Recap
- SIC, SIC/XE Machine Architectures
- 2-pass Assembler algorithm
- Define symbols -> symbol table
- Assemble instructions & generate object program
- Addressing
- Simple, Indirect, Immediate, Format 4
- Program relocation
- Allows us to load the program anywhere in main memory
- SIC, SIC/XE 시스템 아키텍처
- 2-pass 어셈블러 알고리즘
- 기호 정의 -> 기호 표
- 명령어 조립 및 객체 프로그램 생성
- 주소 지정
- Simple, Indirect, Immediate, Format 4
- 프로그램 재배치
- 메인 메모리의 어디서나 프로그램을 로드할 수 있다.
Machine-Independent Assembler Features
- There are some common assembler features that are notclosely related to machine architecture
- The presence or absence of such features is much more closely related to issues such as programmer convenience and software environment than it is to machine architecture
- 기계 아키텍처와 밀접한 관련이 없는 몇 가지 일반적인 어셈블러 기능이 있다.
- 이러한 기능의 유무는 기계 아키텍처보다 프로그래머의 편의성 및 소프트웨어 환경과 같은 문제와 훨씬 더 밀접하게 관련되어 있다.
- 5 features are introduced in our textbook (Chapter 2.3)
어셈블러 기능
Literals, Symbol defines, expressions, Program blocks, Control sections
Fig 2.9
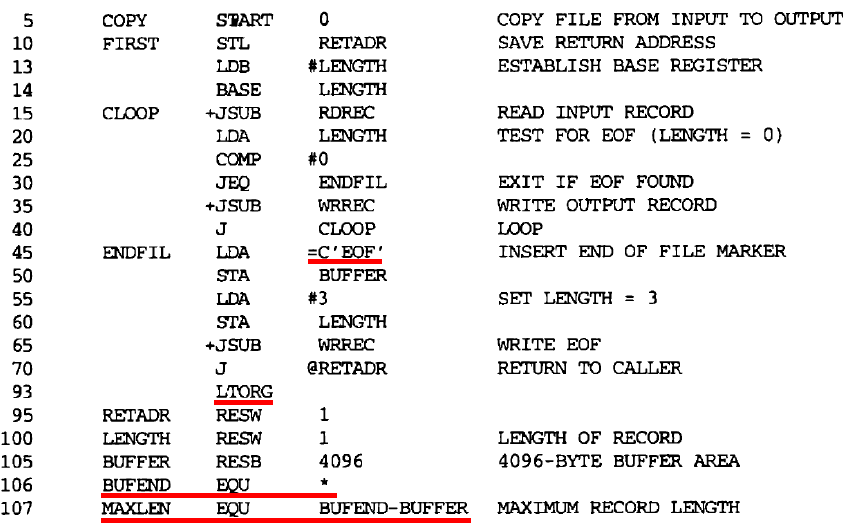
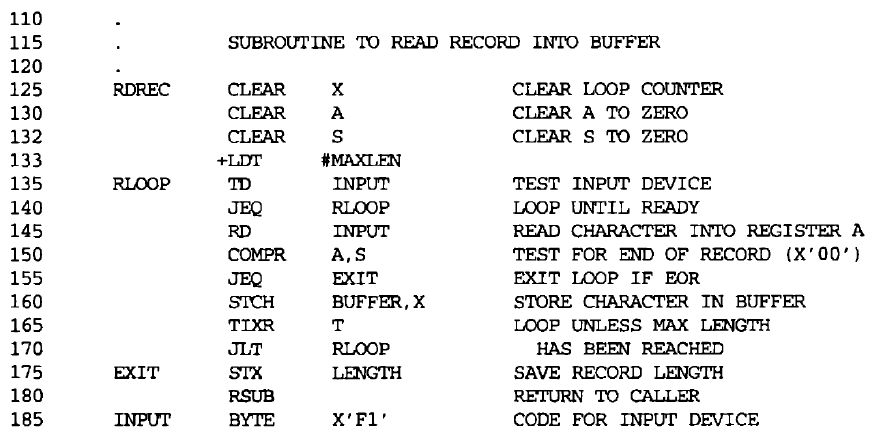
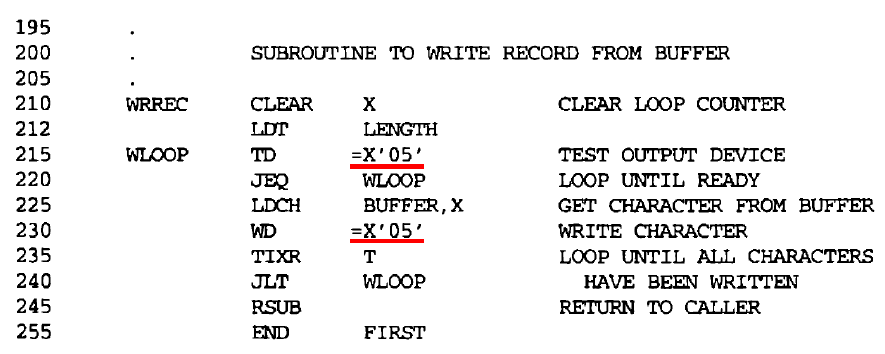
Fig 2.10
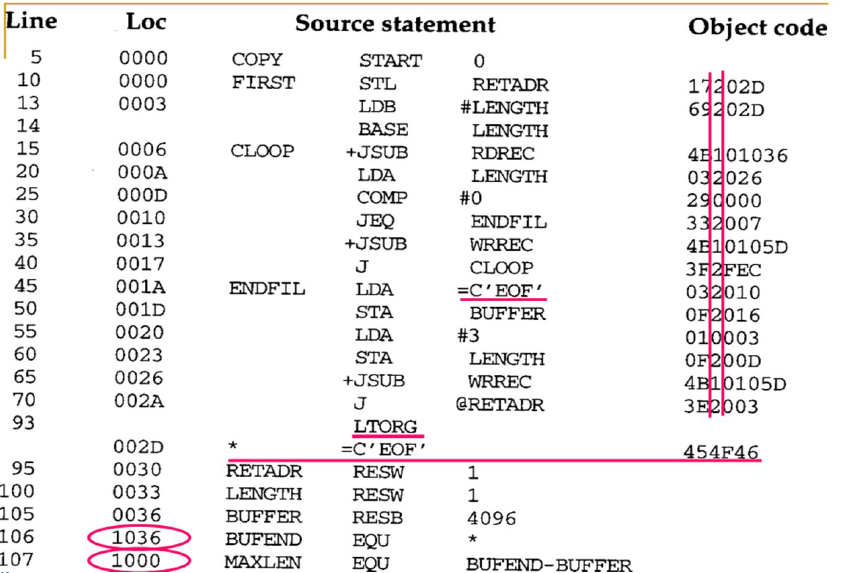


Literals
- It is often convenient for the programmer to be able to write the value of a constant operand as a part of the instructionthat uses it.
- This avoids having to define the constant elsewhere in the program and make up a label for it.
- Such an operand is called a “literal” because the value is stated literally in the instruction.
- A literal is identified with the prefix “=“, which is followed by a specification of the literal value, using the same notation as in the BYTE statement.
- e.g.
- 프로그래머가 상수 피연산자의 값을 사용하는 명령어의 일부로 쓸 수 있는 것은 종종 편리하다.
- 이렇게 하면 프로그램의 다른 곳에서 상수를 정의하고 상수에 대한 레이블을 작성할 필요가 없다.
- 이러한 피연산자는 문자 그대로 명령어에 값이 명시되어 있기 때문에 "문자"라고 불린다.
- 리터럴은 접두사 "="로 식별되며, 그 뒤에 바이트 문에서와 동일한 표기법을 사용하여 리터럴 값의 지정이 뒤따른다.
- 예)
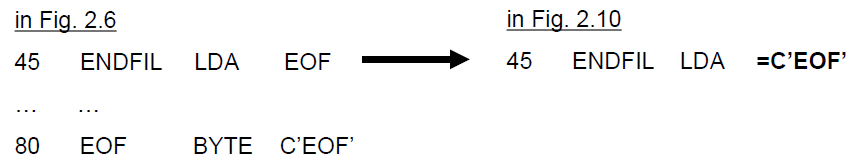
- 예)
Literal operand를 통해 상수값 자체를 instruction에 쓸 수 있게 한다.
원래 상수를 operand value로 사용하기 위해서는 byte나 word같은 directive로 정의하고 이후에 사용할 수 있었는데 그렇게 하지 않아도 된다.
Literals vs. Immediate Operand
- It is important to understand the difference between a literal and an immediate operand
- With immediate addressing, the operand value is assembled as part of the machine instruction.
- The immediate value is within the machine instruction itself.
- [e.g.] Line 55 in Fig. 2.10: LDA# 3 010003
- With a literal, the assembler generates the specified value as a constant at some other memory location.
- The address of this generated constant is used as the target address for the machine instruction.
- The literal value is obtained from data memory.
- [e.g.] Line 45 in Fig. 2.10: ENDFIL LDA=C'EOF' 032010
- 리터럴 피연산자와 직접 피연산자의 차이를 이해하는 것이 중요하다.
- 즉시 주소 지정을 사용하면 피연산자 값이 machine instruction의 일부로 조립된다.
- immediate value은 machine insturction 자체 내에 있다.
- [예] Fig 2.10 Line 55: LDA #3 010003
- 리터럴을 사용하여 어셈블러는 지정된 값을 다른 메모리 위치에서 상수로 생성한다.
- 이 생성된 상수의 주소는 기계 명령의 대상 주소로 사용된다.
- 리터럴 값은 데이터 메모리로부터 얻어진다.
- [예] Fig 2.10의 Line 45: ENDFIL LDA=C'EOF' 032010
immediate: value가 machine instruction 자체 내에 있다.
literal: 지정된 값을 다른 메모리 위치에서 상수로 생성
Literal Pool
- Assembler collects all the literal operands used in a program into one or more literal pools
- Default location is at the end of the program
- A literal pool listing is shown in Fig. 2.10 immediately following the END statement for better code reading. In this case, the pool consists of the single literal =X’05’.
- In some cases, however, a programmer can declare a place (i.e., at some other location in the object program)
- By using the assembler directive LTORG(Line 93 in Fig. 2.10)
- When the assembler encounters a LTORG statement, it creates a literal pool that contains all of the literal operands used since the previous LTORG (or the beginning of the program).
- To keep the literal operand close to the instruction that uses it.
- 어셈블러는 프로그램에서 사용되는 모든 리터럴 피연산자를 하나 이상의 리터럴 풀로 수집한다.
- 기본 위치는 프로그램 끝이다.
- 더 나은 코드 판독을 위해 END 문 바로 뒤에 리터럴 풀 목록이 Fig 2.10에 표시되어 있습니다. 이 경우 풀은 단일 리터럴 =X'05'로 구성된다.
- 그러나 어떤 경우에는 프로그래머가 장소(즉, 오브젝트 프로그램의 다른 위치)를 선언할 수 있다.
- assembler directive LTORG(그림 2.10의 93번 라인)를 사용하여
- 어셈블러가 LTORG 문을 만나면 이전 LTORG(또는 프로그램의 시작) 이후 사용된 모든 리터럴 피연산자를 포함하는 리터럴 풀을 만든다.
- 리터럴 피연산자를 사용하는 지침에 가깝게 유지한다.
모든 literal operand를 literal pool로 수집
기본 위치는 프로그램 끝
프로그래머가 선언할 수도 있다.
LTORG
Duplicate Literals
- Most assemblers recognize duplicate literals (= the same literal used in more than one place in the program), and store only one copy of the specified data value
- For example, the literal =X’05’ is used on lines 215 and 230. However, only one data area with this value is generated. Both instructions refer to the same address in the literal pool for their operand.
- 대부분의 어셈블러는 중복 리터럴(= 프로그램에서 둘 이상의 위치에서 사용되는 동일한 리터럴)을 인식하고 지정된 데이터 값의 복사본 하나만 저장한다.
- 예를 들어, =X'05'는 215행과 230행에서 사용된다. 그러나 이 값을 가진 데이터 영역은 하나만 생성된다. 두 명령어는 피연산자의 리터럴 풀에서 동일한 주소를 참조한다.
중복 literal은 하나만 저장
How does the Assembler handle Literal Operands?
- The basic data structure needed: LITTAB(Literal Table)
- For each literal used, the table contains [Literal name, Operand value and length, Address assigned to the operand when it is placed in a literal pool]
- During Pass1: Each literal operand is recognized.
- Assembler searches LITTAB for the specified literal name.
- If found, no action is needed; Otherwise, the literal is added to LITTAB (leaving the address unassigned).
- If the code is LTORG or END, assign addresses for literals in LITTAB.
- During Pass2: Each literal operand is translated to its address.
- The operand address for use in generating object code is obtained by searching LITTAB for each literal operand encountered
- The data values of literals are inserted into the object program
- 필요한 기본 데이터 구조: LITTAB(Literal Table)
- 사용된 각 리터럴에 대해 테이블에는 [리터럴 이름, 피연산자 값 및 길이, 피연산자가 리터럴 풀에 배치될 때 피연산자에 할당된 주소]가 포함된다.
- During Pass 1: 각 리터럴 피연산자가 인식된다.
- 어셈블러는 LITTAB에서 지정된 리터럴 이름을 검색한다.
- 발견되면 조치가 필요하지 않습니다. 그렇지 않으면 리터럴이 LITTAB에 추가된다(주소는 할당되지 않음).
- 코드가 LTORG 또는 END이면 LITTAB에서 리터럴에 대한 주소를 할당한다.
- During Pass 2: 각 리터럴 피연산자는 해당 주소로 변환된다.
- 개체 코드를 생성하는 데 사용할 피연산자 주소는 발견된 각 리터럴 피연산자에 대해 LITTAB를 검색하여 얻는다.
- 리터럴의 데이터 값이 객체 프로그램에 삽입된다.
필요한 데이터 구조: LITTAB(Literal Table)
During Pass 1: 각 literal operand 인식
During Pass 2: 각 literal operand 해당 주소로 변환, object program에 삽입
Symbol Definitions
- Most assemblers provide an assembler directive that allows the programmer to define symbols and specify their values.
- EQU is the assembler directives whose main function is the definition of symbols.
- One common use of EQU (for “equate”)
- Form: symbol EQU value
- To establish symbolic names that can be used for improving readability in place of numeric values.
- 대부분의 어셈블러는 프로그래머가 기호를 정의하고 값을 지정할 수 있는 어셈블러 지시어를 제공한다.
- EQU는 기호의 정의를 주요 기능으로 하는 어셈블러 지시어이다.
- EQU의 한 가지 일반적인 사용 ("등가")
- Form: symbol EQU value
- 숫자 값 대신 가독성을 향상시키는 데 사용할 수 있는 기호 이름을 설정한다.

EQU: symbol 정의
숫자 대신 이름 설정
symbol 정의. SIC에서는 EQU라는 directive로 정의할 수 있다. 상수값에 대해서 이름을 붙일 수 있다. 이름을 붙이면 의미 전달에 유리할 것이다.
4096이라고 쓰는 것보다 4096 symbol을 정의하고 대신 사용하면 가독성이 올라간다.
Symbol Definitions with EQU
- When the assembler encounters the EQU statement, it enters MAXLEN into SYMTAB (with value 4096).
- During assembly of the LDT instruction, the assembler searches SYMTAB for the symbol MAXLEN, using its value as the operand in the instruction.
- The resulting object code is exactly the same as the original version of the instruction (i.e., the one using the value instead of symbol)
- However, the source statement is easier to understand. It is also much easier to find and change the value of MAXLEN if this becomes necessary
- 어셈블러는 EQU 문을 만나면 MAXLEN을 SYMTAB(값 4096)에 입력한다.
- LDT 명령어를 조립하는 동안 어셈블러는 명령어의 피연산자 값을 사용하여 기호 MAXLEN을 SYMTAB에서 검색한다.
- 결과 객체 코드는 명령의 원래 버전과 정확히 동일하다(즉, 기호 대신 값을 사용하는 코드).
- 그러나 소스 문장이 더 이해하기 쉽다. 또한 MAXLEN의 값을 찾고 변경하는 것이 훨씬 더 쉽다.
EQU 문을 만나면 MAXLEN을 SYMTAB에 입렵
LDT 명령어를 조립하는 동안 피연산자 값을 사용하여 MAXLEN을 SYMTAB에서 검색한다.
원래 버전과 동일하다.
pass1에서 EQU directive를 assembler가 처리하고, symbol table에 넣는다. pass2에서 EQU directive로 정의된 operand 해당 주소로 반환한다.
Symbol Definitions with EQU
- Another common use of EQU is to define mnemonic names를for registers.
- In a machine with many general-purpose registers, not like in SIC, having mnemonic names for registers can help!
- c.f.) The standard mnemonics for registers are already defined in SIC
- The programmer can establish and use names that reflect the logical function of the registers in the program
- In a machine with many general-purpose registers, not like in SIC, having mnemonic names for registers can help!
- EQU의 또 다른 일반적인 용도는 레지스터의 mnemonic names를 정의하는 것이다.
- SIC와 달리 범용 레지스터가 많은 기계에서는 레지스터를 위한 mnemonic name을 갖는 것이 도움이 될 수 있다.
- c.f.) 레지스터에 대한 표준 니모닉은 SIC에 이미 정의되어 있다.
- 프로그래머는 프로그램에서 레지스터의 논리적 기능을 반영하는 이름을 설정하고 사용할 수 있다.

- SIC와 달리 범용 레지스터가 많은 기계에서는 레지스터를 위한 mnemonic name을 갖는 것이 도움이 될 수 있다.
mnemonic names 정의
register 이름을 정의할 수도 있다.
general purpose register 어떤 용도로 사용하냐에 따라 다른 이름을 정의해줄 수 있다. R1을 BASE Register로 사용한다면 BASE라고 이름을 붙여줄 수 있다.
Restriction in Symbol Definitions
- The descriptions on the EQU statement contain a restriction that is common to all symbol-defining assembler directives.
- All symbols used on the right-hand side of the statement (= all terms used to specify the value of the new symbol) must have been defined previously in the program.
- EQU 문에 대한 설명에는 모든 기호 정의 어셈블러 지시어에 공통되는 제한이 포함되어 있다.
- statement의 오른쪽에 사용되는 모든 기호(= 새 기호 값을 지정하는 데 사용되는 모든 용어)는 프로그램에서 미리 정의되어 있어야 한다.

제약 상황. forward reference를 허용하지 않는다. BETA에서 ALPHA를 사용한다면 ALPHA가 먼저 정의가 되어야 한다.
Expression
- Most assemblers allow the use of expression wherever a single operand (labels, literals, etc.) is permitted. Each such expression must, of course, be evaluated by the assembler to produce a single operand address or value.
- Assemblers generally allow arithmetic expressions formed according to the normal rules using the operators +,-,*,and /
- Individual terms in the expression may be constants, user-defined symbols, or special terms.
- The most common such special term is the current value of the location counter (often designated by *). This term represents the value of the next unassigned memory location
- [e.g.] Line 106 in Fig. 2.10: BUFEND EQU *
- -> This statement gives BUFEND a value that is the address of the next byte after the buffer area
- 대부분의 어셈블러는 단일 피연산자(라벨, 리터럴 등)가 허용되는 곳이면 어디든 표현식의 사용을 허용한다. 이러한 각 표현식은 물론 어셈블러가 평가하여 단일 피연산자 주소 또는 값을 생성해야 한다.
- 어셈블러는 일반적으로 연산자 +, -, * 및 /를 사용하여 정규 규칙에 따라 생성되는 산술 식을 허용한다.
- 식의 개별 용어는 상수, 사용자 정의 기호 또는 특수 용어일 수 있다.
- 가장 일반적인 특수 용어는 위치 카운터의 현재 값(종종 *로 지정됨)입니다. 이 용어는 할당되지 않은 다음 메모리 위치의 값을 나타낸다.
- [예] Line 106 in Fig. 2.10: BUFEND EQU *
- -> 이 문은 BUFEND에게 버퍼 영역 다음 바이트의 주소인 값을 제공한다.
어떤 값으로 계산을 할 수 있는 코드 구문들을 Expression이라고 정의한다.
arithmetic expression을 사용할 수 있다. 여러 산술 연산자들을 통해 만들어질 수 있다. 각 term이 constants, user-defined symbolds, special terms. *는 할당되지 않은 다음 메모리의 위치 값.
이 지점에서의 location counter 값의 value를 생각해보아야 한다.
- Expressions are classified depending upon the types of values they produce
- Absolute expressions: independent of program location
- Relative expressions: relative to the beginning of program
- A symbol defined by EQU can also be absolute or relative
- 표현식은 생성되는 값의 유형에 따라 분류된다.
- 절대식: 프로그램 위치와 무관함
- 상대식: 프로그램 시작 시 상대식
- EQU에 의해 정의된 기호는 절대적이거나 상대적일 수도 있다.

This value (hexadecimal 1000) does not represent an address, as do most of the other entries in Loc column. It does show the value that is associated with the symbol that appears in the source statement (MAXLEN).
이 값(16진수 1000)은 Loc 열의 다른 대부분의 항목과 마찬가지로 주소를 나타내지 않는다. source statement(MAXLEN)에 나타나는 기호와 관련된 값을 표시한다.
- To determine the type of an expression, we must keep track of the types of all symbols defined in the program. For this purpose we need a flag in the symbol table to indicate type of value (absolute or relative) in addition to the value itself.
- Thus, SYMTAB needs a type field to discern absolute symbols from relative symbols
- 식 유형을 결정하기 위해 프로그램에 정의된 모든 기호 유형을 추적해야 한다. 이를 위해 기호 표에 값 자체 외에도 값의 유형(절대 또는 상대)을 나타내는 플래그가 필요하다.
- 따라서 SYMTAB는 절대 기호를 상대 기호와 구별하기 위해 type field가 필요하다.
SYMTAB는 type field가 필요
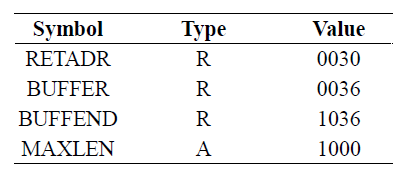
- Operands of format 4 instructions may have relative values; Such relative values should be modified for relocation by the loader later.
- We need to know which is relative
- e.g., +JSUB RDREC->relative value, we need a modification record
- e.g., +LDT #MAXLEN->absolute value
- 형식 4 명령의 피연산자는 상대적인 값을 가질 수 있다.
- 어느 것이 상대적인지 알아야 한다.
- 예: +JSUB RDREC->상대값, 수정기록이 필요하다.
- 예: +LDT #MAXLEN->절대값
Program Blocks
- In all of the examples we have seen so far, the program being assembled was treated as a unit
- The source programs logically contained subroutines, data areas, etc
- However, they were handled by the assembler as one entity, resulting in a single block of object code.
- Many assemblers provide features that allow more flexible handling of the source and object programs
- Some features allow the generated machine instructions and data to appearin the object program in a different orderfrom the corresponding source statements -> Program Blocks, to refer to segments of code that are rearranged within a single object program unit
- Other features result in the creation of several independent parts of the object program. These parts maintain their identity and are handled separately by the loader -> Control Sections, to refer to segments that are translated into independent object program units
- 지금까지 본 모든 예에서, 조립되는 프로그램은 하나의 단위로 취급되었다.
- 소스 프로그램은 논리적으로 서브루틴, 데이터 영역 등을 포함했다.
- 그러나 이들은 어셈블러에 의해 하나의 개체로 처리되어 객체 코드의 단일 블록이 생성되었다.
- 많은 어셈블러가 소스 및 객체 프로그램을 보다 유연하게 처리할 수 있는 기능을 제공한다.
- 일부 기능은 생성된 기계 명령어와 데이터가 해당 소스 문 -> 프로그램 블록과 다른 순서로 객체 프로그램에 나타나 단일 객체 프로그램 유닛 내에서 재배치되는 코드의 세그먼트를 참조할 수 있게 한다.
- 다른 기능들은 객체 프로그램의 몇 가지 독립적인 부분들을 만든다. 이러한 부품은 독립 객체 프로그램 단위로 변환되는 세그먼트를 참조하기 위해 로더 -> 제어 섹션에 의해 개별적으로 처리된다.
program block, 논리적인 구분
각 program block이 별도의 주소 공간을 가지고 있다.
loader->control section에 의해 개별적으로 처리된다.
- Figures 2.11 and 12 show an example program as it might be written using program blocks
- The assembler directive USE indicates which portions of the source program belong to the various blocks (If no USE statements are included, the entire program belongs to the single block)
- Three program blocks are used.
- Executable instructions: (unnamed)
- Data area that are a few words or less in length (named CDATA)
- Data area consisting of larger blocks of memory (named CBLKS)
- Each program block has relative address space separately
- 그림 2.11과 12는 프로그램 블록을 사용하여 작성될 수 있는 예제 프로그램을 보여준다.
- 어셈블러 지시 USE는 소스 프로그램의 어떤 부분이 다양한 블록에 속하는지 나타낸다(USE 문이 포함되지 않은 경우 전체 프로그램은 단일 블록에 속함).
- 세 개의 프로그램 블록이 사용된다.
- 실행 지침: (이름 없음)
- 길이가 몇 단어 이하인 데이터 영역 (CDATA라고 함)
- 더 큰 메모리 블록(CBLKS)으로 구성된 데이터 영역
- 각 프로그램 블록에는 별도의 상대 주소 공간이 있다.
USE는 소스 프로그램이 어떤 아양한 블록에 속하는지 나타냄.
- Pass 1
- Maintain a separate LOCCTR for each program block
- Each label is assigned an address relative to the start of the blockthat contains it
- SYMTBL stores block number for each symbol
- Store starting address of each block in block table
* At the end of Pass 1, the assembler constructs a table that contains the starting addresses and lengths for all blocks

- Maintain a separate LOCCTR for each program block
- Pass 2
- For translation, the assembler calculates the address for each symbol relative to the start of the object program
- By adding the address of the symbol, relative to the start of its block, to the assigned block starting address(e.g., the address of INPUT = 6 + 66 = 6C)
- 6: The address relative to the start of the block
- 66: The starting address of CDATA
- By adding the address of the symbol, relative to the start of its block, to the assigned block starting address(e.g., the address of INPUT = 6 + 66 = 6C)
- For translation, the assembler calculates the address for each symbol relative to the start of the object program
- Pass 1
- 각 프로그램 블록에 대해 별도의 LOCCTR 유지
- 각 레이블에는 해당 레이블을 포함하는 블록의 시작과 관련된 주소가 할당된다.
- SYMTBL은 각 기호에 대한 블록 번호를 저장한다.
- 각 블록의 시작 주소를 블록 테이블에 저장
* 패스 1의 끝에서 어셈블러는 모든 블록의 시작 주소와 길이를 포함하는 테이블을 구성한다.각 symbol block number를 저장하게 된다.
- 각 프로그램 블록에 대해 별도의 LOCCTR 유지
- Pass 2
- 번역을 위해 어셈블러는 객체 프로그램의 시작을 기준으로 각 기호에 대한 주소를 계산한다.
지정된 블록 시작 주소에 해당 블록의 시작에 상대적인 기호 주소를 추가한다. (예: INPUT = 6 + 66 = 6C).
6: 블록의 시작과 관련된 주소
* 66: CDA의 시작 주소TA주소 계산
- 번역을 위해 어셈블러는 객체 프로그램의 시작을 기준으로 각 기호에 대한 주소를 계산한다.
Fig 2.12
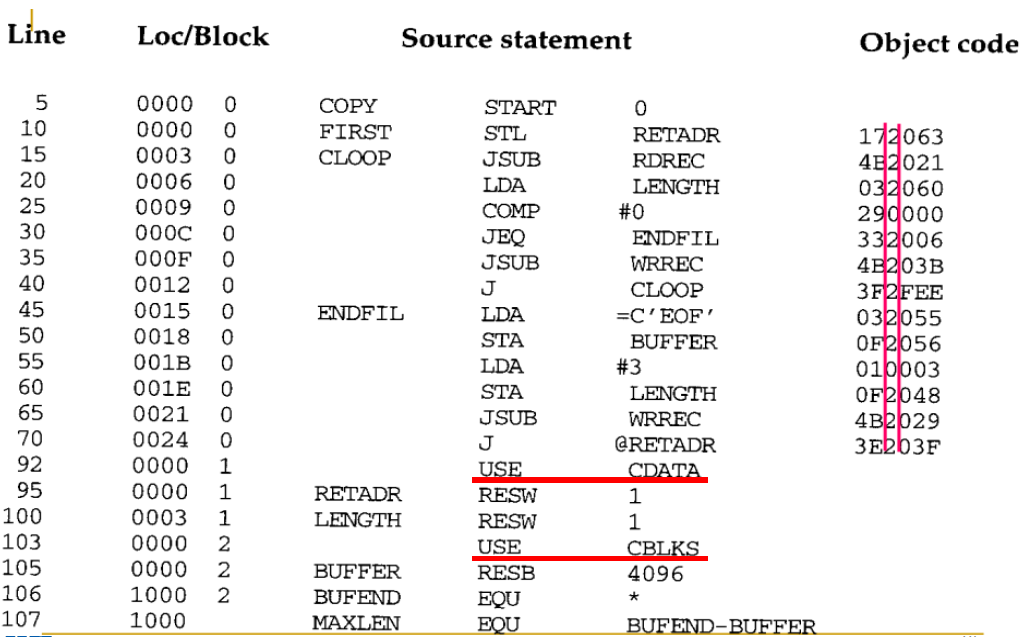
JSUB은 Format 4 instruction.
USE Directive를 만날 때마다 이전에 사용하던 text record를 object program 파일에 쓰고 새로운 program block에 대한 object 값을 저장한다.
RESW, RESB라 별도의 object code가 필요하지 않다.


Fig 2.13

- The first two Text records: generated from the source lines 5~70
- When the USE on line 92 is recognized, the assembler writes out the current Text record (even though there is still room left in it)
- The assembler then prepares to begin a new Text record for the new program block. The next two Text records come from lines 125~180
- The 5th Text record contains the single byte of data from line 185
- The 6th Text record resumes the default program block and the rest of the object program continues in similar fashion
- 처음 두 개의 텍스트 레코드: 소스 라인 5~70에서 생성된다.
- 라인 92에서 USE가 인식되면 어셈블러는 현재 텍스트 레코드를 기록한다(아직 공간이 남아 있더라도).
- 그런 다음 어셈블러는 새 프로그램 블록에 대한 새 텍스트 레코드를 시작할 준비를 한다. 다음 두 개의 텍스트 레코드는 125~180행에서 나온다.
- 5번째 텍스트 레코드는 185행의 데이터의 단일 바이트를 포함한다.
- 6번째 텍스트 레코드는 기본 프로그램 블록을 재개하고 나머지 객체 프로그램은 유사한 방식으로 계속된다.
Fig 2.14
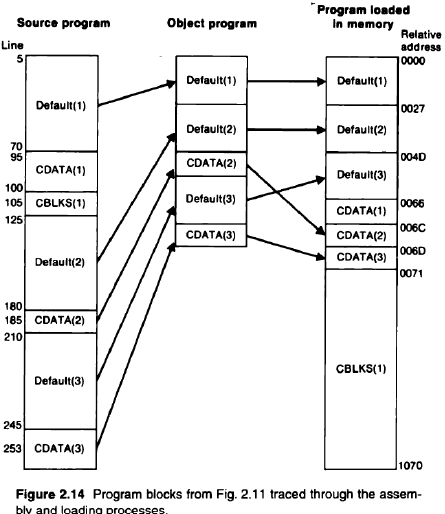
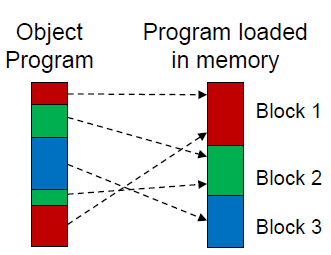
- It doesn’t matter that the Text records of the object program are not in sequence by address; the loader will simply load the object code from each record at the indicated address
- When this loading is completed, the generated code from the default block will occupy relative locations 0000 through 0065; the generated code and reserved storage for CDATA will occupy locations 0066 through 0070; the storage reserved for CBLKS will occupy locations 0071 through 1070
- 오브젝트 프로그램의 텍스트 레코드가 주소별로 순서가 아니더라도 상관 없다. 로더는 표시된 주소의 각 레코드에서 오브젝트 코드를 로드하기만 하면 된다.
- 이 로드가 완료되면 기본 블록에서 생성된 코드가 상대 위치 0000 ~ 0065를 차지하게 되고, CDATA에 대해 생성된 코드 및 예약된 저장소는 위치 0066 ~ 0070을 차지하게 되며, CBLKS에 예약된 저장소는 위치 0071 ~ 1070을 차지하게 된다.
Use directive로 program block을 저장하고, object program에서는 그 순서를 따르게 된다. 이에 대한 object code는 존재하지 않는다. 실행시킬 때 loader가 program block별로 나누어서 load하게 된다.
Advantages of Using Program blocks
- To satisfy the contradictive goals
- Separate the program into blocks in a particular order
- Large buffer area is moved to the end of the object program
- Using the extended format instructions or base relative mode may be reduced. (lines 15, 35, and 65)
- Placement of literal pool is easier: simply put literals in CDATA block, before the large data area. (line 253)
- As a result, programmers can reduce their care for using such features.
- Data areas are scattered
- Program readability is better if data areas are placed in the source program close to the statements that refer to them.
- 모순된 목표를 충족시키기 위해 (동시에!)
- 프로그램을 특정 순서로 블록으로 구분한다.
- 큰 버퍼 영역이 개체 프로그램의 끝으로 이동된다.
- 확장 포맷 명령 또는 기본 상대 모드를 사용하면 감소될 수 있다. (15, 35 및 65번 라인)
- 리터럴 풀을 배치하는 것이 더 쉽다. CDATA 블록에 리터럴을 큰 데이터 영역 앞에 놓기만 하면 된다. (253번 라인)
- 결과적으로, 프로그래머들은 그러한 기능들을 사용하는 것에 대한 그들의 관심을 줄일 수 있다.
- 데이터 영역이 분산되어 있음
- 데이터 영역이 소스 프로그램에 참조하는 문에 가깝게 배치되면 프로그램 가독성이 향상된다.
모순된 목표 충족
1) 프로그램을 특정 순서로 블록 구분
2) 데이터 영역 분산 -> 가독성 향상
리터럴 밸류를 끝으로 안보내기 위해 format 4 instruction을 사용해야 했다. 하지만 literal value들을 c data block에 모아준다면. 프로그램 끝에 존재하는 것이 아니다. PC relative만으로도 접근할 수 있다.
buffer와 instruction을 가까이 놓아도 실제 메모리에 loading 될 때는 멀어진다. 첫 번째 goal까지 같이 달성할 수 있다.
