
LlamaIndex란?
LlamaIndex는 RAG pipeline을 구성하게 해주는 프레임워크입니다. 저는 처음에 Llama라는 이름을 보고 메타에서 출시한 LLM 모델과 관련이 있나 했지만 그렇지는 않았습니다. 이와 유사한 프레임워크로는 langchain이 있습니다. 두 프레임워크 모두 지금 빠르게 발전하고 있어 관심 있는 분들은 지켜보시길 추천합니다. 저도 그러려고 노력하는 중입니다.
RAG(Retrieval Augmented Generation)
RAG는 사용자의 데이터를 기반으로 LLM의 지식을 보충 및 강화하기 위한 패러다임입니다. 일반적으로는 두 가지 단계로 구성되어 있습니다.
1. 색인화 단계
2. 사용자 쿼리 단계
1.색인 단계(indexing stage)
색인화 단계에서는 외부의 데이터를 LLM모델이 검색해서 사용할 수 있도록 knowledge-base를 준비하는 단계입니다.

Data Connector(Data Loader): data connector는 다양한 데이터 소스 및 데이터 형식을 Document 형식으로 수집하는 llamaindex의 도구입니다. 여기서 Document는 text와 metadata로 이루어진 일종의 자료구조라고 저는 이해했습니다. Document 형식으로 변환된 데이터는 node 단위로 한 번 더 나뉘게 되는데 node는 Document가 chunking된 Document의 일부분이라고 생각하시면 됩니다.
Data Indexes: 이제 데이터가 검색되기 쉬운 형식으로 색인화를 진행합니다. 대표적으로 사용되는 색인화 방식으로는 vector indexing이 있는데, 이는 준비된 데이터(여기서는 node)를 embedding model을 사용해서 embedding을 한뒤, vector형식으로 저장을 하는 방법이 존재합니다.(chunking된 node의 의미를 담고있어서 semantic search의 일종이라고 생각합니다.)
쿼리 단계(query stage)
쿼리 단계에서는 사용자 쿼리와 가장 관련성이 높은 Context(여기서는 node)를 검색하고 이를 사용자 쿼리와 함께 LLM에 전달해서 최종 응답을 생성해냅니다. 이 구조는 기존 LLM에 존재하지 않았던 지식을 제공해 주어 모델의 할루시네이션을 감소시킵니다.
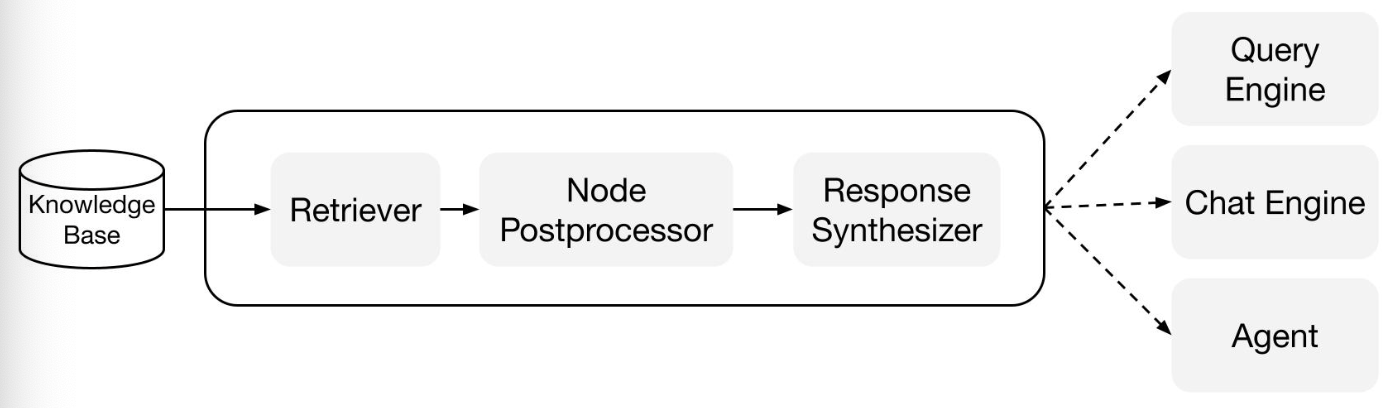
이 과정을 위해 llamaindex는 3가지 도구를 제공해 줍니다.
Retrievers: 관련 컨텍스트를 효율적으로 검색하는 방법을 정의합니다. 이 부분은 구축된 index마다 방법이 다르며, 가장 많이 사용되는 retriever는 vector 검색입니다.
Node postprocessors: 검색된 Context(node)를 특정 로직에 따라 필터링 및 리랭킹을 시키는 부분입니다.
Response Synthesizers: postprocessing까지 끝나면 사용자 쿼리와 함께 검색된 Context를 사용해 LLM에서 최종 응답을 생성해냅니다.
혹시 틀린 부분이 있다면 알려주세요. 피드백은 언제나 환영입니다
