0️⃣ 서론
기존에는 JPA를 사용하여 스크랩의 검색을 원하는 로직을 구현하려고 했습니다.
그러나, 원래 의도는 타이틀이나 디스크립션(설명)에서 keyword가 있는 삭제되지 않고 사용자만의 스크랩을 찾는 로직이었습니다.
따라서 위의 로직을 지키기 위해서 생성되어야 하는 sql문의 조건을 살펴보겠습니다.
- 삭제되지 않는 스크랩(DeletedDateIsNull)이어야 한다.
- 사용자의 스크랩이어야 한다. (User)
- 대소문자를 무시하고 타이틀이나 디스크립션(설명)에서 keyword가 있어야 한다. (TitleContainingIgnoreCaseOrDescriptionContainingIgnoreCase)
따라서 아래와 같이 코드를 작성했습니다!
@Transactional
public Slice<GetScrapResponse> searchScraps(String email, String keyword, Pageable pageable) {
User user = userService.validateUser(email);
Sort sort = Sort.by(Sort.Direction.DESC, "createdDate");
PageRequest pageRequest = PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(),
sort);
Slice<Scrap> scrapSlice = scrapRepository
.findAllByUserAndDeletedDateIsNullAndTitleContainingIgnoreCaseOrDescriptionContainingIgnoreCase(
user, keyword, keyword, pageRequest)
.orElseThrow(() -> new NotFoundException(ErrorCode.NOT_EXISTS_SCRAP));
return scrapSlice.map(GetScrapResponse::of);
}그러나, 아래와 같이 실제로 작동되는 로직은 제가 의도한 로직이 아니라 타이틀이나 디스크립션에 or문이 적용되지 않고 아래로 내려갑니다.
따라서 삭제된 scrap에서도 keyword가 검색되는 로직이 됩니다...🥲
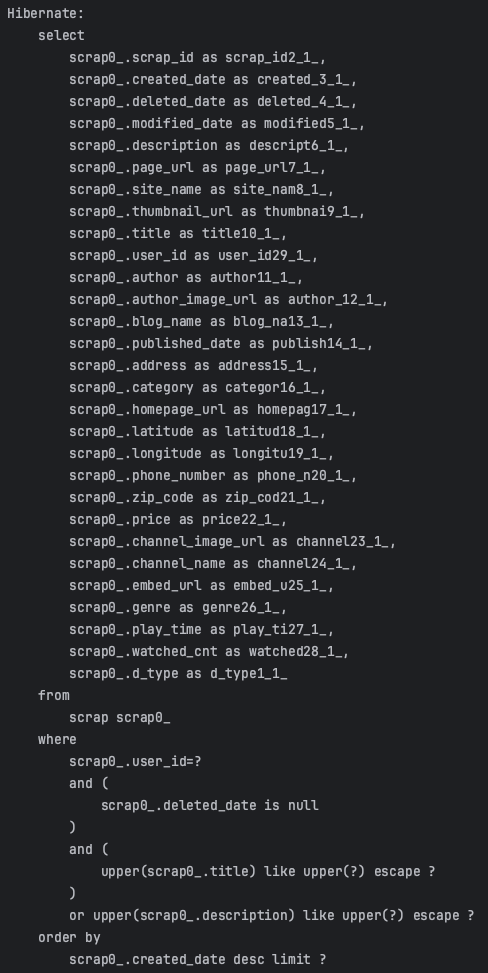
더 나아가서, jpa에서 주어진 sql문을 사용하면 메소드 명이 엄청나게 길어져서 조건을 붙일 때마다 길어져서 메소드를 파악하기 어렵습니다.
scrapRepository.findAllByUserAndDeletedDateIsNullAndTitleContainingIgnoreCaseOrDescriptionContainingIgnoreCase(user, keyword, keyword, pageRequest)
그리고 keyword를 2번 입력해주었는데 sql문의 조건이 4개이기 때문에 각각의 조건을 맞추어주기 위해서 동일한 keyword임에도 불구하고 두 번 반복해서 중복이 발생하게 된다는 문제점이 있습니다.
그러면 이러한 문제를 해결하기 위해서 도입한 방법을 소개하겠습니다!!
1️⃣ 본론
먼저 중요한 점은 의도한 로직을 지키기 위해서는 타이틀이나 디스크립션에 or문이 먼저 적용되어야 하는 우선순위가 있습니다.
즉, 완벽하게는 sql을 작성하지는 않았지만 아래와 같이 scrap의 타이틀과 디스크립션에서 키워드가 있는지 판단하는 sql문이 ( ) 소괄호 부분이 먼저 실행되어야 합니다.
select scrap.blog_name from scrap where scrap.user_id =? and scrap_deleted_date is null and (scrap.title like %keyword% or scrap.description like %keyword%)
이렇게 우선순위를 정해야 하거나, 검색 같이 조건문과 로직이 복잡한 경우에는 2가지 방식으로 해결할 수 있습니다.
1. ✍️ 직접 Query문 작성하기
- Java Persistence Query Language(JPQL)은 객체지향 쿼리로 JPA가 지원하는 다양한 쿼리 방법 중 하나입니다.
- @Query 어노테이션를 사용해서 직접 query문을 정의할 수 있게 됩니다.
public interface ScrapRepository extends JpaRepository<Scrap, Long> {
@Query(value = "SELECT s FROM Scrap s WHERE s.user = :user AND s.deletedDate IS NULL AND (s.title LIKE %:keyword% OR s.description LIKE %:keyword%) ORDER BY s.createdDate DESC")
Optional<Slice<Scrap>> findAllByUserAndDeletedDateIsNullAndTitleContainingIgnoreCaseOrDescriptionContainingIgnoreCase(User user, String title, String description, Pageable pageable);
}위에와 같이 @Query 어노테이션을 사용하여 원하는 query를 직접 지정해서 우선순위 및 자세한 사항을 직접 작성할 수 있습니다.
그러나, query문을 직접 작성하면 조건 및 오타를 작성하게 될 수도 있으며, 쿼리 문자열이 상당하게 길어집니다.
2. 🐳 QueryDSL 적용하기
우선은 QueryDSL이 무엇인지 자세하게 설명해드리겠습니다.
QueryDSL은 하이버네이트 쿼리 언어(HQL: Hibernate Query Language)의 쿼리를 타입에 안전하게 생성 및 관리해주는 프레임워크입니다.
- 문자가 아닌 코드로 쿼리를 작성할 수 있어 컴파일 시점에 문법 오류를 확인할 수 있습니다!!
- 인텔리제이와 같은 IDE의 자동 완성 기능의 도움을 받을 수 있습니다.
- 복잡한 쿼리나 동적 쿼리 작성이 편리합니다.
- 쿼리 작성 시 제약 조건 등을 메서드 추출을 통해 재사용할 수 있습니다.
- JPQL 문법과 유사한 형태로 작성할 수 있어 쉽게 적응할 수 있습니다.
2-1. QueryDSL 의존성 추가하기
- 아래 부분은 QueryDSL로 추가되는 부분만 나타내었습니다.
buildscript {
ext {
queryDslVersion = "5.0.0"
}
}
plugins {
//위에 부분은 생략
id "com.ewerk.gradle.plugins.querydsl" version "1.0.10"
}
dependencies {
//위에 부분은 생략
// QueryDSL
implementation "com.querydsl:querydsl-jpa:${queryDslVersion}"
implementation "com.querydsl:querydsl-apt:${queryDslVersion}"
}
// querydsl
def querydslDir = "$buildDir/generated/'querydsl'"
querydsl {
jpa = true
querydslSourcesDir = querydslDir
}
sourceSets {
main.java.srcDir querydslDir
}
compileQuerydsl {
options.annotationProcessorPath = configurations.querydsl
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
querydsl.extendsFrom compileClasspath
}
2-2. QuerydslConfig 파일 설정하기
@Configuration
public class QuerydslConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}2-3. Repository 구조 변경하기
여기에서는 Spring Data Jpa Custom Repository를 사용하여 repository 구조(ScrapRepsitory, ScrapRepositoryCustom, ScrapRepositoryCustomImpl)를 변경하였습니다.
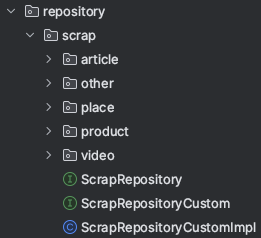
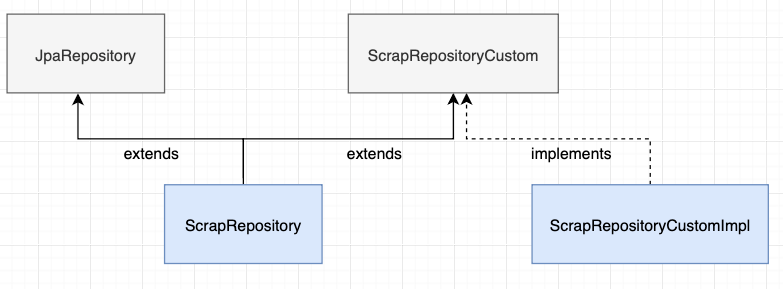
2-4. QueryDSL 사용하기
public interface ScrapRepository extends JpaRepository<Scrap, Long>, ScrapRepositoryCustom {
}- ScrapRepositoryCustom 클래스에 원하는 기능의 메소드를 작성합니다.
- 이때, 저는 스크랩에서 키워드를 검색하고, 최신순으로 조회할 예정이라서
searchKeywordInScrapOrderByCreatedDateDesc(User user, String keyword, Pageable pageable)라고 작성하였습니다. - 이전과 달라진 점은
scrapRepository.findAllByUserAndDeletedDateIsNullAndTitleContainingIgnoreCaseOrDescriptionContainingIgnoreCase(user, keyword, keyword, pageRequest)에서 메소드명이 간결해지고 명확하게 나타낼 수 있게 되었습니다. - 그리고 keyword를 한 번만 넘겨주어도 됩니다.
public interface ScrapRepositoryCustom {
Slice<Scrap> searchKeywordInScrapOrderByCreatedDateDesc(User user, String keyword, Pageable pageable);
}- JPAQueryFactory을 사용해서 QueryDSL을 본격적으로 작성해보겠습니다.
- 이때, 여기에서 주목해야 할점은 where 문 부분입니다.
scrap.user.eq(user).and(scrap.deletedDate.isNull()).and(scrap.title.containsIgnoreCase(keyword).or(scrap.description.containsIgnoreCase(keyword)))에서 타이틀과 디스크립션에서 keyword를 검색하는 부분에서 () 소괄호를 붙여서 or문이 우선순위가 높도록 설정할 수 있습니다.- @Query문과 다른 점은
@Query(value = "SELECT s FROM Scrap s WHERE s.user = :user AND s.deletedDate IS NULL AND (s.title LIKE %:keyword% OR s.description LIKE %:keyword%) ORDER BY s.createdDate DESC")보다 더 구조적이라서 의도한 로직을 더 쉽게 파악할 수 있다는 점입니다. - 그리고 offset, limit와 같이 세세한 부분도 설정해줄 수 있어서, 나중에 no-offset과 같이 성능을 향상시켜야 할 경우에도 쉽게 작성할 수 있습니다.
@RequiredArgsConstructor
public class ScrapRepositoryCustomImpl implements ScrapRepositoryCustom {
private final JPAQueryFactory queryFactory;
@Override
public Slice<Scrap> searchKeywordInScrapOrderByCreatedDateDesc(User user, String keyword,
Pageable pageable) {
List<Scrap> contents = queryFactory
.selectFrom(scrap)
.where(
scrap.user.eq(user)
.and(scrap.deletedDate.isNull())
.and(scrap.title.containsIgnoreCase(keyword)
.or(scrap.description.containsIgnoreCase(keyword)))
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize()+1)
.orderBy(scrap.createdDate.desc())
.fetch();
return new SliceImpl<>(contents, pageable, hasNextPage(contents, pageable.getPageSize()));
}
private boolean hasNextPage(List<Scrap> contents, int pageSize) {
if (contents.size() > pageSize) {
contents.remove(pageSize);
return true;
}
return false;
}
}아래와 같이 위의 QueryDSL을 사용하면 의도한 로직대로 query문이 동작함을 알 수 있습니다.
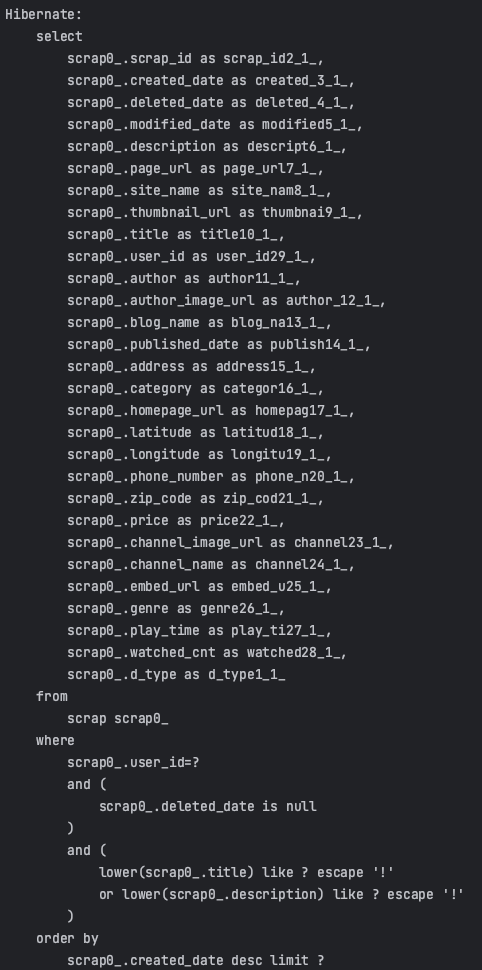
그리고 이전에는 JPA를 사용해서 단순한 로직이어서 Repository에 대한 test 코드를 작성하지 않았지만, 이번에는 직접 QueryDSL로 정의해주었기 때문에 해당 메소드에 대한 테스트를 작성했습니다.
@DataJpaTest
@ActiveProfiles("test")
@Sql(scripts = "/truncate.sql", executionPhase = ExecutionPhase.AFTER_TEST_METHOD)
@Sql(scripts = "/setup.sql", executionPhase = ExecutionPhase.BEFORE_TEST_METHOD)
@Import(TestConfig.class)
public class ScrapRepositoryTest {
@Autowired
private ScrapRepository scrapRepository;
@Autowired
private UserRepository userRepository;
String email = "1234@naver.com";
@Test
void should_has_next_is_returned_true_when_the_next_page_is_present() {
// 다음 페이지가 있을 때, hasNext가 true로 반환된다.
// given
User user = userRepository.findByEmailAndDeletedDateIsNull(email).get();
String keyword = "오늘";
Pageable pageable = PageRequest.of(0, 2);
//when
Slice<Scrap> results = scrapRepository.searchKeywordInScrapOrderByCreatedDateDesc(user,
keyword, pageable);
// then
assertThat(results.hasNext()).isTrue();
}
@Test
void should_the_title_is_returned_when_searching_for_keywords_without_case_insensitive() {
// 대소문자를 구분하지 않고 keyword를 검색할 때, 검색 결과가 있으면 해당 title을 반환된다.
//스크랩 검색할 때, 대소문자를 구분하지 않고 검색할 수 있는 지 확인
// given
User user = userRepository.findByEmailAndDeletedDateIsNull(email).get();
String keyword = "toDay";
Pageable pageable = PageRequest.of(0, 2);
//when
Slice<Scrap> results = scrapRepository.searchKeywordInScrapOrderByCreatedDateDesc(user,
keyword, pageable);
// then
assertThat(results.getContent().get(0).getDescription()).isEqualTo("Today is rainy");
}
}

참고 자료 1 : https://tecoble.techcourse.co.kr/post/2021-08-08-basic-querydsl/
참고 자료 2 : https://velog.io/@soyeon207/QueryDSL-Spring-Boot-에서-QueryDSL-JPA-사용하기
2️⃣ 결론
- 이전 프로젝트에서 QueryDSL을 사용해본 적이 있어서, 어떤 방식으로 동작하는지는 알고는 있었지만, 이전에는 필요해서 QueryDSL을 도입하기보다는 프로젝트가 이미 QueryDSL을 사용하고 있어서 사용했습니다.
- 따라서 왜 QueryDSL을 사용해야 하는지 정확하게 알지는 못한 채로 JPA의 기본 문법보다 길어서 최대한 JPA를 사용하려고 하고 QueryDSL을 사용하려고 하지 않았던 것 같습니다.
- 그러나, 이번에는 QueryDSL을 먼저 도입하지 않고 직접 JPA를 사용하다가 불편함을 느끼고 왜 QueryDSL을 사용하는 지 직접 체험해보고 정말 필요하구나!!라는 점을 깨닫고 사용하게 된 것 같아서 QueryDSL의 진가를 더 알게 되고 더 잘 사용할 수 있겠다는 생각을 했습니다☺️
- 앞으로도 기술이나 새로운 라이브러리 등을 도입할 때 필요성을 깨닫고 제대로 사용해야겠다는 다짐을 했습니다!!
