get_dummies() method
먼저 get_dummies의 작동 원리에 대해서 이해하겠습니다.
다음 소주제에서는 어디에 활용하면 좋을지에 대해서 말씀 드리겠습니다.
말로는 설명이 어려울 것 같아서 아래 그림과 함께 설명 드립니다.
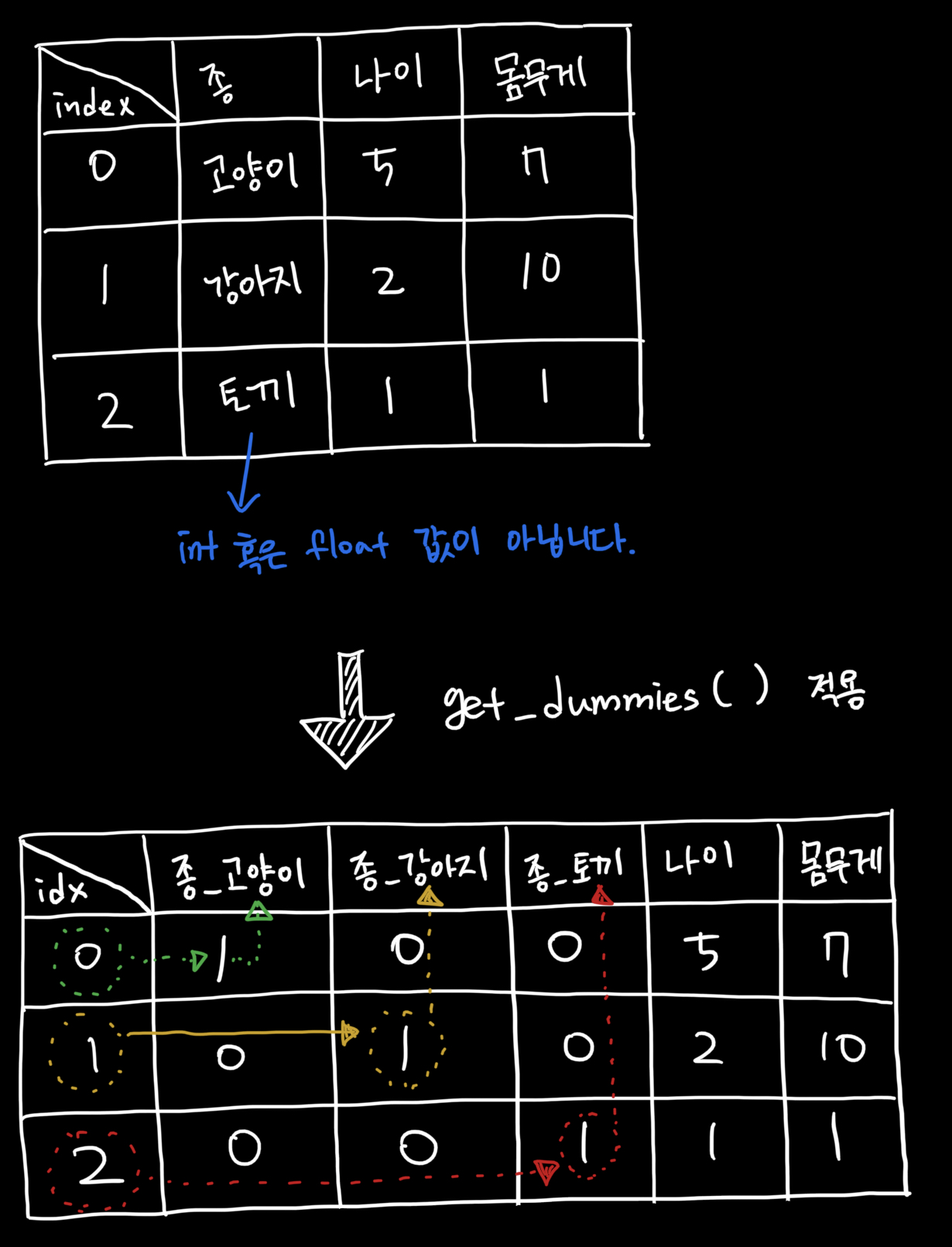
-
그림을 보시면 categorical 값을 가지는 column을 변형했습니다.
-
0번 데이터는 고양이 값을 가지고 있었네요.
(나머지는 직접 생각해보실까요!) -
get_dummies()적용하면 column이 카테고리의 개수(고양이, 강아지, 토끼 총 3개)만큼 생기고 해당 데이터가 가지는 값에 1 값을 저장합니다.- 당연히 나머지는 0을 가지네요.
-
one-hot encoding과 정말 닮았네요?
pandas 공식 문서
df = pd.DataFrame({
'A': ['a', 'b', 'a'],
'B': ['b', 'a', 'c'],
'C': [1, 2, 3]
})
pd.get_dummies(df, prefix=['col1', 'col2'])
'''
<결과>
prefix는 접두사라는 용어로 쓰입니다. -> 직관적이네요.
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
'''어디에 활용할까?
데이터의 feature가 위에서 그린 그림처럼 categorical한 값이라면 우리는 해당 값을 머신러닝에 활용하기 위해서 직접 전처리를 해주어야할 것입니다.
(제가 머신러닝을 공부중에 있어서 예시로 콕 집어 말씀드립니다.)
실제로 저는 어떤 데이터로 Random Forest 모델을 학습 시키고자 했습니다. 그런데 categorical한 값들은 모두 빼고 학습시켰습니다.
이젠 get_dummies() method를 알게 되었으니 categorical features도 학습에 활용을 해봐야겠네요.

개발자가 되고싶읍니다...