데이터 전처리 강의 수강 중, 세션이 오늘부터 진행되었다.
직접 작성해보면서 복습한다는 생각으로 작성하려한다.
이전 VSC 내 Jupyter Notebook 실습 환경을 구성하여 진행하였고,
해당 세션을 진행하는 동안에는 Anaconda Jupyter Notebook 으로 진행한다.
각 라이브러리의 함수에 대한 모든 문법을 외울 수는 없다
어떠한 기능을 필요로 할 때,
어떤 라이브러리에 어떤 함수를 사용하면 되는지를 알아두자
Python & Library
일전 Python 장점을 얘기한 적이 있었다.
: 수많은 커뮤니티 & 라이브러리(모듈 집합체) 존재
그에 따라 Python을 사용하는 유저는 언제든지 필요에 따라,
기존 라이브러리를 호출하여 사용이 가능하다.
import (호출)
import 라이브러리 명 as 별칭라이브러리를 호출하는 명령어로, 기본 구문은 위와 같다.
오늘은 pandas 와 time 라이브러리를 사용할 예정으로 호출해준다.
Pandas
: R(프로그래밍 언어) 의 데이터프레임을 참고하여 만듬
: 데이터 프레임은 열, 행, 인덱스로 구성된 테이블 형식이다
import pandas as pd
import timeJupyter Notebook 환경에서 최초 import를 진행하면, 해당 ipynb 파일에서는 더 이상 호출 할 필요가 없다.
참고하도록 하자
✔️ import? from?
라이브러리를 호출할 때 import 를 사용한다고 했다.
from 의 경우, 라이브러리의 특정 함수를 호출하고자 할 때 사용한다.
from matplotlib.pyplot as plt # matplotlib 라이브러리의 pyplot 함수를 호출그럼 import로 호출하면 되지않나? 라고 생각하겠지만,
코드가 너무 길어지게 된다.
라이브러리 지원함수
라이브러리. 이후 tab 을 하면 사용할 수 있는 함수리스트를 볼 수 있다.
Magic Command
IPython Kernel 에서 제공되는 명령어
%, %%를 통해 실행
IPython 커널의 경우,
Jupyter Notebook 및 Lab과 같은 웹 기반 대화형 환경을 위한 표준 커널이다.
즉, Jupyter 환경에서만 사용가능한 특수 커맨드라고 생각하자
자주쓰이는 커맨드 중 time (코드 실행시간 측정) 을 사용해보았다.
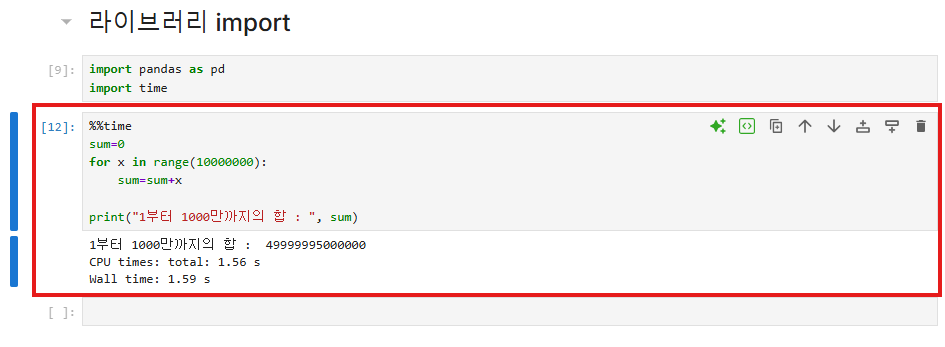
%%time : 셀 전체 수행 후 소요 시간
EDA 시작
EDA는 Exploratory Data Analysis 의 약자
데이터를 이해하기 위해, 요약 통계와 시각화를 활용하여
데이터의 주요 특성, 변수 간의 잠재적 관계, 패턴, 이상치 등을 찾아내는 초기 분석 단계이다.
즉 본격적인 데이터 분석을 하기 위해 데이터를 체크한다는 개념이다
데이터 프레임 만들기
데이터프레임은 테이블 형태로 만들 수 있고,
리스트와 딕셔너리 활용할 수 있다.
data1 = [['Choi',22],['Kim',48],['Joo',32]]
df4 = pd.DataFrame(data1, columns=['Name','Age'])
data2 = {'Name' : ['Choi','Kim','Joo'],'Age':[22,48,32]}
df5 = pd.DataFrame(data2)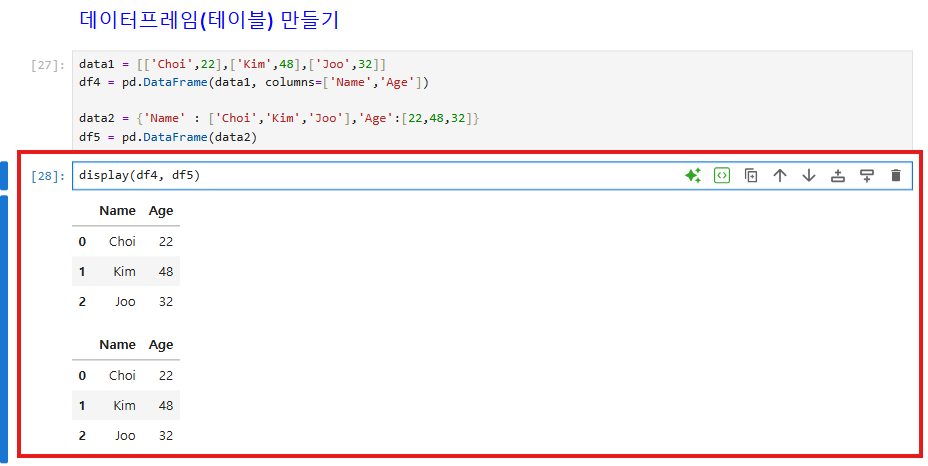
리스트 및 딕셔너리로 이루어진 데이터를 데이터프레임(테이블)화 한 것을 볼 수 있다.
추가적으로,
Display 내장함수를 쓰면 여러 개의 데이터 셋을 볼 수 있다.
display(df1, df2 ...)
CSV 파일을 통한 LOAD
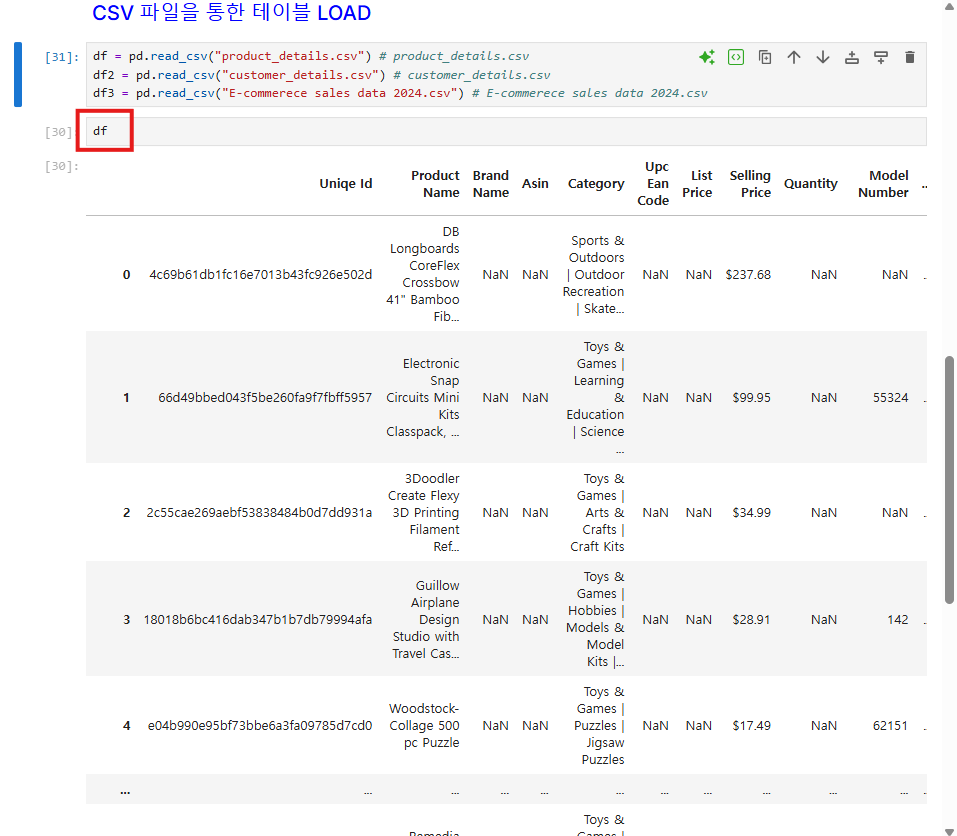
pandas의 read_csv 함수를 이용해 읽어온 파일을 출력한다.
pd.read_csv(파일명)
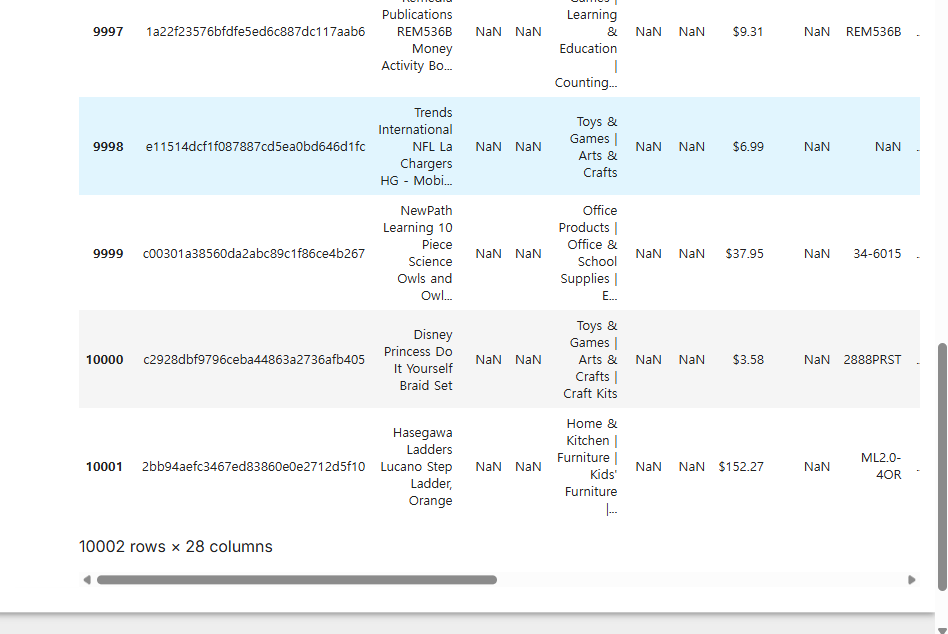
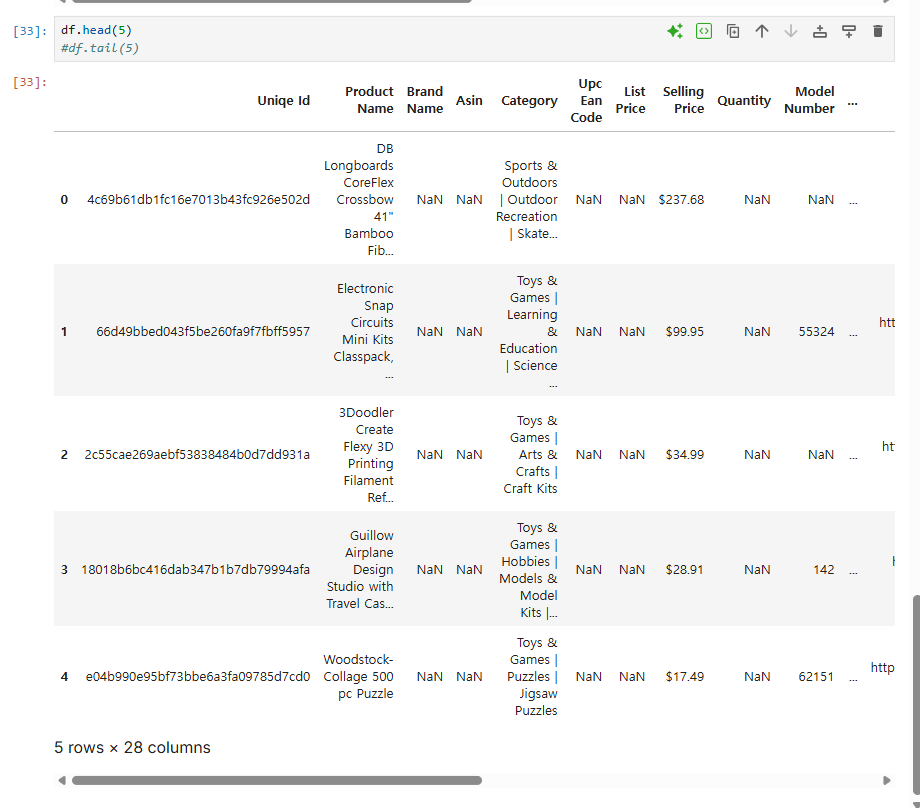
처음/마지막 기준 5줄 출력
SQL Limit 절과 비슷, 기본 값 5로 지정
df.head() / df.tail()
구조 파악하기
행의 갯수를 출력
len(df)

