
크롤링
: 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위
크롤링 패턴
import requests
from bs4 import BeautifulSoup라이브러리 임포트
해당 코드는 파이썬에서 웹 크롤링(웹 페이지로부터 데이터를 수집하는 작업)을
수행하기 위해 사용되는 코드임
-
requests 모듈은 HTTP 요청을 보내는데 사용이 되는 모듈임.
==> 이 모듈은 웹 서버에 HTTP 요청을 보내고 응답을 받는데 사용이 됨.
주로 GET 또는 POST 요청을 보내는데 사용되며, 웹 페이지의 HTML
내용이나 JSON 데이터 등을 가져올 때 사용이 됨 -
Beautiful 모듈은 HTML이나 XML 문서를 파싱하고 분석하는데 사용되는 모듈임
==> 이 모듈은 HTML 문서 요소를 선택하고 검색하는데 도움이 되며,
웹 페이지의 특정 부분을 추출하거나 원하는 데이터를 수집하는데 사용이 됨
따라서 위 코드의 내용은 웹 페이지에서 데이터를 가져와서 파싱하고, 필요한
정보를 추출할 수 있게 하는 코드임. 이는 웹 크롤링을 구현하는데 매우
일반적으로 사용하는 방법임
get 메서드 안에 홈페이지 링크 넣기
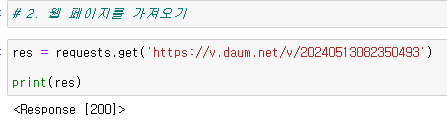
Response 200은 요청 정보를 가져오는데 성공했다는 뜻!
그냥 프린트를 한다면 아래와 같이 출력됨
html.parser
: 분석 하겠다는 뜻
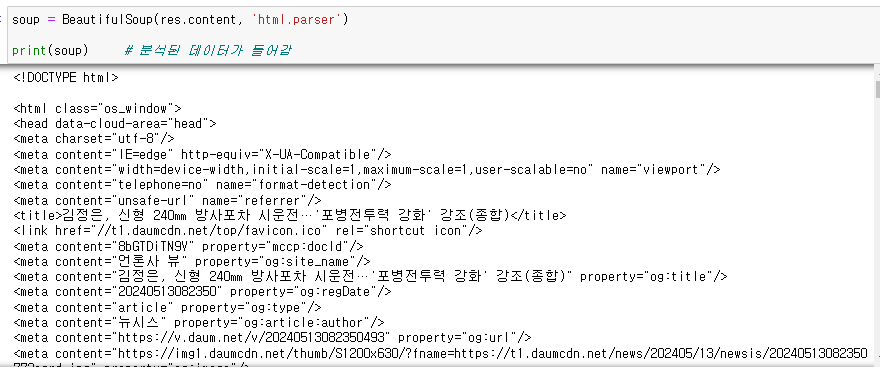
html 처럼 분석을 해주는 것이 확인 됨
soup 변수를 이용하면 됨!
find()
: 찾겠다는 뜻

글 내용만 가져온다면

h3 대신 title 태그를 가져와도 값은 똑같이 나옴!

혹은 class_ = '클래스명' 을 작성해도 됨

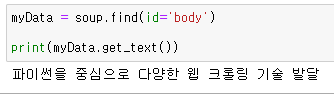
id를 가져올 때는 id = 'id명' 을 작성하면 됨

html 태그를 직접 작성하여 홈페이지를 만들어보자
=============================코드=============================
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h1 id = 'title'>크롤링이란?</h1>
<p class = 'cssstyle'>웹 페이지에서 필요한 데이터를 추출하는 것</p>
<p id = 'body' align = 'center'>파이썬을 중심으로 다양한 웹 크롤링 기술 발달</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
print(soup)=============================실행=============================

태그를 검색해보자

h1에 해당되는 텍스트가 출력됨!

p태그로 추출
p태그를 가져올 시 여러개인 경우에는 맨 처음에 나오는 내용만 출력하고,
그 이후 데이터는 검색을 하지 않음

모든 p태그를 추출하는 경우
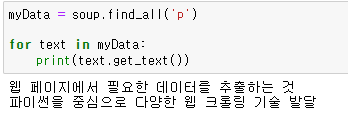
클래스명으로 추출

id명으로 추출
따라서 크롤링 작업 시에 가장 많이 사용되는 속성은 class 속성임
