팀명 : GBE-SK앞서 작성한 Anomaly Detection과 겹치는 내용이 많기에 상당 부분 생략될 수 있음을 미리 말씀 드리고자 한다.
1. 프로젝트 개요
A. 개요
LLM의 등장 이후 여러 산업 분야에서 지식을 다루는 업무들이 점점 고도화되고 있다.
특히 정보를 찾기 위해 검색엔진의 입력창에 키워드를 입력하고 결과를 확인하고 원하는 정보가 없으면 다른 키워드로 다시 검색하기를 반복하는 번거로운 과정을 이제 더이상 자주 할 필요가 없어졌다.
이제 LLM한테 물어보면 질문의 의도까지 파악해서 필요한 내용만 잘 정리해서 알려 준다.

그렇지만 LLM이 가진 근본적인 한계도 있다.
먼저, 정보라는 것은 의미나 가치가 시간에 따라 계속 변하기 때문에 모델이 이를 실시간으로 학습하기 힘들고 이 때문에 아래 예시처럼 knowledge cutoff 가 자연스럽게 발생한다.

그리고 LLM이 알려주는 지식이 항상 사실에 기반한 것이 아닌 경우가 종종 있다. 특히 특정 도메인이나 문제 영역은 매우 심각한 거짓 정보들을 생성해 내곤 한다. 아래 예시에서 추천하는 맛집들은 모두 실재하지 않는 장소들이다.

이러한 환각 현상은 메타인지를 학습하지 않은 LLM의 근본적인 한계라 볼 수 있다.
모델은 학습 과정에서 정보를 압축해서 저장하기 때문에 정보의 손실이 발생할 수밖에 없고, 이 때문에 특정 입력 조건에 대해서는 사실 여부보다는 지식를 표현하는 국소적인 패턴이 더 큰 영향을 주면서 답변이 생성될 수 있기 때문이다.
이러한 문제를 극복하기 위해서는 RAG(Retrieval Augmented Generation) 기술이 필수이다.
RAG는 질문에 적합한 레퍼런스 추출을 위해 검색엔진을 활용하고 답변 생성을 위해 LLM(Large Language Model)을 활용한다.
이때 LLM은 스스로 알고 있는 지식을 출력하기보다는 언어 추론 능력을 극대화하는 것에 방점을 둔다.
이렇게 사실에 기반한 지식 정보를 토대로 질문에 답을 하고 출처 정보도 같이 줄 수 있기 때문에 사용자는 훨씬 더 안심하고 정보를 소비할 수 있게 된다.
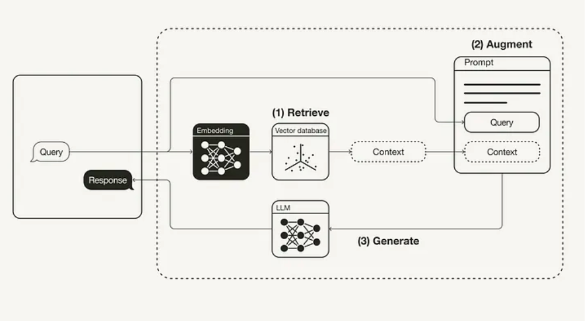
이번 대회에서는 과학 상식을 질문하는 시나리오를 가정하고 과학 상식 문서 4200여개를 미리 검색엔진에 색인해 둔다.
대화 메시지 또는 질문이 들어오면 과학 상식에 대한 질문 의도인지 그렇지 않은 지 판단 후에 과학 상식 질문이라면 검색엔진으로부터 적합한 문서들을 추출하고 이를 기반으로 답변을 생성한다.
만일 과학 상식 이외의 질문이라면 검색엔진을 활용할 필요 없이 적절한 답을 바로 생성한다.
마지막으로, 본 프로젝트는 모델링에 중점을 둔 대회가 아니라 RAG(Retrieval Augmented Generation) 시스템의 개발에 집중하고 있다. 이 대회는 여러 모델과 다양한 기법, 그리고 앙상블을 활용하여 모델의 성능을 향상시키는 일반적인 모델링 대회와는 다르다. 대신에 검색 엔진이 올바른 문서를 색인했는지, 그리고 생성된 답변이 적절한지 직접 확인하는 것이 중요한 대회이다.
따라서, 참가자들은 작은 규모의 토이 데이터셋(10개 미만)을 사용하여 초기 실험을 진행한 후에 전체 데이터셋에 대한 평가를 진행하는 것을 권장한다. 실제로 RAG 시스템을 구축할 때에도 이러한 방식이 일반적으로 적용되며, 이를 통해 실험을 더욱 효율적으로 진행할 수 있다. 따라서 이번 대회는 2주간 진행되며, 하루에 제출할 수 있는 횟수가 5회로 제한된다.
자, 이제 여러분만의 RAG 시스템을 구축하러 가보실까~?
출처: Upstage(AI Stages)
제공된 데이터셋
과학 상식 정보를 담고 있는 순수 색인 대상 문서 4200여개(학습 데이터 별도 제공 X)
파일 포맷은 각 line이 json 데이터인 jsonl 파일이다.

학습 데이터 설명
이번 대회는 머신러닝 모델을 학습하는 것 보다는 임베딩 생성 모델, 검색엔진, LLM 등을 활용하여 레퍼런스를 잘 추출하고 이를 토대로 얼마나 답변을 잘 생성하는지 판단하는 대회이다.
따라서 모델 학습을 위한 학습데이터를 별도로 제공하지 않고, 과학 상식 정보를 담고 있는 순수 색인 대상 문서 4200여개가 제공된다.
문서의 예시는 아래와 같다. 'doc_id'에는 uuid로 문서별 id가 부여되어 있고 'src'는 출처를 나타내는 필드이다. 그리고 실제 RAG에서 레퍼런스로 참고할 지식 정보는 'content' 필드에 저장되어 있다.
참고로 데이터를 Open Ko LLM Leaderboard에 들어가는 Ko-H4 데이터 중 MMLU, ARC 데이터를 기반으로 생성했기 때문에 출처도 두가지 카테고리를 가진다.
B. 환경
-
팀 구성 및 컴퓨팅 환경
7인 1팀, 인당 RTX 3090ti 서버를 VSCode와 SSH로 연결하여 사용 -
협업 환경
Notion, GitHub -
의사 소통
KakaoTalk, Zoom, Slack, Discord
2. 프로젝트 팀 구성 및 역할
-
팀 구성
IR 대회도 AD 대회와 마찬가지로 7명이서 진행하였다. 공식적으로 등록된 건 AD 3명, IR 4명 이었지만 모두가 함께 2개의 대회에 참여하였다. 이 중 나는 공식적으로는 IR 팀에 배정되어 대회에 참여하게 되었다.
IR도 AD와 동일하게 간트차트를 작성하여 Task 구성을 한 눈에 보기 좋게 구성하였다. 나는 IR 간트차트를 담당하게 되었었는데 처음 간트차트를 접하고 구성하느라 하루를 통째로 투자하였던 것 같다. 덕분에 결과물은 보기 좋게 나온 것 같아 만족스러웠다.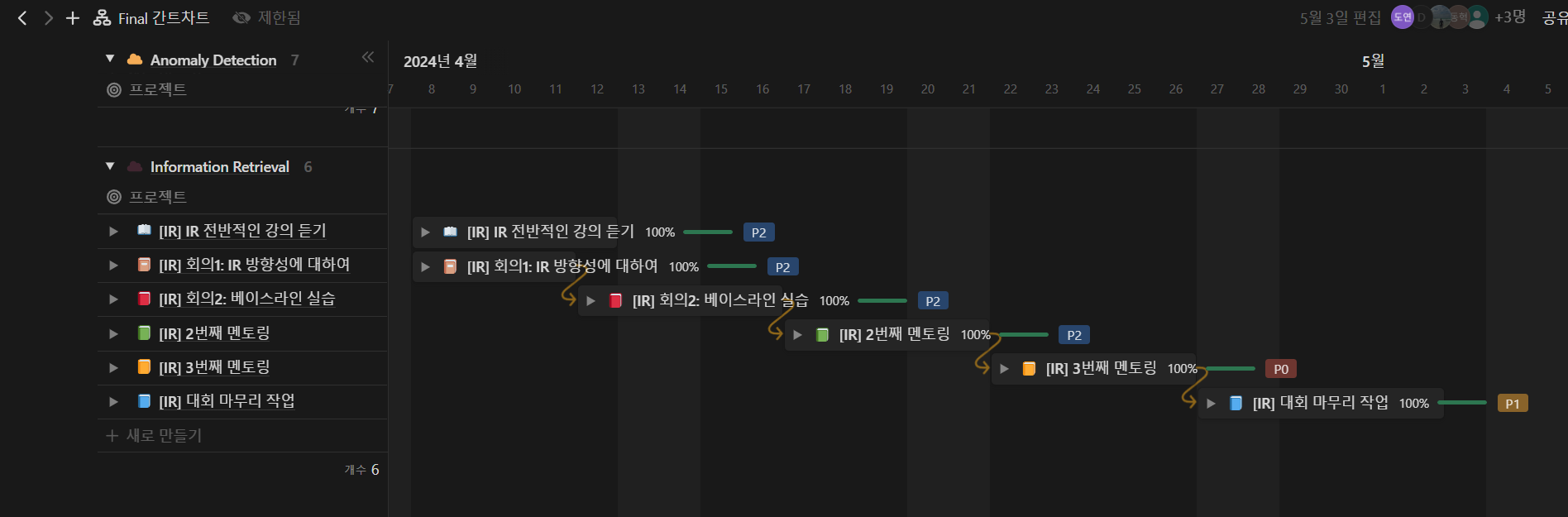
-
역할
Task 목록은 다음과 같다.
Information Retrieval 공부하기 및 강의 듣기
데이터 확인 및 분류(Data Verification)
프롬프트 엔지니어링(Prompt Engineering)
모델링 및 파라미터 튜닝(Modeling and Parameter Tuning)
결과 정리 및 보고서 작성(Summarization of Results and Report Writing)IR은 모두가 처음 접해보는 분야기도 하고 아직 다른 교육 과정에서 쉽게 접할 수 없는 내용이어서 개인적으로 공부하는 시간을 오래가졌다. 이 분야는 RAG 실습만 짜여진대로 잘 따라하고 짜여진 baseline code만 잘 이해해도 반 이상은 얻어가는 분야라는 이야기가 많았다. 처음 나의 목표는 '짜여진 Baseline code라도 잘 이해해서 얻어가자' 였다.
3. 프로젝트 수행 절차 및 방법
A. 팀 목표 설정
1주차 : 주어진 Upstage 강의 다 듣기, Data 구성 확인하기, base line code 이해하기
2주차 : Prompt engineering 고도화
3주차 : 모델링, 모델 튜닝, prompt 수정, 최종 모델 완성
4주차 : 보고서 작성, PPT 제작, GIT 관리
B. 프로젝트 사전 기획
(1) 협업 문화
- 특별한 일을 제외하고는 항상 모여서 의논하면서 Task 진행할 것(Zoom, Discord)
- 오프라인 모임이 가능할 경우 오프라인 만남을 적극 활용할 것(소통 Skill Up)
- 논의 사항 및 오류 사항이 있을 경우 즉각 팀원들과 상의할 것
- New 아이디어 발생 시 Team Notion에 작성 후 팀원 호출하여 해당 아이디어에 대해 공유할 것
- 말하지 않아도 각자 중간 진행 상황에 대해 틈틈이 보고할 것
이번 대회에서는 정말 많은 플랫폼을 활용하였다. Notion부터 시작해서 Discord, Zoom, GitHub 등등 좀 더 활용하고 있는 플랫폼을 극대화 시키고자 노력했던 것 같다. 나는 Meeting을 진행할 때마다 꼭 회의록을 작성하여 Notion에 남겨두는 습관을 들였다. 나중에 회의에 불참한 사람이든, 집중하지 못한 사람이든 누가봐도 어떤 회의를 진행하였는지 확인하기 위함이었다.
4. 프로젝트 수행 결과
팀 최고 점수
Public - Final Result(MAP : 0.9045)
개인 점수
Public - Final Result(MAP : 0.7121)

팀 최고 점수
Private -Final Result(MAP : 0.8652)
개인 점수
Private - Final Result(MAP : 0.7227)

우리 팀에서는 총 5가지의 관점으로 이 대회에 접근하였다.



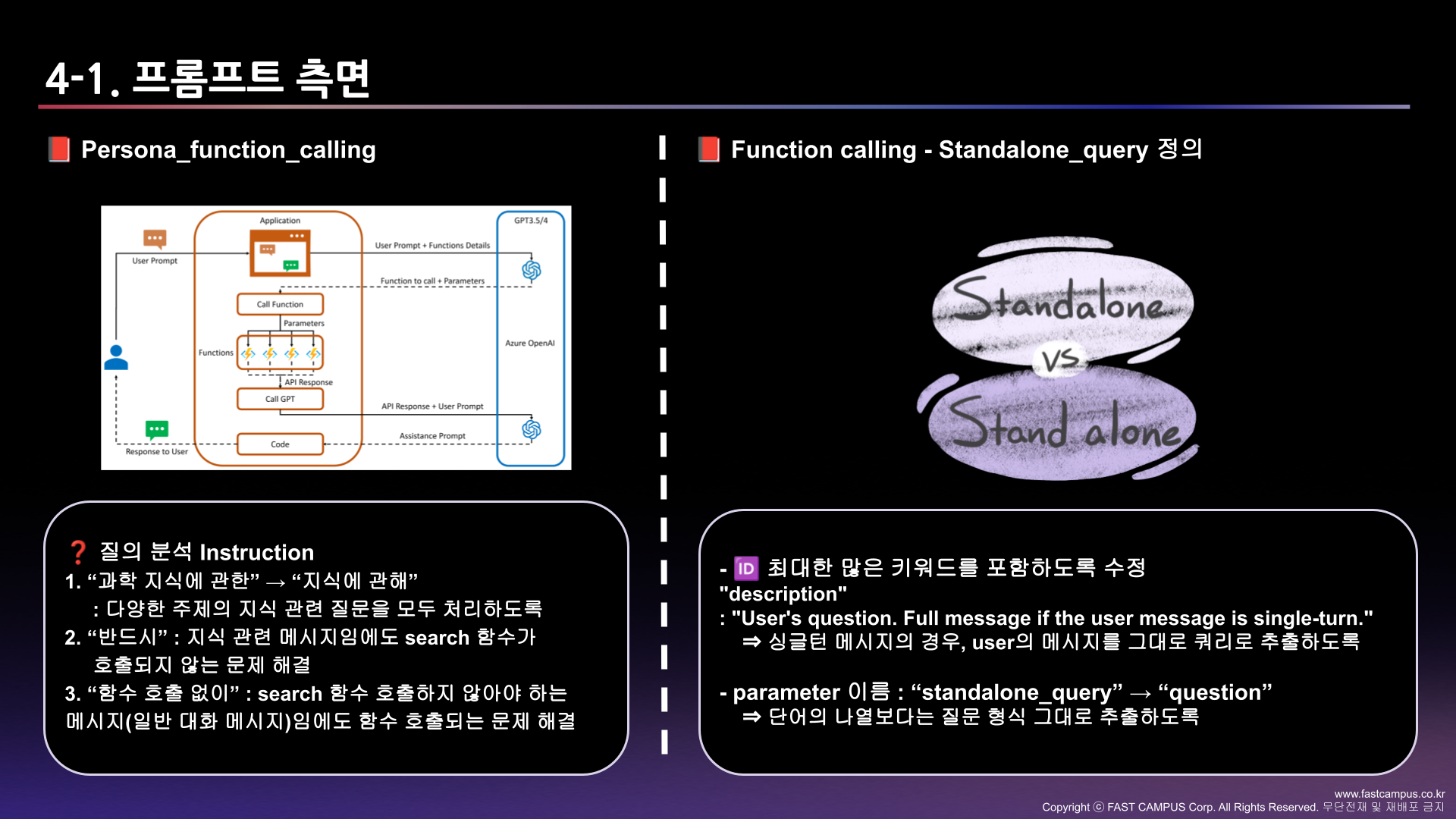





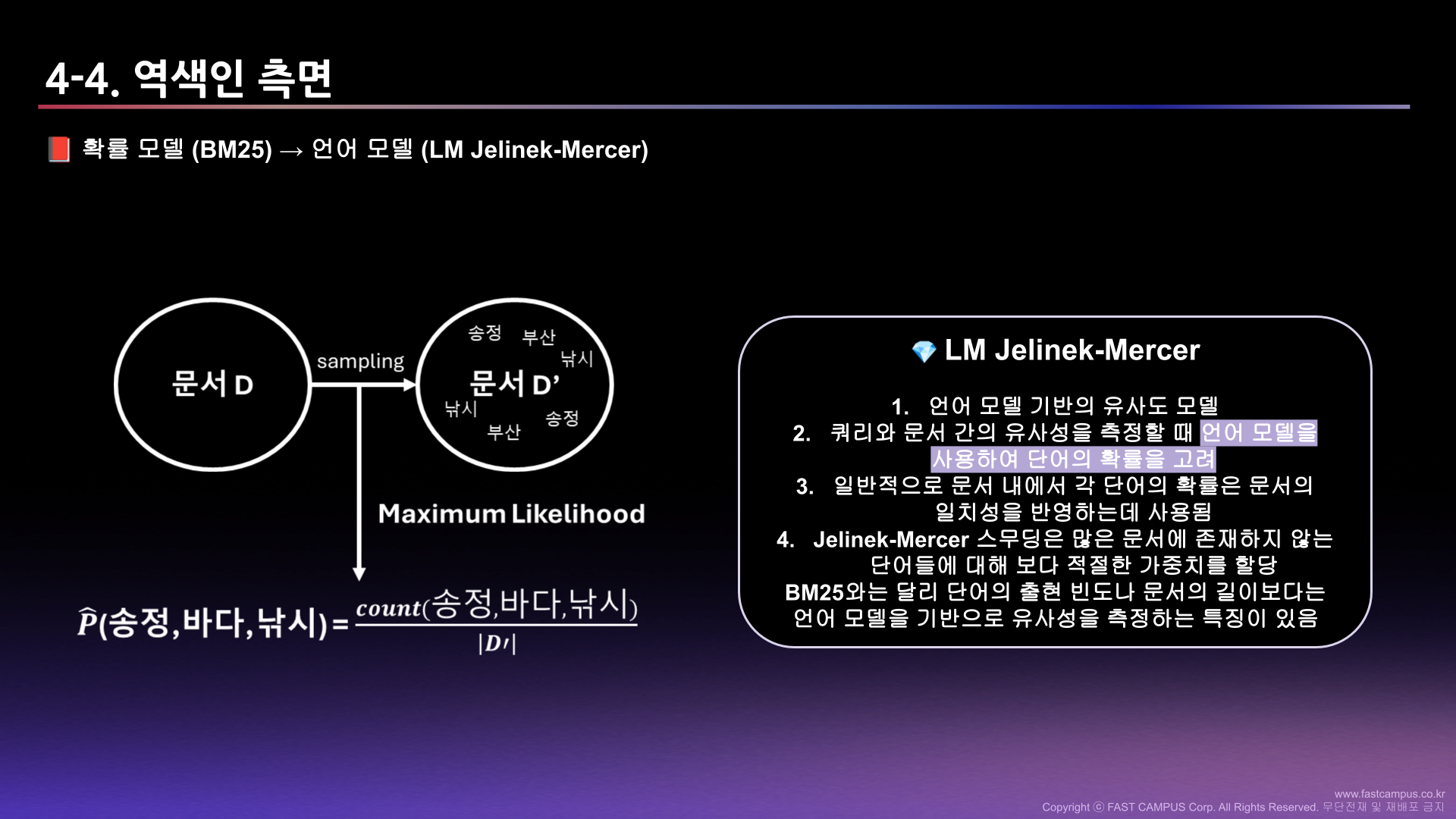


나는 이 중에서 Hybrid retrieval(Sparse + Dense)와 HyDE(Hypothetical Document Embeddings), Prompt engineering에 집중하였다.
참고 자료로 PPT 링크를 첨부하도록 하겠다. 참고자료 : PPT
5. 자체 평가 의견
A. 잘했던 점
- 새로운 관점으로 접근하기 위해 HyDE 기법을 추가하였다.
- 대회 방향에 알맞은 문서 색인을 할 수 있도록 Prompt 수정을 끊임없이 하였다.
B. 시도 했으나 잘 되지 않았던 것들
- Hybrid retrieve(Sparse + Dense)를 적용하기 위해 나름대로 코드를 작성했으나 적용이 되지 않고 있었다는 것을 대회 마무리 때 알게 되었다. 급한대로 Hybrid 적용을 한 코드로 여러가지 프롬프트 실험을 많이 해보았지만 이상하게 나만 성능이 잘 나오지 않았다. 이후에 대회가 끝나고 코드 탐색을 다시 해보았는데 Sparse와 Dense의 score를 맞추는 작업이 이루어 지지 않고 있던 문제를 발견하게 되었다.
C. 아쉬웠던 점들
- 실제로 HyDE 기법은 성능 향상에 효과가 있었다. 비록 잘못된 코드(Sparse + Dense score 작업이 이루어지지 않은)로 돌렸지만 12.55% 성능 향상이 결과적으로 확인 되었다. 하지만 Prompt 수정에 너무 많은 시간을 썼었고, HyDE 기법을 대회 마무리 쯤 알게 되어 많은 시도를 해보지 못한 것이 아쉬웠다. 팀원들에게 이 기법을 공유하여 적용할 수 있는 시간이 없어서 나 혼자 시도 해보고 마무리 했던 점이 굉장히 아쉬웠다.
D. 프로젝트를 통해 배운 점 또는 시사점
- 접하기 어려운 RAG 시스템을 직접 공부하고 경험할 수 있어서 정말 값진 경험이었다고 생각한다. 실제로 Open AI API Credit 까지 일정 금액 제공해주셔서 실제로 GPT 를 사용하여 모델을 학습시킬 수 있었던 것이 정말 좋았다. LLM의 발전은 무궁무진하다. 이 분야로 뛰어들기 위해서는 정말 많은 공부를 해야겠다는 다짐을 하게 된 계기였던 것 같다.
마무리
Information Retrieval 대회까지 모두 마무리하였다. 패스트 캠퍼스 부트캠프를 참여하며 정말 상상도 못할 정도로 많은 성장이 있었다는 생각이 든다. 코드 한 줄 칠 줄 몰랐던 내가 조금씩이나마 코드를 칠 줄 알게 되었다는 점, 코드를 읽고 이해할 수 있게 되었다는 점, 컴퓨터 프로그램 언어를 활용하여 데이터를 분석할 수 있게 되었다는 점, 이 모든 게 패스트캠퍼스가 아니었으면 불가능 했을 것 같다. 이 값진 경험들을 잊지 않고 계속 활용할 수 있도록 앞으로도 많은 노력을 할 것이다 !
#패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #인공지능개발자 #ML #머신러닝 #경진대회 #딥러닝 #NLP
