Meta-Learner
먼저 meta-learner 전체 코드입니다.
class MetaLearner:
def __init__(self, env, env_name, agent, trans_dim, action_dim, hidden_dim, train_tasks, test_tasks, save_exp_name, save_file_name, load_exp_name, load_file_name, load_ckpt_num, device, **config,
):
self.env = env
self.env_name = env_name
self.agent = agent
self.train_tasks = train_tasks
self.test_tasks = test_tasks
self.num_iterations = config["num_iterations"]
self.meta_batch_size = config["meta_batch_size"]
self.num_samples = config["num_samples"]
self.batch_size = self.meta_batch_size * config["num_samples"]
self.max_step = config["max_step"]
self.sampler = Sampler(env=env, agent=agent, action_dim=action_dim, hidden_dim=hidden_dim, max_step=config["max_step"])
self.buffer = Buffer(
trans_dim=trans_dim,
action_dim=action_dim,
hidden_dim=hidden_dim,
max_size=self.batch_size,
device=device,
)
if not save_file_name:
save_file_name = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
self.result_path = os.path.join("results", save_exp_name, save_file_name)
if load_exp_name and load_file_name:
ckpt_path = os.path.join(
"results",
load_exp_name,
load_file_name,
"checkpoint_" + str(load_ckpt_num) + ".pt",
)
ckpt = torch.load(ckpt_path)
self.agent.policy.load_state_dict(ckpt["policy"])
self.agent.vf.load_state_dict(ckpt["vf"])
self.buffer = ckpt["buffer"]
# 조기 학습 중단 조건 설정
self.dq: deque = deque(maxlen=config["num_stop_conditions"])
self.num_stop_conditions = config["num_stop_conditions"]
self.stop_goal = config["stop_goal"]
self.is_early_stopping = False
def meta_train(self):
# 메타-트레이닝
total_start_time = time.time()
for iteration in range(self.num_iterations):
start_time = time.time()
print(f"=============== Iteration {iteration} ===============")
# 메타-배치 태스크에 대한 경로를 수집
indices = np.random.randint(len(self.train_tasks), size=self.meta_batch_size) # 메타-배치 태스크 인덱스 랜덤 샘플링
for i, index in enumerate(indices):
self.env.reset_task(index)
print(f"[{i + 1}/{self.meta_batch_size}] collecting samples")
trajs: List[Dict[str, np.ndarray]] = self.sampler.obtain_samples(
max_samples=self.num_samples,
)
self.buffer.add_trajs(trajs)
batch = self.buffer.sample_batch()
# 정책과 가치함수를 PPO 알고리즘에서 학습
print(f"Start the meta-gradient update of iteration {iteration}")
log_values = self.agent.train_model(self.batch_size, batch)
# 메타-테스트 태스크에서 학습 성능 평가
self.meta_test(iteration, total_start_time, start_time, log_values)
if self.is_early_stopping:
print(
f"\n================================================== \n"
f"The last {self.num_stop_conditions} meta-testing results are {self.dq}. \n"
f"And early stopping condition is {self.is_early_stopping}. \n"
f"Therefore, meta-training is terminated.",
)
break
def meta_test(
self,
iteration,
total_start_time: float,
start_time: float,
log_values: Dict[str, float],
) -> None:
# 메타-테스트
test_results = {}
test_return: float = 0
test_run_cost = np.zeros(self.max_step)
for index in self.test_tasks:
self.env.reset_task(index)
self.agent.policy.is_deterministic = True
trajs: List[Dict[str, np.ndarray]] = self.sampler.obtain_samples(max_samples=self.max_step)
test_return += np.sum(trajs[0]["rewards"]).item()
if self.env_name == "vel":
for i in range(self.max_step):
test_run_cost[i] += trajs[0]["infos"][i]
test_results["return"] = test_return / len(self.test_tasks)
if self.env_name == "vel":
test_results["run_cost"] = test_run_cost / len(self.test_tasks)
test_results["sum_run_cost"] = np.sum(abs(test_results["run_cost"]))
test_results["total_loss"] = log_values["total_loss"]
test_results["policy_loss"] = log_values["policy_loss"]
test_results["value_loss"] = log_values["value_loss"]
test_results["total_time"] = time.time() - total_start_time
test_results["time_per_iter"] = time.time() - start_time
self.visualize_within_tensorboard(test_results, iteration)
# 학습 결과가 조기 중단 조건을 만족하는지를 체크
if self.env_name == "dir":
self.dq.append(test_results["return"])
if all(list(map((lambda x: x >= self.stop_goal), self.dq))):
self.is_early_stopping = True
elif self.env_name == "vel":
self.dq.append(test_results["sum_run_cost"])
if all(list(map((lambda x: x <= self.stop_goal), self.dq))):
self.is_early_stopping = True
# 학습 모델 저장
if self.is_early_stopping:
ckpt_path = os.path.join(self.result_path, "checkpoint_" + str(iteration) + ".pt")
torch.save(
{
"policy": self.agent.policy.state_dict(),
"vf": self.agent.vf.state_dict(),
"buffer": self.buffer,
},
ckpt_path,
)
역시 init 부분부터 살펴보도록 하겠습니다.
def __init__
class MetaLearner:
def __init__(self, env, env_name, agent, trans_dim, action_dim, hidden_dim, train_tasks, test_tasks, save_exp_name, save_file_name, load_exp_name, load_file_name, load_ckpt_num, device, **config,
):
self.env = env
self.env_name = env_name
self.agent = agent
self.train_tasks = train_tasks
self.test_tasks = test_tasks
self.num_iterations = config["num_iterations"]
self.meta_batch_size = config["meta_batch_size"]
self.num_samples = config["num_samples"]
self.batch_size = self.meta_batch_size * config["num_samples"]
self.max_step = config["max_step"]
self.sampler = Sampler(env=env, agent=agent, action_dim=action_dim, hidden_dim=hidden_dim, max_step=config["max_step"])
self.buffer = Buffer(
trans_dim=trans_dim,
action_dim=action_dim,
hidden_dim=hidden_dim,
max_size=self.batch_size,
device=device,
)
if not save_file_name:
save_file_name = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
self.result_path = os.path.join("results", save_exp_name, save_file_name)
self.writer = SummaryWriter(log_dir=self.result_path)
if load_exp_name and load_file_name:
ckpt_path = os.path.join(
"results",
load_exp_name,
load_file_name,
"checkpoint_" + str(load_ckpt_num) + ".pt",
)
ckpt = torch.load(ckpt_path)
self.agent.policy.load_state_dict(ckpt["policy"])
self.agent.vf.load_state_dict(ckpt["vf"])
self.buffer = ckpt["buffer"]
# 조기 학습 중단 조건 설정
self.dq: deque = deque(maxlen=config["num_stop_conditions"])
self.num_stop_conditions = config["num_stop_conditions"]
self.stop_goal = config["stop_goal"]
self.is_early_stopping = Falsedef meta_train
def meta_train(self):
# 메타-트레이닝
total_start_time = time.time()
for iteration in range(self.num_iterations):
start_time = time.time()
print(f"=============== Iteration {iteration} ===============")
# 메타-배치 태스크에 대한 경로를 수집
indices = np.random.randint(len(self.train_tasks), size=self.meta_batch_size)
for i, index in enumerate(indices):
self.env.reset_task(index)
print(f"[{i + 1}/{self.meta_batch_size}] collecting samples")
trajs: List[Dict[str, np.ndarray]] = self.sampler.obtain_samples(
max_samples=self.num_samples,
)
self.buffer.add_trajs(trajs)
batch = self.buffer.sample_batch()
# 정책과 가치함수를 PPO 알고리즘에서 학습
print(f"Start the meta-gradient update of iteration {iteration}")
log_values = self.agent.train_model(self.batch_size, batch)
# 메타-테스트 태스크에서 학습 성능 평가
self.meta_test(iteration, total_start_time, start_time, log_values)
if self.is_early_stopping:
print(
f"\n================================================== \n"
f"The last {self.num_stop_conditions} meta-testing results are {self.dq}. \n"
f"And early stopping condition is {self.is_early_stopping}. \n"
f"Therefore, meta-training is terminated.",
)
break메타 트레인 함수는 main함수에서 실행시키는 함수입니다. 즉 그냥 모든걸 담고 있겠죠
# RL^2 학습 시작
meta_learner.meta_train()한번 천천히 봅시다.
for i, index in enumerate(indices):
self.env.reset_task(index)
print(f"[{i + 1}/{self.meta_batch_size}] collecting samples")
trajs: List[Dict[str, np.ndarray]] = self.sampler.obtain_samples(
max_samples=self.num_samples,
)
self.buffer.add_trajs(trajs)
batch = self.buffer.sample_batch()indices만큼 for문을 돌립니다.
env.reset_task를 통해서 env를 reset시키고-
sampler에서 obtain_samples를 수행합니다.
여기 sampler에서는 직접적으로 environment와 상호작용을 하여 실제 agent가 수행한 정보(action, state, done, reward 등...)을 가져옵니다.
이후 self.buffer.add_trajs(trajs)를 통해서 버퍼에 추가한 후에 for문을 끝내고 있습니다.
# 정책과 가치함수를 PPO 알고리즘에서 학습
print(f"Start the meta-gradient update of iteration {iteration}")
log_values = self.agent.train_model(self.batch_size, batch)업데이트를 해 준 후에 test를 하며 코드를 끝내고 있습니다.
마무리하면서 좀 더 간단하게
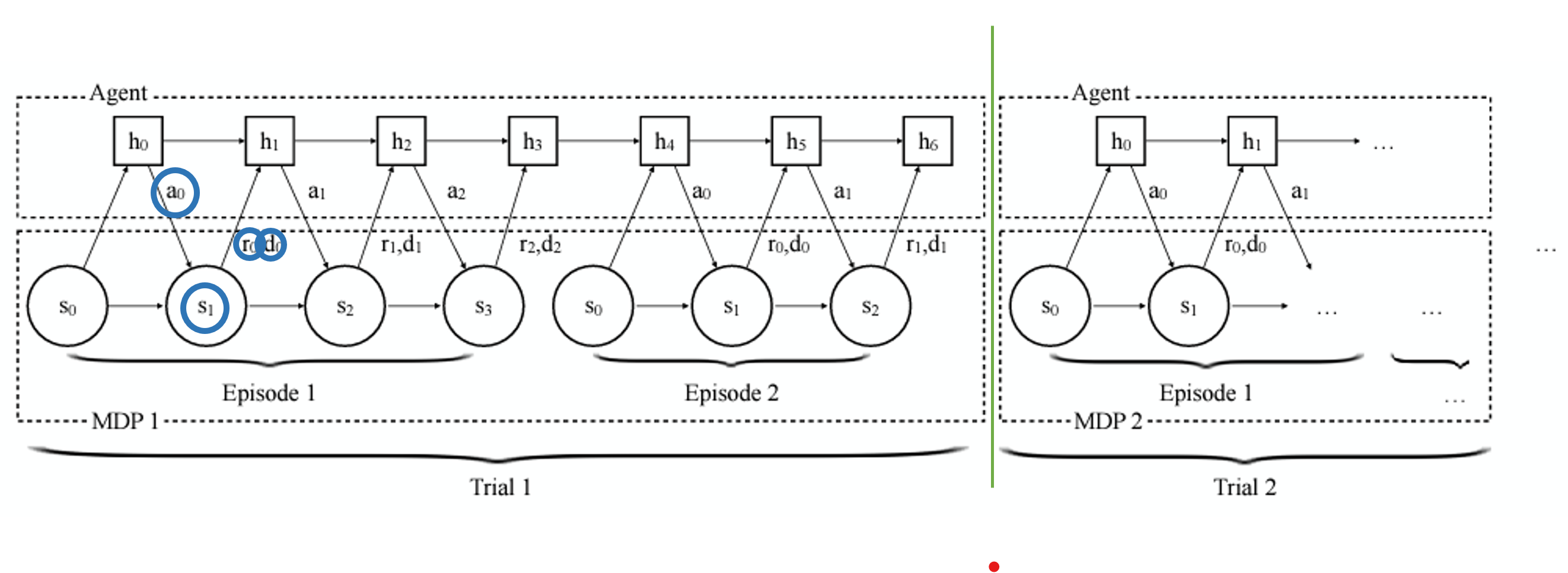
제가 논문 읽으면서 진짜 머리 깨지려고 했던게
아니 hidden state를 날려버리는데 무슨 어떻게 기억을 한다는 거지?
그렇다면 코드에 설명이 되어 있는건가? 해서 봤더니 이해가 안되는거예요.
코드가 잘못될일은 없으니까.. 진짜 10시간은 헤멧던거 같은데 진짜 간단한거였어요 뭐냐면

이게 제가 간단하게 필기한건데(틀린정보가 있을 수 있음)
hidden state자체를 GRU라고 생각했기 때문에 제 생각같은 오류가 발생한거예요 하
우리가 학습시키려는건 저 필기에서 W값을 잘 학습시키는게 목적이고,
W값이 잘 학습이 된다면 hidden state를 잘 넘겨주고, input을 잘 사용하는 그런 GRU를 만들 수 있는 겁니다.
이러면 hidden state를 날려주는 이유도 합리적이죠
왜냐면 hidden state 자체는 MDP를 가지고 있다라고 이해할 수 있고 모델이 만들어 낸거니까.
우리는 이 hidden state를 잘 표현하는 GRU의 W를 잘 학습시키려는 거구요...
암튼 그렇습니다. 포스팅 작성하다가 갑자기 깨달아 버려서 신나서 마무리합니다
틀린정보는 댓글로 알려주세요
