오리엔테이션(OT)
CH01 - 이상 탐지 개요
- 차원 축소 기술
- EDA
- 데이터 시각화
CH02 - ML 기반 이상 탐지
- 본격적인 이상 탐지 학습
- D/L이 아닌 조금 더 전통적인 방식의 머신러닝 기술에 대해 학습
- 통계 기반
- 분류 기반
- 군집 기반
- D/L is not all you need!
CH03 - DL 기반 이상 탐지
- 딥러닝을 사용하는 이상 탐지 기술에 대해 알아보는 시간
- 모든 경우에 딥러닝이 적잘하지는 않지만, 여전히 가장 강력한 AI 기술
- 비 선형적인 데이터에 적용하기 적절
CH04 - 이상 탐지 Case study
- 공개된 데이터 셋으로 이상탐지에 대해 구체적으로 알아보는 시간
- 2개의 kaggle case study
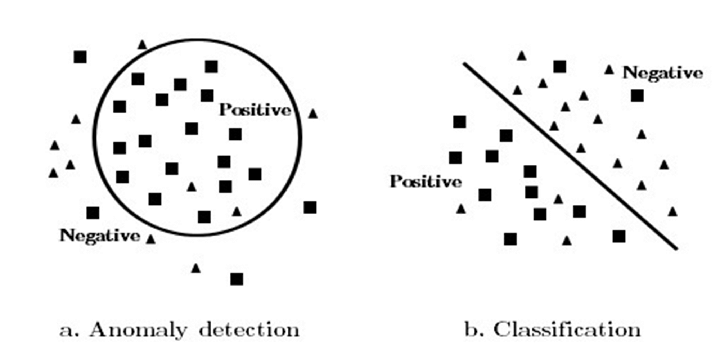
이상탐지 개요
- 이상 탐지?
- 데이터의 대다수와 현저히 다르며 정상 범위에서 벗어나서 드물게 발생하는 항목, 사건, 관측치를 찾아내는 과정
- 이상 탐지 use-case
- 이상탐지 기술이 활용되는 예시
- Image 이상 탐지
- 촬영된 이미지
- 의료 도메인, 산업용 공정 등에서 활용 - Text 이상 탐지
- 문자로 표현되는 데이터의 의미를 파악하는 이상 탐지
- Tabular data 이상 탐지
- 테이블(표) 형태로 표현 가능한 데이터의 이상 탐지
- 수치적, 통계적 특성을 주로 활용
- Time-series data 이상 탐지
- 일정한 시간 정보를 포함한 데이터의 이상 탐지
- 사이버 공격 방어, 실시간 금융 거래 모니터링
- 이번 강의에서는!
- Tabular + Time-series + a
- 전통적인 방식의 머신 러닝 알고리즘에 대해 학습
데이터 특성의 이해
-
데이터 종류
[데이터 정보]
정량적 vs 정성적 정보
=> 정량적 : 수치, 도형, 기호 등 바로 측정할 수 있는 정보
=> 정성적 : 언어나 문자 등 '설명'이 필요한 정보
[데이터 유형]
정형 데이터(Structured data)
=> 행과 열로 구성되어 있는 테이블 형태의 데이터
시계열 데이터(Time Series Data)
=> 시간 정보가 존재하는 tabular data
비정형 데이터(Unstructured data)
=> 정해진 구조가 없이 저장된 데이터
반정형 데이터(Semi-Structured data)
=> 데이터 내용 안에 구조에 대한 설명이 함께 존재함
=> tabular data와 다르게 고정된 스키마가 없음
=> XML, HTML, Json 등 -
EDA(Exploratory Data Analysis)
-
EDA란?
=> 시각화, 통계적 기법 적용 등을 통해 데이터를 탐색하는 과정 -
EDA의 핵심 요소
=> 데이터의 각 column의 의미를 파악하고 상관 관계를 파악
=> 결측치 처리 및 데이터 필터링
=> 직관적이고 쉽게 이해할 수 있는 데이터 시각화 -
Dataset 이해
-
결측치 파악
-
데이터 시각화
- hourly / daily / weekly
- Value Distribution (Day & Hour)
- Hour & Day: Demand by Hour
차원 축소
- 고차원 데이터와 차원 축소
-
고차원 데이터
=> 고차원 데이터 : 많은 수의 변수나 특성을 가진 데이터
=> 차원의 저주(The Curse of Dimensionality) : 데이터의 차원이 증가함에 따라 필요한 데이터 샘플의 양이 기하급수 적으로 증가하여 모델 학습과 일반화에 어려움을 초래하는 현상
=> 시각화 문제 : 차원이 높은(복잡한) 데이터는 직관적으로 이해하기 힘듦 -
차원 축소
=> 데이터의 특성(Feature)을 줄여서 데이터를 간결하게 만드는 기술
- 차원 축소 방법
-
차원 축소 유형
=> Feature Selection : 분석 목적에 부합하는 소수의 특징만을 선택
=> Feature Extraction : 기존 특징의 변환을 통해 새로운 특징 추출 -
PCA(Principal Component Analysis; 주 성분 분석)
=> 여러 변수간 존재하는 상관관계를 이용해 이를 대표하는 주성분을 추출해 차원을 축소하는 방법 -
t-SNE(t-distributed Stochastic Neighbor Embedding)
=> 고차원 데이터를 저차원에 t-확률 분포로 표현하는 비선형 차원축소 방법 -
PCA vs t-SNE
=> 데이터가 비 선형적인 관계를 가진다면 t-SNE 활용
=> 데이터가 선형적인 관계를 가진다고 PCA가 더 좋은 것은 아님
