로 projection 을 시키면 vector 를 표현하는 어떤 값이 된다.
- σ1,σ2,σ3 은 그 축의 중요도가 들어가 있어서 이 값을 기준으로 sorting 한다.
- σ 가 큰 몇 개의 vector 에 대응되는 Principle Component 로 주어진 데이터의 설명력을 갖게 된다.
- 100 차원의 공간에서 Principle Component 를 3개를 잡으면 100 차원에서 3차원으로 reduction 한 것.
- PCA 를 하는 과정에 SVD 가 사용됬고, n 차원 공간을 잘 설명하는 축들은 PCA 이고, SVD 의 U 와 같다.
Other topics
- Neural Net 의 ResNet (Residual Network 을 사용하는 구조)