데이터 전처리 & 시각화 강의를 수강하고,
배운 내용 및 실습을 진행한 부분을 작성하고자 한다.
이전 Jupyter Notebook 실습 환경을 구성했는데, 해당 환경에서 진행한다.
Pandas
Python 내 라이브러리
표 형태(관계형) 의 데이터 분석을 할 때 가장 많이 사용 됨
Excel, csv, tsv, pickle 등과 함께 사용할 수 있음
데이터의 결측치를 쉽게 처리할 수 있고,
데이터의 시각화 및 문자열 및 날짜, 시간 처리도 간편하다.
Jupyter Note 터미널에서,
pip install pandas 를 통해 설치가 가능하다.
라이브러리 불러오기
보통 별칭은 "pd" 로 사용한다.
import pandas as pd
데이터 셋 불러오기
현재 사용 가능한 데이터셋이 없기에, 'seaborn' 라이브러리를 가져온다.
이후 'tips'라는 이름을 가진 데이터를 가져와 data 변수에 지정
import seaborn as sns
data = sns.load_dataset('tips')
data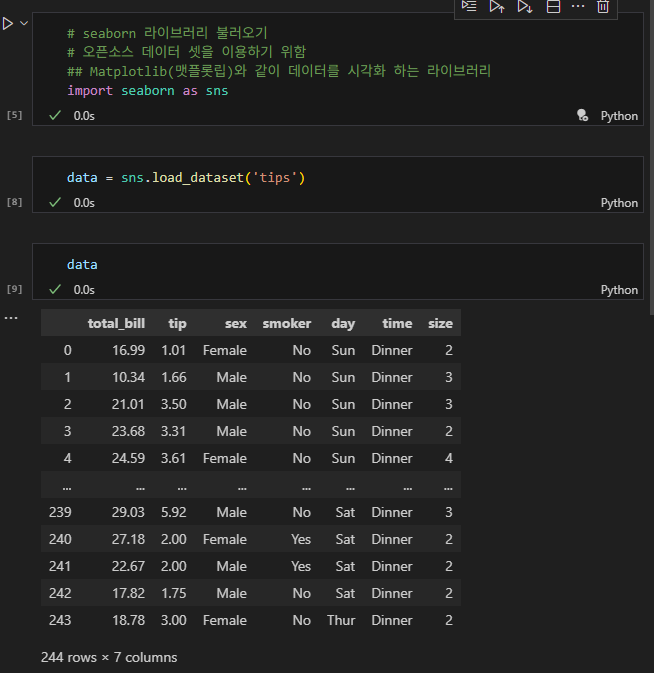
데이터 불러오기/저장하기
to_csv( ) 메소드를 통해 데이터를 파일화
( ) 안에는 경로\파일명 을 지정하면 된다.
# to_csv 메소드(데이터를 저장)
data.to_csv("tips_data.csv")
데이터 전치리를 완료하고 나서, 위와 같이 파일을 저장할 수 있다.
pandas에 내장된 read_csv 함수를 통해 데이터 불러오기
df=pd.read_csv("tips_data.csv")
df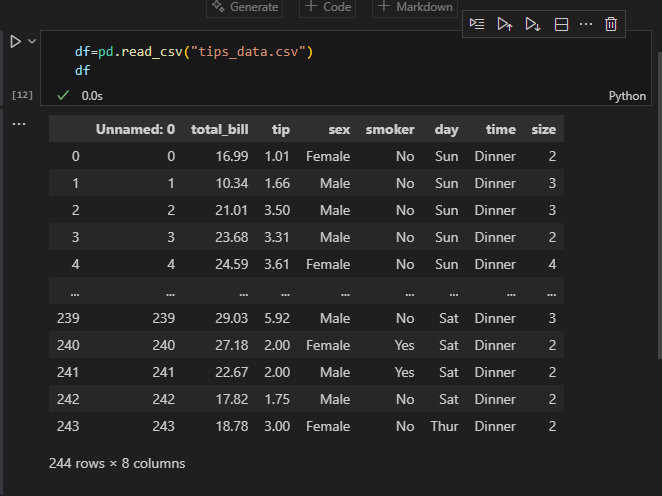
불러오기를 진행했을 때 새로운 컬럼('Unnamed:0') 이 생성된 것을 볼 수 있다.
파일 저장 시 index 생성여부에 대해 지정 해 줄 수 있는데,
기본 값이 True 이므로 index 가 생성된 것이다.
저장 시 index=False 를 통해 인덱스 생성이 되지 않게 해보자
data.to_csv("tips_data.csv", index=False)
df=pd.read_csv("tips_data.csv")
df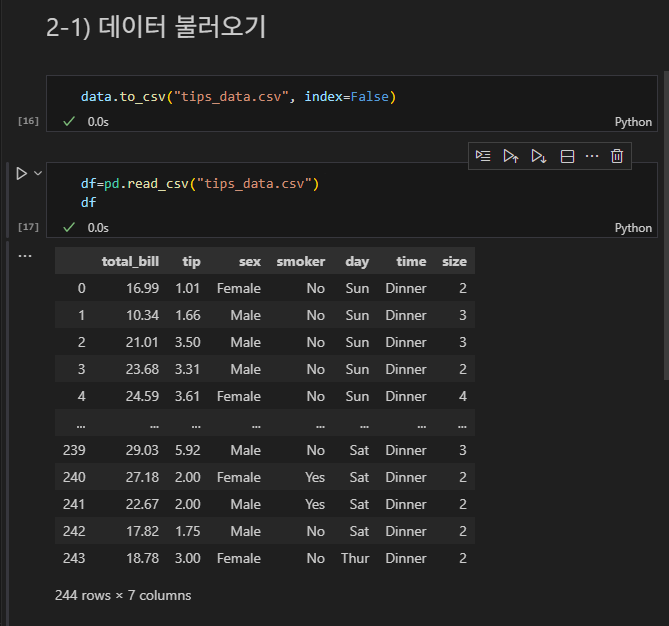
반대로 불러오기 시에도 가능하다.
data.to_csv("tips_data.csv")
df=pd.read_csv("tips_data.csv, index_col = 0")
df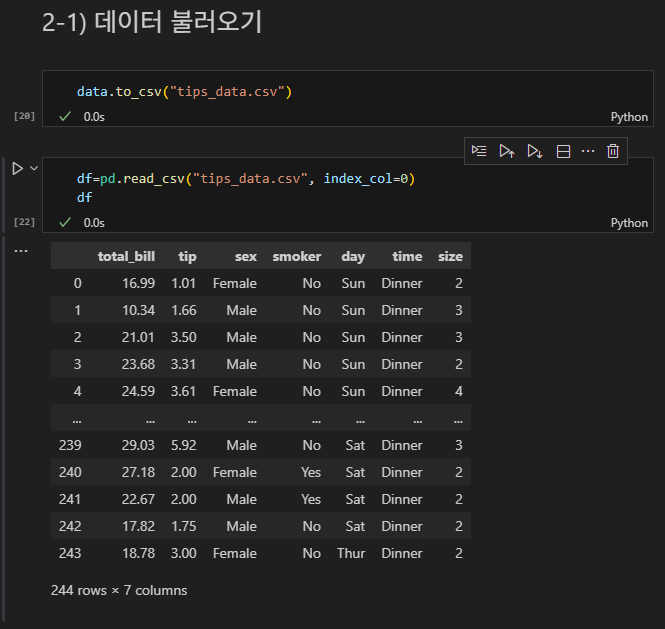

성장과 회고를 기록하는 일기장