모두를 위한 메타러닝책의 코드를 참고하였습니다.
논문에서는 TRPO를 이용하여 구현하였다고 되어있는데요.
아무래도 TRPO는 구현 난도가 높기 때문에 우리는 PPO를 이용하여 구현해보도록 합시다.
그전에 전체적인 MDP를 기억시키기 위해서 RNN(Recurrent Neural Network)중 GRU(Gated Recurrent Unit)을 사용하였습니다.
GRU
PPO를 구성하기 전에 GRU를 먼저 작성해보도록 합시다.
GRU를 구성하기 전에 GRU에 대한 설명은 다른 블로그(추천 블로그)에 많이 설명되어 있으니 참고하고 보시면 더 이해하기 쉽습니다!
import torch.nn.functional as F
from torch.distributions import Normal
import numpy as np
class GRU(nn.Module):
def __init__(
self, input_dim, output_dim, hidden_dim, hidden_activation = F.relu, init_w = 3e-3,
):
super().__init__()
self.hidden_activation = hidden_activation
# GRU 레이어 생성
self.gru = nn.GRU(input_size=input_dim, hidden_size=hidden_dim)
# 출력 레이어 생성
self.last_fc_layer = nn.Linear(hidden_dim, output_dim)
self.last_fc_layer.weight.data.uniform_(-init_w, init_w)
self.last_fc_layer.bias.data.uniform_(-init_w, init_w)
def forward(self, x: torch.Tensor, h: torch.Tensor):
x, h = self.gru(x.unsqueeze(0), h.unsqueeze(0))
x = self.hidden_activation(x)
x = self.last_fc_layer(x)
return x, hpytorch에서 제공하는 GRU를 일부 이용하였습니다.
self.gru = nn.GRU(input_size=input_size, hidden_size=hidden_dim)두 인수를 넘겨주면 자동으로 GRU를 생성시켜 줍니다.
GRU는 두가지의 입력을 받는데, 첫번째로는 agent의 input이고, 두번째는 기억에 사용되는 hidden state입니다.
우리는 GRU를 그대로 사용할 수 없고 우리가 원하는 dimension으로 사용해야 하기 때문에 fc_layer를 추가하여 변환시킬 수 있게 해줍니다.
그래서 forward함수를 보면 gru에 agent input과 hidden_state를 넣고,
output x(hidden_state가 아님)를 activation과 fc_layer로 적절한 dimension으로 변환시켜줍니다.
GaussianGRU
GaussianGRU는 GRU를 상속받아 사용합니다.
왜 GRU랑 GaussianGRU로 따로 생각할까요?
우리는 RL에서 exploration을 할 때 deterministic하게 action을 구성하지 않는다면,
Distribution을 이용하여 exploration을 진행하기 때문입니다.
그러면 GRU는 value function에 이용하고, GaussianGRU는 actor에 해당한다는 것을 추론할 수 있습니다.
이헤가 잘 안되니 코드를 먼저 한번 보도록 합시다.
class GaussianGRU(GRU):
def __init__(self, input_dim, output_dim, hidden_dim, init_w = 1e-3):
super().__init__(input_dim=input_dim, output_dim=output_dim, hidden_dim=hidden_dim, init_w=init_w)
self.log_std = -0.5 * np.ones(output_dim, dtype=np.float32)
self.log_std = torch.nn.Parameter(torch.Tensor(self.log_std))
def get_normal_dist(self, x, h):
mean, hidden = super().forward(x, h)
std = torch.exp(self.log_std)
return Normal(mean, std), mean, hidden
def get_log_prob(self, trans, hidden, action):
normal, _, _ = self.get_normal_dist(trans, hidden)
return normal.log_prob(action).sum(dim=-1)
def forward(self, x, h):
normal, mean, hidden = self.get_normal_dist(x, h)
action = normal.sample()
log_prob = normal.log_prob(action).sum(dim=-1)
action = action.view(-1)
return action, log_prob, hiddenGaussianGRU에서는 GRU에 log_std를 추가시켜 주었습니다.
이때 log_std를 학습가능한 파라미터로 주었습니다.
정상적으로 학습이 된다면, 학습이 될수록 log_std가 줄어 exploration이 줄 것이라 예상 가능합니다.
def get_normal_dist(self, x, h):
mean, hidden = super().forward(x, h)
std = torch.exp(self.log_std)
return Normal(mean, std), mean, hidden여기서 normal distribution을 생성하는데, GRU에서 나온 x(action_mean)와 log_std를 이용하여
return Normal(mean, std), mean, hidden만들어내는 것을 볼 수 있습니다.
PPO
본격적으로 이 둘을 이용하여 PPO agent를 생성해보도록 합시다.
PPO는 어느정도 안다는 가정하에 설명을 이어가도록 하겠습니다.
살짝 코드가 기니까 나누어서 보도록 합시다.
일단 PPO의 전체 코드입니다.
import torch.optim as optim
import numpy as np
class PPO:
def __init__(self, trans_dim, action_dim, hidden_dim, device, **config):
self.device = device
self.num_epochs = config["num_epochs"]
self.mini_batch_size = config["mini_batch_size"]
self.clip_param = config["clip_param"]
self.policy = GaussianGRU(
input_dim=trans_dim,
output_dim=action_dim,
hidden_dim=hidden_dim,
).to(device)
self.vf = GRU(
input_dim=trans_dim,
output_dim=1,
hidden_dim=hidden_dim,
).to(device)
self.optimizer = optim.Adam(
list(self.policy.parameters()) + list(self.vf.parameters()),
lr=config["learning_rate"],
)
self.net_dict = {
"policy": self.policy,
"vf": self.vf,
}
def get_action(self, trans, hidden):
# 주어진 관측 상태와 은닉 상태에 따른 현재 정책의 action 얻기
action, log_prob, hidden_out = self.policy(
torch.Tensor(trans).to(self.device),
torch.Tensor(hidden).to(self.device),
)
return(
action.detach().cpu().numpy(),
log_prob.detach().cpu().numpy(),
hidden_out.detach().cpu().numpy(),
)
def get_value(self, trans, hidden):
# 상태 가치 함수 추론
value, hidden_out = self.vf(
torch.Tensor(trans).to(self.device),
torch.Tensor(hidden).to(self.device),
)
return value.detach().cpu().numpy(), hidden_out.detach().cpu().numpy()
def train_model(self, batch_size, batch):
# PPO 알고리즘에 따른 네트워크 학습
trans = batch["trans"]
pi_hiddens = batch["pi_hiddens"]
v_hiddens = batch["v_hiddens"]
actions = batch["actions"]
returns = batch["returns"]
advants = batch["advants"]
log_probs = batch["log_probs"]
num_mini_batch = int(batch_size / self.mini_batch_size)
trans_batches = torch.chunk(trans, num_mini_batch)
pi_hidden_batches = torch.chunk(pi_hiddens, num_mini_batch)
v_hidden_batches = torch.chunk(v_hiddens, num_mini_batch)
action_batches = torch.chunk(actions, num_mini_batch)
return_batches = torch.chunk(returns, num_mini_batch)
advant_batches = torch.chunk(advants, num_mini_batch)
log_prob_batches = torch.chunk(log_probs, num_mini_batch)
sum_total_loss = 0
sum_policy_loss = 0
sum_value_loss = 0
for _ in range(self.num_epochs):
sum_total_loss_mini_batch = 0
sum_policy_loss_mini_batch = 0
sum_value_loss_mini_batch = 0
for (
trans_batch,
pi_hidden_batch,
v_hidden_batch,
action_batch,
return_batch,
advant_batch,
log_prob_batch,
) in zip(
trans_batches,
pi_hidden_batches,
v_hidden_batches,
action_batches,
return_batches,
advant_batches,
log_prob_batches,
):
# 상태 가치 함수 손실 계산
value_batch, _ = self.vf(trans_batch, v_hidden_batch)
value_loss = F.mse_loss(value_batch.view(-1, 1), return_batch)
# 정책 손실 계산
new_log_prob_batch = self.policy.get_log_prob(
trans_batch,
pi_hidden_batch,
action_batch,
)
ratio = torch.exp(new_log_prob_batch.view(-1, 1) - log_prob_batch)
policy_loss = ratio * advant_batch
clipped_loss = (
torch.clamp(ratio, 1 - self.clip_param, 1 + self.clip_param) * advant_batch
)
policy_loss = -torch.min(policy_loss, clipped_loss).mean()
# 손실 합 계산
total_loss = policy_loss + 0.5 * value_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
sum_total_loss_mini_batch += total_loss
sum_policy_loss_mini_batch += policy_loss
sum_value_loss_mini_batch += value_loss
sum_total_loss += sum_total_loss_mini_batch / num_mini_batch
sum_policy_loss += sum_policy_loss_mini_batch / num_mini_batch
sum_value_loss += sum_value_loss_mini_batch / num_mini_batch
mean_total_loss = sum_total_loss / self.num_epochs
mean_policy_loss = sum_policy_loss / self.num_epochs
mean_value_loss = sum_value_loss / self.num_epochs
return dict(
total_loss=mean_total_loss.item(),
policy_loss=mean_policy_loss.item(),
value_loss=mean_value_loss.item(),
)def __init__
이중 init부분을 먼저 보도록 하죠.
def __init__(self, trans_dim, action_dim, hidden_dim, device, **config):
self.device = device
self.num_epochs = config["num_epochs"]
self.mini_batch_size = config["mini_batch_size"]
self.clip_param = config["clip_param"]
self.policy = GaussianGRU(
input_dim=trans_dim,
output_dim=action_dim,
hidden_dim=hidden_dim,
).to(device)
self.vf = GRU(
input_dim=trans_dim,
output_dim=1,
hidden_dim=hidden_dim,
).to(device)
self.optimizer = optim.Adam(
list(self.policy.parameters()) + list(self.vf.parameters()),
lr=config["learning_rate"],
)
self.net_dict = {
"policy": self.policy,
"vf": self.vf,
}보시면, self.policy에는 GaussianGRU를 사용하고 있으며, self.vf(value function)에는 GRU를 사용하고 있음을 알 수 있습니다.
올바른 추론이었습니다!
def get_action
def get_action(self, trans, hidden):
# 주어진 관측 상태와 은닉 상태에 따른 현재 정책의 action 얻기
action, log_prob, hidden_out = self.policy(
torch.Tensor(trans).to(self.device),
torch.Tensor(hidden).to(self.device),
)
return(
action.detach().cpu().numpy(),
log_prob.detach().cpu().numpy(),
hidden_out.detach().cpu().numpy(),
)당연한건 제쳐두고... hidden_out을 따로 받아서 사용한다는 점만 인지하고 가도록 합시다.
기억해야 하니깐요!
def get_value도 마찬가지니까 넘어가겠습니다.
def train_model
아직 살펴보진 않았지만, 기존 PPO와 같이 batch에서 꺼내와서 학습합니다.
def train_model(self, batch_size, batch):
# PPO 알고리즘에 따른 네트워크 학습
trans = batch["trans"]
pi_hiddens = batch["pi_hiddens"]
v_hiddens = batch["v_hiddens"]
actions = batch["actions"]
returns = batch["returns"]
advants = batch["advants"]
log_probs = batch["log_probs"]
num_mini_batch = int(batch_size / self.mini_batch_size)
trans_batches = torch.chunk(trans, num_mini_batch)
pi_hidden_batches = torch.chunk(pi_hiddens, num_mini_batch)
v_hidden_batches = torch.chunk(v_hiddens, num_mini_batch)
action_batches = torch.chunk(actions, num_mini_batch)
return_batches = torch.chunk(returns, num_mini_batch)
advant_batches = torch.chunk(advants, num_mini_batch)
log_prob_batches = torch.chunk(log_probs, num_mini_batch)
sum_total_loss = 0
sum_policy_loss = 0
sum_value_loss = 0
for _ in range(self.num_epochs):
sum_total_loss_mini_batch = 0
sum_policy_loss_mini_batch = 0
sum_value_loss_mini_batch = 0
for (
trans_batch,
pi_hidden_batch,
v_hidden_batch,
action_batch,
return_batch,
advant_batch,
log_prob_batch,
) in zip(
trans_batches,
pi_hidden_batches,
v_hidden_batches,
action_batches,
return_batches,
advant_batches,
log_prob_batches,
):
# 상태 가치 함수 손실 계산
value_batch, _ = self.vf(trans_batch, v_hidden_batch)
value_loss = F.mse_loss(value_batch.view(-1, 1), return_batch)
# 정책 손실 계산
new_log_prob_batch = self.policy.get_log_prob(
trans_batch,
pi_hidden_batch,
action_batch,
)
ratio = torch.exp(new_log_prob_batch.view(-1, 1) - log_prob_batch)
policy_loss = ratio * advant_batch
clipped_loss = (
torch.clamp(ratio, 1 - self.clip_param, 1 + self.clip_param) * advant_batch
)
policy_loss = -torch.min(policy_loss, clipped_loss).mean()
# 손실 합 계산
total_loss = policy_loss + 0.5 * value_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
sum_total_loss_mini_batch += total_loss
sum_policy_loss_mini_batch += policy_loss
sum_value_loss_mini_batch += value_loss
sum_total_loss += sum_total_loss_mini_batch / num_mini_batch
sum_policy_loss += sum_policy_loss_mini_batch / num_mini_batch
sum_value_loss += sum_value_loss_mini_batch / num_mini_batch
mean_total_loss = sum_total_loss / self.num_epochs
mean_policy_loss = sum_policy_loss / self.num_epochs
mean_value_loss = sum_value_loss / self.num_epochs
return dict(
total_loss=mean_total_loss.item(),
policy_loss=mean_policy_loss.item(),
value_loss=mean_value_loss.item(),
)torch.chunk를 이용하여 buffer에 쌓인 데이터를 불러옵니다.
# 상태 가치 함수 손실 계산
value_batch, _ = self.vf(trans_batch, v_hidden_batch)
value_loss = F.mse_loss(value_batch.view(-1, 1), return_batch)value function에 hidden을 같이 넣어주고 있습니다.
이후 loss를 구해주고 있습니다.
# 정책 손실 계산
new_log_prob_batch = self.policy.get_log_prob(
trans_batch,
pi_hidden_batch,
action_batch,
)
ratio = torch.exp(new_log_prob_batch.view(-1, 1) - log_prob_batch)PPO와 마찬가지로 ratioㄹ르 구해 update를 해줍니다.
PPO와 똑같죠?
간단하게 정리한 그림입니다.
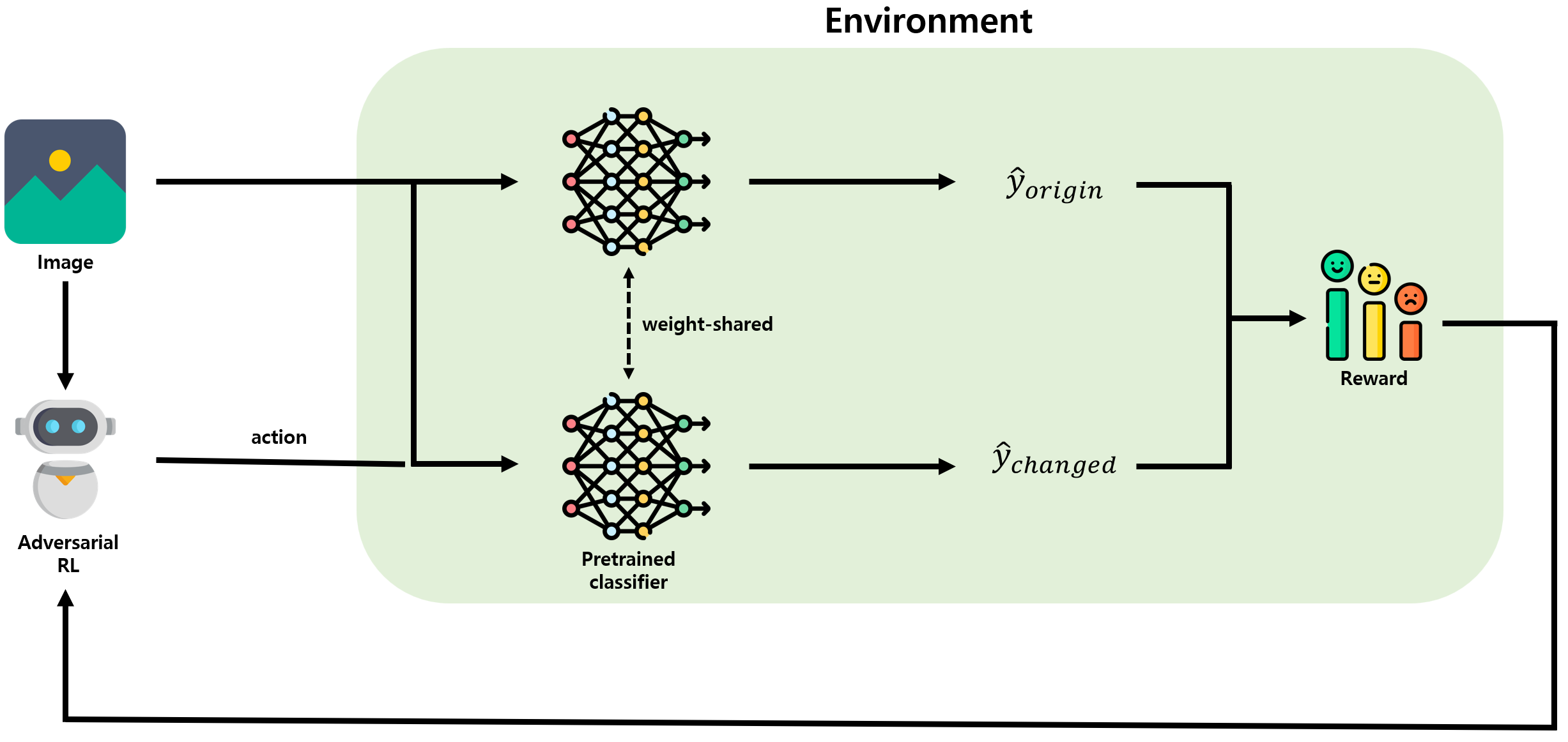
다음 메타 러너는 다음 post에서 알아봅시다.
