대규모 트랜잭션을 처리하는 배민 주문시스템 규모에 따른 진화
본 페이지는 [우아한테크세미나] 1부: 대규모 트랜잭션을 처리하는 배민 주문시스템 규모에 따른 진화 참고하여 작성되었습니다.
1. 배달의민족 주문 시스템

MSA
- 가게, 메뉴, 주문, 결제, 배달 등 수많은 시스템이 통신하는 구조
- 다른 시스템에 문제가 생겨도 주문이 가능하게 하는 방법을 고민
대용량 데이터
- 배민 주문 시스템은 방대한 데이터를 저장. 일 평균 300만 건의 주문을 저장하며. 수년간의 데이터를 보관하고 관리.
- 대규모 데이터의 정합성을 보장하고, 조회 성능을 보장할 수 있는 방법을 고민
대규모 트랜잭션
- 배민 주문 시스템은 일 평균 300만건의 주문이 발생
- 서비스 특성 상 점심, 저녁 시간에 순간적으로 더 많은 트랜잭션 발생. 즉, 순간적으로 몰리는 트래픽에 대해 대규모 트랜잭션을 처리할 수 있도록 고민
여러 시스템과 연계
- 배민 주문 시스템은 이벤트 기반으로 통신하고 MSA를 지향한다. 주문 시스템은 이벤트 기반으로 여러 시스템과 통신
- 이벤트 발행에 대한 일관성을 보장, 이벤트 아키텍처를 단순화하기 위한 고민
2. 성장하는 주문 시스템
여러 성장통들

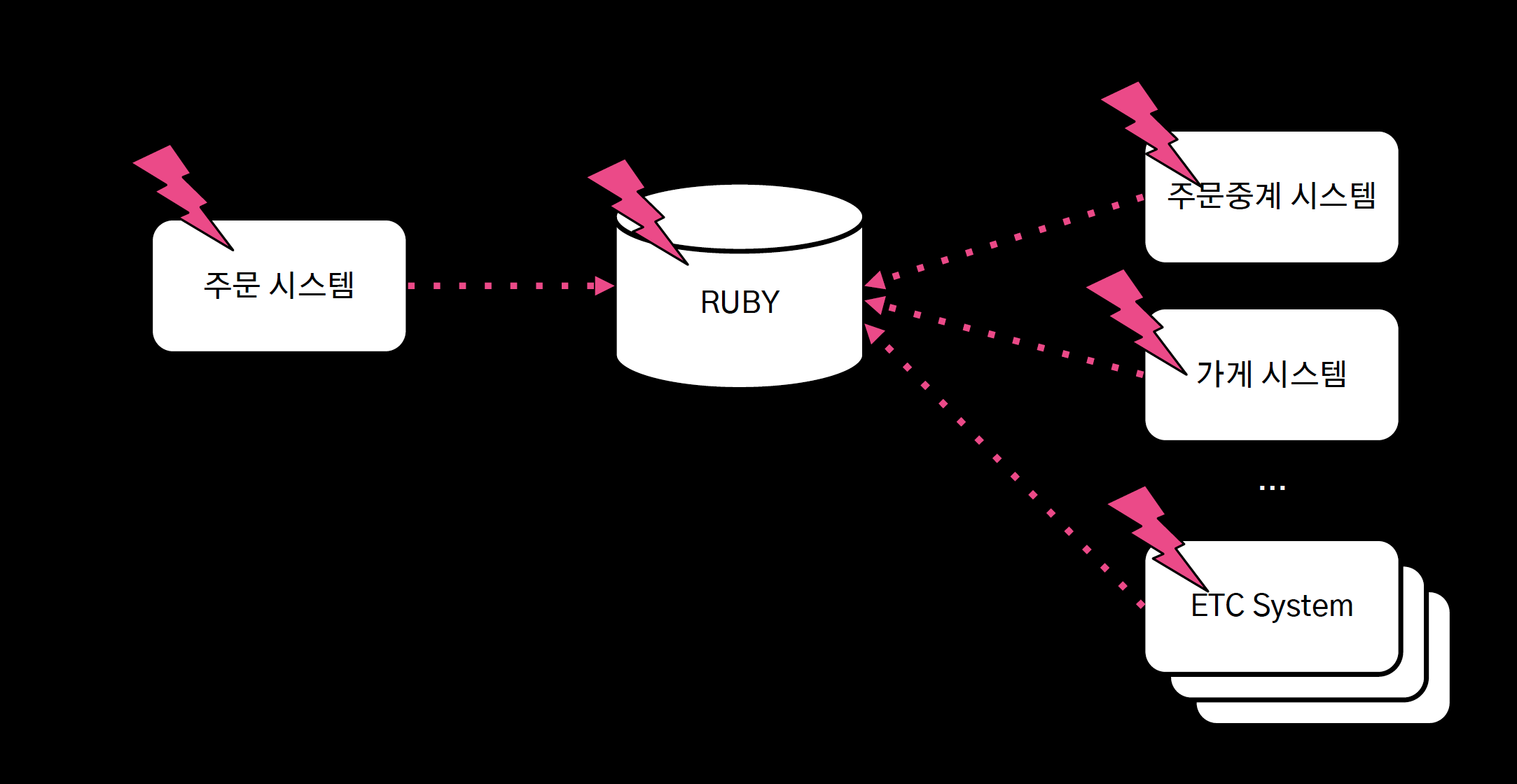
1) 단일 장애 포인트
- 중앙 집중 DB의 장애, 전체 시스템으로 전파
5년 전 배민의 아키텍처
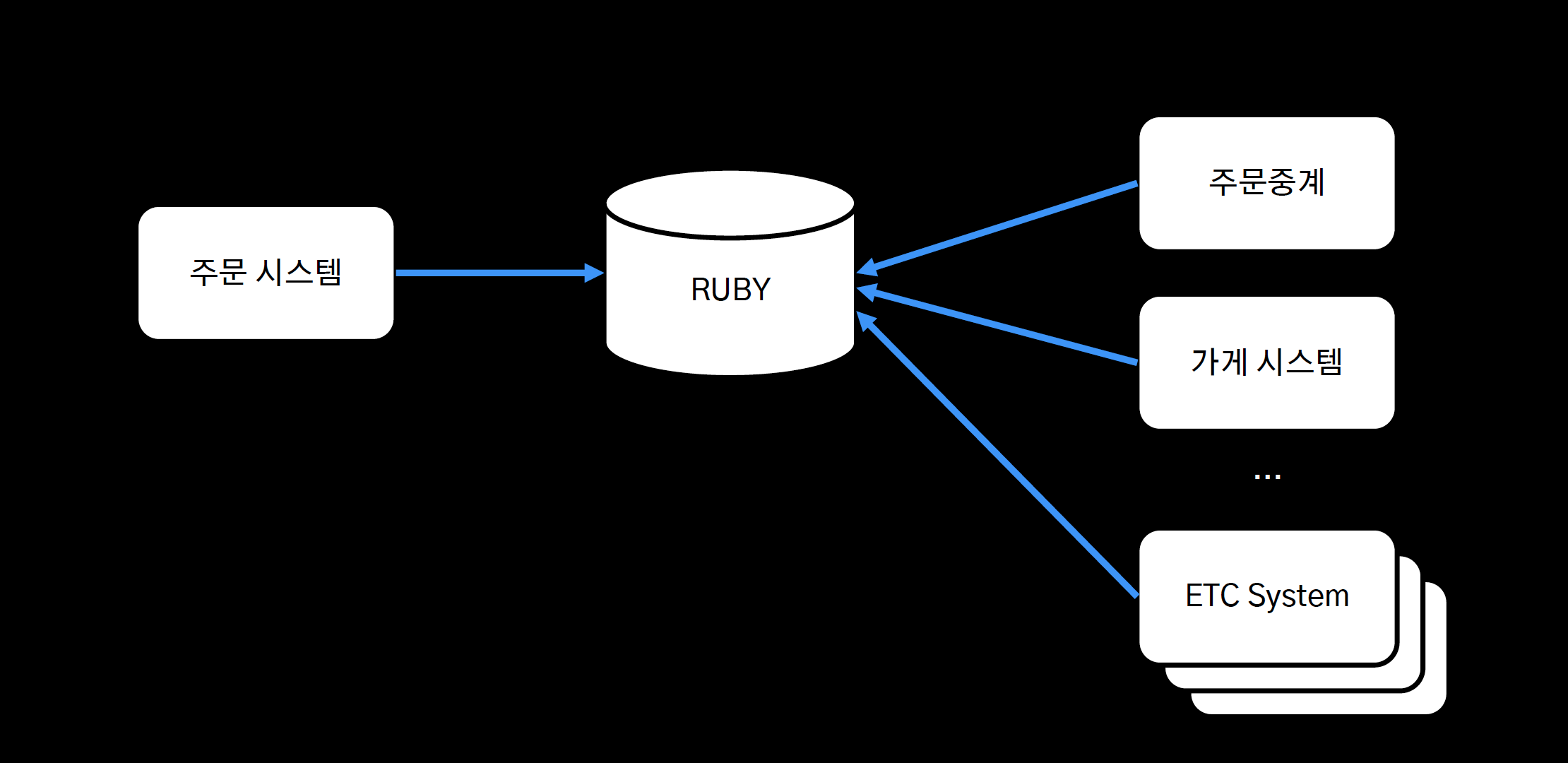
- Ruby라는 중앙 집중 저장소에 모든 시스템이 의존
- 특정 시스템의 장애가 발생하면 그 부하가 중앙 집중 저장소에 고스란히 전파가 되고, 모든 시스템에 장애가 전파가 되는 구조였다.
탈루비 프로젝트
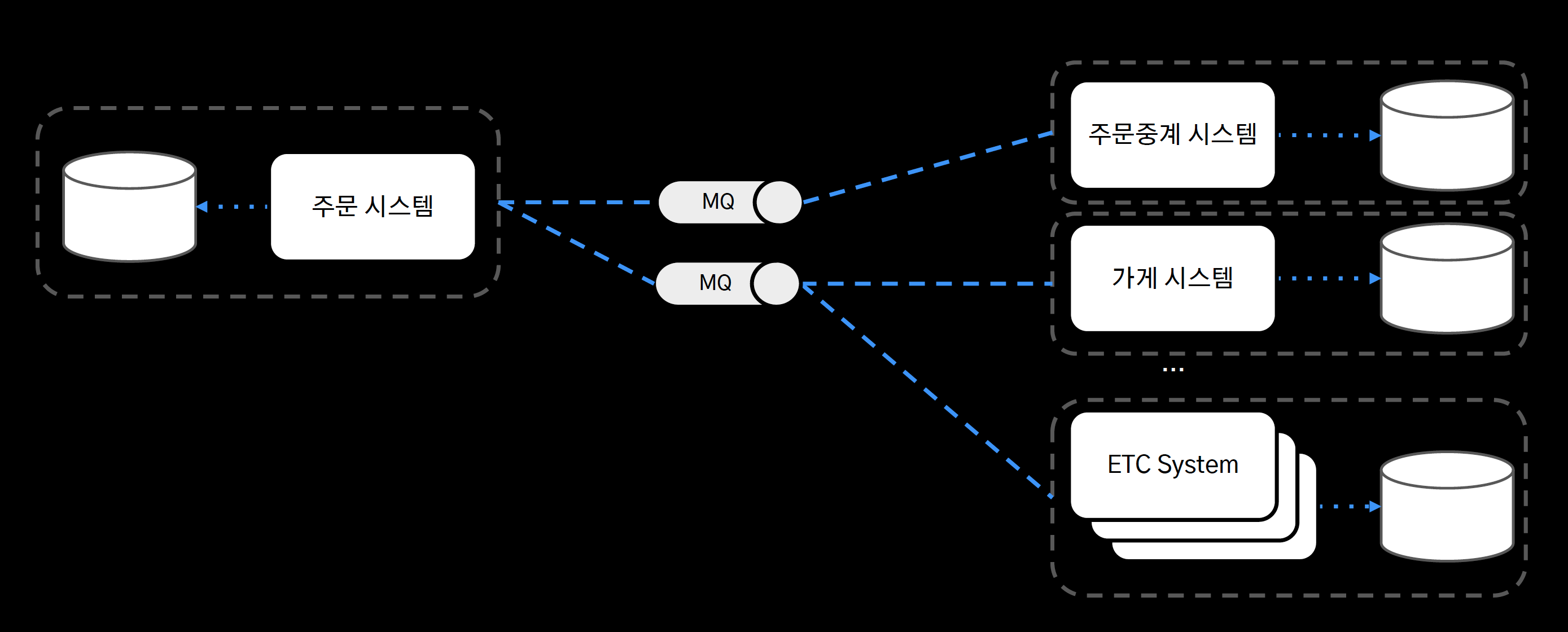
- 각 서비스 별로 DB를 분리하고, 시스템 간 통신은 Message Queue 기반으로 통신하도록 수정
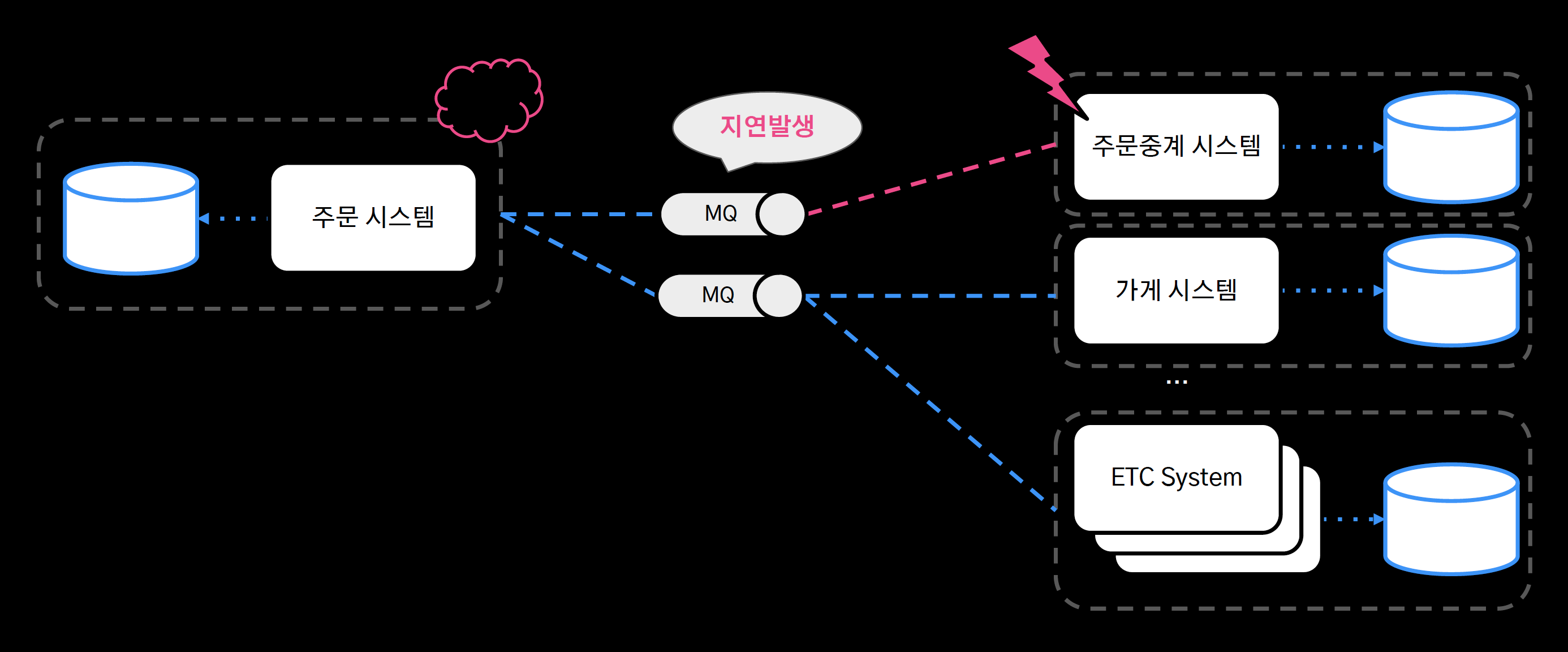
- 만약 주문중계 시스템에 문제가 발생하더라도 가게 시스템 등 다른 시스템들은 아무런 영향 없이 서비스를 유지할 수 있다.
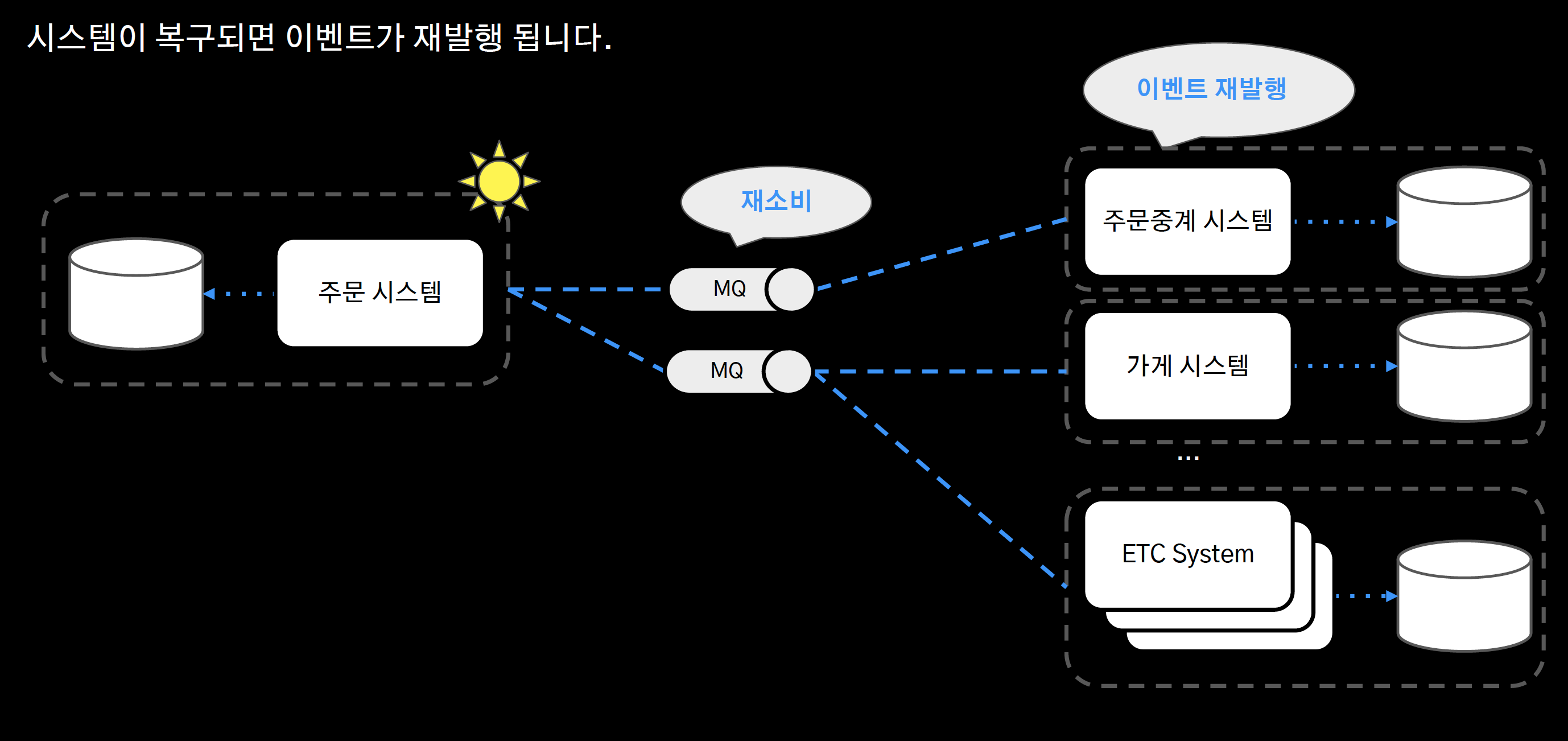
- 또한 주문중계 시스템이 복구가 되면 주문 시스템에 이벤트를 재발행해준다.
요약

2) 대용량 데이터
- 주문 시스템 아키텍처를 조금 더 자세하게 들여다 보자
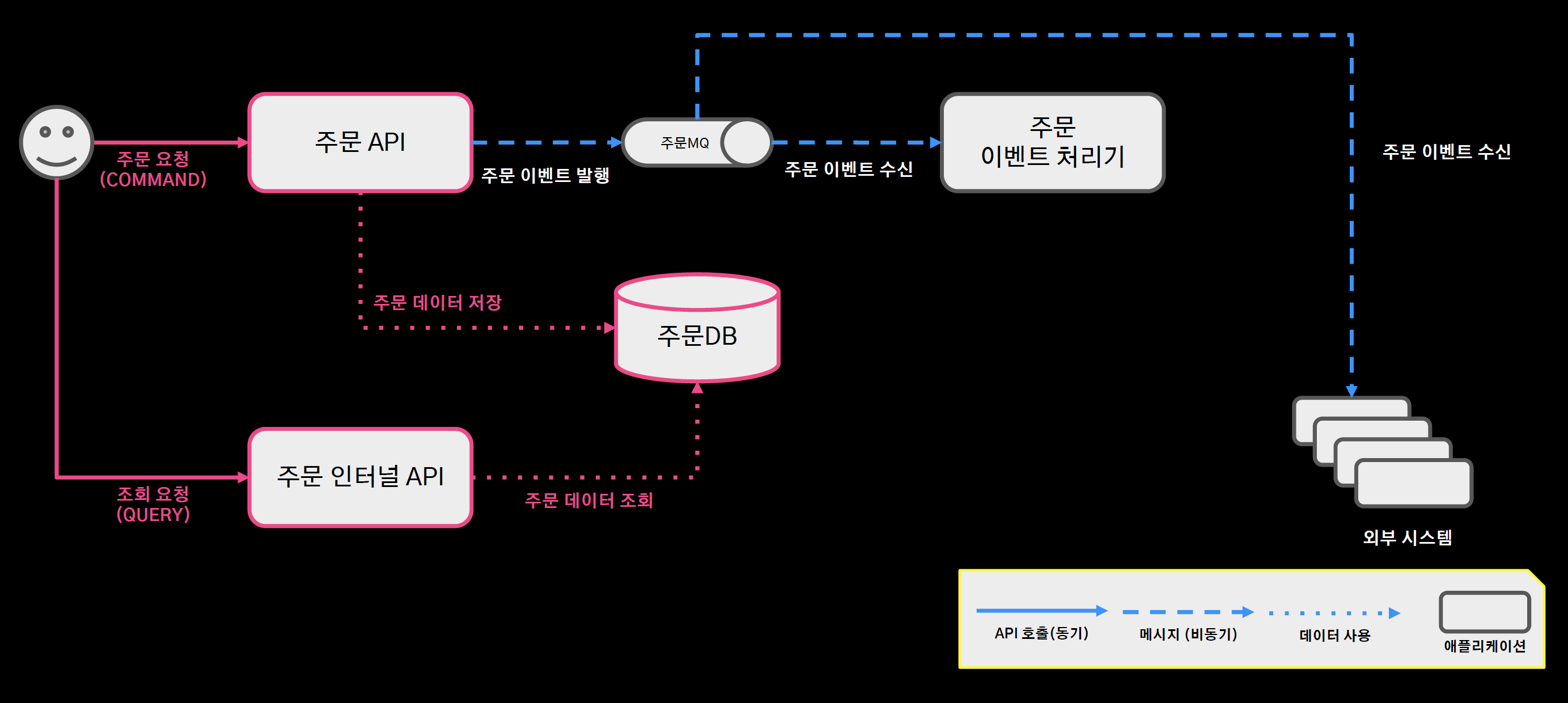
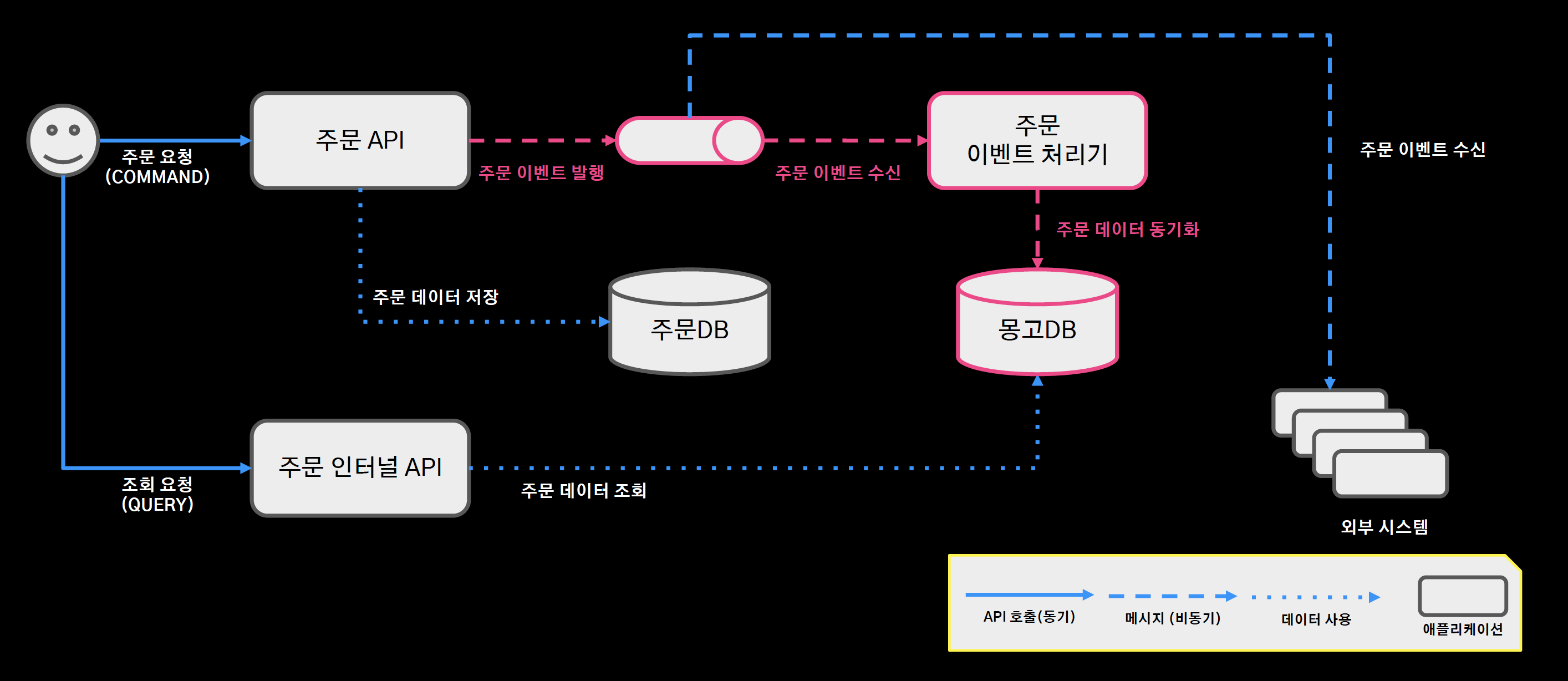
주문 시스템 아키텍처
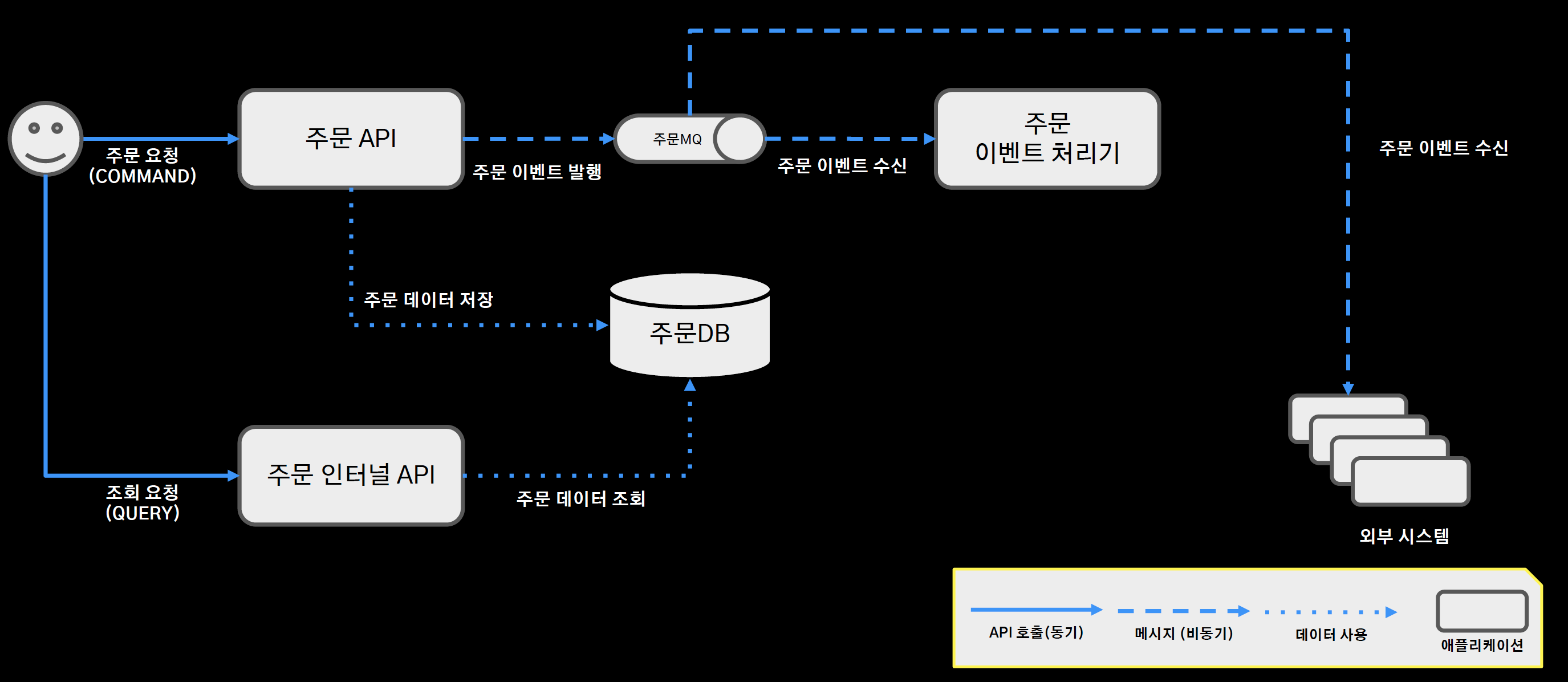
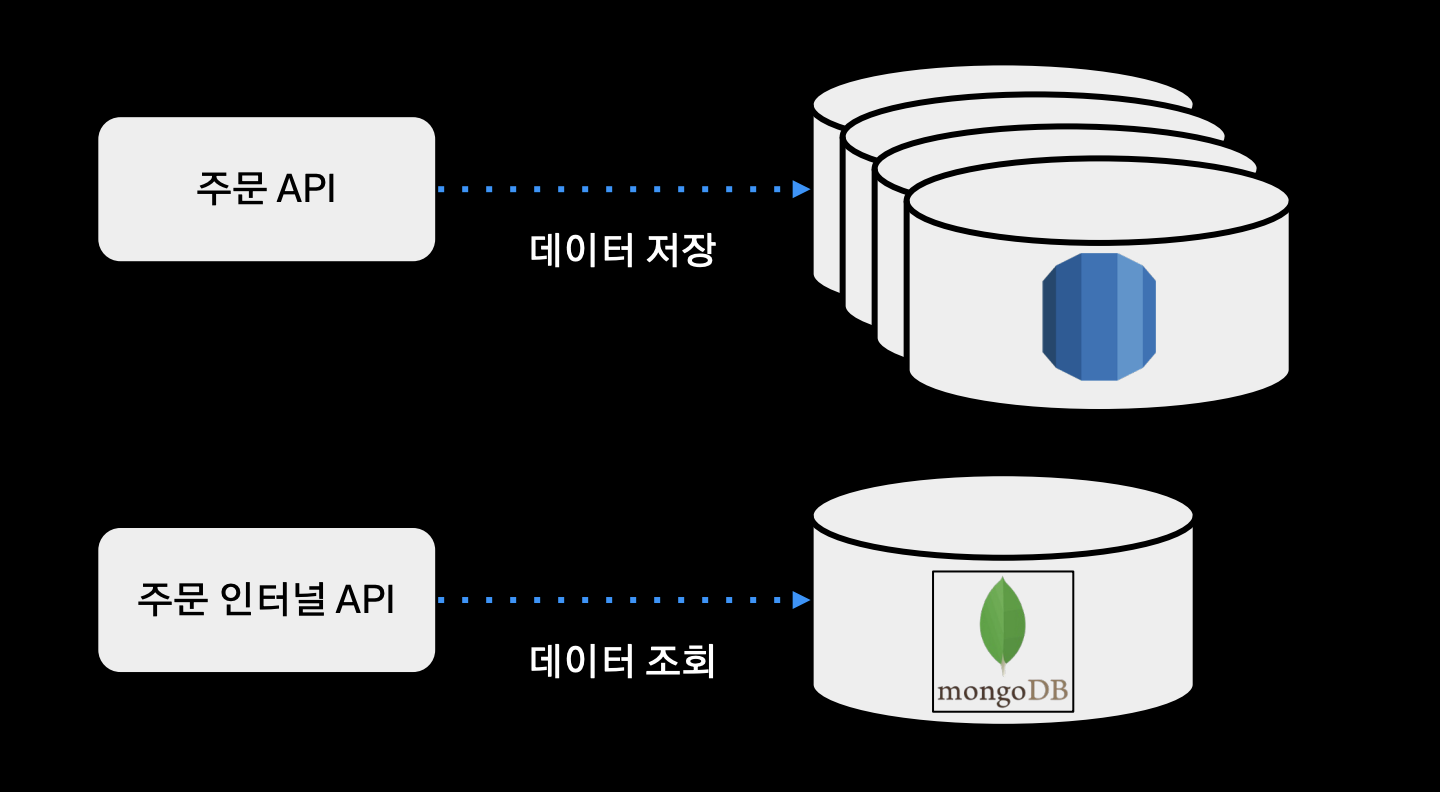
- 주문 커맨드 요청: 주문 API 서버 엔드포인트가 처리해서 RDBMS에 저장
- 주문 쿼리 요청: 주문 인터널 API 서버 내에서 주문 데이터 조회
- 주문 이벤트 처리기: 주문 도메인 로직과 서비스 로직을 분리하기 위해 중간에 메시지 큐를 두면서 분리
- 주문의 도메인 로직이 수행이 되면, 도메인 이벤트를 주문 MQ에 발행하고 주문 이벤트 처리기는 이 이벤트를 수신하면서 알림 전송이나 현금 영수증 발행, 데이터 동기화 등 도메인 로직과 분리되는 서비스 로직을 처리한다.
- 또한 외부 시스템도 이 메시지 큐를 구독한다.
- 대용량 데이터 조회 성능에 이슈가 있는 부분을 빨간 선으로 하이라이팅
- 정규화된 주문 DB에서 저장과 조회가 함께 일어나는 구조
주문내역
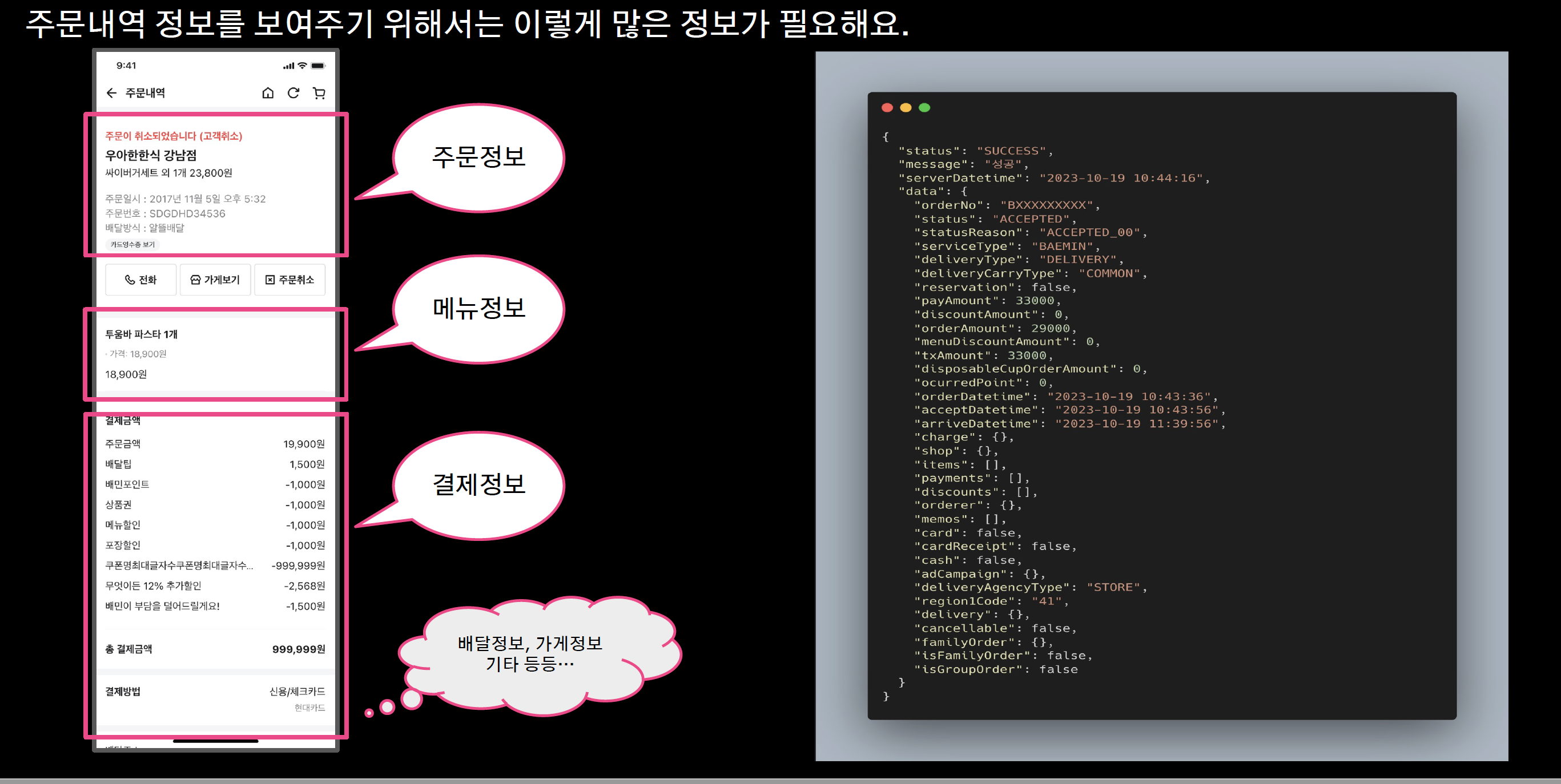
- 이 정보를 정규화 DB에서 조인 연산으로 가져오고 성능 저하로 이어짐.
조인 연산으로 인한 성능 저하
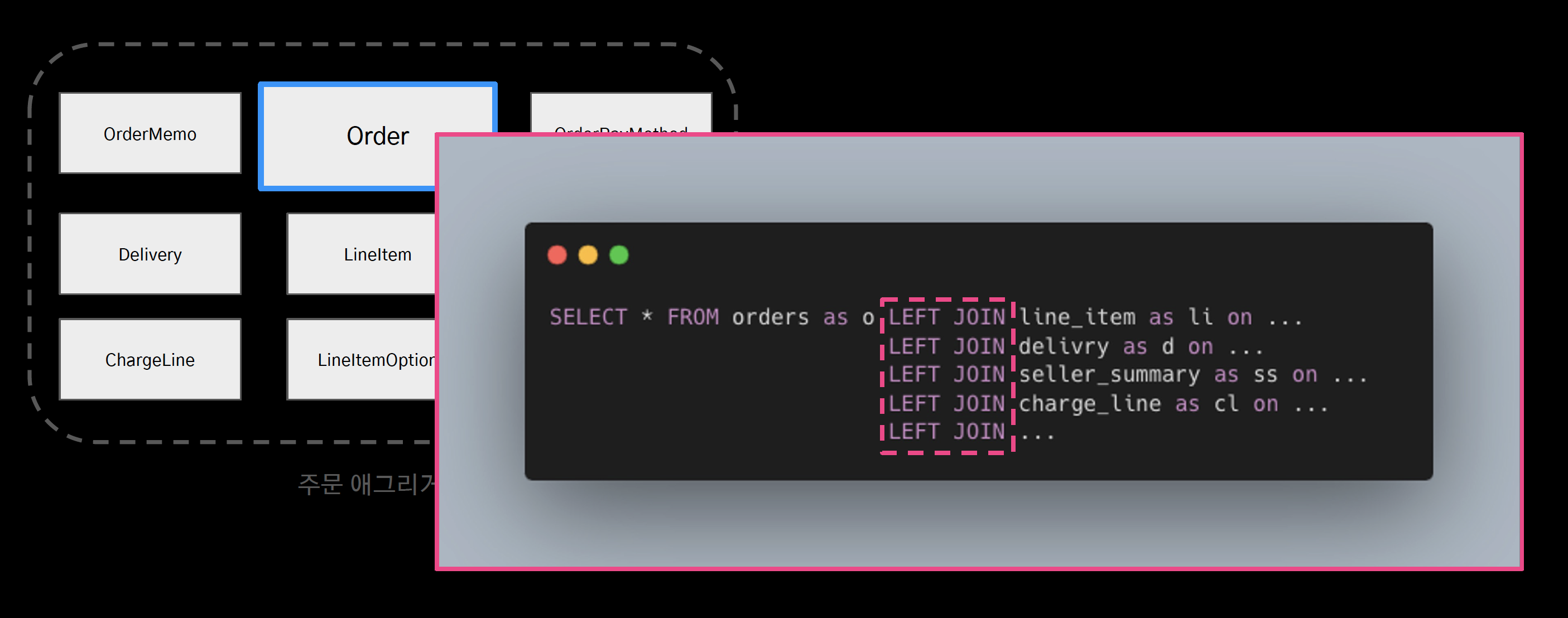
- 정규화된 애그리거트는 조회 시 조인 연산을 필요로 하게 했고, 이는 곧 성능 저하로 이어졌다.
역정규화를 통한 모델링
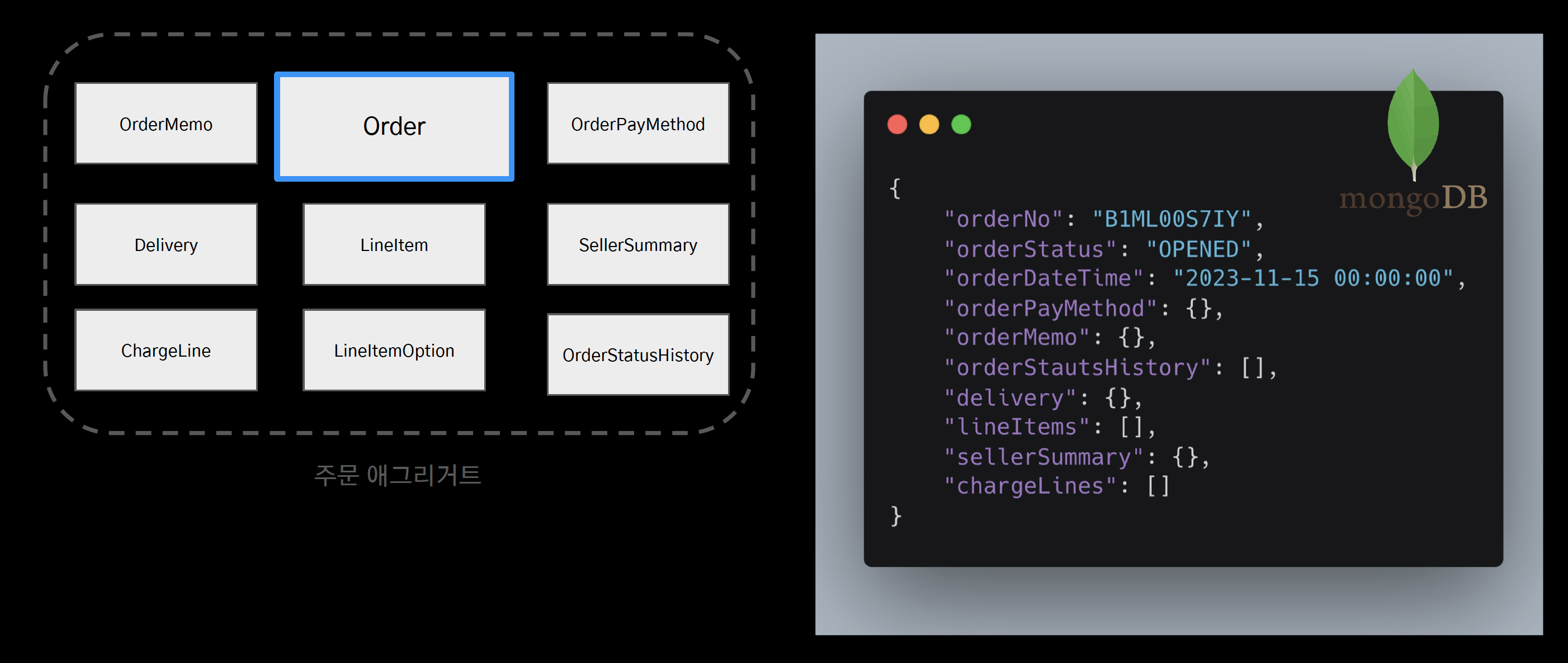
- 조회성능을 높이기 위해 단일 도큐먼트로 역정규화를 진행
- 조회를 위한 조회모델을 MongoDB로 설계
db.orders.find({"_id": "B1ML00S7IY"})- 조인 연산을 모두 없애고 id 조회만으로 조회 성능을 올렸다.
- 그러면 주문 DB와 동기화는 어떤 방법으로 했을까?
주문 도메인 생명 주기
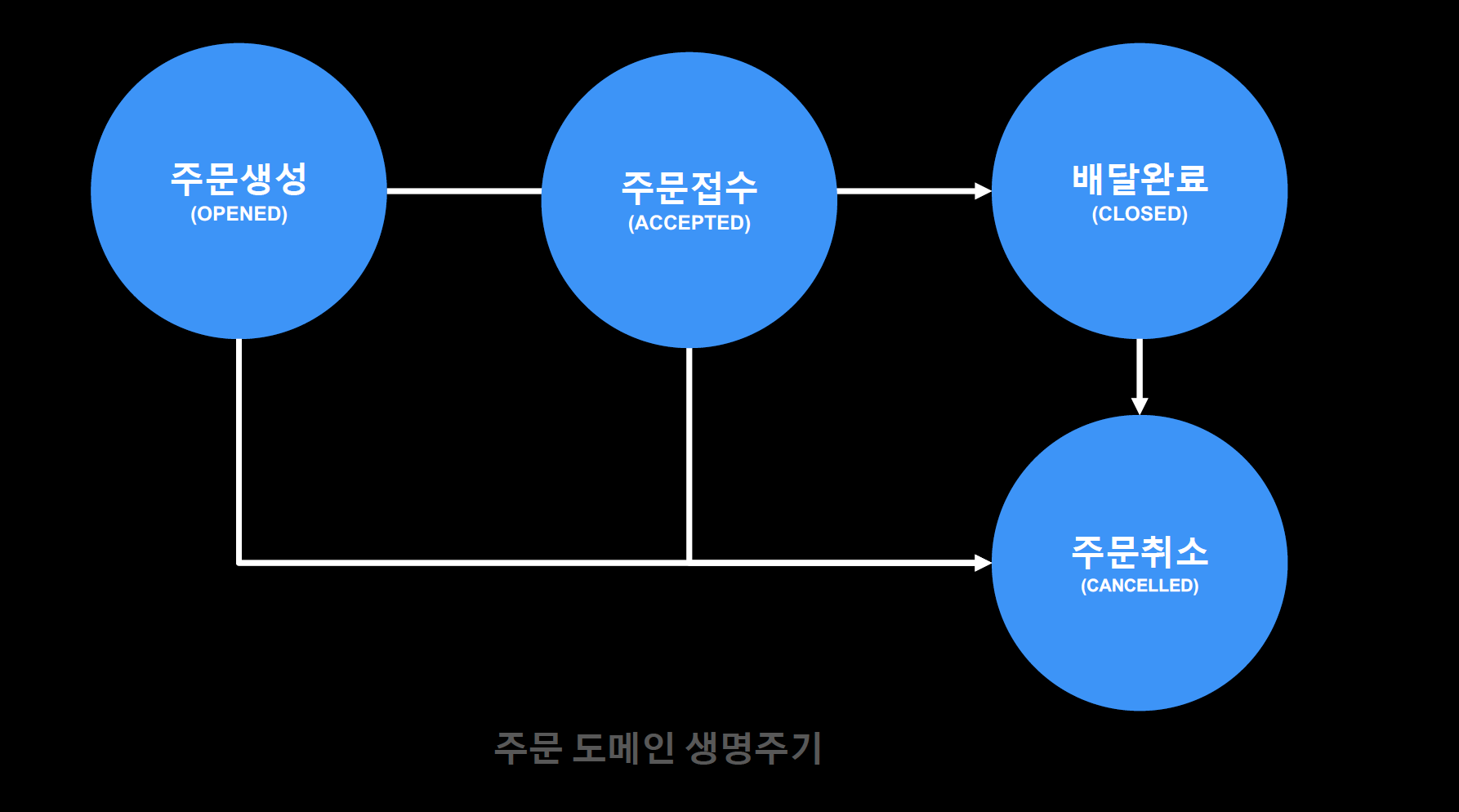
- 주문은 데이터가 변경될 때 위와 같은 주문 도메인 생명주기를 갖고있다.
- 중요한 건 주문 데이터는 이 생명주기 안에서만 도메인 변경이 발생한다.
데이터 동기화
- 주문 이벤트 처리기가 주문 도메인 생명주기 안에서 발생하는 도메인 이벤트를 수신하여 몽고DB에 저장하는 방식으로 데이터를 동기화했다.
CQRS 적용 아키텍처
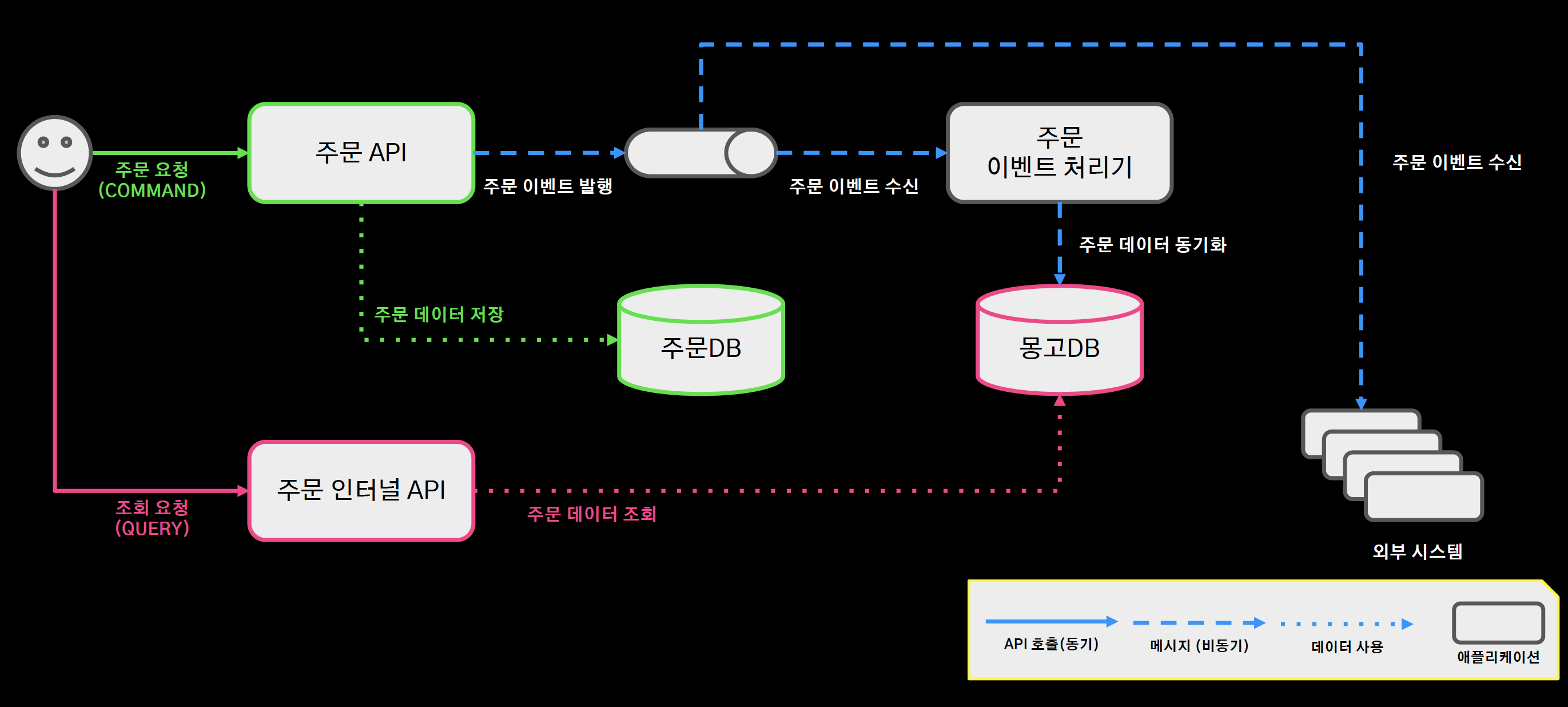
- 이 후 CQRS를 적용하여 조회 성능이 저하되는 트러블 슈팅을 극복함.
요약

3) 대규모 트랜잭션
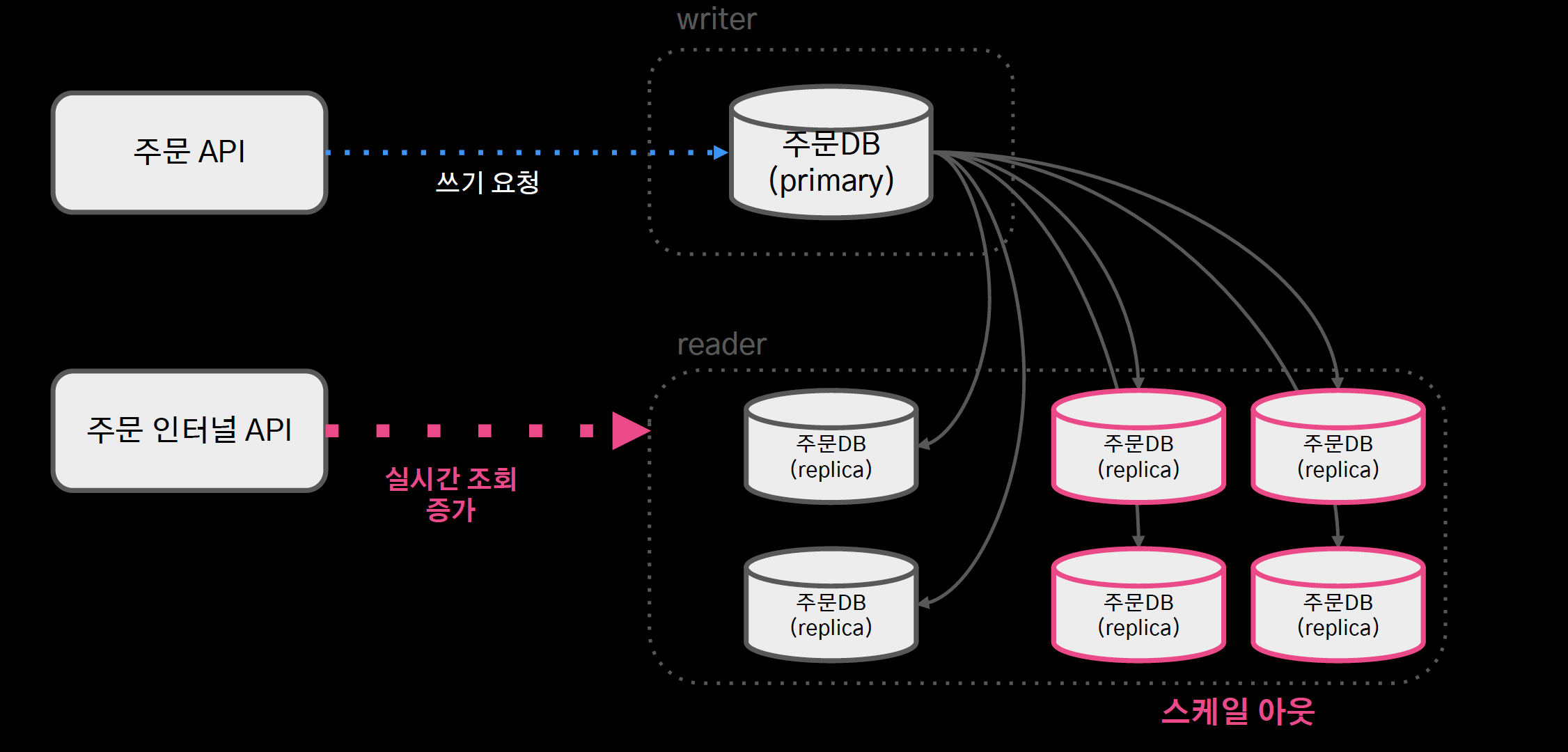
- primary 장비 1대, replica n대
- 실시간 조회 증가 시 레플리카를 스케일 아웃함으로 대응
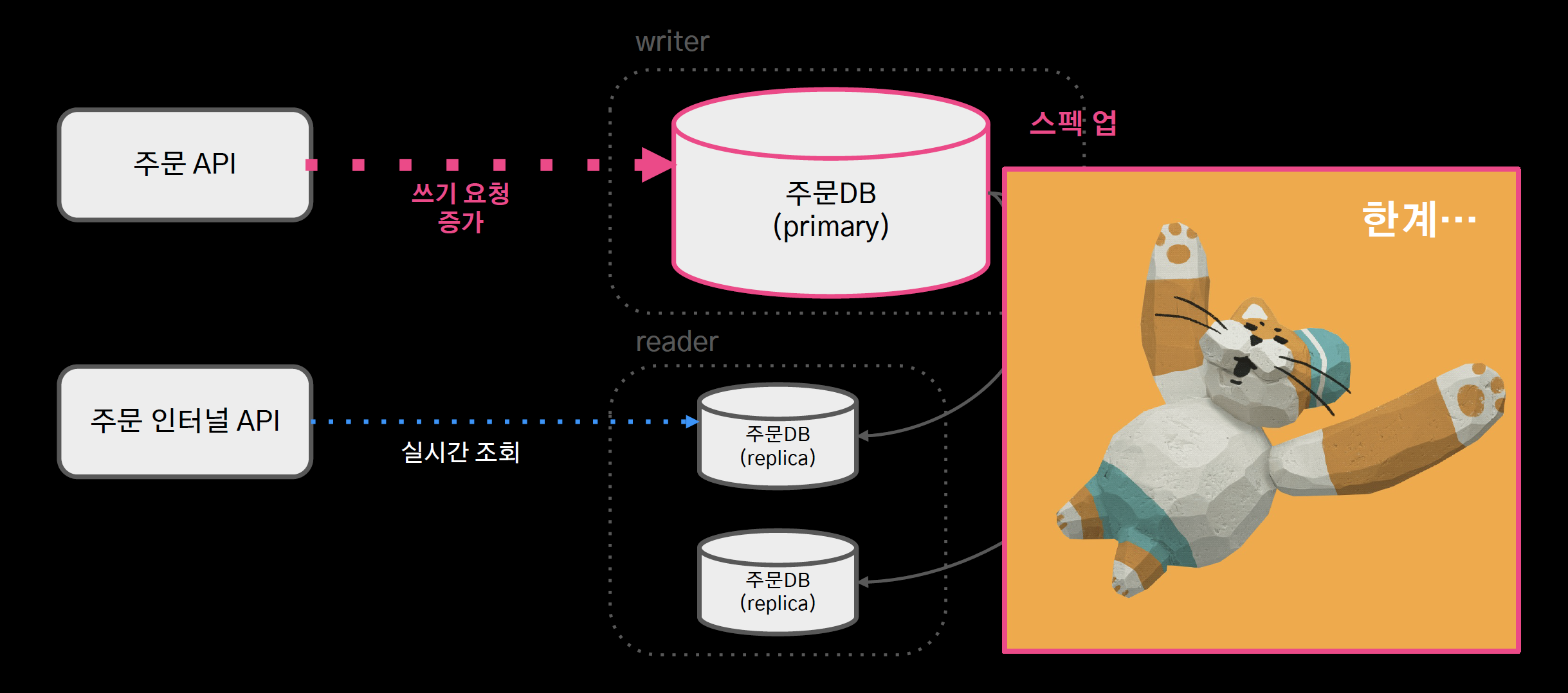
- 쓰기요청은 단일 장비를 사용하고 있어 스케일 업으로만 대응할 수 밖에 없었고, 이미 aws가 지원하는 스펙으로도 감당이 어려운 상황이 되었다.
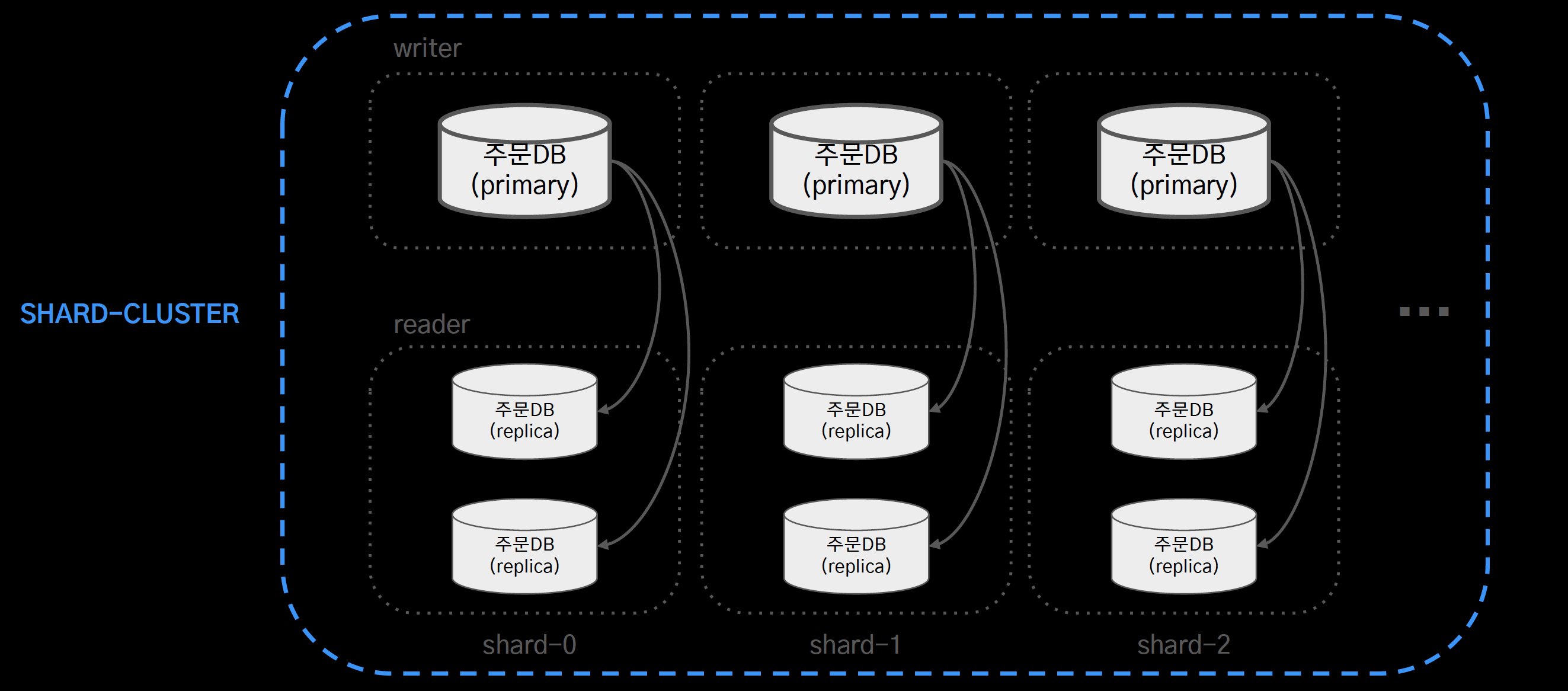
- 샤드 클러스터를 구성하여 쓰기 부하를 분산
- 하지만 AWS 오로라는 샤딩을 지원하지 않았다. 그래서 애플리케이션 레벨에서 샤딩을 직접 구현했다.

- 데이터를 저장할 때 어느 샤드에 접근할지 결정하는 샤딩 전략
- 분산된 저장 데이터를 순서대로 애그리게이트 하는 방법
샤딩 전략
1. Key Based Sharding (Hash Based Shading)
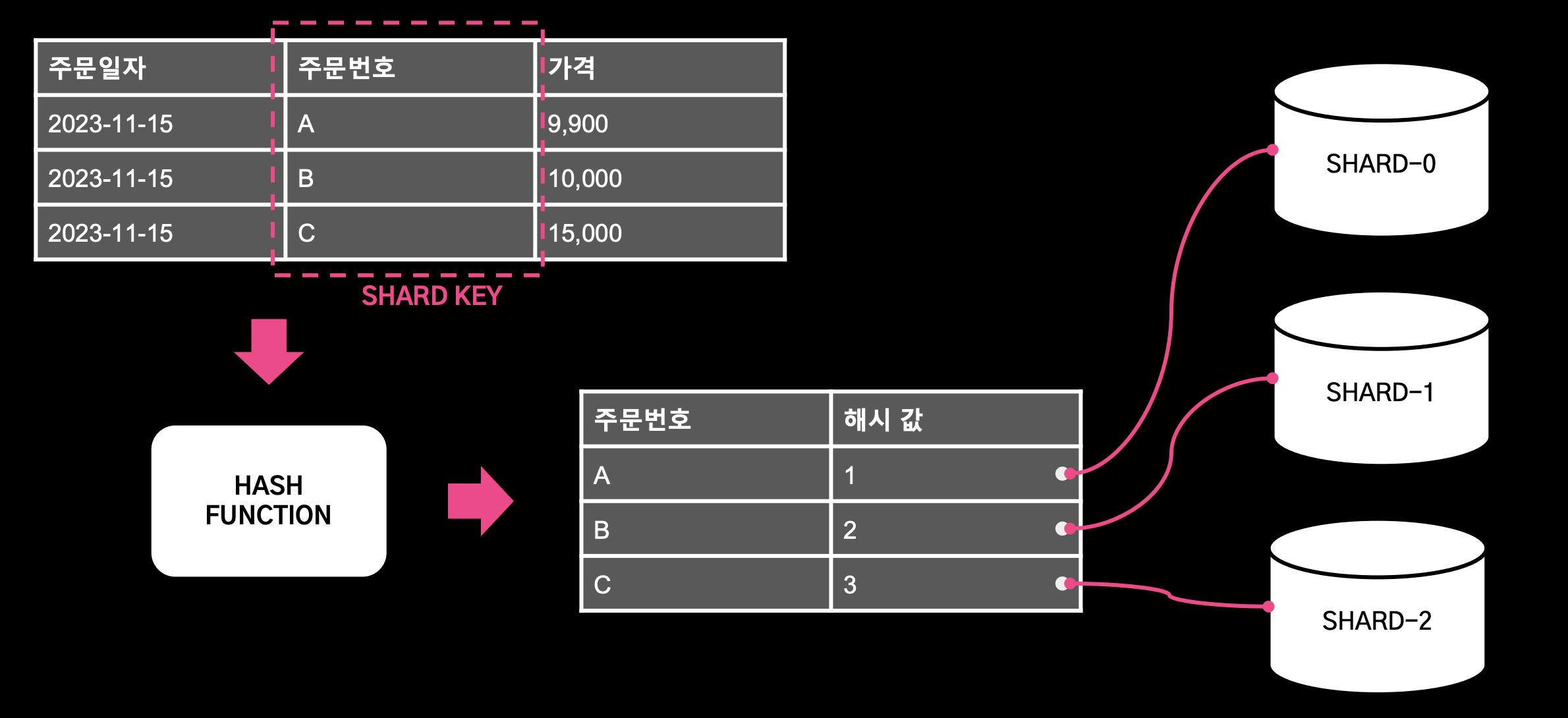
- 샤드 키가 해시 함수에 의해서 해시 키가 결정되고 이 키가 샤드를 결정한다.
- 장점: 구현이 간단하며, 샤드 클러스터 내 샤드들에 데이터를 골고루 분배할 수 있다.
- 단점: 장비를 동적으로 추가, 제거할 때 데이터 재배치가 필요하다
2. Range Based Sharding
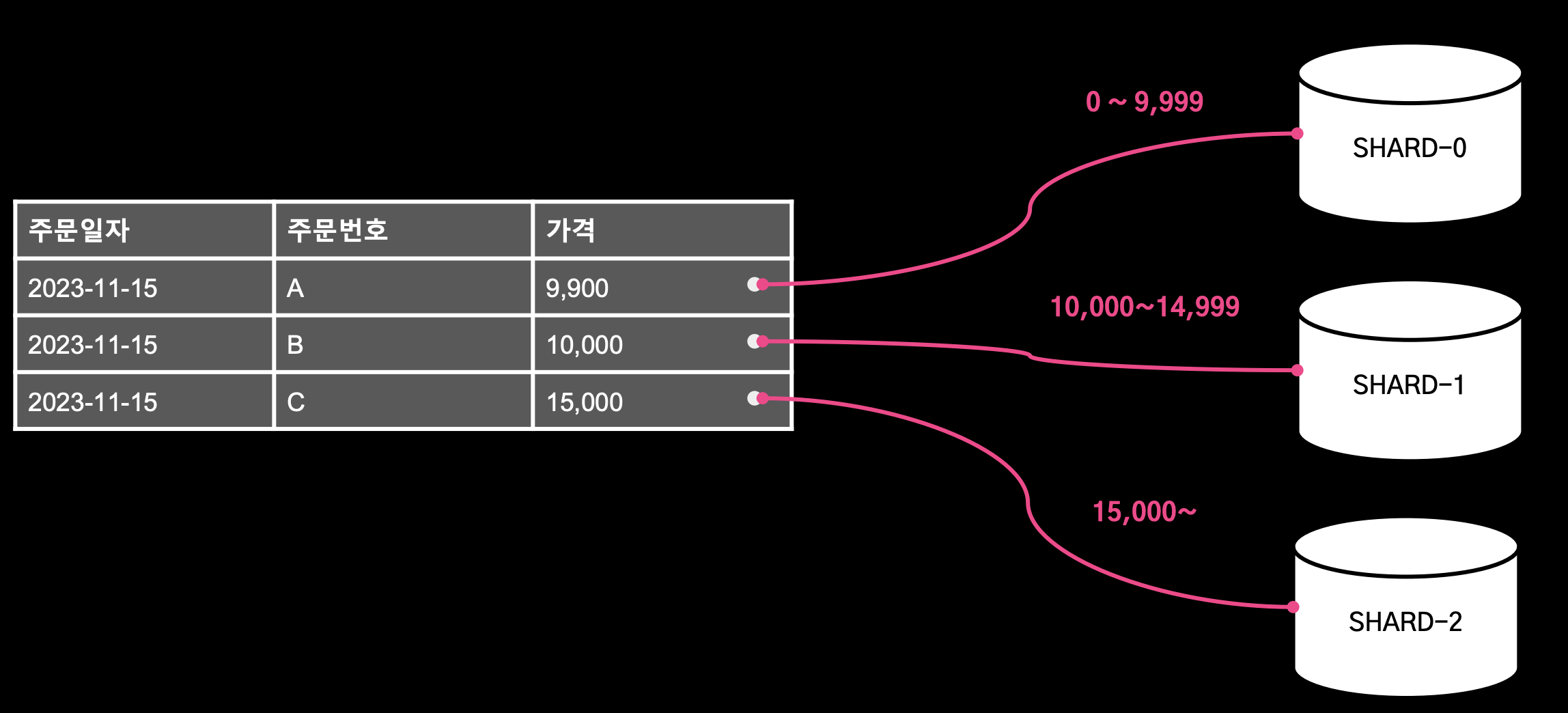
- 특정 필드의 레인지 값으로 샤드를 결정
- 장점: 특정 값의 범위 기반으로 샤드를 결정하면 되기 때문에 구현이 간단하다.
- 단점: 데이터가 균등하게 배분되지 않아 특정 샤드에 데이터가 물리면 HotSpot이 되어 성능 저하가 발생할 수 있다.
3. Directory Based Sharding
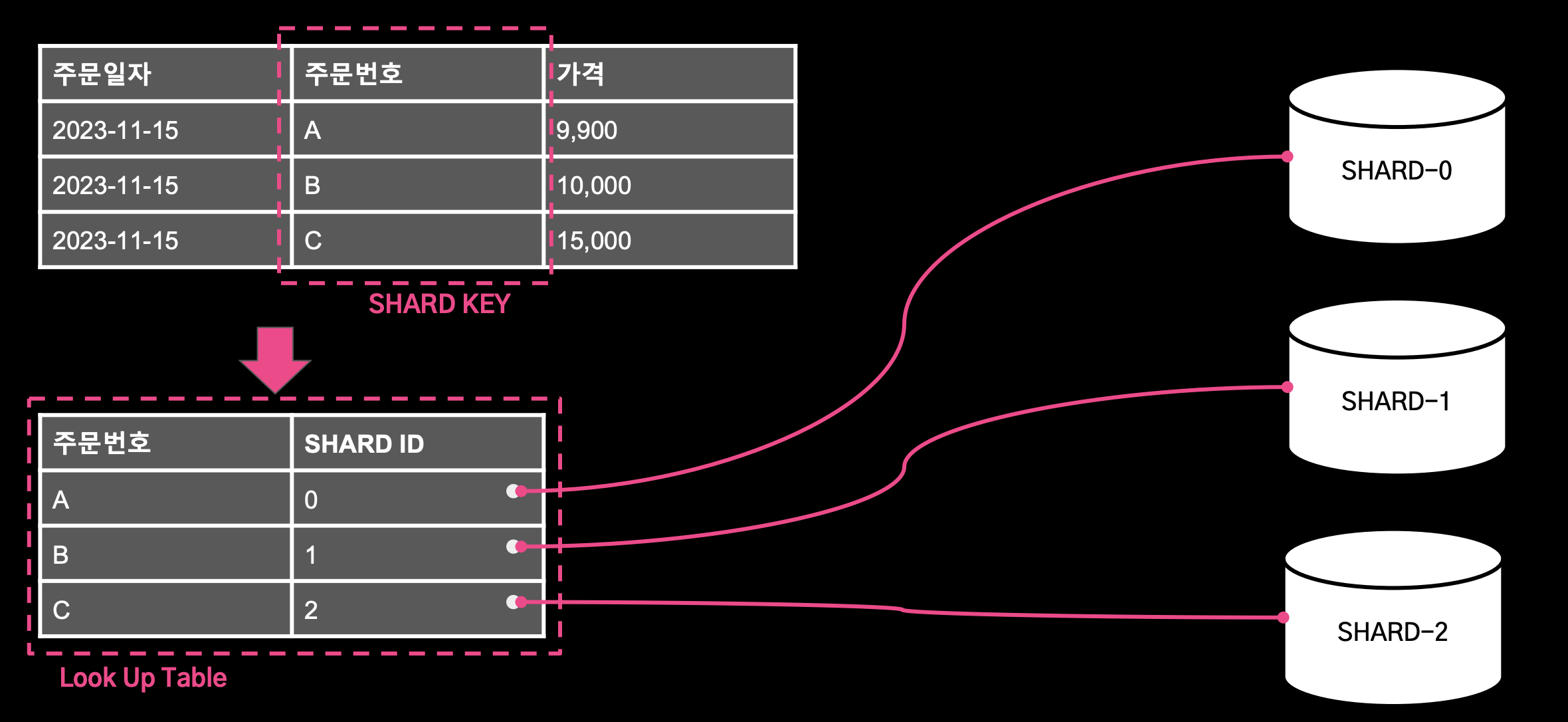
- 주문 번호화 Shard Id를 테이블에 저장하고 이 테이블을 기준으로 샤드를 선택한다.
- 장점: 샤드 결정 로직이 Look Up Table로 분리되어 있기 때문에 동적으로 샤드를 추가하는데 유리하다.
- 단점: Look Up Table이 단일 장애 포인트가 될 수 있다.
주문 시스템의 특징
- 주문이 정상 동작하지 않으면, 배민 서비스 전체의 좋지 않은 경험으로 이어진다. (주문 정상동작을 최우선) -> 단일 장애 포인트는 피한다.
- 동적 주문 데이터는 최대 30일만 저장한다. (30일이 지나면 더 이상 변경되지 않는 스냅샷 형태로 보관 된다.) -> 샤드 추가 이후 30일이 지나면 데이터는 다시 균등하게 분배 된다.
- 위의 사항을 고려해서 Key Based Sharding 방식으로 샤딩을 구현했다.
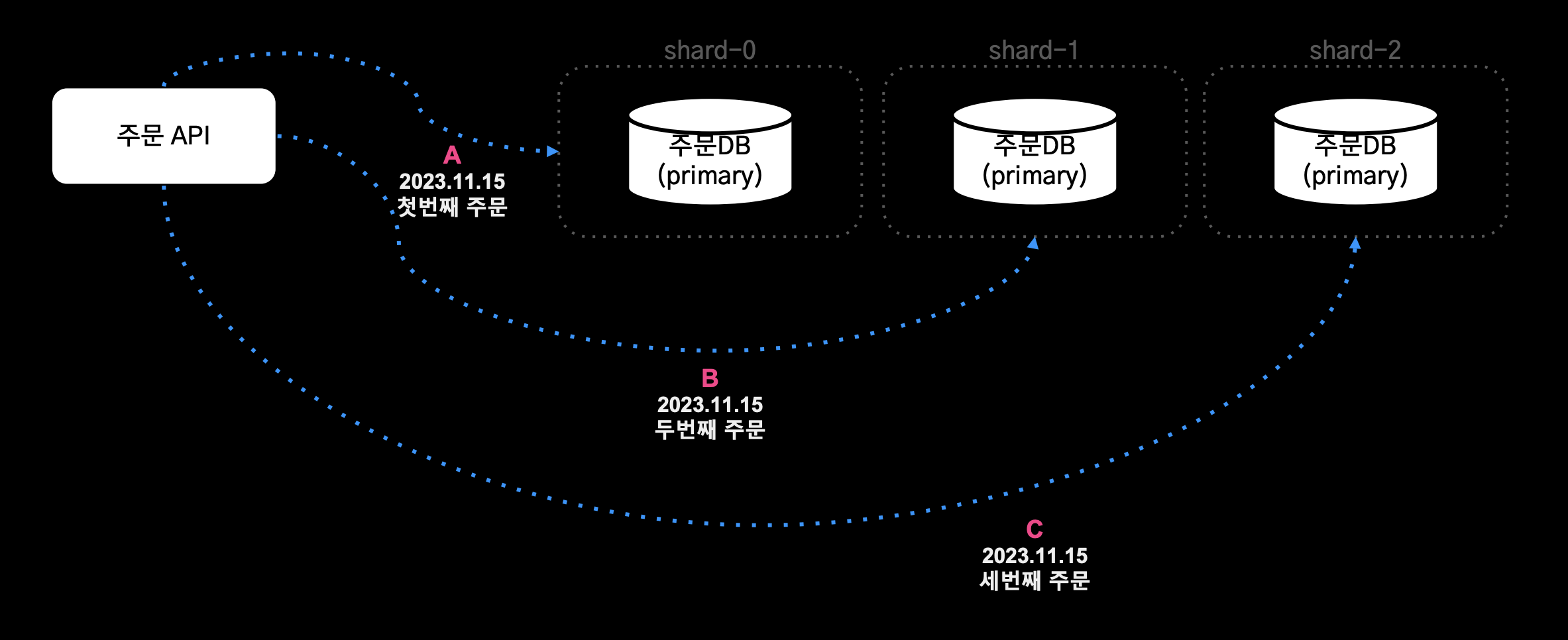
샤드 키

- 주문번호를 샤드키로 사용
B1MU00584X라는 주문번호에서 추출한 주문 순번 % 샤드 수의 Hash Function을 적용해서 샤드 번호를 구한다.
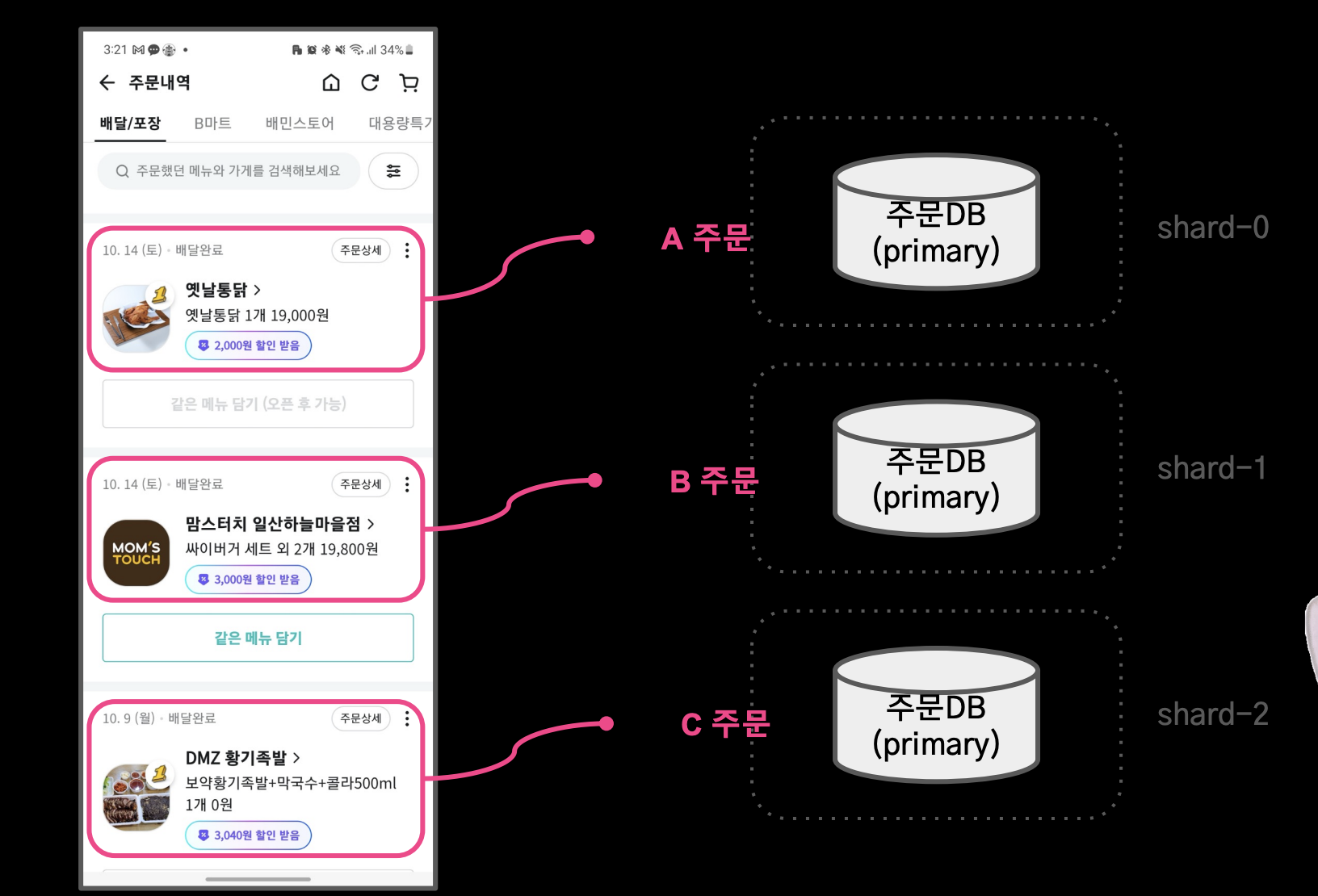
데이터 소스 결정
구현
- AOP와 AbstractRoutingDataSource를 이용하여 구현
AOP
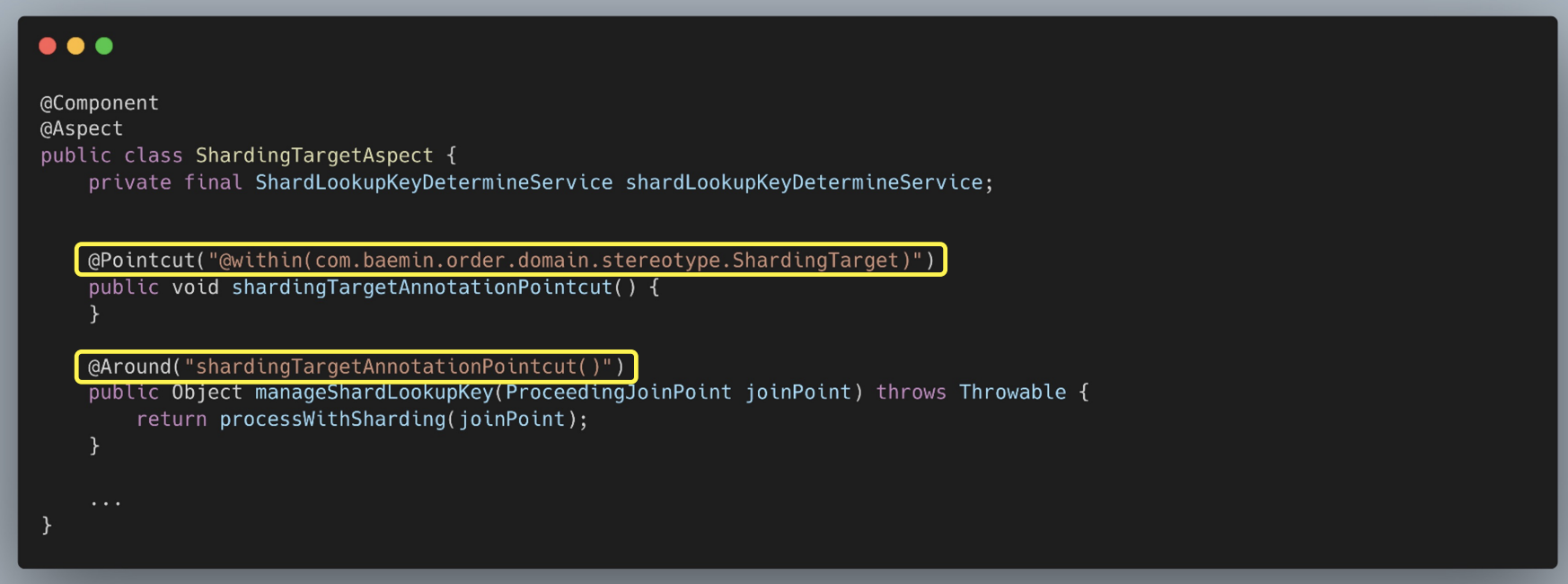
- Pointcut으로
@ShardingTarget이라는 어노테이션이 붙은 메서드를 가져오고 Advice 메서드에서 processWithSharding() 메서드를 수행한다.
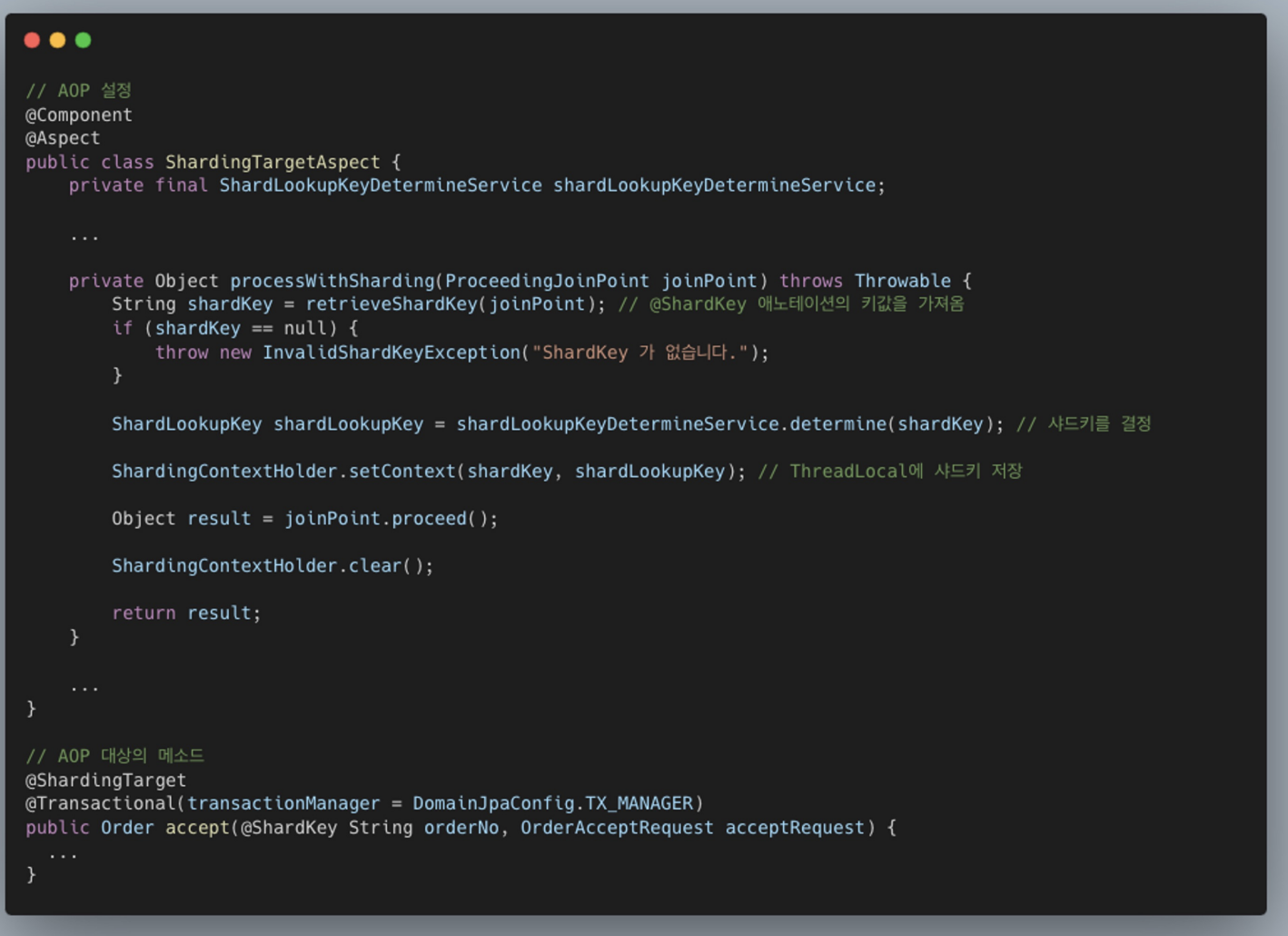
processWithSharding()메서드에서는@ShardKey어노테이션이 붙은 인자를 가져와 샤드키를 결정하고 ThreadLocal에 샤드키를 저장한다.
AbstractRoutingDataSource
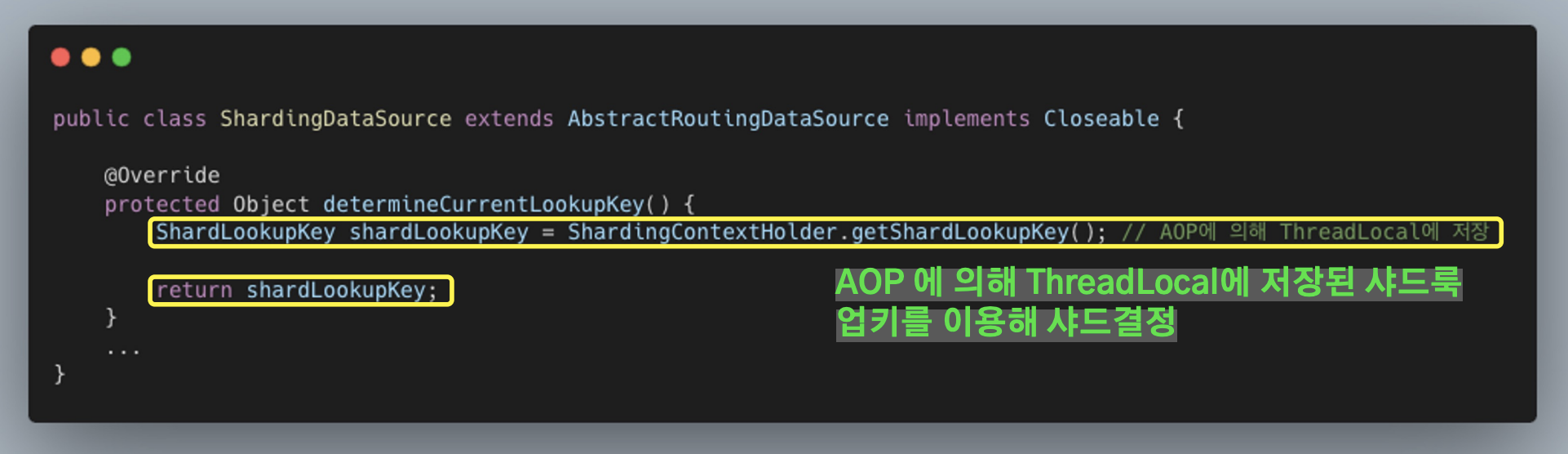
- determineCurrentLookupKey를 오버라이딩하고 ThreadLocal에 저장된 샤드 룩업 키를 이용하여 해당하는 샤드의 데이터 소스를 선택한다.
다건 조회시 데이터 애그리게이트
- N개의 샤드에 분산 저장된 데이터를 어떻게 조합하여 내려줄지 고민했다.
조회 모델
- 위에서 고민한 이슈는 이미 CQRS 패턴을 적용함으로써 해결이 되었다.
- 데이터의 조회는 Query 전용 MongoDB에 저장된 값으로 해결
쓰기 요청 증가 스케일 아웃 대응
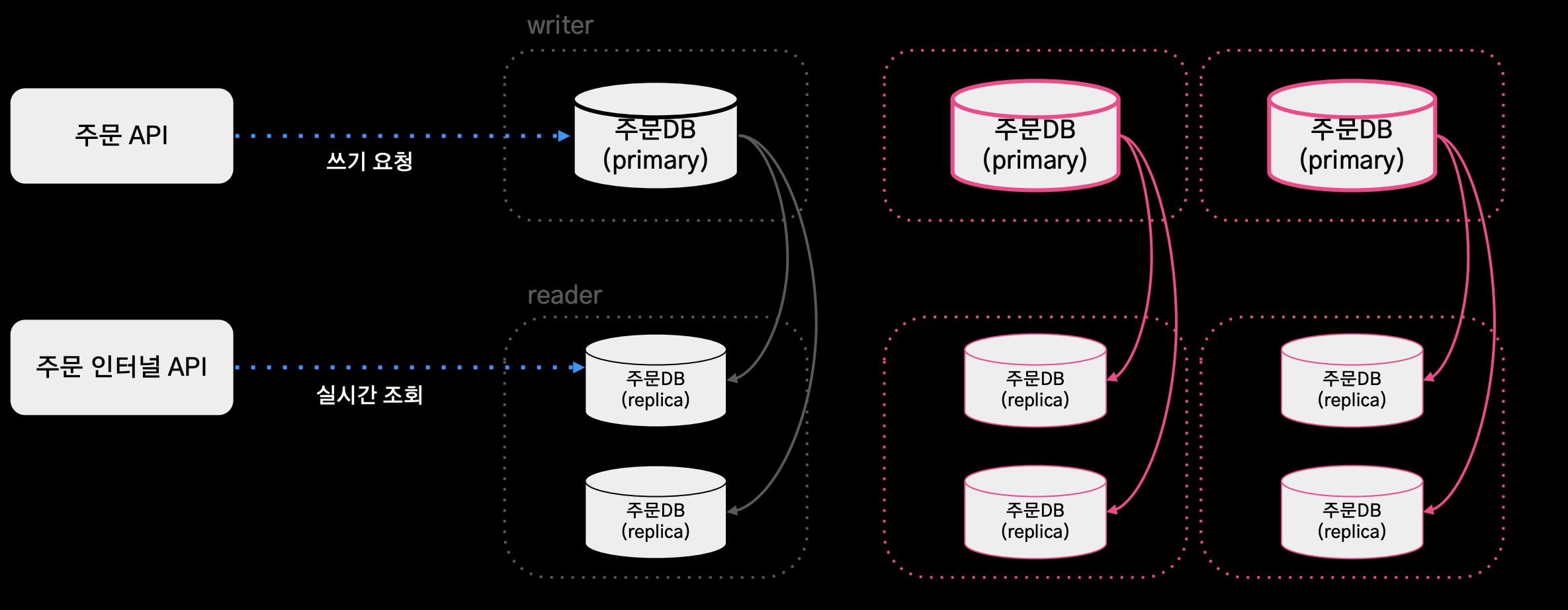
- 이로써 샤딩으로 인해 증가하는 트랜잭션을 스케일 아웃으로 대응이 가능해졌다.
- 아직까지는 요청량이 갑자기 증가할 때에는 샤드를 추가하지는 않고, 고정된 샤드의 값에서 Scale Up하는 방식으로 대응하고 있음
요약

4) 복잡한 이벤트 아키텍처
이벤트 기반의 관심사 분리
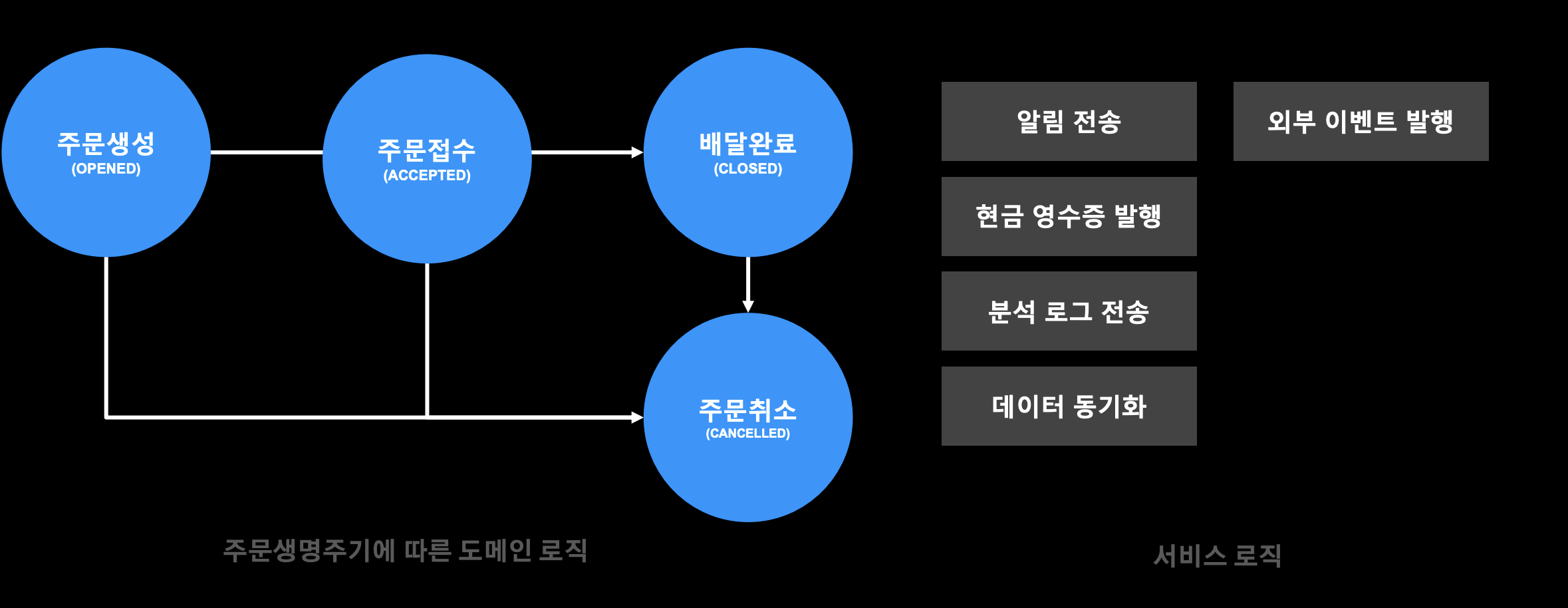
- 주문 도메인 로직과 서비스 로직을 이벤트를 기반으로 관심사를 분리하고 있다.
- 주문 도메인 안에서 이루어지는 주문 도메인 로직과 그 외 기타 서비스 로직을 이벤트 기반으로 경계를 두고 격리해서 처리하고 있다.
주문시스템 이벤트 아키텍처
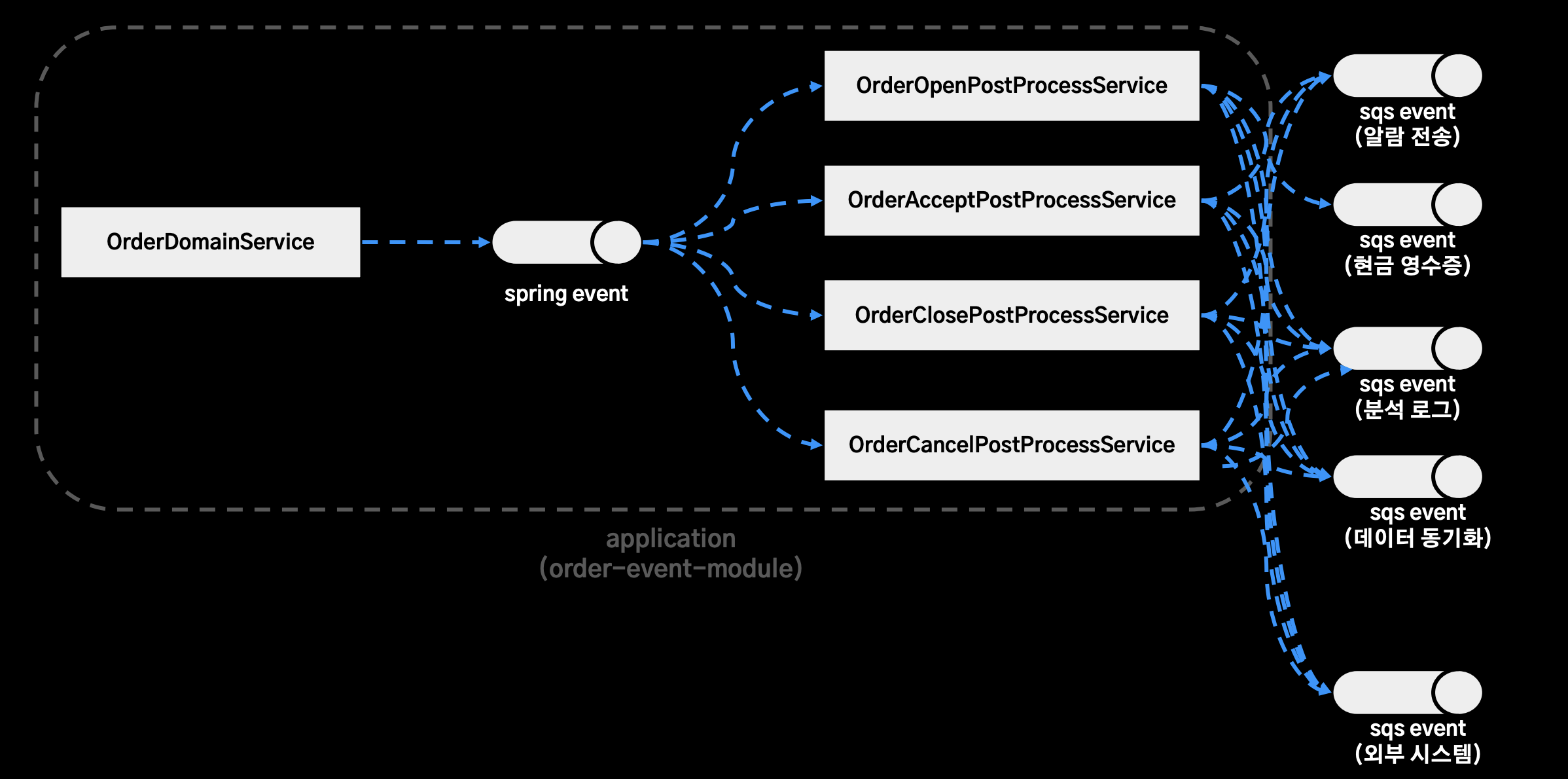
- order-event-module이라는 모듈 안 구조
OrderDomainService: 주문 도메인의 생명주기의 도메인 로직을 수행하고, Spring Event로 생성, 접수, 완료, 취소에 해당하는 이벤트를 발행OrderXXXProcessService: Application Event를 구독해서 서비스 로직을 수행하는 구조- 스프링 어플리케이션 큐를 이용해서 도메인 로직과 서비스 로직이 분리되어 있는 것처럼 보인다.
시스템 관점 아키텍처
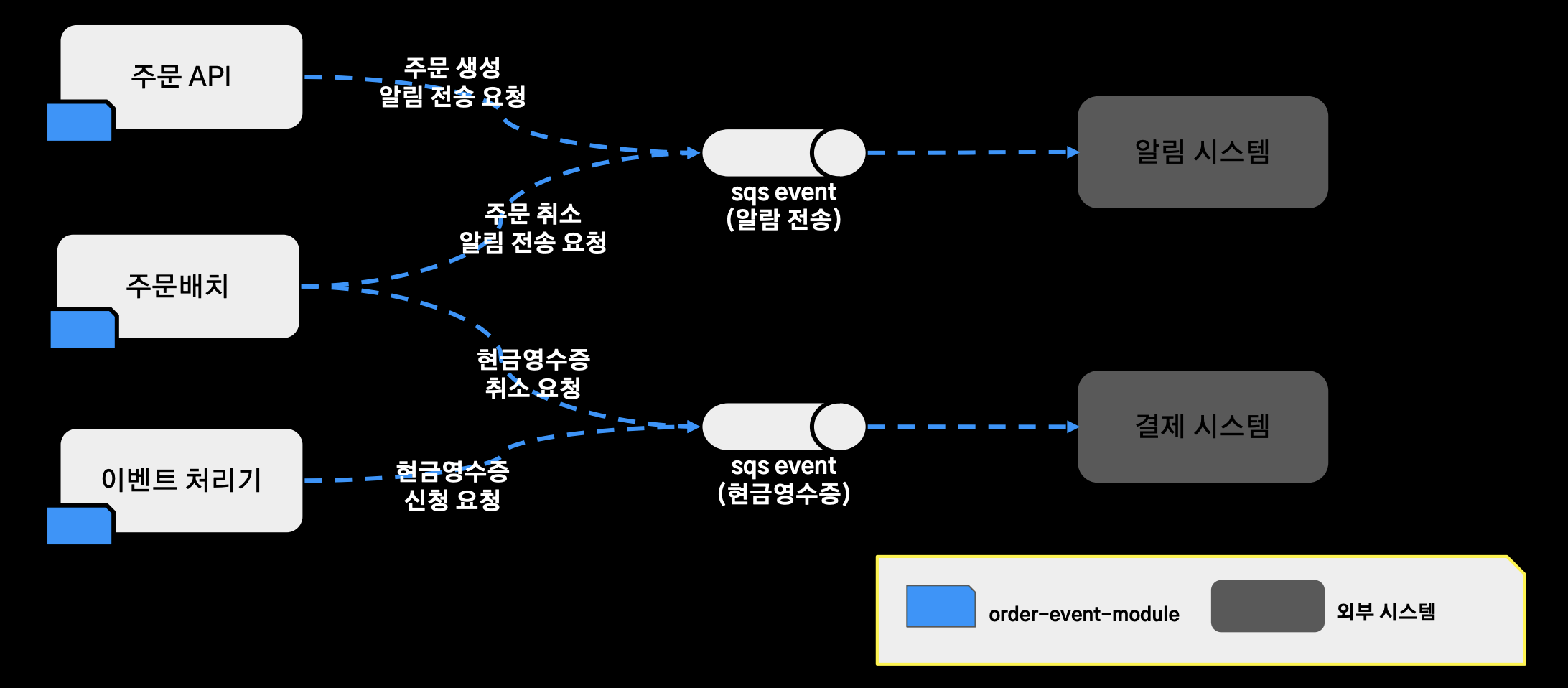
문제점1 (로직을 수행하는 주체를 파악하기 어렵다)
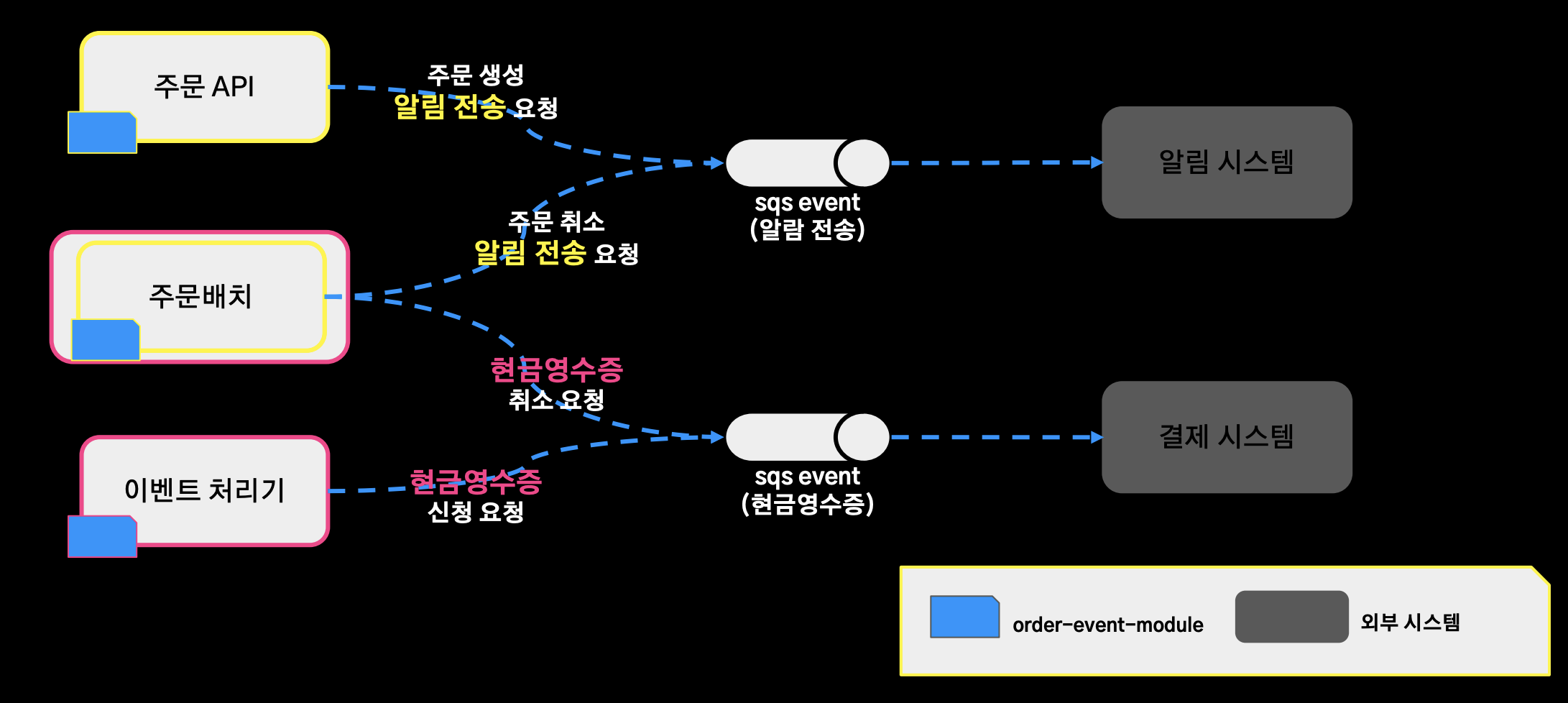
- 로직을 수행하는 주체를 파악하기 어렵다.
- 주문 API와 주문 배치가 각각 주문 생성 알림 전송 요청 서비스 주문 취소 알림 전송 로직을 수행하고, 주문배치와 이벤트 처리기가 각각 현금영수증 취소 요청, 현금 영수증 신청 신청 요청을 처리하고 있다.
- 이렇게 서비스 로직을 수행하는 어플리케이션이 달라지게 됨으로써 이걸 파악하는데 점점 더 어려워졌고, 기능을 추가할 경우 특정 이벤트를 처리하는 서버에는 추가하지 않는 이슈가 존재했다.
문제점2 (이벤트 유실이 발생할 경우 재처리가 어렵다)
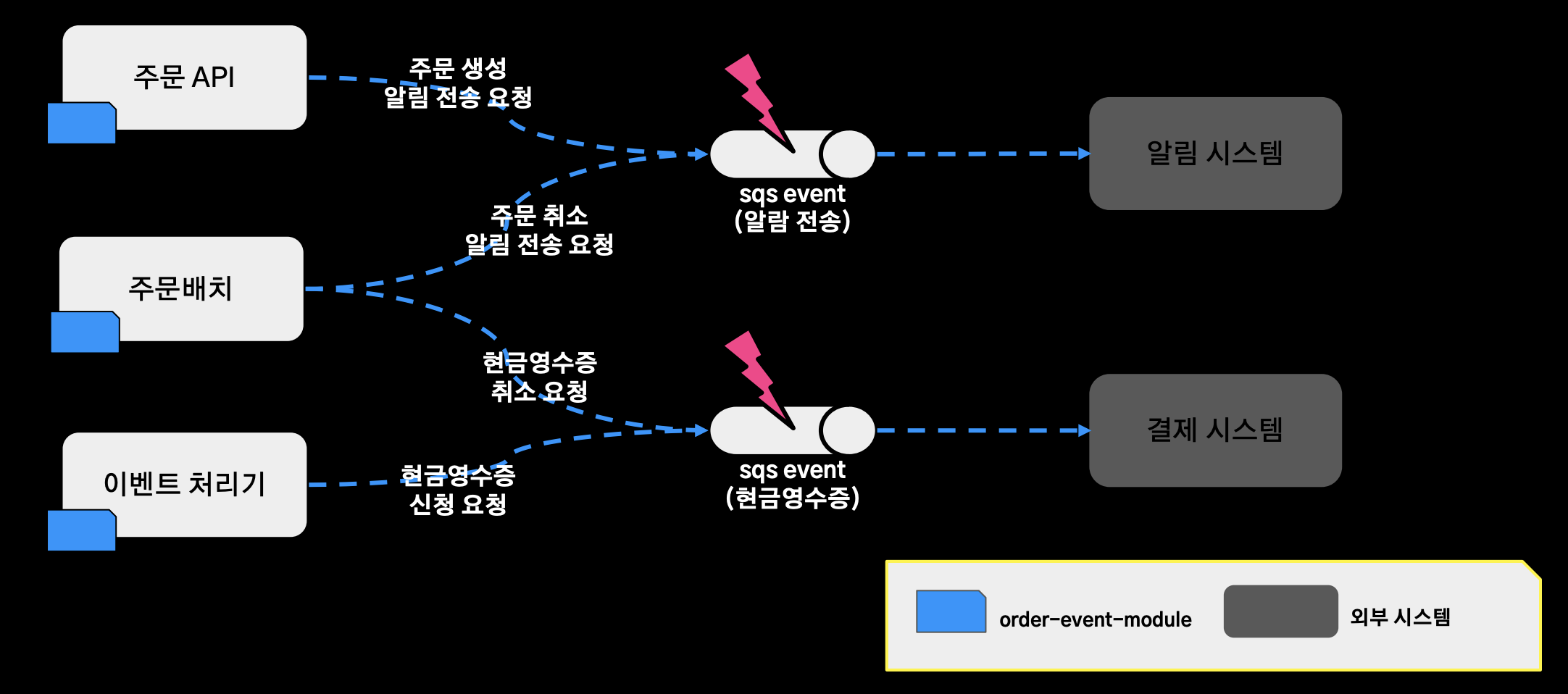
- 이벤트 유실이 발생할 경우 재처리가 어렵다.
- 가령 알림 전송을 하기 위해 알림 시스템에 메시지를 보내기 위해 sqs에 문제가 발생하게 되면, 도메인 로직에 대한 어플리케이션 이벤트를 재발행할 수단이 없었다.
내부 / 외부 이벤트 정리
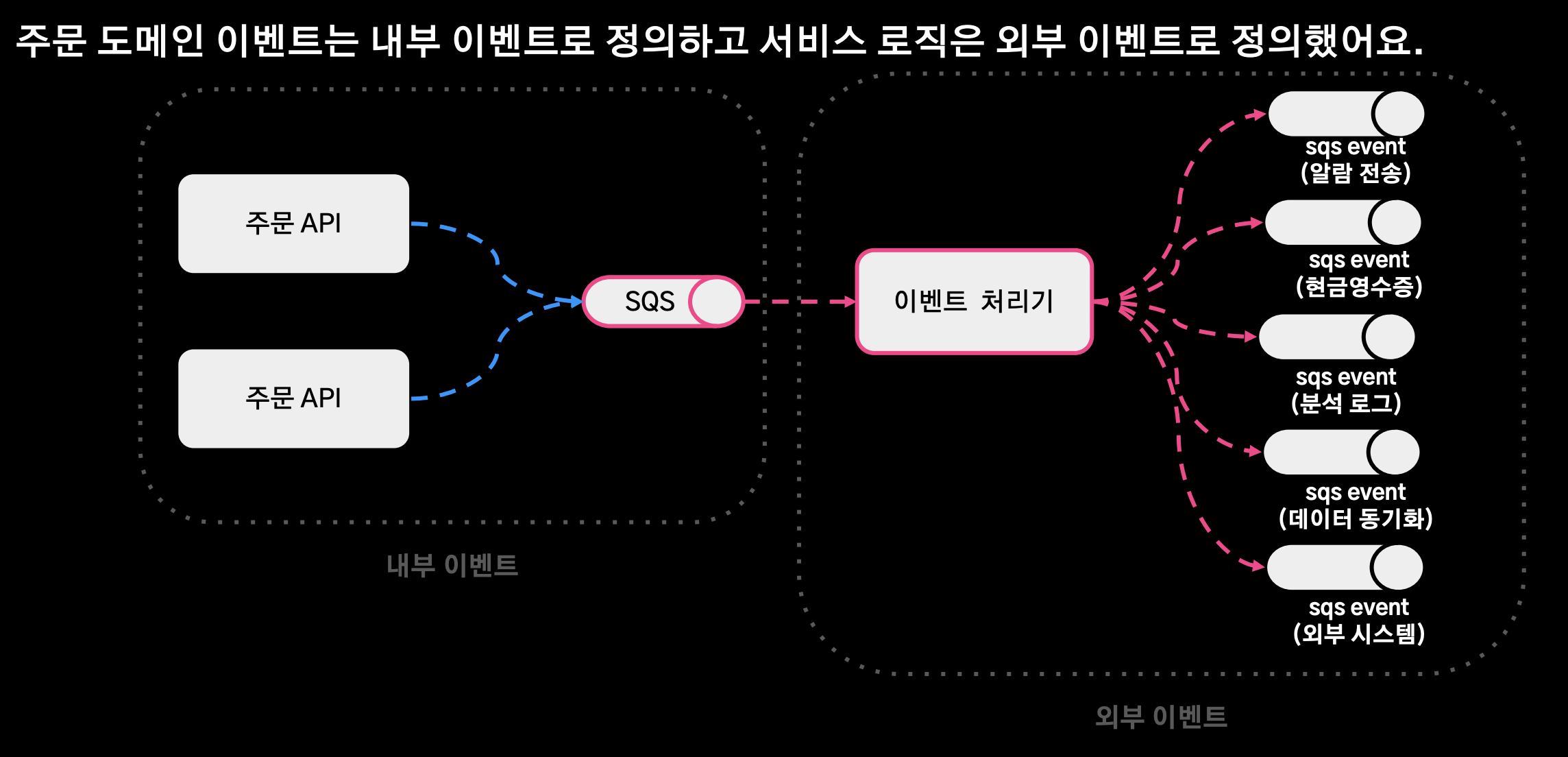
- 주문 도메인 이벤트는 내부 이벤트로 정의하고 서비스 로직은 외부 이벤트로 정의했다.
- 내부 이벤트는 Spring Event 대신 SQS를 사용했고, 이 SQS를 구독하는 이벤트 처리기가 도메인 이벤트를 수신해서 외부 이벤트를 수행하게 아키텍처를 변경했다.
ZERO Payload
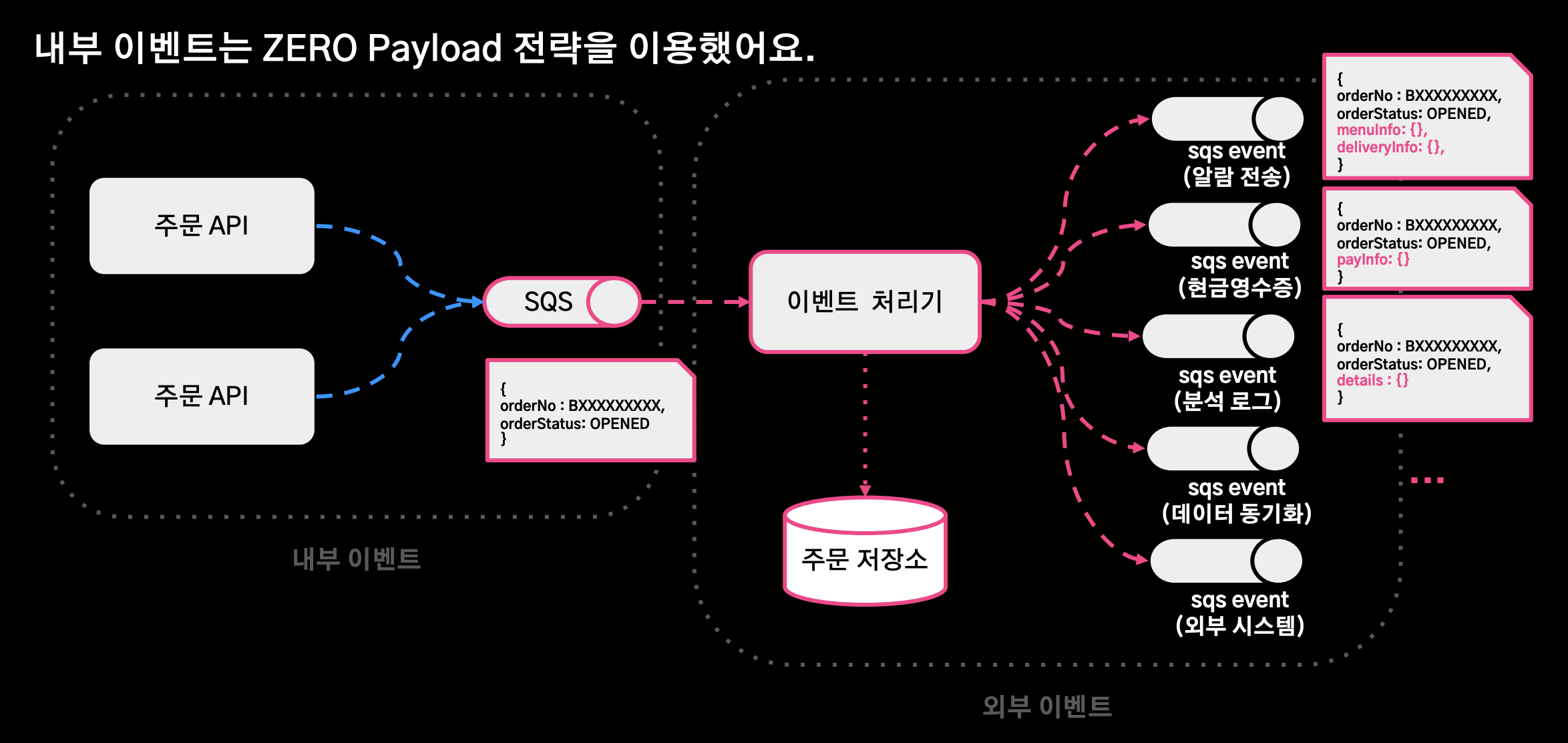
- 내부 이벤트는 Zero Payload 전략을 이용했다.
- 내부 이벤트에 외부 서비스 로직을 적용하기 어렵게 하기 위함.
- 내부 이벤트는 주문에 관련된 도메인 로직만을 수행하고, 이 도메인 이벤트를 수신한 이벤트 처리기에서 각각의 서비스 로직에 필요한 데이터를 조회할 수 있게 처리.
이벤트 처리 주체의 단일화
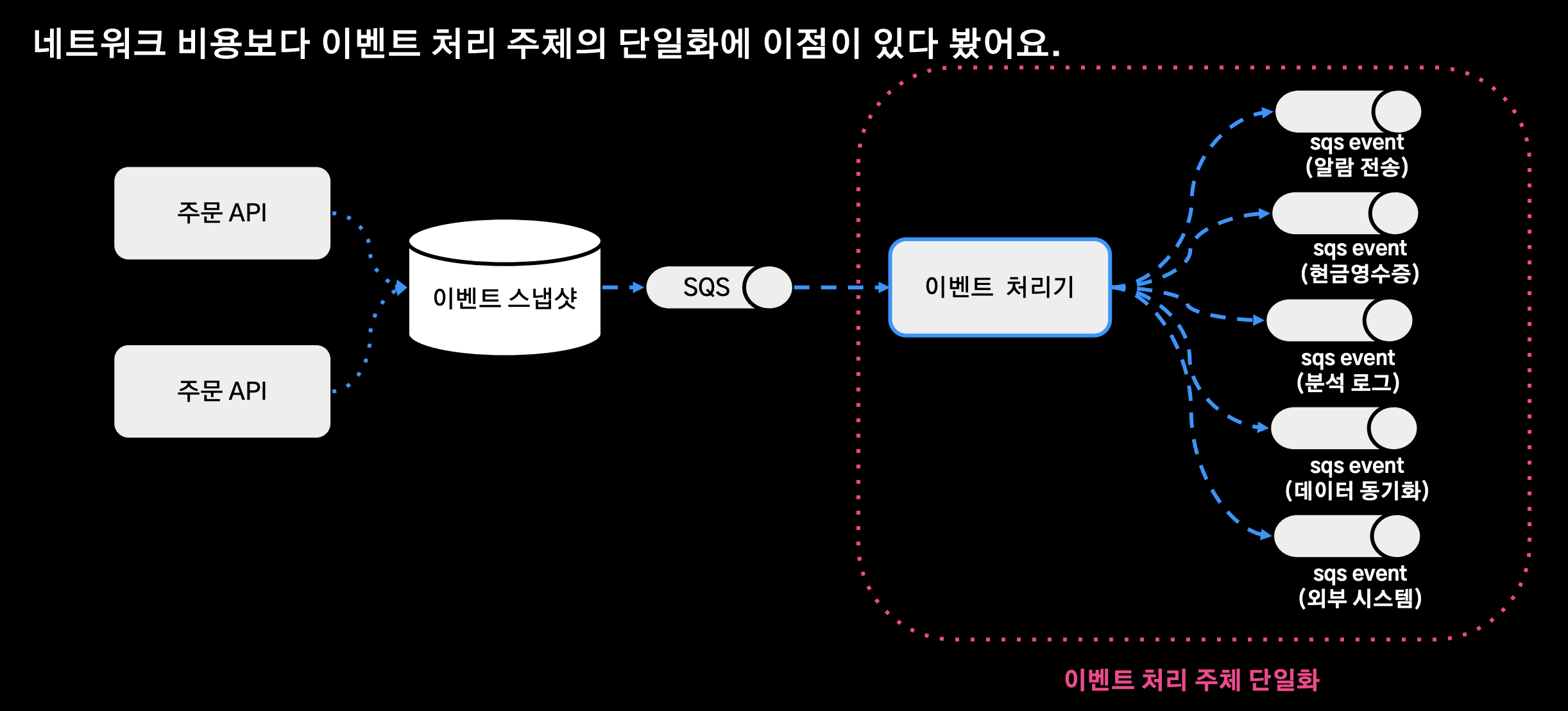
- 이벤트 처리 주체를 위와 같이 단일화 시켰다. 네트워크 비용보다 이벤트 처리 주체의 단일화에 이점이 있다고 생각해서 위와 같이 적용
이벤트 발행 실패 유형
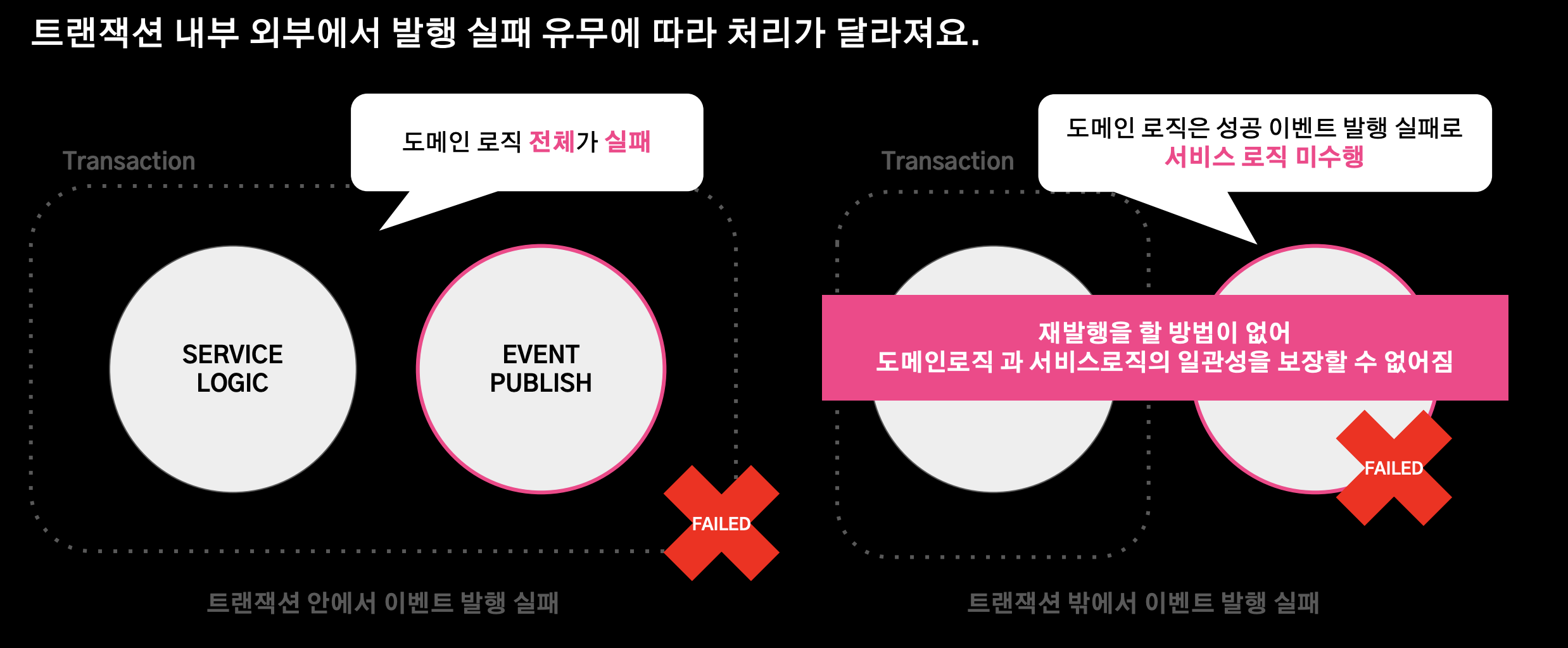
- 트랜잭션 내부/외부에서 발행 실패 유무에 따라 처리가 달라진다. 트랜잭션 외부에서 실패 시 도메인 로직은 성공 이벤트를 발행하고 서비스 로직을 미수행한다. 이 경우 재발행을 할 방법이 없어 도메인 로직과 서비스 로직의 일관성을 보장할 방법이 없다.
트랜잭션 아웃박스 패턴
- 이벤트 발행 실패와 서비스 실패를 격리하여 재발행 수단을 보장한다.
- 도메인 로직과 Outbox 엔티티에 이벤트 데이터 페이로드를 insert하는 로직을 하나의 트랜잭션으로 정의했다.- 이벤트 발행 실패 시에도 아웃박스 엔티티를 통해서 재발행이 가능하게 설계했다.
트랜잭션 커밋 성공
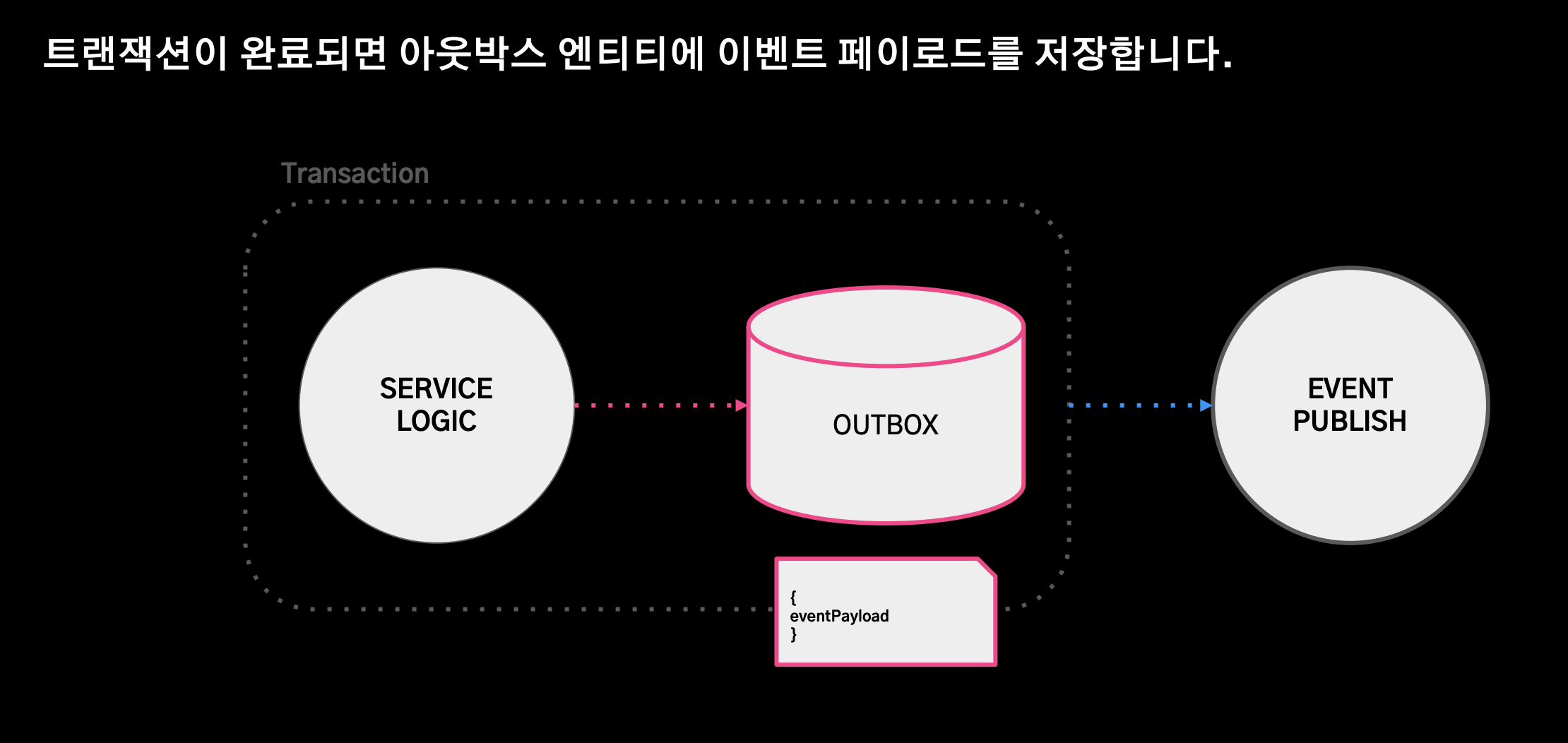
- 트랜잭션이 완료되면 아웃박스 엔티티에 이벤트 페이로드를 저장한다.
트랜잭션 커밋 실패
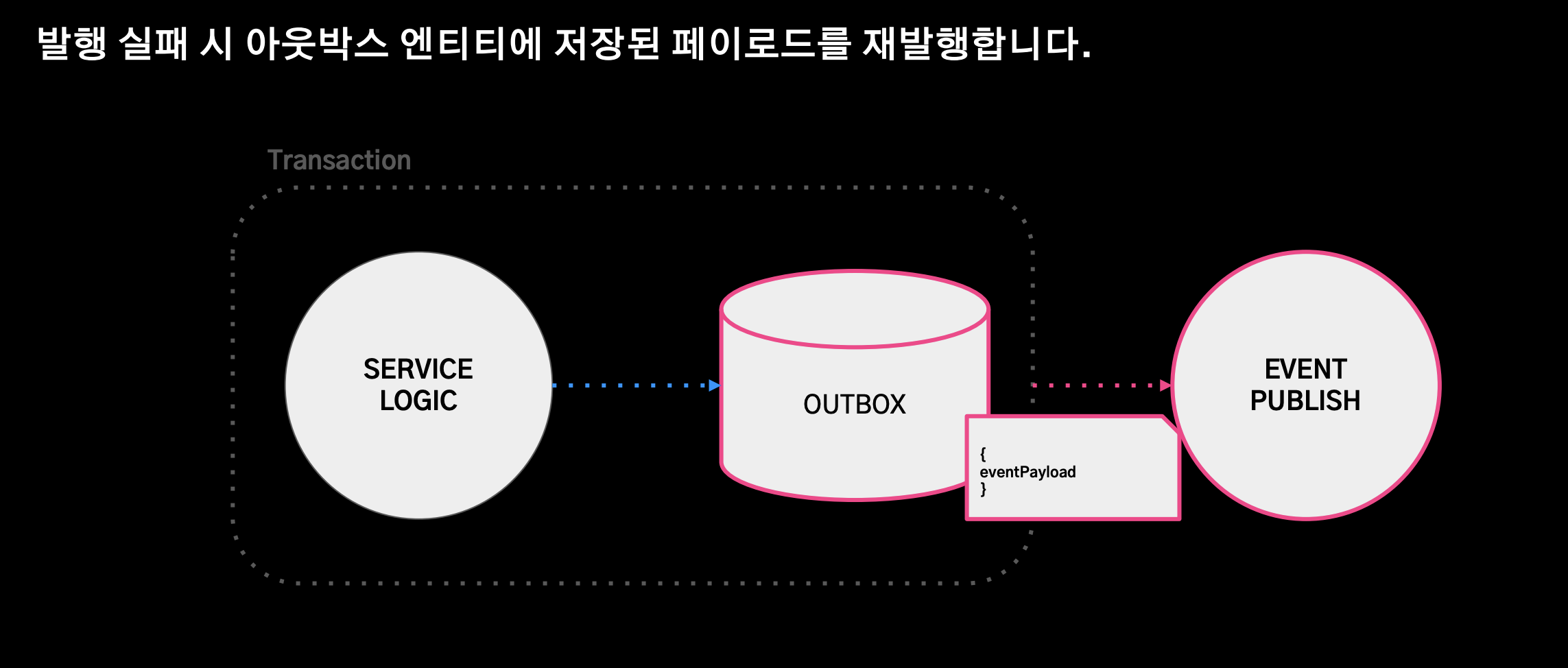
- 발행 실패 시 아웃박스 엔티티에 저장된 페이로드를 재발행한다.
최종 아키텍처
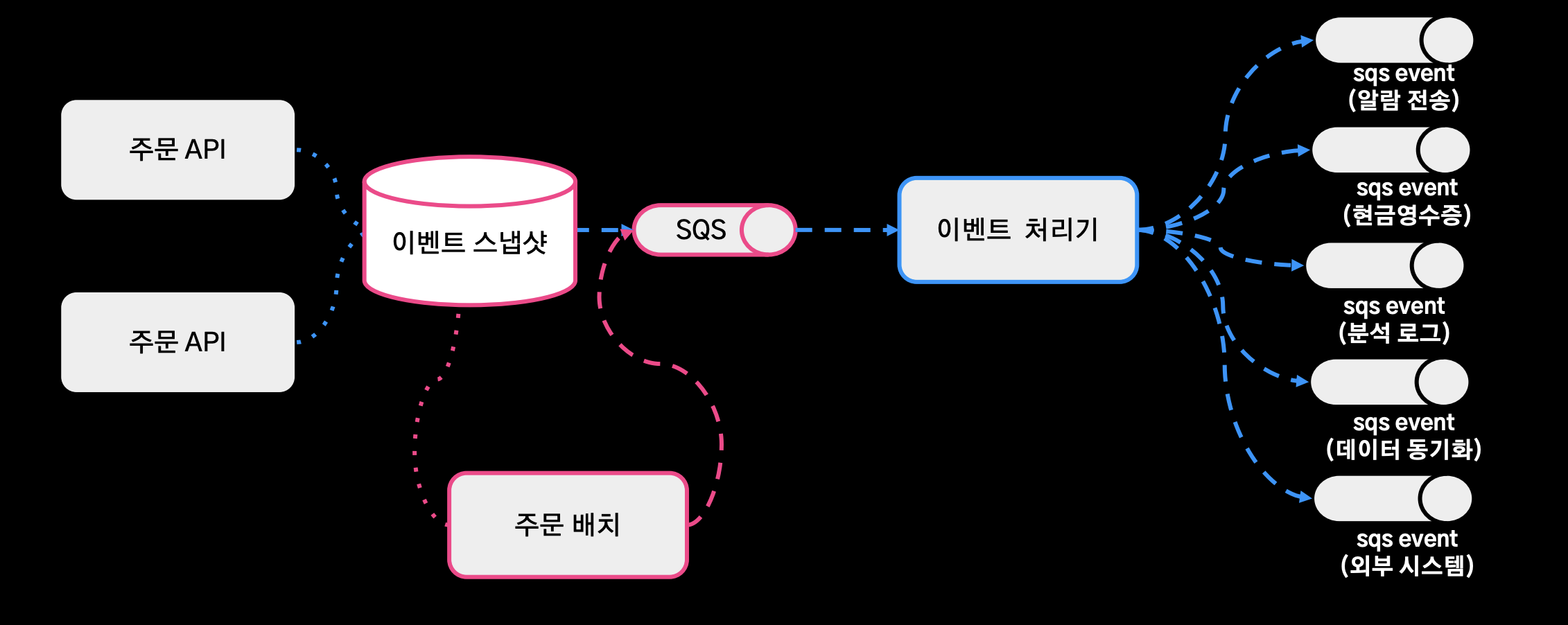
- 중복 발행은 될 수 있지만 유실은 되지 않게 설계를 하게 됨.
- 중복 발행에 대한 처리는 Subscriber 쪽에서 키 값을 기준으로 중복이 발생했을 경우에 해당 이벤트를 스킵하는 방식으로 멱등성을 보장했다.
요약

3. Q&A
- Q. 대규모 트래픽의 경우 사업의 특징마다 다르겠지만 웹플럭스 같은 리액티브 프로그래밍으로 충분한지 아니면 지금의 MVC 모델로도 가능한지 궁금하다.
- A. 도메인 특성상 다른 것 같다. 주문 도메인 특성상 데이터의 정합성이 중요하기 때문에, RDB를 주로 사용해야 하는 서비스였고 WebFlux를 사용한다해도 저장소가 병목이 되어 이점을 가져가기 어렵다. 하지만 가게 노출 서비스 같은 경우에는 데이터의 정합성 보다는 데이터들을 잘 캐싱해서 조회하는 것에 특화된 도메인이라 이럴 경우에는 스레드를 효율적으로 관리할 수 있는 WebFlux가 더 효율적인 방식일 것이다.
- Q. 매일마다 주문이 대규모로 들어오는 시간이 있을 것 같은데, 피크 시간대 인프라 또는 리소스 자원을 어떻게 관리하는 지 궁금하다.
- A. 12시, 6시에 트래픽이 몰리는 경향이 있어 AWS의 AutoScaling 자동 스케줄링 정책을 사용하고 있다. 새벽 시간에는 인스턴스 수를 줄이고 주문이 몰리는 시간에는 충분한 인스턴스를 확보해서 피크 시간 대비 3배의 가용 수준을 유지하고 있다.
- Q. 주문 아키텍처를 리디자인할 때의 사이드 이펙트들이 발생할지 알기 어려웠을텐데 어떻게 큰 리스크를 이겨냈는지 궁금하다.
- A. 2가지 방법이 있는데 AB 테스트를 이용한 점진적 배포, 배포 없이 빠르게 스위칭이 가능한 토글을 적용했다.
- 점유율이 낮은 지역부터 점진적으로 배포한 이후 점진적으로 지역을 늘려나가거나, 레거시 로직으로 빠르게 스위칭이 가능한 토글을 사용
- Q. 운영되고 있는 서비스에 스토리지에 대한 의존성도 같이 걷어내기 쉽지 않았을텐데 어떤 부분들을 고려해서 개선했나?
- A. 탈루비: 중앙집중DB -> 각 시스템. 데이터모델링도 같이 새로 진행이 된 작업이라 이전 데이터를 새로운 구조의 데이터로 마이그레이션 하는 과정을 거쳤다.
- 주문 DB 샤딩: 한 대의 장비의 데이터를 N대의 장비에 분산해서 저장하는 작업. 샤드키에 일자 조건을 넣어서 특정 일자 이후에는 데이터가 분산되어 저장되도록 하는 로직을 구현했음.
- 특정 일자의 이후에 로직이 동작하는 방식으로 무중단 서비스 배포를 진행했다.
- Q. 주문은 백엔드단에서 수행되는 로직이 매우 많을 텐데, 만약 로직이 트랜잭션 단위로 묶여 있다면(상품, 쿠폰 재고와 같은 다른 msa를 호출하는 단위 등), 각 트랜잭션 별로 에러가 발생할 때 어떻게 처리하는지 궁금하다.
- A. 도메인 별로 트랜잭션 단위의 정합성을 보장하고 있고, 이후의 과정에서는 대사 시스템을 통해 보정하고 있다. 트랜잭션을 시스템 별로 묶기에는 조금 어려운 점이 있었다. 예를 들어 특정 주문이 카드와 쿠폰의 복합 결제로 이뤄졌다면, 결제 시스템도 마찬가지로 카드 쿠폰으로 처리가 되어있는지 일 단위로 확인한다.
- Q. 일 주문 300만이면 생각하지 못한 다양한 이슈가 무수히 많이 발생하는데, 이에 대한 로그수집 및 에러처리의 자동화가 어떤 구성으로 되어 있는지 서비스가 안정화 되어 있다면 트래픽 상승에 따라 겪었던 대표적인 이슈가 있는가?
- A. 대시보드 구성과 알람 설정. APM 시스템은 핀포인트, 시스템 지표는 Spring Actuator MicroMeter를 Metricbeat가 수집하고 어플리케이션 로그는 filebeat가 수집. 수집된 지표를 그라파나 대시보드로 보고 있다.
- 또한 장애대응 가이드를 만들어 주기적으로 모의장애 훈련을 진행하고 있음
- Q. 일 300만의 주문데이터량의 처리에 RDBMS를 사용하고 있는지 궁금하다.
- A. 트랜잭션 정합성이 중요한 도메인이다보니 CUD 작업에는 RDBMS를 사용하고 있고, 주문 내역 검색을 위해서 ElsaticSearch를 보조로 사용하고 있고, 조회 성능을 위해 역정규화를 통한 NoSQL DB를 사용하고 있다.
- Q. 일 300만 건이라는 주문을 처리할 때 안정성과 효율성이 굉장히 중요할 것 같은데, 대용량 데이터를 어떻게 처리하는지 그리고 팀 내에 장애 대응 가이드가 따로 있는지 궁금하다.
- A. 안정성: 일 단위, 시간 단위 등 특정 단위 별로 DB를 관리해주는 팀에서 스냅샷을 생성하고 있다. 그래서 문제가 발생했을 경우 특정 시점으로 빠르게 복원할 수 있게 스냅샷을 저장하고 있고, 정합성은 위에서 언급한 것 처럼 대사작업을 계속 진행하고 있다.
- 효율성: 특징에 맞는 저장소를 사용함으로 효율성을 극대화하기 위해 노력하고 있다.
- Q. 재발행된 이벤트에 대한 중복 처리 대응은 어떻게 하고 있는지 궁금하다.
- A. Subscriber 쪽에서 키 값을 기준으로 중복이 발생했을 경우에는 해당 이벤트를 스킵하는 방식으로 멱등성을 보장하고 있다.
- Q. Transactional OutBox Pattern 사용 시 Commit된 이벤트를 발행하는 애플리케이션 서버는 어떤 방식으로 재발행되는지 궁금하다. (지속적으로 Polling, 주기적인 스케줄링, Outbox 테이블을 변경 감지)
- A. OutBox 테이블에 저장하고 유실이 발생하면 수동으로 배치를 수행해서 재발행. 다른 팀에서는 Polling 방식을 이용해서 주기적으로 미발행된 메시지를 탐지하는 걸로 알고 있다.
- Q. 주문과 주문 조회 애플리에이션 서버, DB를 나눔으로써 실제 주문 처리 순서와 이벤트를 통한 주문 정보의 저장 순서에 차이가 있을 수도 있는데, 이러한 경우에는 어떻게 대응하고 있는지 궁금하다.
- A. 실시간 조회가 필요한 경우(대부분 단건 조회)에는 Master 장비를 조회하고 있다.
- Q. Key 모듈러 연산으로 샤딩 주소를 찾는 경우 샤드를 추가할 때 마다 데이터를 재배치하는 큰 작업이 진행되는데 이런 이슈는 어떻게 해결했는지 궁금하다.
- A. 아직까지 샤드를 추가해본 적은 없지만 데이터가 30일이 지났을 경우에는 몽고DB에 스냅샷 형태로 저장이 되기 때문에 30일이 지나면 데이터가 고르게 분포될 것으로 예상하고 있고 만약에 이런 부분에 대해 수고를 덜고 싶다면 Look Up Table을 관리하는 Directory Based Sharding 전략을 택하는 것을 추천한다.

평범한 백엔드 개발자