Machine-Independent Assembler Features
- There are some common assembler features that are notclosely related to machine architecture
- The presence or absence of such features is much more closely related to issues such as programmer convenience and software environment than it is to machine architecture
- 기계 아키텍처와 밀접한 관련이 없는 몇 가지 일반적인 어셈블러 기능이 있다.
- 이러한 기능의 유무는 기계 아키텍처보다 프로그래머의 편의성 및 소프트웨어 환경과 같은 문제와 훨씬 더 밀접하게 관련되어 있다.
- 5 features are introduced in our textbook (Chapter 2.3)
Literals, Symbol definitions, Expressions, Program blocks, Control sections
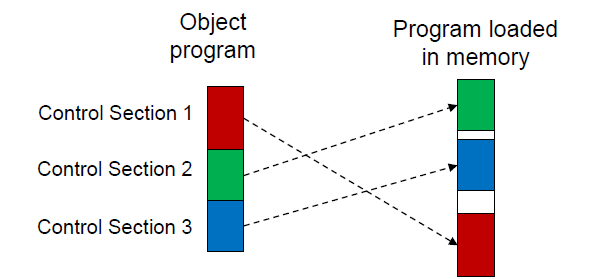
Control Section
- It is a part of program that maintains its identity after assembly; each such control section can be loaded and relocated independently of the others
- Different control sections are most often used for subroutines or other logical subdivisions of a program
- The programmer can assemble, load, and manipulate each of these control sections separately
- The resulting flexibilityis a major benefit of using control sections
- 조립 후 정체성을 유지하는 프로그램의 일부이며, 이러한 각 제어 섹션은 다른 섹션과 독립적으로 로드되고 재배치될 수 있다.
- 다른 제어 섹션은 서브루틴이나 프로그램의 다른 논리적인 부분들을 위해 가장 자주 사용된다.
- 프로그래머는 이러한 제어 섹션을 개별적으로 조립, 로드 및 조작할 수 있다.
- 결과적으로 유연성은 컨트롤 섹션을 사용하는 주요 이점이다.
control section.
loader가 independent하게 메모리에 올린다. 큰 메모리 공간이 연속적으로 존재하는 경우가 많지 않으므로 loader가 control section에 independant하게 load할 수 있다면 파편화된 메모리 상태에서도 잘 로딩할 수 있다.
"유연성"
Program Linking
- When control sections form logically related parts of a program, it is necessary to provide some means for linking them together.
- Instructions in one control section(CS) might need to refer to instructions or data located in another section.
- However, the assembler is unable toprocess these references because CSs are independently loaded and relocated.
- Such references between CSs are called “external references”.
- The assembler has no idea where any other CS will be located at execution time, so it just generates information for each external reference that will allow the loader to perform the required linking
- 제어 섹션이 프로그램의 논리적으로 관련된 부분을 형성할 때, 이들을 서로 연결하기 위한 수단을 제공할 필요가 있다.
- 한 제어 섹션의 명령은 다른 섹션에 있는 명령 또는 데이터를 참조해야 할 수 있다.
- 그러나 CS가 독립적으로 로드되고 재배치되기 때문에 어셈블러는 이러한 참조를 처리할 수 없다.
- 이러한 CS 간의 참조를 "외부 참조"라고 한다.
- 어셈블러는 실행 시 다른 CS가 어디에 위치할지 모르기 때문에 로더가 필요한 링크를 수행할 수 있도록 각 외부 참조에 대한 정보만 생성한다.
(CS = control section)
제어 섹션 논리적으로 연결된 부분.
다른 control section의 데이터 접근하기 위한 external reference
외부 참조 정보만 생성한다.
Fig. 2.15 & 16
- Here, we describe how external references are handled by our assembler.
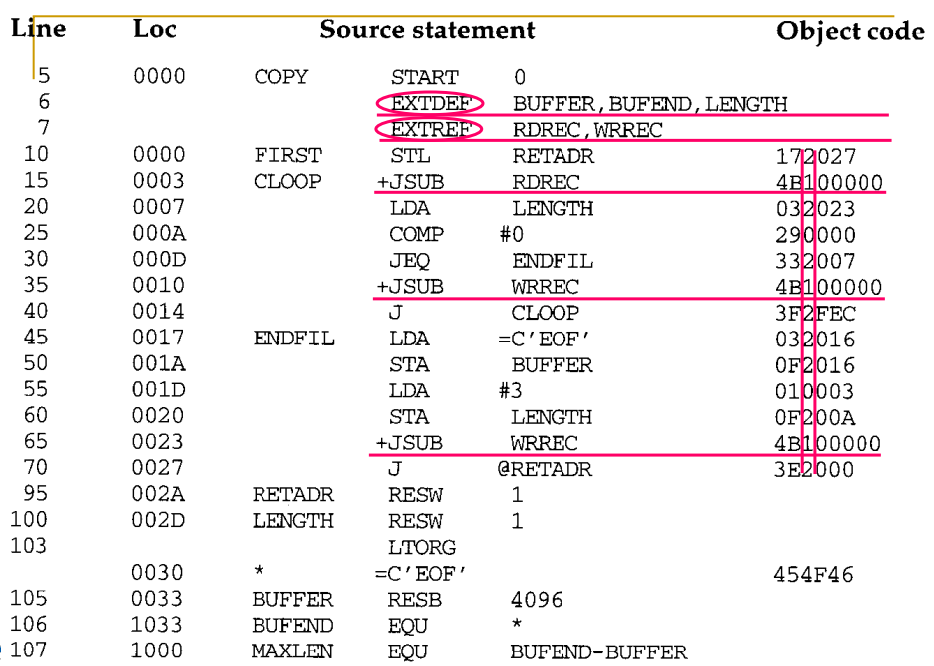
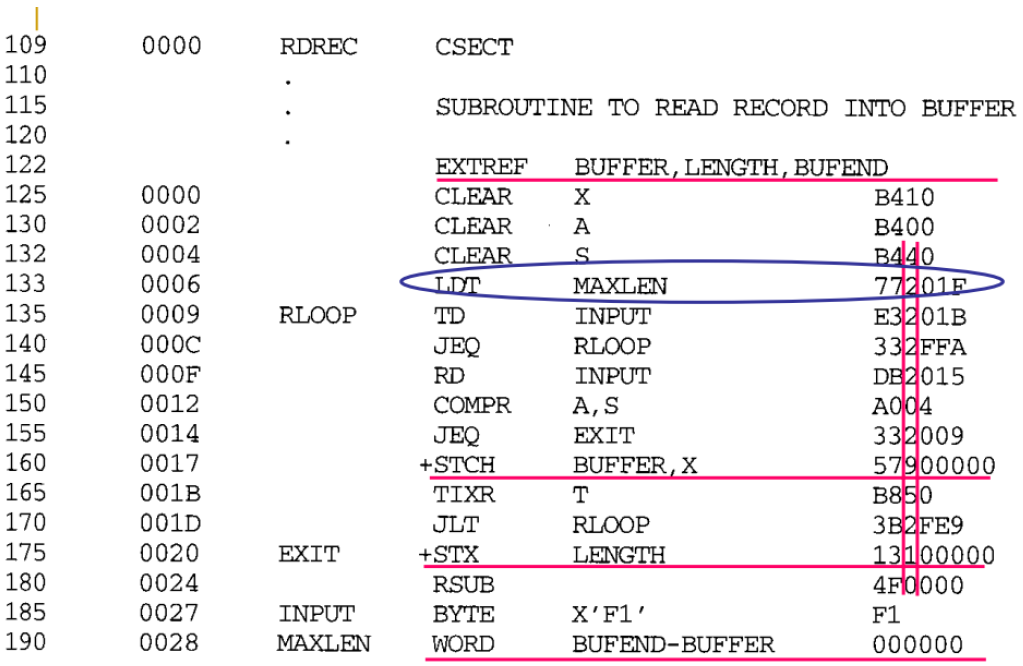
- Figures 2.15 and 16 show an example program using 3 control sections: one for the main program and one for each subroutine
- CSECT: assembly directive to signal the start of a new CS
- EXTDEF: assembly directive to name symbols defined in a CS, used by other section
- Such symbols are called external symbols
- Control section names are automatically considered to be external symbols
- EXTREF: assembly directive to name symbols used in a CS, defined elsewhere
- The assembler establishes a separate LOC for each CS, just as it does for program blocks.
- 여기서는 외부 참조가 어셈블러에 의해 처리되는 방법을 설명한다.
- 그림 2.15와 16은 3개의 제어 섹션(메인 프로그램용 및 각 서브루틴용)을 사용한 프로그램의 예를 보여준다.
- CSECT: 새로운 CS의 시작을 알리는 assembly directive
- EXTDEF: CS에 정의된 기호를 명명하기 위한 assembly directive, 다른 섹션에서 사용
- 이러한 기호를 external symbols라고 한다.
- control section 이름은 자동으로 external symbols로 간주된다.
- EXTREF: CS에서 사용되는 기호를 명명하기 위한 assembly directive, 다른 곳에서 정의
- 어셈블러는 프로그램 블록과 마찬가지로 각 CS에 대해 별도의 LOC를 설정한다.
CSECT: CS 시작
EXTDEF: CS에 정의된 기호 명명, 다른 섹션에서 사용
EXTREF: CS에 사용되는 기호 명명, 다른 곳에서 정의
Fig 2.16

How to handle External References?
- The assembler has no ideawhere the CS containing an external reference (e.g., RDREC) will be loaded, so it cannot assemble the address for the reference.
- Instead, the assembler insertsan address of 0 and passes information to the loader, so the proper address can be inserted at load time.
- [e.g.] CLOOP +JSUB RDREC 4B100000
- [e.g.] +STCH BUFFER,X 57900000
- An extended format instruction (i.e., format 4) must be used to provide room for the actual address to be inserted.
- Relative addressing (i.e., format 3) is not possible
- 어셈블러는 외부 참조(예: RDREC)를 포함하는 CS가 어디에 로드될지 모르기 때문에 참조에 대한 주소를 assemble할 수 없다.
- 대신 어셈블러는 0 주소를 삽입하고 로더에 정보를 전달하므로 로드 시 적절한 주소를 삽입할 수 있다.
- [예] CLOP +JSUB RDREC 4B100000
- [예] +STCH BUFFER,X 57900000
- 확장 형식 지침(예: 형식 4)을 사용하여 실제 주소를 삽입할 공간을 제공해야 한다.
- 상대 주소 지정(예: 형식 3)은 불가능하다.
CS 어디에 로드될지 모름
어셈블러는 0 주소를 삽입하고 로더에 정보 전달. 로드시 적절한 주소 삽입 가능. (번역하는 대신 0으로 채워두고 정보를 알려준다. 얘가 external symbol이야. 여기에 출력해야해.)
format4를 사용하여 실제 주소를 삽입할 공간을 제공해야 한다. (무조건) (control section이 어디에 배치될지 모르니까 format 4를 사용해야 한다.)
New Record Types
- The assembler must include information in the object program that will cause the loader to insert the proper values where they are required.
- Define record:
- For external symbols defined in the control section by EXTDEF
- Indicates the relative address of each external symbol within this control section
- Refer record:
- For external symbols used in the control section by EXTREF
- No address information is available
- 어셈블러는 로더가 필요한 곳에 적절한 값을 삽입하도록 하는 정보를 객체 프로그램에 포함해야 한다.
- 레코드 정의:
- EXTDEF에 의해 제어 섹션에 정의된 외부 기호의 경우
- 이 제어 섹션에 있는 각 외부 기호의 상대 주소를 나타낸다.
- 참조 레코드:
- EXTREF에 의해 제어 섹션에 사용되는 외부 기호의 경우
- 사용 가능한 주소 정보가 없다.
둘의 차이를 이해하기.
Definde record는 control section에서 정의한 export하기 위해 사용하는 external symbol.
Refer record는 반대로 control section이 다른 control section에 정의된 것을 사용하려고 할 때.
Record Types
- Define record (EXTDEF)
- Col. 1 D
- Col. 2-7 Name of external symbol defined in this control section
- Col. 8-13 Relative address within this control section (hexadecimal)
- Col.14-73 Repeat information in Col. 2-13 for other external symbols
- Refer record (EXTREF)
- Col. 1 R
- Col. 2-7 Name of external symbol referred to in this control section
- Col. 8-73 Names of other external reference symbols
- Modification record (revised)
- Col. 1 M
- Col. 2-7 Starting address of the field to be modified (hexadecimal)
- Col. 8-9 Length of the field to be modified, in half-bytes (hexadecimal)
- Col. 10 Modification flag (+ or -)
- Col.11-16 External symbol whose value is to be added to or subtracted from the indicated field
Fig. 2.17



record 집합이 control section만큼 존재한다. external symbol을 사용하는 instruction이다. handle하기 위해 만들어진 modification record가 M.
external 처리가 완료되었다.
+면 더하고 -면 빼고.. 직관적이다.
Control Section and Program Linking
- Loader
- For every external symbol
- Find the relative address from the define record
- Add the starting address of the control section where the symbol is defined
- Modify the field
- More details will be covered later!
- For every external symbol
- Loader
- 모든 외부 기호에 대해
- 정의 레코드에서 상대 주소 찾기
- 기호가 정의된 제어 섹션의 시작 주소 추가
- 필드 수정
- 자세한 내용은 나중에 다룬다
- 모든 외부 기호에 대해
loader는 모든 외부 기호에 대해 상대 주소 찾기, 제어 섹션 시작 주소 추가, 필드 수정을 한다.
Assembler Design Option
- 2-pass assembler scans source code twice!
- First, to produce a symbol table and secondly to produce object codes.
- Is this the only way to design an assembler?
- Of course, NOT… We can make it with the 1-pass algorithm or even a multi-pass algorithm!
- In this lecture, we will just study on the “one-pass assembler”, which scans the source code only one time (-> avoids the overhead of an additional pass over the source program) but often must patch the object code produced during this scan.
- 2-pass assembler가 소스 코드를 두 번 스캔합니다!
- 첫째, 심볼 테이블을 생성하고 둘째, 객체 코드를 생성한다.
- 이것이 조립기를 설계하는 유일한 방법인가?
- 물론, 아니다… 우리는 1 pass 알고리즘이나 심지어 multi-pass 알고리즘으로도 만들 수 있다.
- 이 강의에서는 소스 코드를 한 번만 스캔하지만(-> 소스 프로그램을 통한 추가 패스의 오버헤드를 피함) 종종 이 스캔 중에 생성된 객체 코드를 패치해야 하는 "one-pass assembler"에 대해 공부한다.
2-pass assembler가 소스 코드를 두 번 스캔. 1) symbol table 생성 2) object code 생성
one-pass assembler, n-pass assembler를 만들 수 있다.
One-Pass Assemblers
- Two different types
- Type I “Load-and-Go Assembler”: produces object code directly in memoryfor immediate execution, with no object program written out, and no loader needed.
- Type II: produces the usual kind of object programfor later execution, so object program is produced, and loader is yet needed.
- The main problem in trying to assemble a program in one pass involves “forward references”
- Instruction operands often are symbols that have not yet been defined in the source program. Thus, the assembler does not know what address to be inserted into the translated instruction
- 두 가지 다른 유형
- Type I "Load-and-Go Assembler": 는 즉시 실행을 위해 메모리에 직접 객체 코드를 생성하며, 객체 프로그램을 작성하거나 로더 없이 즉시 실행할 수 있다.
- Type II: 나중에 실행할 수 있도록 일반적인 종류의 객체 프로그램을 생성하므로 객체 프로그램이 생성되고 로더가 여전히 필요하다.
- 하나의 패스로 프로그램을 조립하는 데 있어 주된 문제는 "순방향 참조"이다.
- 명령 피연산자는 종종 소스 프로그램에서 아직 정의되지 않은 기호이다. 따라서 어셈블러는 번역된 명령어에 어떤 주소를 삽입해야 할지 모른다.
Type 1: Load-and-Go Assembler. 직접 object code 생성. 즉시 실행
Type 2: 객체 프로그램 생성
두 가지 타입으로 만들 수 있다. 해당 object program을 만드느냐 만들지 않냐. type1,2 모두 forward reference를 해결해야 한다.
Fig. 2.18
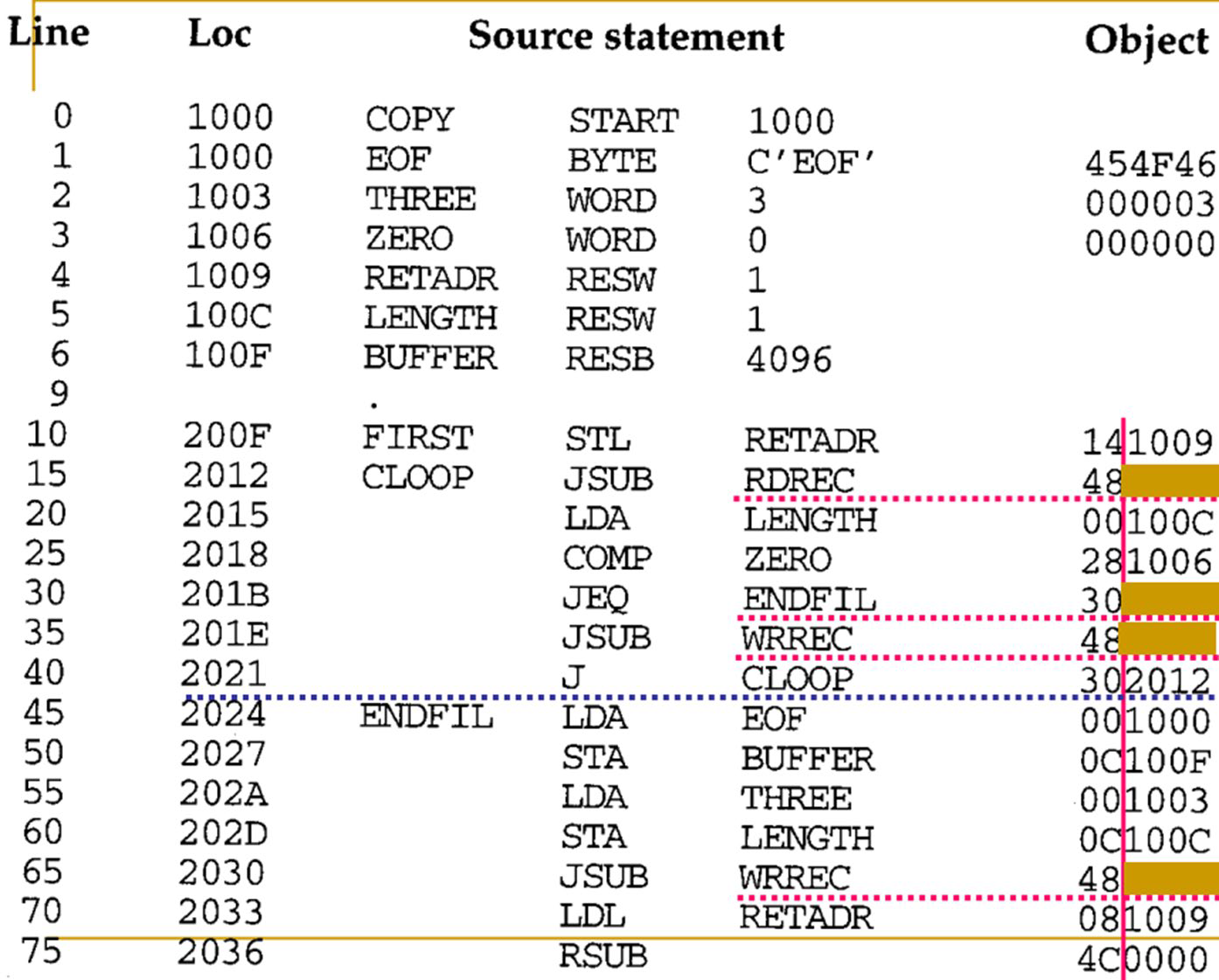
- Sample program for a one-pass assembler
- It has the same logic as in Fig. 2.2 for SIC
- All data item definitions are placed ahead of instructionsthat references them in order to eliminate forward references to the data items
- However, forward references to labels on instructions cannot be eliminated as easily.
- E.g., line 15, 30, 35, 65, and 155
- How can Type 1 & 2 one-pass assemblers address this issue?
- one-pass assembler를 위한 샘플 프로그램
- SIC에 대한 그림 2.2와 동일한 논리를 가지고 있다.
- 데이터 항목에 대한 순방향 참조를 제거하기 위해 모든 데이터 항목 정의가 해당 데이터 항목을 참조하는 명령 앞에 배치된다.
- 그러나 지침의 라벨에 대한 전방 참조는 쉽게 제거할 수 없다.
- 예: line 15, 30, 35, 65 및 155
- Type 1 및 2 one-pass 어셈블러는 이 문제를 어떻게 해결할 수 있는가?


Type I One-Pass Assemblers: “Load-and-Go”
- Useful in a system that is oriented toward program development & testing.
- Programs are re-assembled nearly every time they are run.
- The load-and-go assembler produces the object code in memory rather than writing it out on secondary storage
- Efficiency of the assembly process ↑
- How to solve forward references?
- Store undefined symbols in the SYMTAB with the address of the field that references this symbol
- When the symbol is defined later, look up the SYMTAB and modify the field with correct address
- 프로그램 개발 및 테스트를 지향하는 시스템에 유용하다.
- 프로그램은 거의 매번 실행될 때마다 다시 조립된다.
- 로드 앤 고 어셈블러는 보조 스토리지에 객체 코드를 기록하는 대신 메모리에 객체 코드를 생성한다.
- 조립 공정의 효율성 ↑
- 정방향 참조는 어떻게 해결하는가?
- 이 기호를 참조하는 필드 주소와 함께 정의되지 않은 기호를 SYMTAB에 저장
- 기호가 나중에 정의되면 SYMTAB를 찾아 올바른 주소로 필드를 수정한다.
실행될 때마다 re-assembled
메모리에 object code 생성
forward reference는 SYMTAB에 정의되지 않은 기호를 저장함으로써 해결한다.
Fig. 2.19(a)
- Object code in memory & symbol table entries for the program in Figure 2.18 after scanning line 40
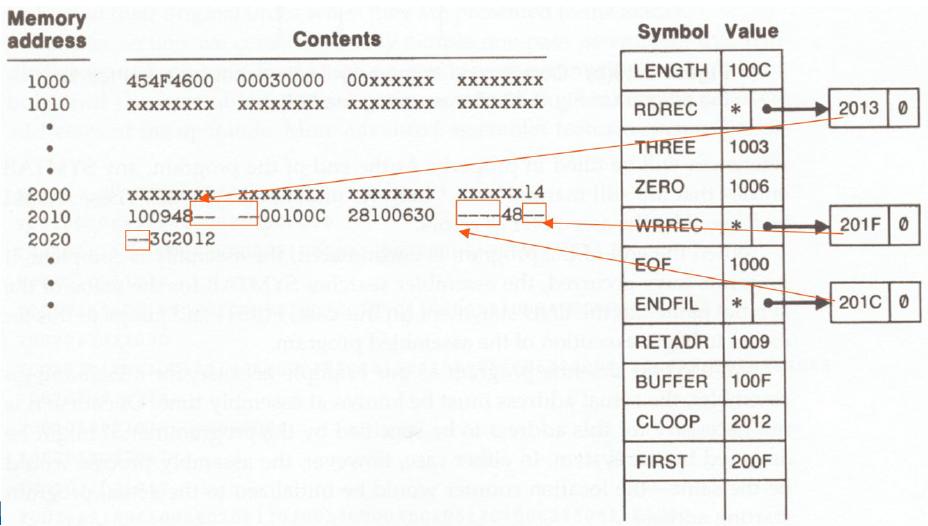
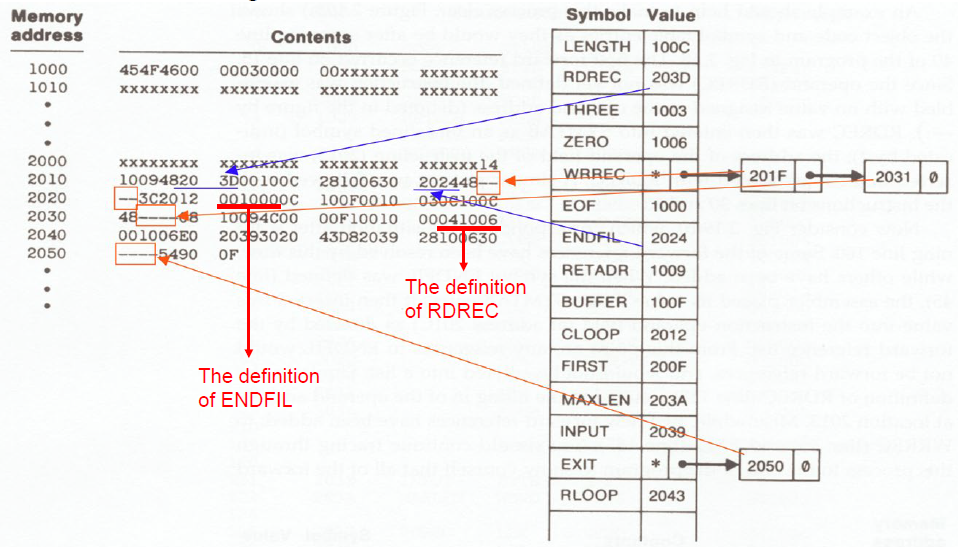
Fig. 2.19(b)
- Object code in memory & symbol table entries for the program in Figure 2.18 after scanning line 160
Type II One-Pass Assemblers
- Writes the object program on disk
- How to solve forward references?
- Forward references are entered into lists as before.
- When the definition of a symbol is encountered, generate another Text records with correct operand address
- When loaded, correct address will be inserted by loader
- 디스크에 개체 프로그램을 쓴다.
- 순방향 참조는 어떻게 해결하는가?
- 순방향 참조는 이전과 같이 목록에 입력된다.
- 기호의 정의가 발견되면 올바른 피연산자 주소를 가진 다른 텍스트 레코드를 생성한다.
- 로드되면 로더를 통해 올바른 주소가 삽입된다.
object program을 쓴다.
forward reference는 list에 입력하고, 정의 발견되면 다른 text record를 생성하고, load하면 loader를 통해 올바른 주소가 삽입되는 방식으로 해결한다.
Fig. 2. 20
- Object program from one-pass assembler for program in Figure 2.18
- The 2nd Text record contains the object code generated from line 10 through 40
- When the definition of ENDFIL on line 45 is encountered, the assembler generates the 3rd Text record -> This specifies that the value 2024 (the address of ENDFIL) is to be loaded at location 201C (the operand address field of the JEQ on line 30)
- 그림 2.18의 프로그램에 대한 원패스 어셈블러의 객체 프로그램
- 두 번째 텍스트 레코드는 라인 10에서 40까지 생성된 객체 코드를 포함한다.
- 라인 45의 ENDFIL 정의가 발견되면 어셈블러는 3번째 텍스트 레코드를 생성한다. -> 이것은 값 2024(ENDFIL의 주소)가 위치 201C(라인 30의 JEQ의 피연산자 주소 필드)에 로드되도록 지정한다.

address value of field, eof symbol
text record를 어떻게 구분하는가.
instruction에 할당된 다음 주소값이 할당되어있다.
