c++ 언어를 기반으로 작성된 글입니다! 🐰

1. 단순 데이터 구조 📦
| 데이터 타입 | 바이트 | 범위 |
|---|---|---|
| (signed)int | 4 | -2,147,483,648 ~ 2,147,483,647 |
| unsigned int | 4 | 0 ~ 4,294,967,295 |
| char | 1 | -128 ~ 127 |
| unsigned char | 1 | 0 ~ 255 |
| short | 2 | -32,768 ~ 32,767 |
| (signed)long long | 8 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| unsigned long long | 8 | 0 ~ 18,446,744,073,709,551,615 |
| bool | 1 | true or false |
| float | 4 | 3.4E+/-38(7개의 자릿수) |
| double | 8 | 1.7E+/-308(15개의 자릿수) |
- 데이터 타입의 범위를 유의하여 overflow가 발생하지 않도록 해야 한다!
- 대부분의 경우, 코딩 테스트는 최대 범위가 long long의 범위를 벗어나지 않으므로 범위가 매우 큰 경우 long long을 사용해야 overflow가 나지 않는다.
2. 비단순 데이터 구조 🏭
2-1. 선형 구조
1) Array 배열 🗄️
- 가장 기본적인 데이터 구조
- 생성시 설정된 셀의 수가 고정되고, 각 셀에는 인덱스 번호가 부여된다.
- 배열을 활용 시 부여된 인덱스를 통해 해당 셀 안에 있는 데이터에 접근할 수 있다.
- 동일한 타입의 데이터들을 저장한 구조이다.

int arr[5] = {0,}; //배열 선언 및 0으로 초기화
for(int i=0; i<5; i++){
cin>>arr[i]; //인덱스 번호로 데이터를 접근할 수 있다.
}2) Linked List 연결 리스트 🧶
- 각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장한다.
- 배열의 크기를 미리 선언해야 하는 배열 리스트와 달리 연결 리스트는 데이터의 숫자만큼만 메모리를 사용하면 되어서 메모리 낭비가 적다.

- 연결 리스트는 다른 자료구보의 구현에 사용되는 도구로써 더 큰 의미를 지닌다.
- 따라서, 연결 리스트는 스택과 큐를 구현하는데에 사용된다.
(이때, 스택과 큐는 배열기반과 연결 리스트 기반으로 구현된다.)
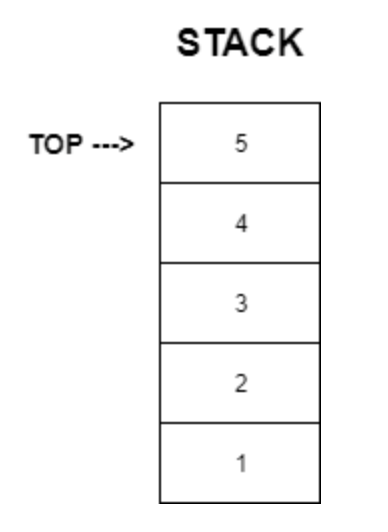
3) Stack 스택 🗑️
- LIFO 구조(Last In First Out)로 가장 마지막에 들어온 데이터가 가장 먼저 리턴된다.
- 한 방향으로만 입력할 수 있으며, 구조 중간에 값을 끼어 넣어 저장할 수 없다.
- 즉, 같은 크기의 자료를 정해진 한 방향으로만 입력, 저장, 삭제가 가능하다.
#include <stack>
stack<int> sta; //int 타입의 스택 sta 선언
sta.push(1); //1을 스택 sta에 추가한다.
stack.pop(); //스택의 top 데이터를 삭제한다.
sta.top(); //스택의 top 데이터를 반환한다.
sta.size(); //스택의 현재 사이즈 반환한다.
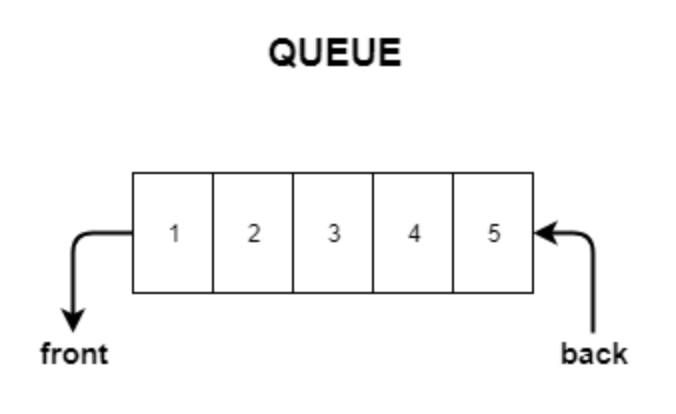
sta.empty(); //스택이 비어 있는지 확인한다.4) Queue 큐 🛝
- 양방향에서 입력과 출력이 진행되는 자료구조
- FIFO 구조(First In First Out)로 가장 먼저 들어온 데이터가 가장 먼더 리턴된다.
- 너비 우선 탐색(BFS)에서 사용된다.
#include <queue>
queue<int> q; //int 타입의 queue 선언
q.push(1); //1을 큐에 추가한다.
q.pop(); //큐의 front 데이터를 삭제한다.
q.front(); //큐의 가장 맨 앞의 데이터를 반환한다.
q.back(); //큐의 마지막 데이터를 반환한다.
q.empty(); //큐이 비어 있는지 확인한다.
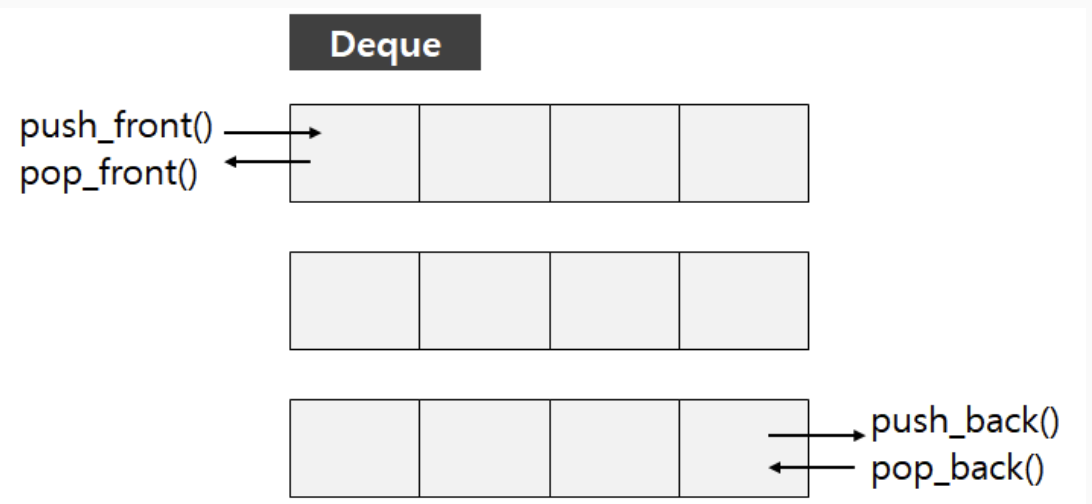
q.size(); //큐의 현재 사이즈를 반환한다.5) Deque 덱 🚪
- 배열 기반의 구조 (vector와 마찬가지로 배열 기반의 컨테이너)
- 앞쪽에서 데이터를 추가, 삭제가 가능하며, 뒤쪽에서 데이터를 추가, 삭제가 가능하다.
즉, 스택 + 큐의 구조라고도 볼 수 있다. (정확히는 아니지만, 스택 + 큐의 특징을 가지고 있다.)
#include <deque>
deque<int> d; //int 타입의 deque 선언
d.push_back(1); //1을 deque의 마지막에 추가한다.
d.pop_back(); //deque의 마지막 데이터를 삭제한다.
d.push_front(1); //deque의 가장 맨 앞에 1을 추가한다.
d.pop_front(); //deque의 맨 처음 데이터를 반환한다.
d.insert(d.begin()+2, 100); //begin()+2 위치에 100을 추가한다.
d.erase(d.begin()+2); //begin()+2 위치의 값을 삭제한다.
d.front(); //deque의 첫번째 값을 반환한다.
d.end(); //deque의 마지막 값을 반환한다.- 참고 자료 : https://novlog.tistory.com/23
2-2. 비선형 구조 🖌️
1) Tree 트리 🎄
- 노드들이 나무 가지처럼 계층적으로 연결된 비선형 자료 구조
- 최상위 노드(루트)가 있고, 최상위 노드 아래에 다른 하위 노드가 있고, 그 하위 노드 안에는 또 다른 하위 노드가 있는 부모와 자식 형태이다.
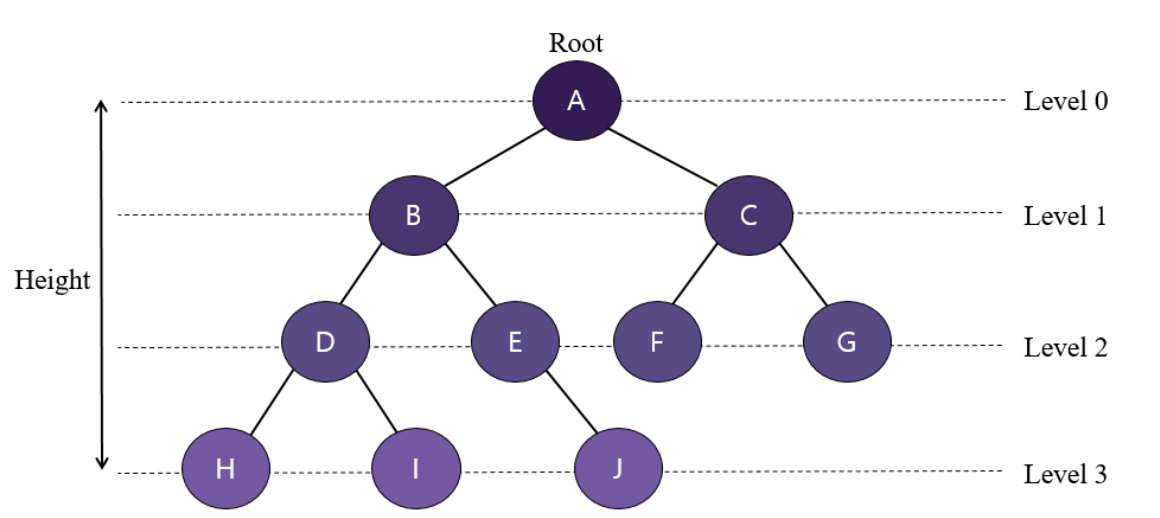
2) Heap 힙 🎈
- 완전 이진 트리의 형태로 만들어진 자료 구조
- 최대값이나 최솟값을 빠르게 찾아내기 위해서 사용한다.
- 우선 순위 큐(priority queue), 힙 정렬에 사용된다.
이때, 우선 순위 큐는 들어간 순서에 상관없이 우선 순위가 높은 데이터가 먼저 나오는 구조이다. - 최대 힙(max heap) : 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- 최소 힙(min heap) : 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리

#include <queue>
priority_queue<int> pq;
pq.push(1); //우선순위 큐에 원소를 추가한다.
pq.pop(); //우선순위 큐의 top 원소를 제거한다.
pq.top(); //우선순위 큐의 top 원소(우선순위가 높은 원소)를 반환한다.
pq.empty(); //우선순위 큐가 비어있는지 확인한다.
pq.size(); //우선순위 큐의 원소의 개수를 반환한다.- 참고 자료 : https://kbj96.tistory.com/15
3) Graph 그래프 📈
- 정확한 내용은 나중에 BFS, DFS를 다룰 때 이야기할 예정이다!!
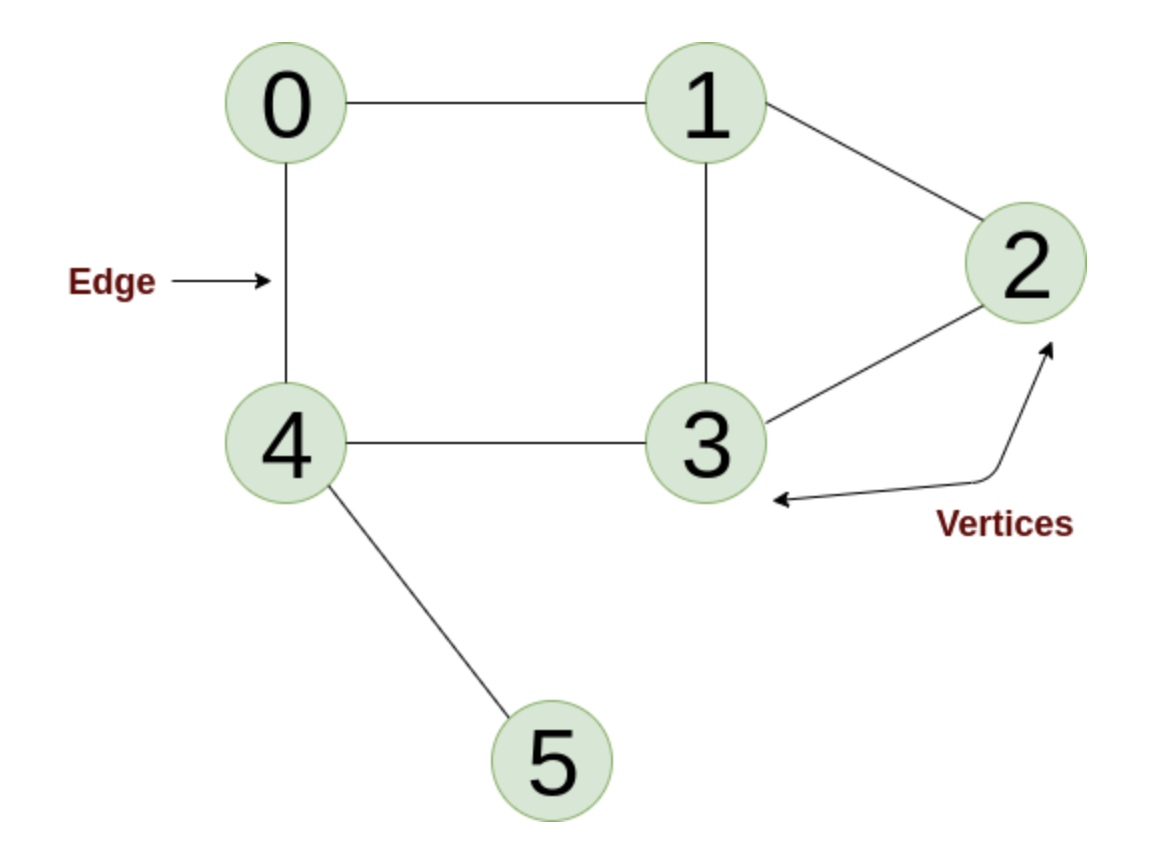
참고자료 📒

컴퓨터공학과 학생이며, 백엔드 개발자입니다🐰