
Issue
AdamW 가 자꾸 터져서, 관련 내용을 추가해서학습해 보기로 한다.
- AdamW 문제로 Adam 을 사용하여 학습 시킨다.
- AdamW 문제로 learning rate 을 많이 줄여서 천천히 학습시켜본다. 0.02 → 0.001
optimizer: AdamW, lr0 = 0.02 , dfl = true
Apply Adam optimizer
Adam 으로 바꾼 이유는, gradient 를 regularization term 으로 꺾어보려 했다.
일단 Adam 은 빼자. 이유는 아래와 같다.
adam
# L2 가 포함된 gradient 사용.
> g_t = ∇L_original(θ_t) + λ * θ_t
adamw
> g_t = ∇L_original(θ_t)
# 이후 m_t, v_t 는 original gradient 를 사용.
> weight = weight - lr * (m_t/sqrt(v_t) + lambda * weight)
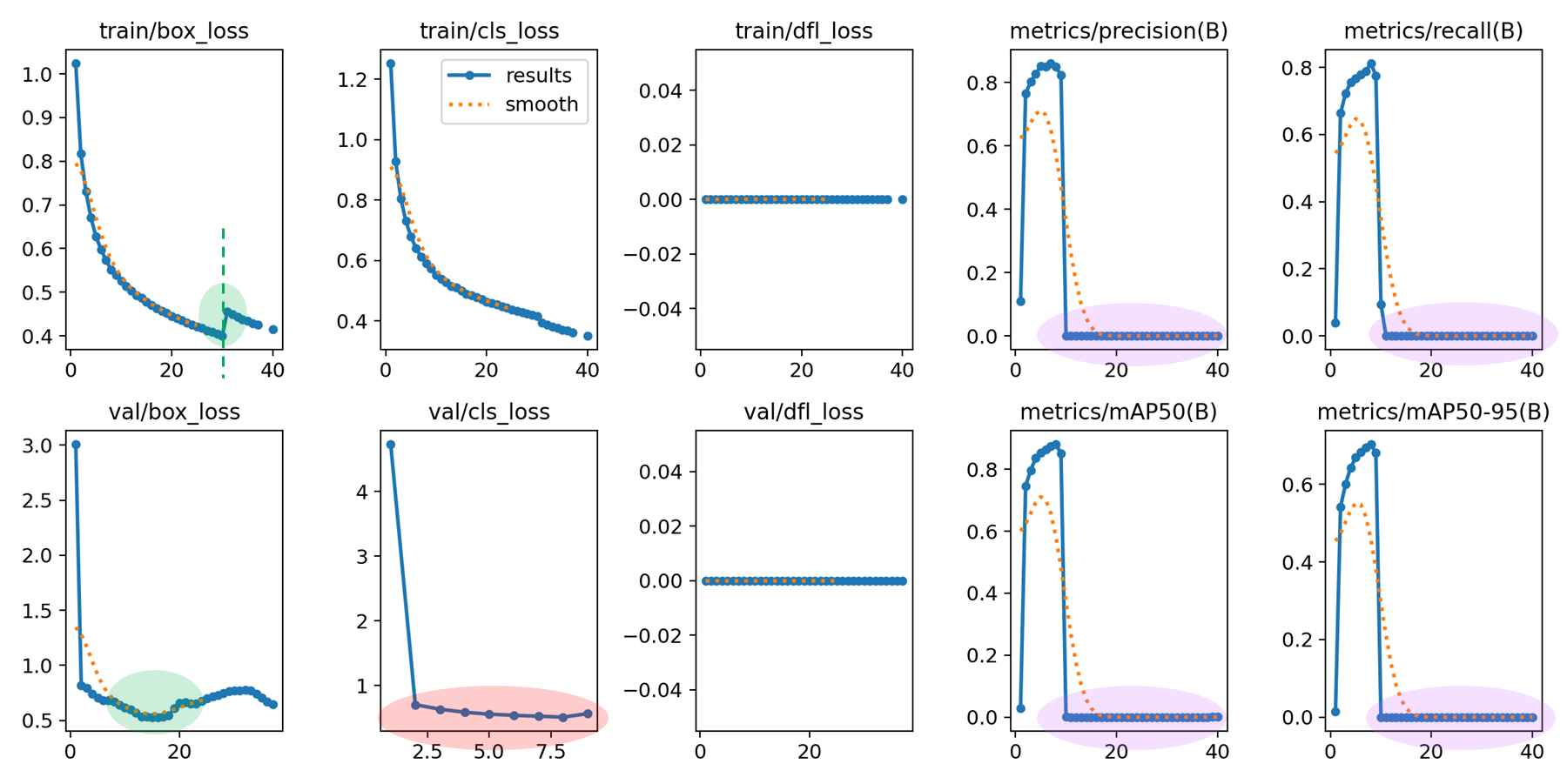
# 이후 m_t 와 v_t 를 사용하여 구하되, gradient 는 유지하고 `lambda + weight` 을 별도 적용.optimizer: Adam , lr0 = 0.02 , dfl = true
valid loss 가 divergence 했다. Adam 계열로 converge 하게 만들자.
- 훈련이 끝났으므로 confusion matrix 도 보자.
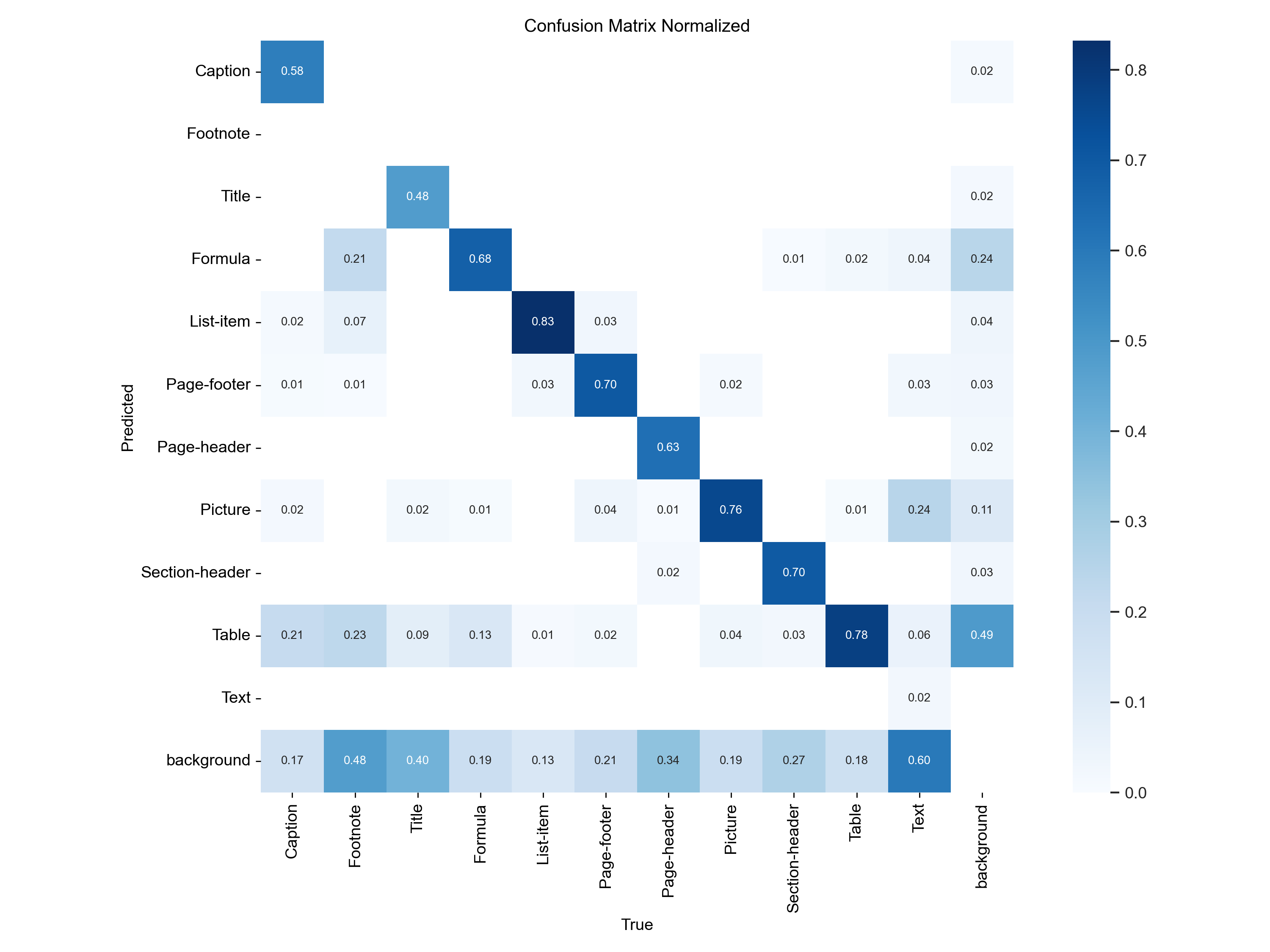

확실히 저조한 성적이다. divergence 했으므로, converge 하려면 lr 을 낮추는 방법도 있지만 일단 AdamW 의 lr 을 낮춰보기로 한다.
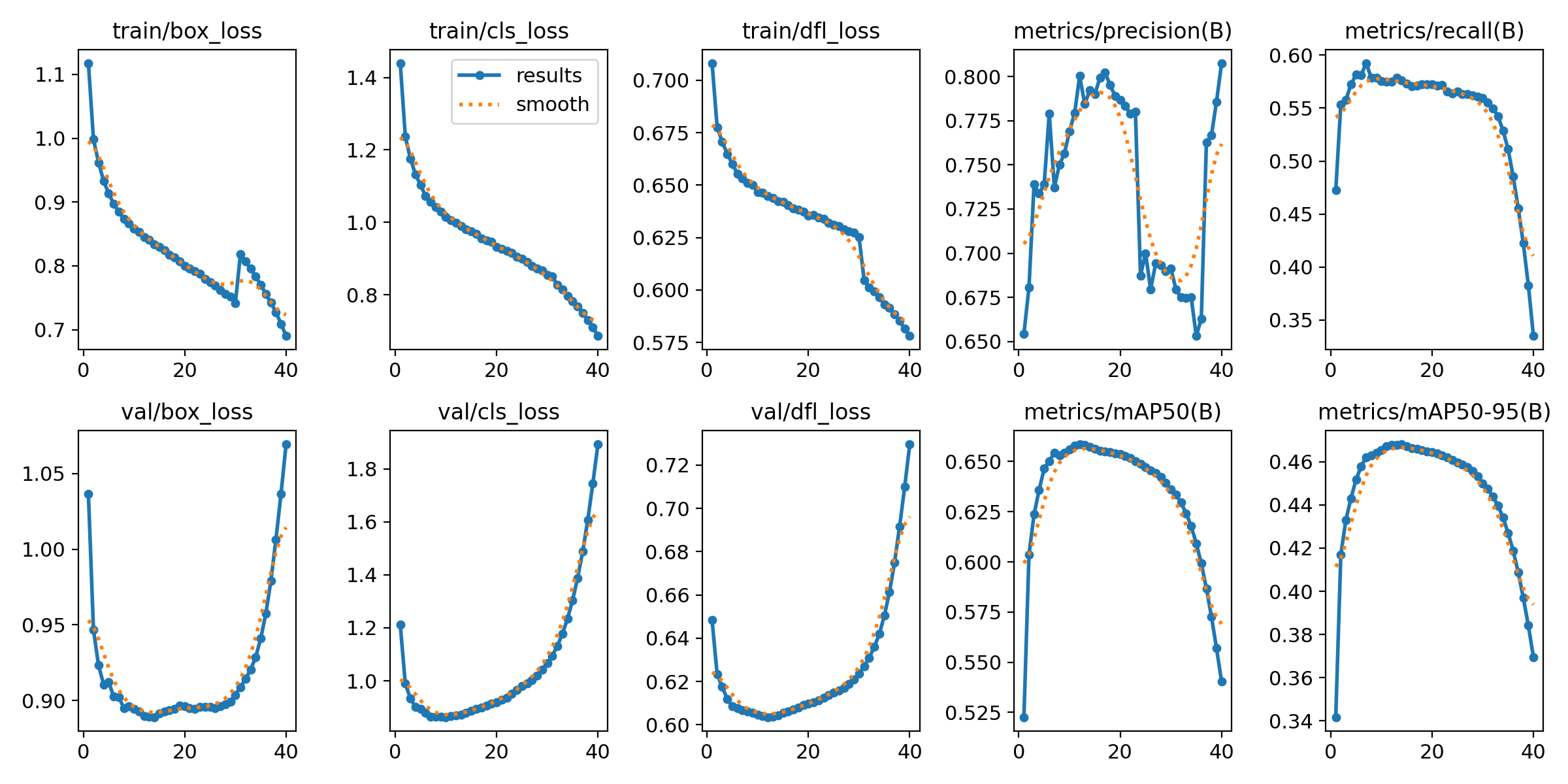
optimizer: SGD, lr0 = 0.02 , dfl = true
SGD 의 validation box_loss 를 잡아보고, 나머지 잘 나오는 것도 가져가는 것이 목표.
Apply AdamW optimizer with lr0 = 0.001
- 확실히 AdamW 의 validation loss 가 SGD 보다 낫다.
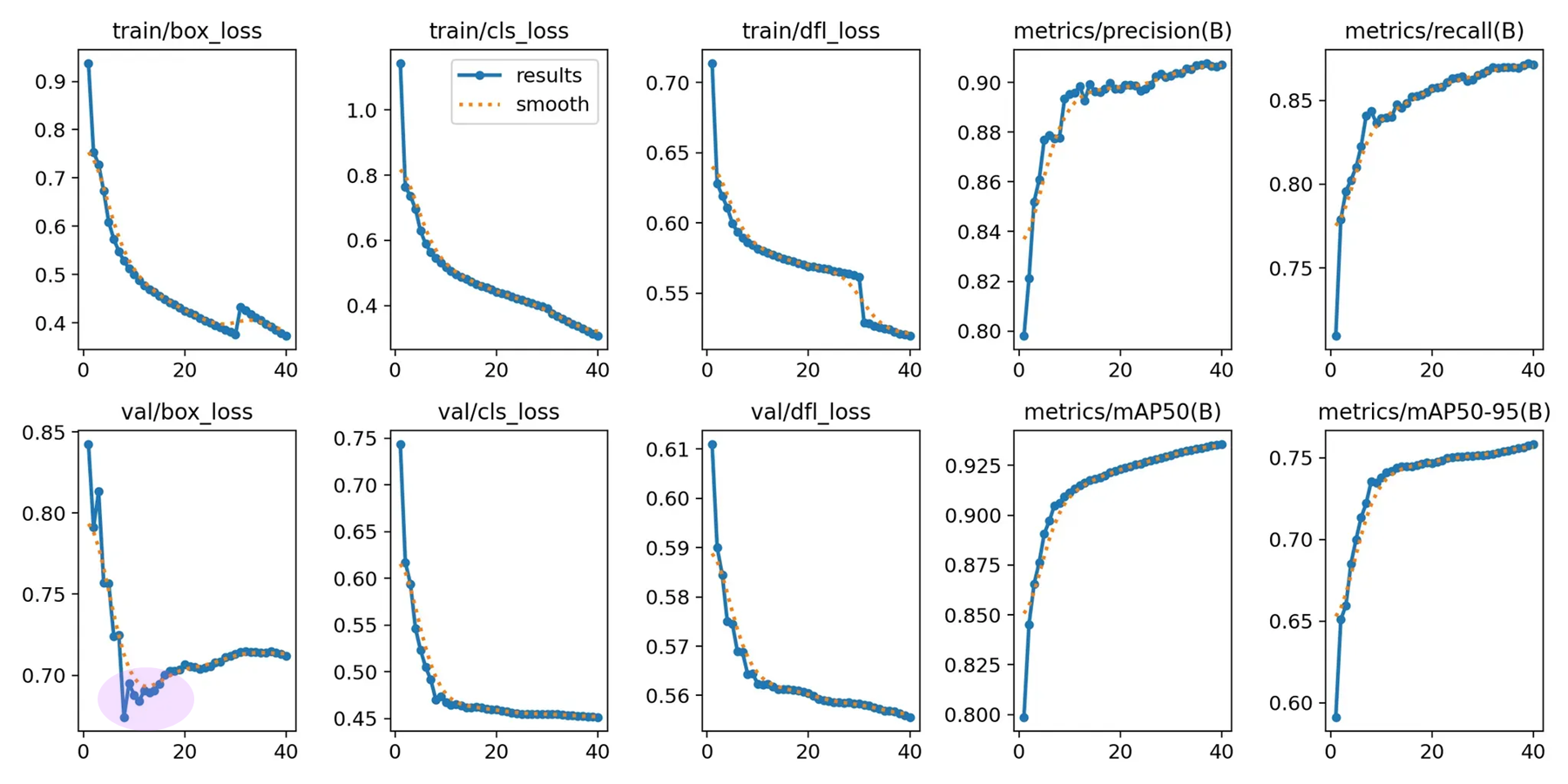
optimizer: AdamW, lr0 = 0.001, dfl = true
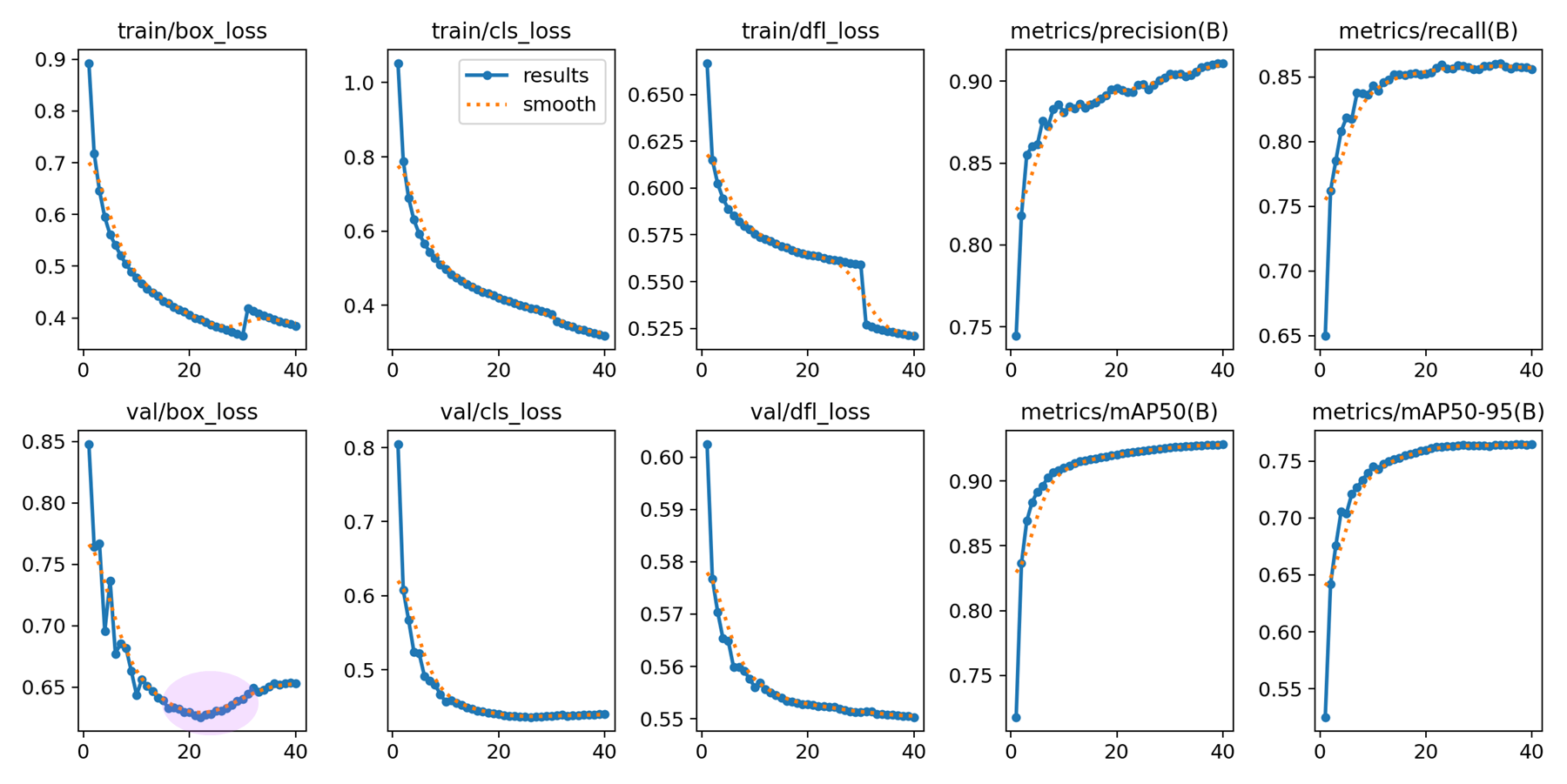

page-footer 이 0.8 에서 0.88 이 나온건 경이롭다. 8% 가 올랐으므로, 전체적으로 balanced 하다.
결론적으로 AdamW 의 dfl_loss 가 들어간 lr 0.001 모델을 사용 할 예정이다.
Apply AdamW optimizer with lr0 = 0.003
3배수 올려서 learning rate 0.003 으로 훈련해보았다. 만약 터질 모양이면, 그래프가 망가질 것이다.
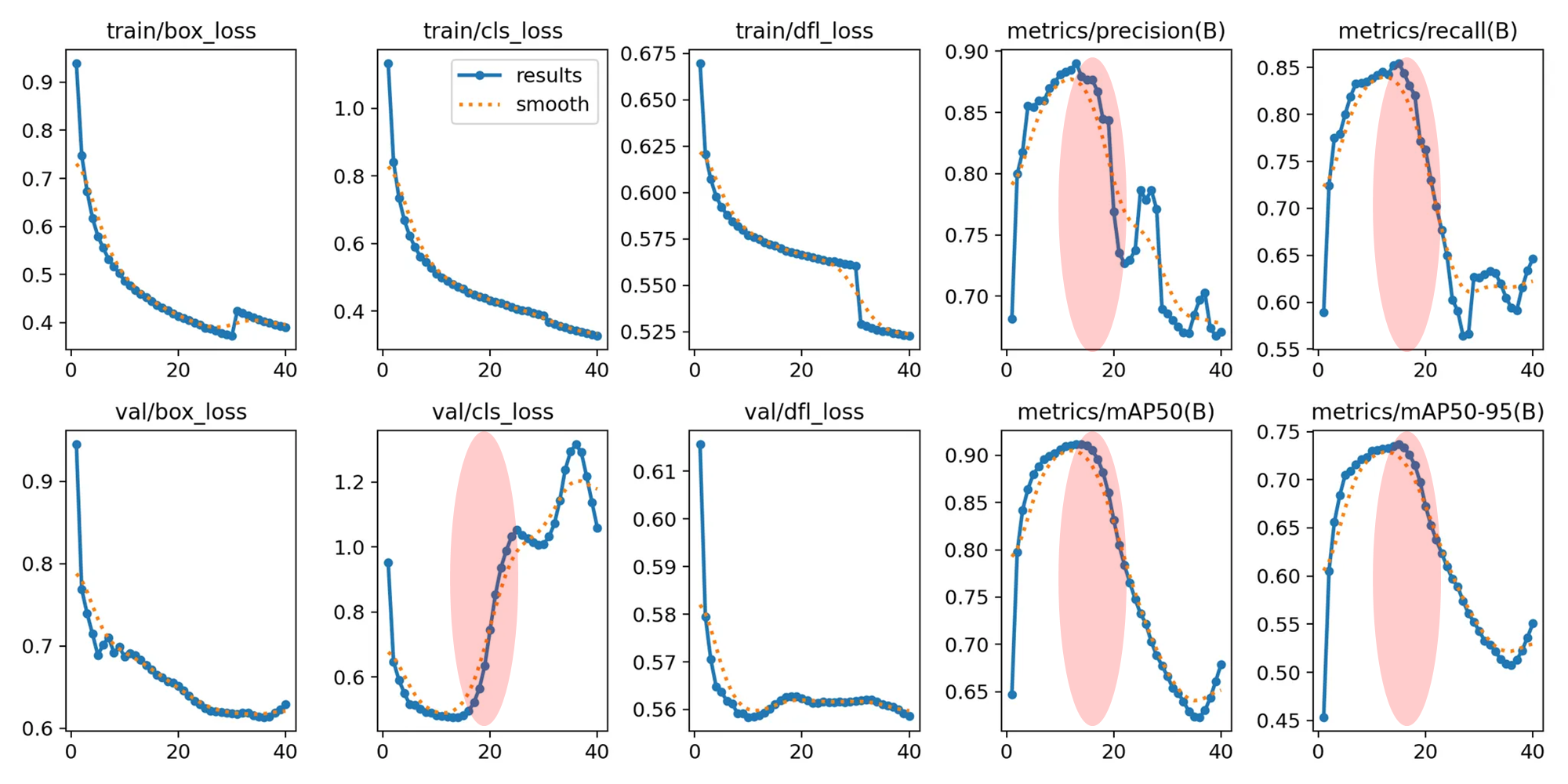
예상대로 valid loss 부터 망가지고 matrics 의 mAP 가 흔들리기 시작했다.

Conclusion
결론적으로, 사용할 모델은
optimizer: AdamW, lr0 = 0.001, dfl = true
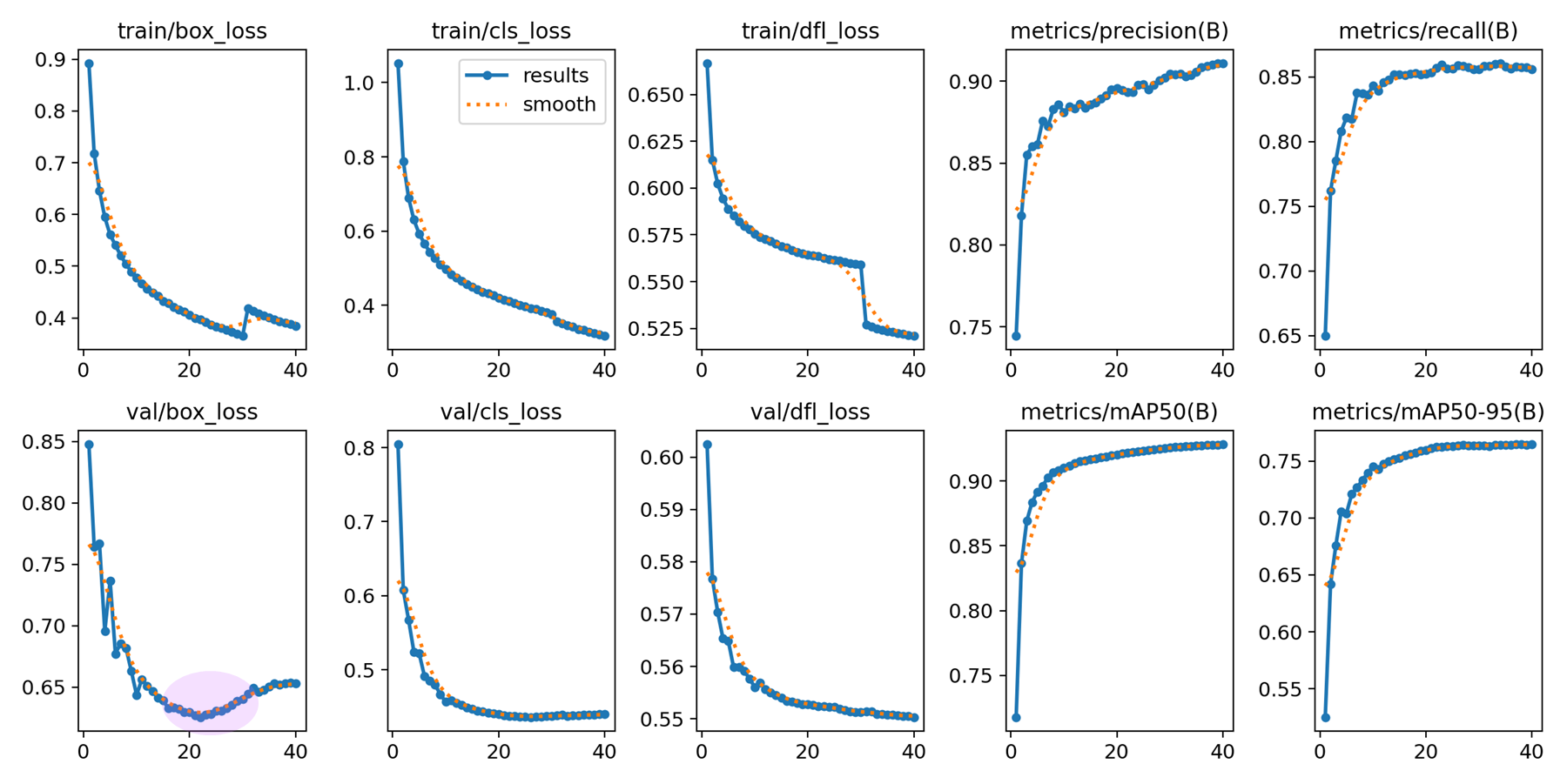
모델로 정하고 시작하겠다.
