ICLR 2017 : Fast Reinforcement Learning via Slow Reinforcement Learning을 읽고 제대로 정리한 글입니다.

📌Abstract
DRL은 굉장히 많은 분야에서 발전해 왔습니다.
이때가... 2017년이니까 딱 Atari에서 블럭을 잘 깨고 할 시절이네요.
하지만 이런 학습에는 많은 시도(trial)이 필요합니다. 왜냐면 생기고나서 세상에 대한 선행 지식(prior knowledge)이 없거든요.
그냥 갓난애기가 태어나자마자 게임기를 주어준 느낌이랄까?
이 페이퍼는 "fast" RL알고리즘을 만드는 것을 목표로 하지 않습니다.
RNN(Recurrent neural network)로 "slow" RL을 만드는 것을 목쵸로 합니다.
이 RNN은 입력으로 observations(states), actions, rewards, termination flags를 받습니다.
이것들은 MDP에서 나왔으니까, 지금 이 환경을 RNN이 기억할 수 있도록 하게 하기 위해서 입니다.
action을 했더니 reward, (next) state, termination flag가 나왔네? 이거 환경 MDP니까 기억해놔!
💡1. Introduction
위에서도 말했지만 이때까지 블럭 깨고 할때였습니다. 문제는 많은 학습 비용(여러번 training)이 필요하다는 거였죠.
연구자들은 이 원인을 좋은 선행 지식이 없어서라고 생각했습니다.
물론 이전에 BRL(Bayesian Reinforcement Learning)같은 prior knowledge를 통합하는 알고리즘이 존재하긴 했습니다.
근데 이것들의 단점은 문제가 간단한 경우에만 적용 가능하다는 것이었죠.
이를 고치기 위해서 BRL에 도메인 특화 RL이 적용이 되긴 했는데 환경에 대해 가정하는 경향(제 생각인데 도메인 특화에서 인간이 간섭하는 것을 뜻하는 것 같습니다)이 있으며, 고차원 설정에서 다루기 어려웠습니다.
아 이것도 문제가 있네요!
그래서 논문 저자들은 다르게 접근합니다.
learning process자체를 목적함수로 둡니다.
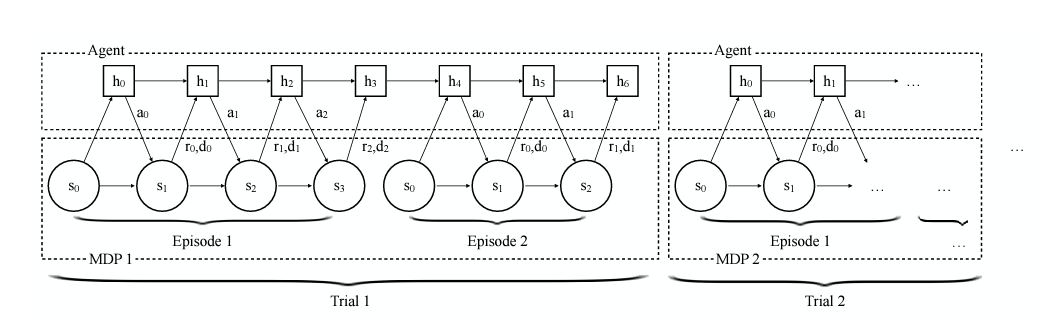
우리가 가정하는 환경을 잠시 보자면,
하나의 Trial은 여러 개의 Episode로 구성이 됩니다.
그리고 각 Trial마다 다른 MDP가 적용이 됩니다.
우리의 목표는 하나의 Trial에서 높은 cumulative reward sum를 받는 것이 목표입니다!
Episode를 여러번 수행하는 동시에, 해당 MDP에서의 구조를 기억을 한 후 최고의 점수를 받는 것이죠!
이렇게 전체 learning process(모든 가능한 MDPs)를 목표로 두면 기존 RL로도 문제를 해결할 수 있다고 합니다.
이때 우리가 RNN을 쓰는 이유는 MDP를 기억한다고 했죠?
RNN의 특징은 기억할 수 있다는 것인데, 그 점을 이용하기 위해서 RNN을 적용하였습니다.
이 논문에서는 총 3가지의 task를 진행하는데, 기존의 연구가 많이 되었던 multi-armed bandits, tabular MDPs
그리고 가장 어려운 vision-based navigation에 대한 task를 진행하였다고 합니다.
💡2 Method
2.1 Preliminaries
여기선 objective function(목적 함수)만 정확히 정의해두고 갑시다.
맨날 보던거죠?
2.2 Formulation
위에 사진을 한번 더 가져옵시다.
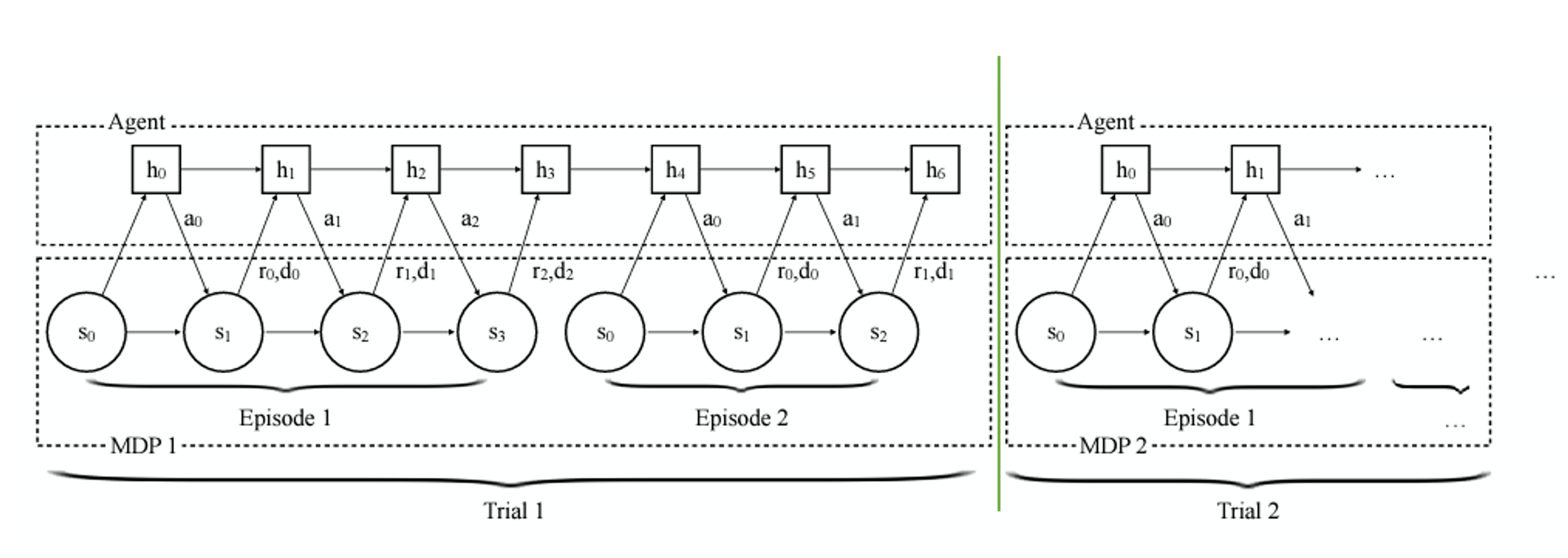
지금 초록색 선을 기준으로 Trial이 나뉘고 있습니다.
다시 한번 상기하자면 1 Trial = N episode라는 점!
우리의 RNN hidden state는 MDP를 기억해야 한다고 말했죠?
근데 초록색 선을 기준으로 MDP가 바뀌게 되는데 이전의 MDP를 기억하면 될까요?
당연히 안되겠죠?
다른 MDP니까 그래서 이것을 기준으로 hidden state를 초기화 해줍니다.
사진이 살짝 불친절해서 제가 조금 더 첨가해보겠습니다.
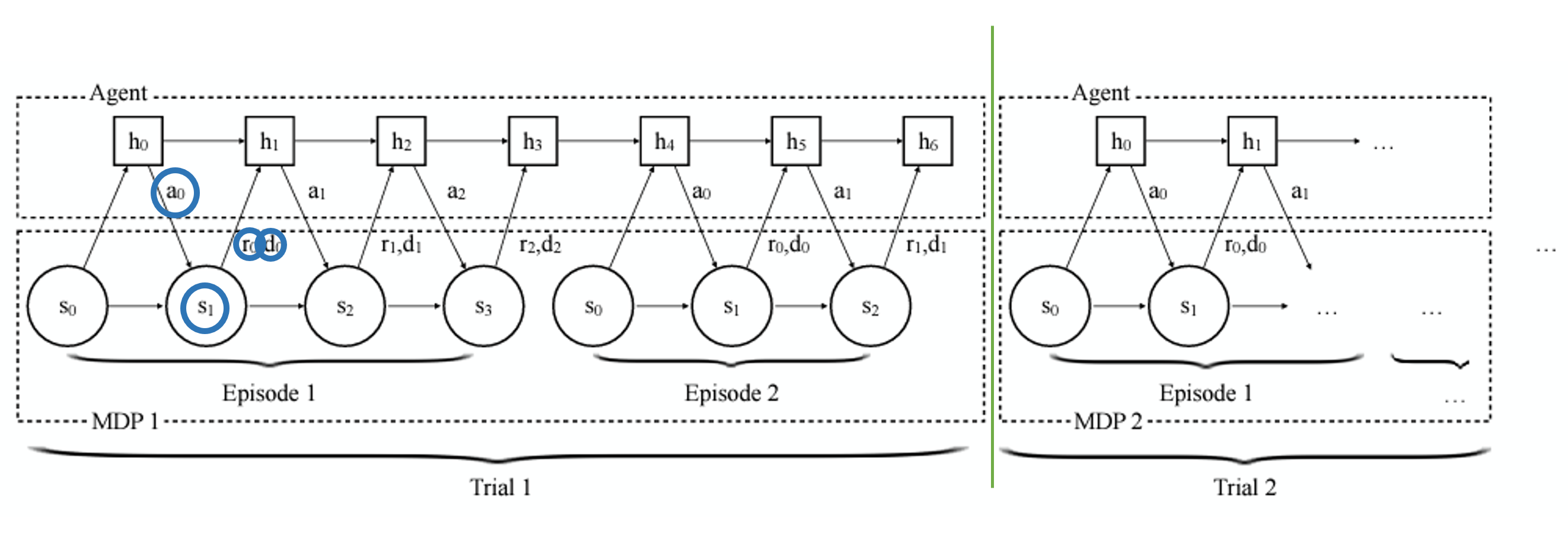
지금 Agent의 input으로 action, state, reward, terminated flag가 들어가고 있습니다
제가 위해서 했던 말을 다시 말하면-
action을 했더니 reward, (next) state, termination flag가 나왔네? 이거 환경 MDP니까 기억해놔!
기억하는건 RNN의 추가적인 특징이고, 우린 다음 state를 봤으면 action을 뱉어야죠?
output으로는 action을 내보냅니다.
2.3 Policy Representation
RNN을 훈련시키는데 vanishing gradient, exploding gradient 문제가 발생해서 GRUs(Gated Recurrent Units)를 사용했다고 합니다.
2.4 Policy Potimization
TRPO를 일차 미분해서 사용했다고 합니다. hyperparameter tuning이 필요가 없어서 편했다고...
💡3 Evaluation
3.1 Multi-Armed Bandits
이 문제는 갑자기 강도가 슬롯머신? 에 쳐들어왔는데 슬롯머신이 정해진 횟수밖에 땡길 수 없다는 것을 가정합니다.

각 손잡이에 확률과 상금이 걸려져 있는데, 이 강도들은 최대한 많은 돈을 뽑아내야겠죠?
예를 들어 손잡이가 두개라면, 첫번째 손잡이는 70% 확률로 100만원이 나오고, 두번째 손잡이는 10% 확률로 10억이 나온다면,
당연히 두번째 손잡이만 계속 땡기는게 이득이겠지만 그걸 잘 생각해야하는게 뽀인트죠?
이 문제의 key challenge는 exploration과 exploitation을 잘해야 하는 것입니다.
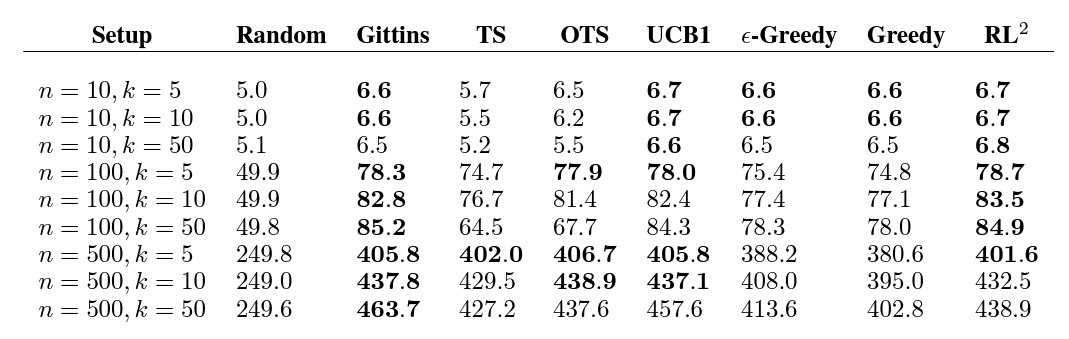
기존의 알고리즘에 밀리지 않은 성능을 보여주었다고 합니다.
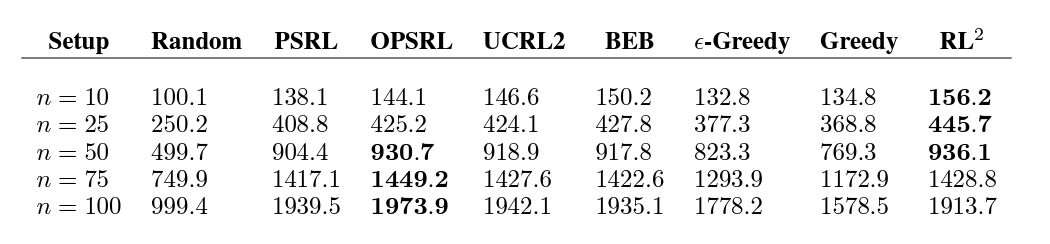
3.2 Tabular MDPs
다른 task를 생각해봅시다.
Multi-Armed bandit에서 잘되는건 알겠어... 근데 이건 sequential하지가 않죠? (현재 판단이 다음 시행에 독립적)
물론 그런 Sequential한 MDP에서도 잘 수행이 되었다고 합니다.
3.3 Visual Navigation
앞의 두문제는 시시하다고 느끼셨나요? 어려운 문제로 가봅시다~~ 고차원으로~~😀
시각 정보만으로는 강화학습에서 어려운 작업입니다.
훈련을 하며 희박한 보상만 받으면서 효율적 탐색이 어렵습니다.
추가적으로 이미 탐색했던 위치를 잊지 않고 결정하기 위해 메모리(RNN)도 효율적으로 사용해야 합니다.
대체적으로 잘하긴 했으니, 완벽하게 잘하지는 못했다고 합니다.
우리가 원한건 대상의 위치를 기억하고 이를 이용해 최적의 행동을 하는 것인데,
때때로 어디에 있는지 잃어버렸다고 합니다.
필자는 더 나은 강화학습 기술이 개선할 것이다 라며 Section 3를 마무리 짓습니다.
실제로 개선되기도 했죠
다음 포스팅은 코드 리뷰로 찾아뵙겠습니다.
