Overview of Mass Storage Structure
- Bulk of secondary storage for modern computers is hard disk drives (HDDs) and nonvolatile memory (NVM) devices
- HDDs spin platters of magnetically-coated material under moving read-write heads
- Drives rotate at 60 to 250 times per second
- Transfer rate is rate at which data flow between drive and computer
- Positioning time (random-access time) is time to move disk arm to desired cylinder (seek time) and time for desired sector to rotate under the disk head (rotational latency)
- Head crash results from disk head making contact with the disk surface -- That’s bad
- Disks can be removable
- 현대 컴퓨터의 보조 스토리지의 대부분은 하드 디스크 드라이브(HDD) 및 비휘발성 메모리(NVM) 장치이다.
- HDD는 움직이는 읽기-쓰기 헤드 아래에서 자기 코팅된 재료의 플래터를 회전시킨다.
- 드라이브 회전 속도가 초당 60~250회수
- 전송 속도는 드라이브와 컴퓨터 간의 데이터 흐름 속도이다.
- 포지셔닝 시간(랜덤 액세스 시간)은 디스크 암을 원하는 실린더로 이동하는 시간(시킹 시간)과 디스크 헤드 아래에서 원하는 섹터가 회전하는 시간(회전 대기 시간)이다.
- 헤드 충돌은 디스크 헤드가 디스크 표면과 접촉할 때 발생한다. -- 그것은 좋지 않다.
- 디스크를 이동할 수 있다.
Moving-head Disk Mechanism
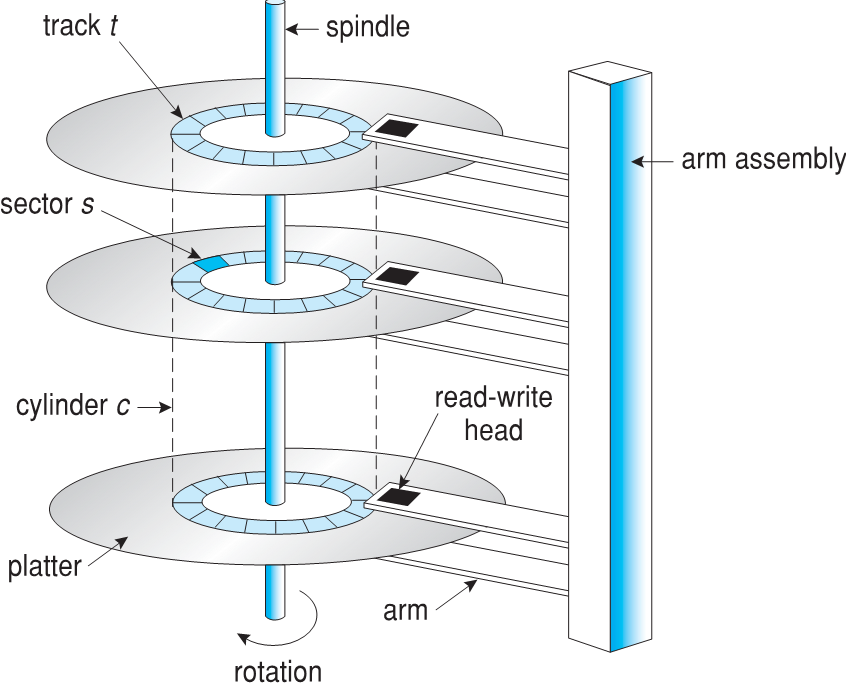
Hard Disk Drives
- Platters range from .85” to 14” (historically)
- Commonly 3.5”, 2.5”, and 1.8”
- Range from 30GB to 3TB per drive
- Performance
- Transfer Rate – theoretical – 6 Gb/sec
- Effective Transfer Rate – real – 1Gb/sec
- Seek time from 3ms to 12ms – 9ms common for desktop drives
- Average seek time measured or calculated based on 1/3 of tracks
- Latency based on spindle speed
- 1 / (RPM / 60) = 60 / RPM
- Average latency = ½ latency
- 플래터의 범위는 .85" ~ 14"이다. (역사적)
- 일반적으로 3.5인치, 2.5인치 및 1.8인치
- 드라이브당 30GB ~ 3TB 범위
- 성과
- 전송 속도 – 이론적 – 6Gb/sec
- 유효 전송 속도 – 실제 – 1Gb/sec
- 데스크톱 드라이브의 경우 3ms ~ 12ms – 9ms의 일반적인 탐색 시간
- 트랙의 1/3을 기준으로 측정 또는 계산된 평균 탐색 시간
- 스핀들 속도에 따른 대기 시간
- 1 / (RPM / 60) = 60 / RPM
- 평균 대기 시간 = ½ 지연 시간
Hard Disk Performance
- Access Latency = Average access time = average seek time + average latency
- For fastest disk 3ms + 2ms = 5ms
- For slow disk 9ms + 5.56ms = 14.56ms
- Average I/O time = average access time + (amount to transfer / transfer rate) + controller overhead
- For example to transfer a 4KB block on a 7200 RPM disk with a 5ms average seek time, 1Gb/sec transfer rate with a .1ms controller overhead =
- 5ms + 4.17ms + 0.1ms + transfer time =
- Transfer time = 4KB / 1Gb/s 8Gb / GB 1GB / 10242KB = 32 / (10242) = 0.031 ms
- Average I/O time for 4KB block = 9.27ms + .031ms = 9.301ms
- 액세스 대기 시간 = 평균 액세스 시간 = 평균 검색 시간 + 평균 대기 시간
- 가장 빠른 디스크의 경우 3ms + 2ms = 5ms
- 저속 디스크의 경우 9ms + 5.56ms = 14.56ms
- 평균 I/O 시간 = 평균 액세스 시간 + (전송/전송 속도 양) + 컨트롤러 오버헤드
- 예를 들어 평균 탐색 시간이 5ms인 7200RPM 디스크에서 4KB 블록을 전송하고 컨트롤러 오버헤드가 .1ms인 전송 속도가 1Gb/s인 경우 =
- 5ms + 4.17ms + 0.1ms + 전송 시간 =
- 전송 시간 = 4KB / 1Gb/s 8Gb / GB 1GB / 10242KB = 32 / (512) = 0.031ms
- 4KB 블록의 평균 I/O 시간 = 9.27ms + .031ms = 9.195ms
The First Commercial Disk Drive

Nonvolatile Memory Devices
- If disk-drive like, then called solid-state disks (SSDs)
- Other forms include USB drives (thumb drive, flash drive), DRAM disk replacements, surface-mounted on motherboards, and main storage in devices like smartphones
- Can be more reliable than HDDs
- More expensive per MB
- Maybe have shorter life span – need careful management
- Less capacity
- But much faster
- Busses can be too slow -> connect directly to PCI for example
- No moving parts, so no seek time or rotational latency
- 디스크 드라이브의 경우 SSD(Solid-State Disks)라고 한다.
- 다른 형태로는 USB 드라이브(썸 드라이브, 플래시 드라이브), DRAM 디스크 교체, 마더보드에 표면 장착, 스마트폰과 같은 장치의 메인 스토리지 등이 있다.
- HDD보다 더 안정적일 수 있다.
- MB당 더 비싸다.
- 수명이 더 짧을 수 있다. – 세심한 관리 필요
- 비교적 적은 용량
- 하지만 훨씬 더 빠르다.
- 버스 속도가 너무 느릴 수 있다 -> PCI에 직접 연결합니다(예)
- 움직이는 부품이 없으므로 탐색 시간이나 회전 대기 시간이 없다.
- Have characteristics that present challenges
- Read and written in “page” increments (think sector) but can’t overwrite in place
- Must first be erased, and erases happen in larger ”block” increments
- Can only be erased a limited number of times before worn out – ~ 100,000
- Life span measured in drive writes per day (DWPD)
- A 1TB NAND drive with rating of 5DWPD is expected to have 5TB per day written within warrantee period without failing
- 과제를 제시하는 특성을 갖춤
- "페이지" 단위로 읽고 쓰지만(생각 섹터) 제 자리에서 덮어쓸 수 없음
- 먼저 지워야 하며 삭제는 더 큰 "블록" 증분으로 발생한다.
- 마모되기 전에 제한된 횟수만 지울 수 있다. – ~ 100,000
- 일일 드라이브 쓰기(DWPD) 단위로 측정된 수명
- 5DWPD 등급의 1TB NAND 드라이브는 보증 기간 내에 고장 없이 하루에 5TB가 기록될 것으로 예상된다.

NAND Flash Controller Algorithms
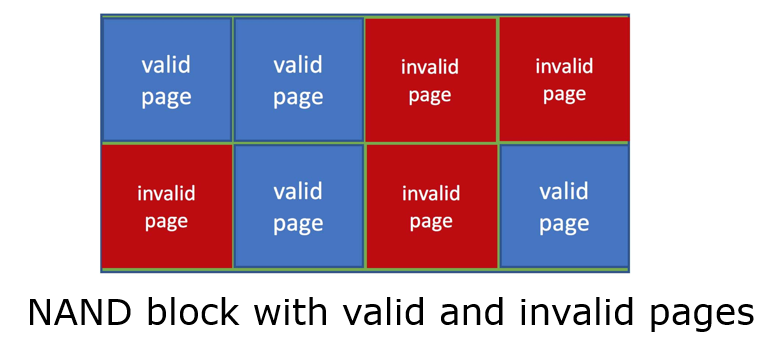
- With no overwrite, pages end up with mix of valid and invalid data
- To track which logical blocks are valid, controller maintains flash translation layer (FTL) table
- Also implements garbage collection to free invalid page space
- Allocates overprovisioning to provide working space for GC
- Each cell has lifespan, so wear leveling needed to write equally to all cells
- 덮어쓰기를 하지 않으면 페이지에 유효한 데이터와 유효하지 않은 데이터가 혼합된다.
- 유효한 논리 블록을 추적하기 위해 컨트롤러는 FTL(Flash Translation Layer) 테이블을 유지 관리한다.
- 또한 잘못된 페이지 공간을 확보하기 위해 가비지 컬렉션을 구현한다.
- GC를 위한 작업 공간을 제공하기 위해 초과 프로비저닝 할당한다.
- 각 셀에는 수명이 있으므로 마모 레벨링은 모든 셀에 동일하게 기록해야 한다.
Volatile Memory
- DRAM frequently used as mass-storage device
- Not technically secondary storage because volatile, but can have file systems, be used like very fast secondary storage
- RAM drives (with many names, including RAM disks) present as raw block devices, commonly file system formatted
- Computers have buffering, caching via RAM, so why RAM drives?
- Caches / buffers allocated / managed by programmer, operating system, hardware
- RAM drives under user control
- Found in all major operating systems
- Linux /dev/ram, macOS diskutil to create them, Linux /tmp of file system type tmpfs
- Used as high speed temporary storage
- Programs could share bulk date, quickly, by reading/writing to RAM drive
- 대량 저장 장치로 자주 사용되는 DRAM
- 휘발성이기 때문에 기술적으로 보조 스토리지가 아니지만 파일 시스템을 가질 수 있으며 매우 빠른 보조 스토리지처럼 사용된다.
- RAM 드라이브(RAM 디스크를 포함한 많은 이름 포함)가 원시 블록 장치로 존재하며, 일반적으로 파일 시스템 포맷된다.
- 컴퓨터에는 RAM을 통한 버퍼링, 캐싱이 있는데, 왜 RAM 드라이브를 사용하는가?
- 캐시/버퍼 할당/프로그래머, 운영 체제, 하드웨어에 의해 관리
- 사용자가 제어하는 RAM 드라이브
- 모든 주요 운영 체제에서 발견됨
- Linux /dev/ram, macOS diskutil to create its, 파일 시스템 유형 tmpfs의 Linux /tmp
- 고속 임시 저장소로 사용
- 프로그램은 RAM 드라이브에 읽기/쓰기를 통해 대량 날짜를 빠르게 공유할 수 있다.
Magnetic Tape

Disk Structure
- Disk drives are addressed as large 1-dimensional arrays of logical blocks, where the logical block is the smallest unit of transfer
- Low-level formatting creates logical blocks on physical media
- The 1-dimensional array of logical blocks is mapped into the sectors of the disk sequentially
- Sector 0 is the first sector of the first track on the outermost cylinder
- Mapping proceeds in order through that track, then the rest of the tracks in that cylinder, and then through the rest of the cylinders from outermost to innermost
- Logical to physical address should be easy
- Except for bad sectors
- Non-constant # of sectors per track via constant angular velocity
- 디스크 드라이브는 논리 블록의 대형 1차원 배열로 지정되며, 논리 블록은 전송 단위가 가장 작다.
- 낮은 수준의 포맷으로 물리적 미디어에 논리적 블록 생성
- 논리 블록의 1차원 배열이 디스크의 섹터에 순차적으로 매핑된다.
- 섹터 0은 가장 바깥쪽 실린더에 있는 첫 번째 트랙의 첫 번째 섹터이다.
- 매핑은 해당 트랙을 순서대로 통과한 다음, 해당 실린더의 나머지 트랙을 통과한 다음, 가장 바깥쪽에서 가장 안쪽까지 나머지 실린더를 통과한다.
- 논리적/물리적 주소는 간단해야 한다.
- 불량 섹터 제외
- 일정한 각속도를 통한 트랙당 일정하지 않은 섹터 수
Disk Attachment
- Host-attached storage accessed through I/O ports talking to I/O busses
- Several busses available, including advanced technology attachment (ATA), serial ATA (SATA), eSATA, serial attached SCSI (SAS), universal serial bus (USB), and fibre channel (FC).
- Most common is SATA
- Because NVM much faster than HDD, new fast interface for NVM called NVM express (NVMe), connecting directly to PCI bus
- Data transfers on a bus carried out by special electronic processors called controllers (or host-bus adapters, HBAs)
- Host controller on the computer end of the bus, device controller on device end
- Computer places command on host controller, using memory-mapped I/O ports
- Host controller sends messages to device controller
- Data transferred via DMA between device and computer DRAM
- I/O 버스와 통신하는 I/O 포트를 통해 액세스되는 호스트 연결 스토리지
- 고급 기술 연결(ATA), 직렬 ATA(SATA), eSATA, 직렬 연결 SCSI(SAS), 범용 직렬 버스(USB) 및 파이버 채널(FC)을 포함한 여러 버스를 사용할 수 있다.
- 가장 일반적인 것은 SATA이다.
- NVM이 HDD보다 훨씬 빠르기 때문에 NVM 익스프레스(NVMe)라는 NVM용 새로운 빠른 인터페이스로 PCI 버스에 직접 연결된다.
- 컨트롤러(또는 호스트 버스 어댑터, HBA)라고 하는 특수 전자 프로세서에 의해 수행되는 버스에서의 데이터 전송
- 버스의 컴퓨터 끝에는 호스트 컨트롤러, 장치 끝에는 디바이스 컨트롤러
- 메모리에 매핑된 I/O 포트를 사용하여 호스트 컨트롤러에 명령 실행
- 호스트 컨트롤러가 디바이스 컨트롤러로 메시지 전송
- 장치와 컴퓨터 DRAM 간에 DMA를 통해 전송되는 데이터
Address Mapping
- Disk drives are addressed as large 1-dimensional arrays of logical blocks, where the logical block is the smallest unit of transfer
- Low-level formatting creates logical blocks on physical media
- The 1-dimensional array of logical blocks is mapped into the sectors of the disk sequentially
- Sector 0 is the first sector of the first track on the outermost cylinder
- Mapping proceeds in order through that track, then the rest of the tracks in that cylinder, and then through the rest of the cylinders from outermost to innermost
- Logical to physical address should be easy
- Except for bad sectors
- Non-constant # of sectors per track via constant angular velocity
- 디스크 드라이브는 논리 블록의 대형 1차원 배열로 지정되며, 논리 블록은 전송 단위가 가장 작다.
- 낮은 수준의 포맷으로 물리적 미디어에 논리적 블록 생성
- 논리 블록의 1차원 배열이 디스크의 섹터에 순차적으로 매핑된다.
- 섹터 0은 가장 바깥쪽 실린더에 있는 첫 번째 트랙의 첫 번째 섹터이다.
- 매핑은 해당 트랙을 순서대로 통과한 다음, 해당 실린더의 나머지 트랙을 통과한 다음, 가장 바깥쪽에서 가장 안쪽까지 나머지 실린더를 통과한다.
- 논리적/물리적 주소는 간단해야 한다.
- 불량 섹터 제외
- 일정한 각속도를 통한 트랙당 일정하지 않은 섹터 수
HDD Scheduling
- The operating system is responsible for using hardware efficiently — for the disk drives, this means having a fast access time and disk bandwidth
- Minimize seek time
- Seek time -> seek distance
- Disk bandwidth is the total number of bytes transferred, divided by the total time between the first request for service and the completion of the last transfer
- 운영 체제는 하드웨어를 효율적으로 사용한다. 디스크 드라이브의 경우 빠른 액세스 시간과 디스크 대역폭을 의미한다.
- 탐색 시간 최소화
- 탐색 시간 -> 탐색 거리
- 디스크 bandwidth는 전송된 총 바이트 수를 첫 번째 서비스 요청과 마지막 전송 완료 사이의 총 시간으로 나눈 값이다.
Disk Scheduling (Cont.)
- There are many sources of disk I/O request
- OS
- System processes
- Users processes
- I/O request includes input or output mode, disk address, memory address, number of sectors to transfer
- OS maintains queue of requests, per disk or device
- Idle disk can immediately work on I/O request, busy disk means work must queue
- Optimization algorithms only make sense when a queue exists
- In the past, operating system responsible for queue management, disk drive head scheduling
- Now, built into the storage devices, controllers
- Just provide LBAs, handle sorting of requests
- Some of the algorithms they use described next
- 디스크 I/O 요청의 소스가 많다.
- 운영 체제
- 시스템 프로세스
- 사용자 프로세스
- I/O 요청에는 입력 또는 출력 모드, 디스크 주소, 메모리 주소, 전송할 섹터 수가 포함된다.
- OS가 디스크 또는 장치별로 요청 대기열을 유지 관리한다.
- 유휴 디스크는 I/O 요청에 따라 즉시 작동할 수 있으며, 사용 중인 디스크는 작업이 대기열에 있어야 함을 의미한다.
- 최적화 알고리즘은 대기열이 존재하는 경우에만 의미가 있다.
- 과거에는 대기열 관리, 디스크 드라이브 헤드 스케줄링을 담당했던 운영 체제
- 이제 스토리지 장치와 컨트롤러에 내장되어 있다.
- LBA를 제공하고 요청 정렬을 처리하기만 하면 된다.
- 그들이 사용하는 알고리즘 중 일부는 다음에 설명된다.
- Note that drive controllers have small buffers and can manage a queue of I/O requests (of varying “depth”)
- Several algorithms exist to schedule the servicing of disk I/O requests
- The analysis is true for one or many platters
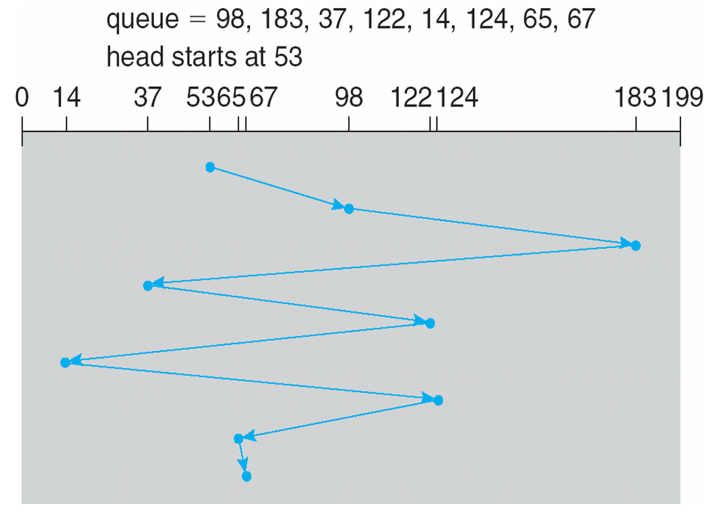
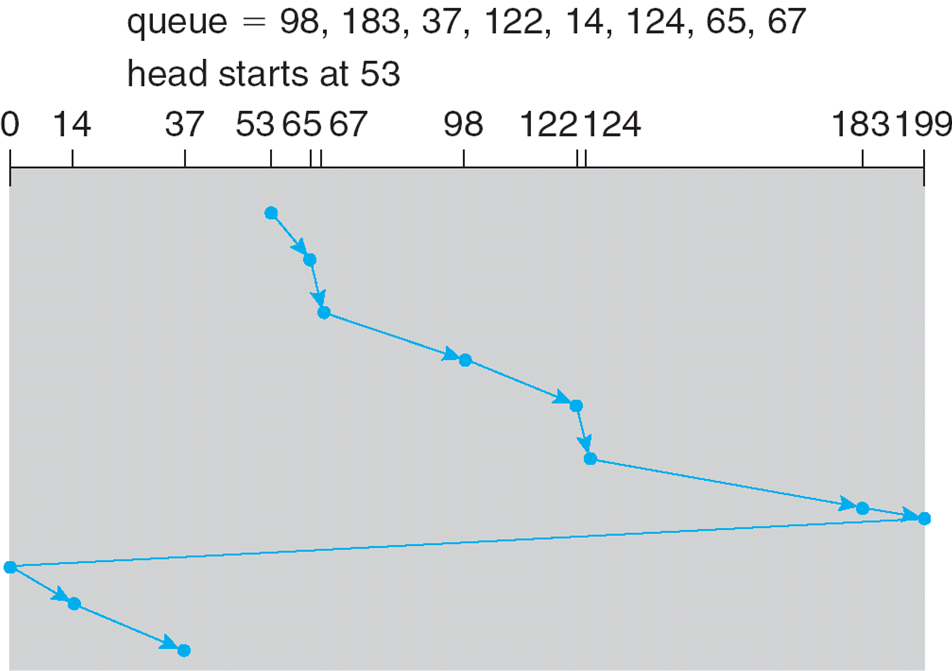
- We illustrate scheduling algorithms with a request queue (0-199)
98, 183, 37, 122, 14, 124, 65, 67
Head pointer 53
- 드라이브 컨트롤러는 버퍼가 작고 I/O 요청 대기열("깊이"가 다양함)을 관리할 수 있다.
- 디스크 I/O 요청의 서비스를 예약하기 위한 몇 가지 알고리즘이 있다.
- 이 분석은 하나 이상의 플래터에 대해 참이다.
- 요청 대기열(0-199)을 사용한 스케줄링 알고리듬을 설명한다.
98, 183, 37, 122, 14, 124, 65, 67
헤드 포인터 53
FCFS
Illustration shows total head movement of 640 cylinders
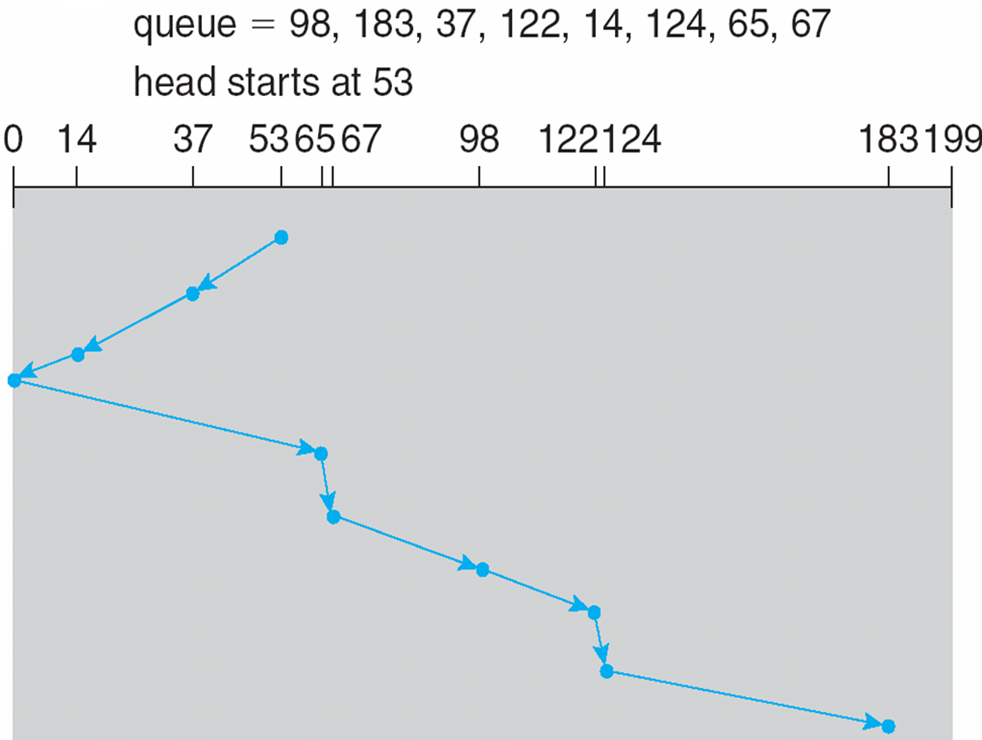
SCAN
- The disk arm starts at one end of the disk, and moves toward the other end, servicing requests until it gets to the other end of the disk, where the head movement is reversed and servicing continues.
- SCAN algorithm Sometimes called the elevator algorithm
- Illustration shows total head movement of 208 cylinders
- But note that if requests are uniformly dense, largest density at other end of disk and those wait the longest
- 디스크 암은 디스크의 한쪽 끝에서 시작하여 다른 쪽 끝으로 이동하여 요청을 처리한다. 요청은 디스크의 다른 쪽 끝에 도달할 때까지 처리된다. 여기서 헤드 움직임은 반대로 되고 서비스는 계속된다.
- SCAN 알고리즘 엘리베이터 알고리즘이라고도 한다.
- 그림에는 208개 실린더의 총 헤드 움직임이 나와 있다.
- 그러나 요청이 균일하게 밀도가 높은 경우 Disk의 다른 쪽 끝에서 가장 밀도가 높고 가장 오래 기다리는 경우
C-SCAN
- Provides a more uniform wait time than SCAN
- The head moves from one end of the disk to the other, servicing requests as it goes
- When it reaches the other end, however, it immediately returns to the beginning of the disk, without servicing any requests on the return trip
- Treats the cylinders as a circular list that wraps around from the last cylinder to the first one
- Total number of cylinders?
- SCAN보다 더 균일한 대기 시간 제공
- 헤드가 디스크의 한쪽 끝에서 다른 쪽 끝으로 이동하여 요청을 처리한다.
- 그러나 다른 쪽 끝에 도달하면 반환 여행에서 요청을 처리하지 않고 디스크의 시작 부분으로 즉시 돌아간다.
- 실린더를 마지막 실린더부터 첫 번째 실린더까지 감싸는 순환 리스트로 처리한다.
- 총 실린더 수?
Selecting a Disk-Scheduling Algorithm
- SSTF is common and has a natural appeal
- SCAN and C-SCAN perform better for systems that place a heavy load on the disk
- Less starvation, but still possible
- To avoid starvation Linux implements deadline scheduler
- Maintains separate read and write queues, gives read priority
- Because processes more likely to block on read than write
- Implements four queues: 2 x read and 2 x write
- 1 read and 1 write queue sorted in LBA order, essentially implementing C-SCAN
- 1 read and 1 write queue sorted in FCFS order
- All I/O requests sent in batch sorted in that queue’s order
- After each batch, checks if any requests in FCFS older than configured age (default 500ms)
- If so, LBA queue containing that request is selected for next batch of I/O
- Maintains separate read and write queues, gives read priority
- In RHEL 7 also NOOP and completely fair queueing scheduler (CFQ) also available, defaults vary by storage device
- SSTF는 일반적이고 자연스러운 매력이 있다.
- 디스크에 부하가 많이 걸리는 시스템의 경우 SCAN 및 C-SCAN 성능이 향상된다.
- 기아는 줄었지만, 여전히 가능하다.
- 기아를 방지하기 위해 Linux는 마감 스케줄러를 구현한다.
- 별도의 읽기 및 쓰기 대기열 유지, 읽기 우선순위 부여
- 왜냐하면 프로세스는 쓰기보다 읽기를 차단할 가능성이 높기 때문이다.
- 별도의 읽기 및 쓰기 대기열 유지, 읽기 우선순위 부여
- 읽기 2개, 쓰기 2개 등 4개 대기열 구현
- 1개의 읽기 및 1개의 쓰기 대기열이 LBA 순서로 정렬되어 기본적으로 C-SCAN
- FCFS 순서로 1개의 읽기 및 1개의 쓰기 대기열 정렬
- 해당 대기열의 순서로 정렬된 배치로 전송된 모든 I/O 요청
- 각 배치 후 FCFS에서 구성된 기간(기본값 500ms)보다 오래된 요청이 있는지 확인한다.
- 그렇다면 해당 요청을 포함하는 LBA 대기열이 다음 I/O 배치에 대해 선택된다.
- RHEL 7에서도 NOOP 및 CFQ(완전 공정 대기열 스케줄러)를 사용할 수 있으며, 기본값은 스토리지 디바이스에 따라 다릅니다.
NVM Scheduling
- No disk heads or rotational latency but still room for optimization
- In RHEL 7 NOOP (no scheduling) is used but adjacent LBA requests are combined
- NVM best at random I/O, HDD at sequential
- Throughput can be similar
- Input/Output operations per second (IOPS) much higher with NVM (hundreds of thousands vs hundreds)
- But write amplification (one write, causing garbage collection and many read/writes) can decrease the performance advantage
- Disk 헤드 또는 회전 대기 시간이 없지만 최적화를 위한 공간이 있다.
- RHEL 7에서는 NOOP(스케줄링 없음)가 사용되지만 인접 LBA 요청이 결합된다.
- 랜덤 I/O에서 가장 적합한 NVM, 순차적 HDD
- 처리량은 비슷할 수 있다.
- NVM(수십만 대 수백)을 사용할 경우 IOPS(초당 입출력 작업 수)가 훨씬 높아진다.
- 그러나 쓰기 증폭(한 번의 쓰기로 인해 가비지 수집이 발생하고 많은 읽기/쓰기)으로 인해 성능이 저하될 수 있다.
Error Detection and Correction
- Fundamental aspect of many parts of computing (memory, networking, storage)
- Error detection determines if there a problem has occurred (for example a bit flipping)
- If detected, can halt the operation
- Detection frequently done via parity bit
- Parity one form of checksum – uses modular arithmetic to compute, store, compare values of fixed-length words
- Another error-detection method common in networking is cyclic redundancy check (CRC) which uses hash function to detect multiple-bit errors
- Error-correction code (ECC) not only detects, but can correct some errors
- Soft errors correctable, hard errors detected but not corrected
- 컴퓨팅의 많은 부분(메모리, 네트워킹, 스토리지)의 기본 측면
- 오류 감지는 문제가 발생했는지 확인한다(예: 비트 플립).
- 감지되면 작동을 중지할 수 있다.
- 패리티 비트를 통해 자주 수행되는 탐지
- 체크섬의 한 형태인 패리티 – 모듈식 산술을 사용하여 고정 길이 단어의 값을 계산, 저장, 비교한다.
- 네트워킹에서 일반적인 또 다른 오류 감지 방법은 다중 비트 오류를 감지하기 위해 해시 함수를 사용하는 순환 중복 검사(CRC)이다.
- ECC(Error-Correction Code)는 오류를 감지할 뿐만 아니라 일부 오류를 수정할 수 있다.
- 소프트 오류 수정 가능, 하드 오류가 감지되었지만 수정되지 않는다.
Storage Device Management
- Low-level formatting, or physical formatting — Dividing a disk into sectors that the disk controller can read and write
- Each sector can hold header information, plus data, plus error correction code (ECC)
- Usually 512 bytes of data but can be selectable
- To use a disk to hold files, the operating system still needs to record its own data structures on the disk
- Partition the disk into one or more groups of cylinders, each treated as a logical disk
- Logical formatting or “making a file system”
- To increase efficiency most file systems group blocks into clusters
- Disk I/O done in blocks
- File I/O done in clusters
- 로우 레벨 포맷 또는 물리적 포맷 - 디스크 컨트롤러가 읽고 쓸 수 있는 섹터로 디스크 분할
- 각 섹터는 헤더 정보와 데이터, 오류 수정 코드(ECC)를 저장할 수 있다.
- 일반적으로 512바이트의 데이터이지만 선택할 수 있다.
- 디스크를 사용하여 파일을 보관하려면 운영 체제가 디스크에 자체 데이터 구조를 기록해야 한다.
- 디스크를 논리 디스크로 처리되는 하나 이상의 실린더 그룹으로 분할
- 논리 포맷 또는 "파일 시스템 만들기"
- 효율성을 높이기 위해 대부분의 파일 시스템은 블록을 클러스터로 그룹화한다.
- 디스크 I/O가 블록 단위로 수행됨
- 파일 I/O가 클러스터에서 수행됨
- Root partition contains the OS, other partitions can hold other Oses, other file systems, or be raw
- Mounted at boot time
- Other partitions can mount automatically or manually
- At mount time, file system consistency checked
- Is all metadata correct?
- If not, fix it, try again
- If yes, add to mount table, allow access
- Is all metadata correct?
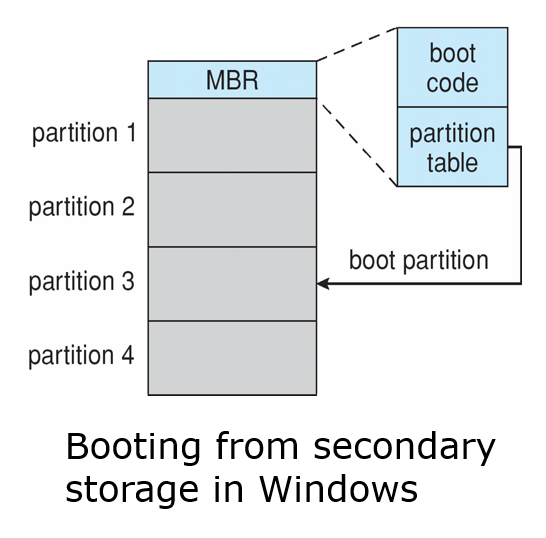
- Boot block can point to boot volume or boot loader set of blocks that contain enough code to know how to load the kernel from the file system
- Or a boot management program for multi-os booting
-
루트 파티션에 OS가 포함되어 있으며, 다른 파티션은 다른 Oes, 다른 파일 시스템을 보유하거나 원시 파티션일 수 있다.
- 부팅 시 마운트된다.
- 다른 파티션은 자동 또는 수동으로 마운트할 수 있다.
-
마운트 시 파일 시스템 일관성 확인
- 모든 메타데이터가 올바른가?
- 그렇지 않으면 수정하고 다시 시도하라.
- "예"인 경우 마운트 테이블에 추가하고 액세스
- 모든 메타데이터가 올바른가?
-
부트 블록은 파일 시스템에서 커널을 로드하는 방법을 알기에 충분한 코드를 포함하는 부트 볼륨 또는 부트 로더 블록 집합을 가리킬 수 있다.
- 또는 다중 OS 부팅을 위한 부팅 관리 프로그램
-
Raw disk access for apps that want to do their own block management, keep OS out of the way (databases for example)
-
Boot block initializes system
- The bootstrap is stored in ROM, firmware
- Bootstrap loader program stored in boot blocks of boot partition
-
Methods such as sector sparing used to handle bad blocks
- 자체 블록 관리를 수행하고 OS를 방해하지 않는 애플리케이션(예: 데이터베이스)을 위한 원시 디스크 액세스
- 부팅 블록이 시스템을 초기화한다.
- 부트스트랩은 ROM, 펌웨어에 저장된다.
- 부트 파티션의 부트 블록에 저장된 부트스트랩 로더 프로그램
- 불량 블록을 처리하는 데 사용되는 섹터 스페어링과 같은 방법
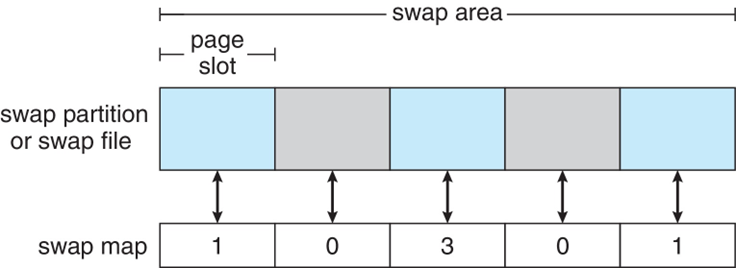
Swap-Space Management
- Used for moving entire processes (swapping), or pages (paging), from DRAM to secondary storage when DRAM not large enough for all processes
- Operating system provides swap space management
- Secondary storage slower than DRAM, so important to optimize performance
- Usually multiple swap spaces possible – decreasing I/O load on any given device
- Best to have dedicated devices
- Can be in raw partition or a file within a file system (for convenience of adding)
- Data structures for swapping on Linux systems:
- DRAM이 모든 프로세스에 충분하지 않은 경우 전체 프로세스(스왑) 또는 페이지(페이지)를 DRAM에서 보조 스토리지로 이동하는 데 사용된다.
- 운영 체제에서 스왑 공간 관리 제공
- DRAM보다 느린 보조 스토리지로 성능 최적화에 중요
- 일반적으로 여러 개의 스왑 공간이 가능하므로 특정 장치의 I/O 로드 감소
- 전용 장치를 갖추는 데 가장 적합
- 원시 파티션 또는 파일 시스템 내의 파일에 있을 수 있습니다(추가의 편의를 위해)
- Linux 시스템에서 스왑을 위한 데이터 구조:
Storage Attachment
- Computers access storage in three ways
- host-attached
- network-attached
- cloud
- Host attached access through local I/O ports, using one of several technologies
- To attach many devices, use storage busses such as USB, firewire, thunderbolt
- High-end systems use fibre channel (FC)
- High-speed serial architecture using fibre or copper cables
- Multiple hosts and storage devices can connect to the FC fabric
- 컴퓨터는 세 가지 방법으로 스토리지에 액세스한다.
- host-attached
- network-attached
- cloud
- 여러 기술 중 하나를 사용하여 로컬 I/O 포트를 통한 호스트 연결 액세스
- 많은 장치를 연결하려면 USB, Firewire, Thunderbolt와 같은 스토리지 버스를 사용해라.
- 하이엔드 시스템은 파이버 채널(FC)을 사용한다.
- 파이버 또는 구리 케이블을 사용한 고속 직렬 아키텍처
- 여러 호스트 및 스토리지 디바이스를 FC 패브릭에 연결할 수 있음
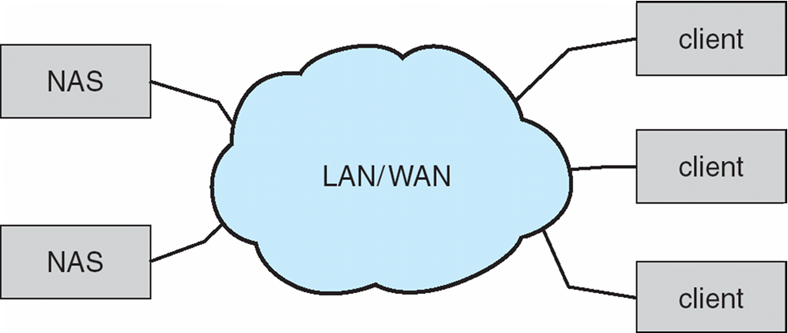
Network-Attached Storage
-
Network-attached storage (NAS) is storage made available over a network rather than over a local connection (such as a bus)
- Remotely attaching to file systems
-
NFS and CIFS are common protocols
-
Implemented via remote procedure calls (RPCs) between host and storage over typically TCP or UDP on IP network
-
iSCSI protocol uses IP network to carry the SCSI protocol
- Remotely attaching to devices (blocks)
-
NAS(Network Attached Storage)는 로컬 연결(예: 버스)이 아닌 네트워크를 통해 사용할 수 있는 스토리지이다.
- 파일 시스템에 원격으로 연결
-
NFS 및 CIFS는 공통 프로토콜이다.
-
일반적으로 IP 네트워크의 TCP 또는 UDP를 통해 호스트와 스토리지 간에 RPC(원격 프로시저 호출)를 통해 구현
-
iSCSI 프로토콜은 IP 네트워크를 사용하여 SCSI 프로토콜을 전송한다.
- 장치(블록)에 원격으로 연결
Cloud Storage
- Similar to NAS, provides access to storage across a network
- Unlike NAS, accessed over the Internet or a WAN to remote data center
- NAS presented as just another file system, while cloud storage is API based, with programs using the APIs to provide access
- Examples include Dropbox, Amazon S3, Microsoft OneDrive, Apple iCloud
- Use APIs because of latency and failure scenarios (NAS protocols wouldn’t work well)
- NAS와 유사하게 네트워크를 통해 스토리지에 대한 액세스를 제공한다.
- NAS와 달리 인터넷이나 WAN을 통해 원격 데이터 센터에 액세스할 수 있다.
- 클라우드 스토리지는 API 기반이며 프로그램은 액세스를 제공하기 위해 API를 사용한다.
- 예를 들어 Dropbox, Amazon S3, Microsoft OneDrive, Apple iCloud 등이 있다.
- 대기 시간 및 장애 시나리오 때문에 API 사용(NAS 프로토콜이 제대로 작동하지 않음)
Storage Array
- Can just attach disks, or arrays of disks
- Avoids the NAS drawback of using network bandwidth
- Storage Array has controller(s), provides features to attached host(s)
- Ports to connect hosts to array
- Memory, controlling software (sometimes NVRAM, etc)
- A few to thousands of disks
- RAID, hot spares, hot swap (discussed later)
- Shared storage -> more efficiency
- Features found in some file systems
- Snaphots, clones, thin provisioning, replication, deduplication, etc
- 디스크 또는 디스크 배열만 연결할 수 있다.
- 네트워크 대역폭 사용에 따른 NAS의 단점을 방지한다.
- 스토리지 어레이에 컨트롤러가 있으며 연결된 호스트에 기능을 제공한다.
- 호스트를 어레이에 연결할 포트
- 메모리, 제어 소프트웨어(때로는 NVRAM 등)
- 몇 개에서 수천 개의 디스크
- RAID, 핫 스페어, 핫 스왑(나중에 설명)
- 공유 스토리지 -> 효율성 향상
- 일부 파일 시스템에서 발견된 기능
- 스냅샷, 클론, 씬 프로비저닝, 복제, 중복제거 등
Storage Area Network
- Common in large storage environments
- Multiple hosts attached to multiple storage arrays – flexible
- 대규모 스토리지 환경에서 공통
- 여러 스토리지 어레이에 연결된 여러 호스트 – 유연성
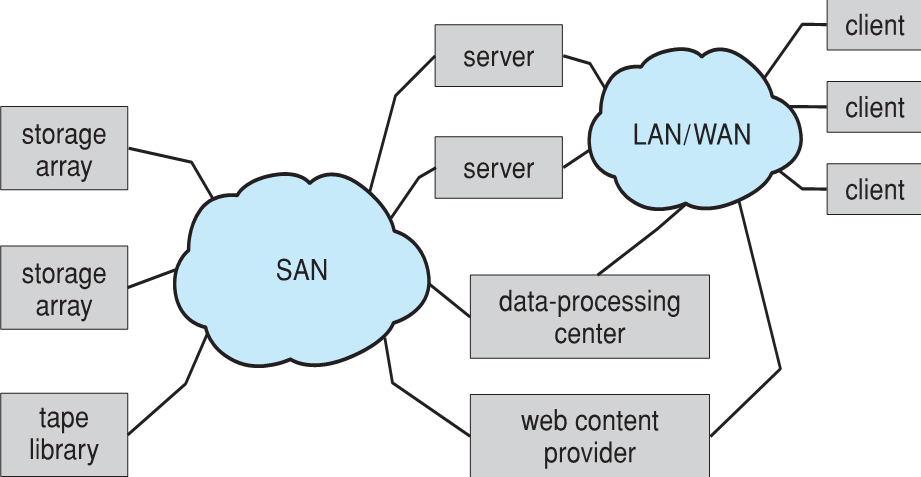
- SAN is one or more storage arrays
- Connected to one or more Fibre Channel switches or InfiniBand (IB) network
- Hosts also attach to the switches
- Storage made available via LUN Masking from specific arrays to specific servers
- Easy to add or remove storage, add new host and allocate it storage
- Why have separate storage networks and communications networks?
- Consider iSCSI, FCOE
- SAN은 하나 이상의 스토리지 어레이이다.
- 하나 이상의 파이버 채널 스위치 또는 InfiniBand(IB) 네트워크에 연결된다.
- 호스트도 스위치에 연결된다.
- LUN 마스킹을 통해 특정 어레이에서 특정 서버로 스토리지 제공한다.
- 스토리지 추가 또는 제거, 새 호스트 추가 및 할당이 용이하다.
- 스토리지 네트워크와 통신 네트워크가 분리된 이유는 무엇인가?
- iSCSI, FCOE 고려

RAID Structure
- RAID – redundant array of inexpensive disks
- multiple disk drives provides reliability via redundancy
- Increases the mean time to failure
- Mean time to repair – exposure time when another failure could cause data loss
- Mean time to data loss based on above factors
- If mirrored disks fail independently, consider disk with 1300,000 mean time to failure and 10 hour mean time to repair
- Mean time to data loss is 100, 0002 / (2 ∗ 10) = 500 ∗ 106 hours, or 57,000 years!
- Frequently combined with NVRAM to improve write performance
- Several improvements in disk-use techniques involve the use of multiple disks working cooperatively
- RAID – 저렴한 디스크의 중복 어레이
- 다중 Disk 드라이브는 이중화를 통해 안정성을 제공한다.
- 평균 고장 시간을 늘린다.
- 평균 복구 시간 – 또 다른 장애로 인해 데이터 손실이 발생할 수 있는 노출 시간
- 위의 요인을 기준으로 평균 데이터 손실 시간
- 미러링된 디스크가 독립적으로 고장나는 경우 평균 고장 시간이 1300,000이고 평균 복구 시간이 10시간인 디스크를 고려해라.
- 평균 데이터 손실 시간은 100,0002 / (2µ10) = 500µ106시간 또는 57,000년이다!
- 쓰기 성능 향상을 위해 NVRAM과 자주 결합
- 디스크 사용 기술의 몇 가지 개선 사항으로 여러 개의 디스크를 함께 사용할 수 있다.
- Disk striping uses a group of disks as one storage unit
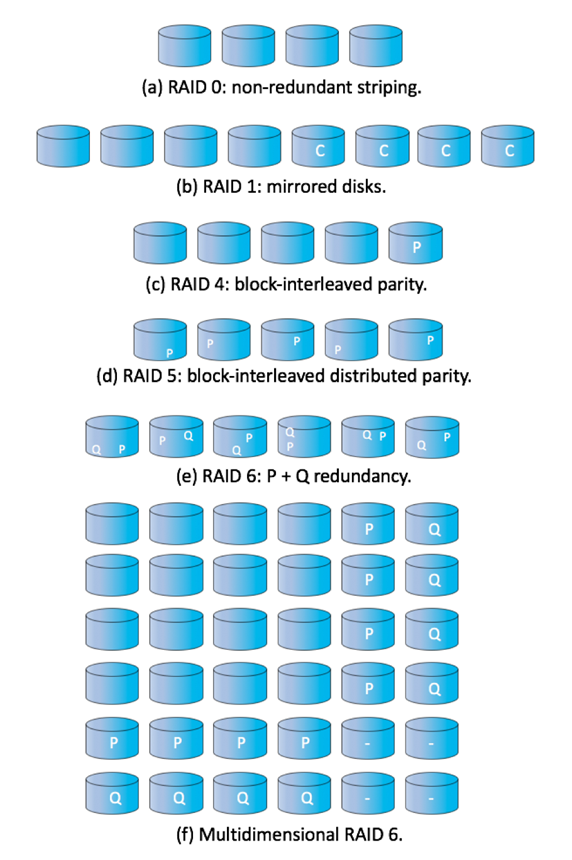
- RAID is arranged into six different levels
- RAID schemes improve performance and improve the reliability of the storage system by storing redundant data
- Mirroring or shadowing (RAID 1) keeps duplicate of each disk
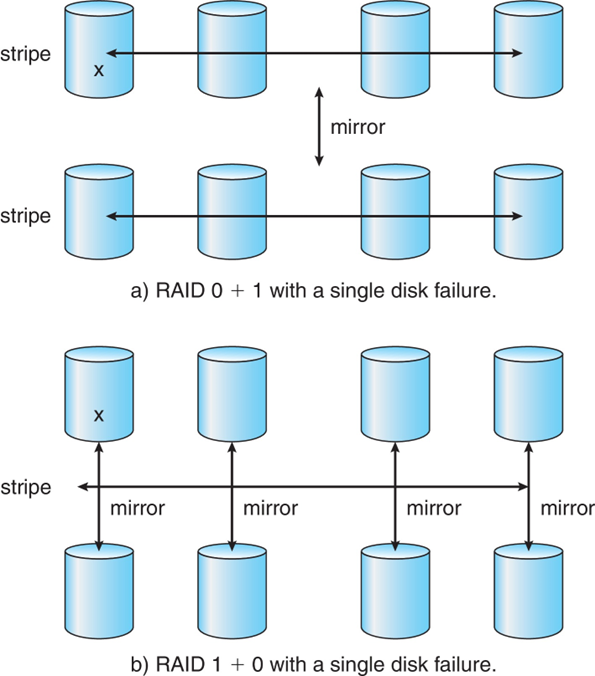
- Striped mirrors (RAID 1+0) or mirrored stripes (RAID 0+1) provides high performance and high reliability
- Block interleaved parity (RAID 4, 5, 6) uses much less redundancy
- RAID within a storage array can still fail if the array fails, so automatic replication of the data between arrays is common
- Frequently, a small number of hot-spare disks are left unallocated, automatically replacing a failed disk and having data rebuilt onto them
- 디스크 스트라이핑은 디스크 그룹을 하나의 저장 단위로 사용한다.
- RAID는 6가지 레벨로 구성된다.
- RAID 구성은 중복 데이터를 저장하여 성능을 향상시키고 스토리지 시스템의 안정성을 향상시킨다.
- 미러링 또는 섀도잉(RAID 1)으로 각 디스크의 중복 유지
- 스트라이프 미러(RAID 1+0) 또는 미러링된 스트라이프(RAID 0+1)는 고성능과 높은 신뢰성을 제공한다.
- 블록 인터리브 패리티(RAID 4, 5, 6)는 훨씬 적은 이중화를 사용한다.
- 스토리지 어레이에 장애가 발생하더라도 스토리지 어레이 내의 RAID는 여전히 장애가 발생할 수 있으므로 어레이 간 데이터 자동 복제가 일반적이다.
- 종종 소수의 핫 스페어 디스크가 할당되지 않은 상태로 남아 고장난 디스크를 자동으로 교체하고 데이터를 재구축한다.
RAID Levels
RAID (0+1) and (1+0)
Other Features
- Regardless of where RAID implemented, other useful features can be added
- Snapshot is a view of file system before a set of changes take place (i.e. at a point in time)
- More in Ch 12
- Replication is automatic duplication of writes between separate sites
- For redundancy and disaster recovery
- Can be synchronous or asynchronous
- Hot spare disk is unused, automatically used by RAID production if a disk fails to replace the failed disk and rebuild the RAID set if possible
- Decreases mean time to repair
- RAID가 구현된 위치에 상관없이 다른 유용한 기능을 추가할 수 있다.
- 스냅샷은 일련의 변경 사항이 발생하기 전(즉, 특정 시점에서) 파일 시스템의 보기이다.
- 12장에서 더 보기
- 복제는 별도의 사이트 간에 쓰기 작업을 자동으로 복제한다.
- 이중화 및 재해 복구용
- 동기식 또는 비동기식일 수 있다.
- 핫 스페어 Disk는 사용되지 않으며, Disk가 고장난 Disk를 교체하지 못하고 가능한 경우 RAID 세트를 재구축하는 경우 RAID 프로덕션에서 자동으로 사용된다.
- 평균 수리 시간 단축
Extensions
- RAID alone does not prevent or detect data corruption or other errors, just disk failures
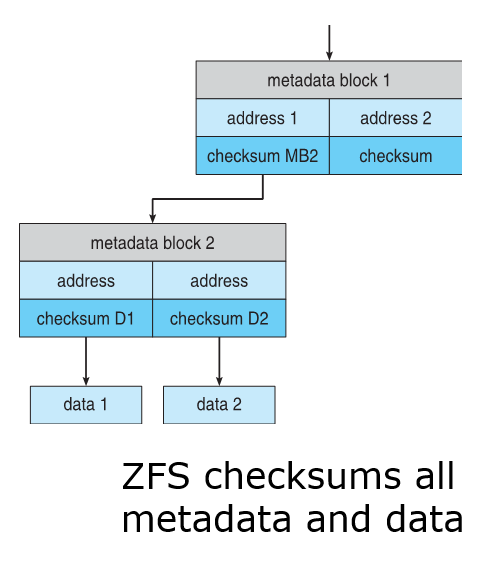
- Solaris ZFS adds checksums of all data and metadata
- Checksums kept with pointer to object, to detect if object is the right one and whether it changed
- Can detect and correct data and metadata corruption
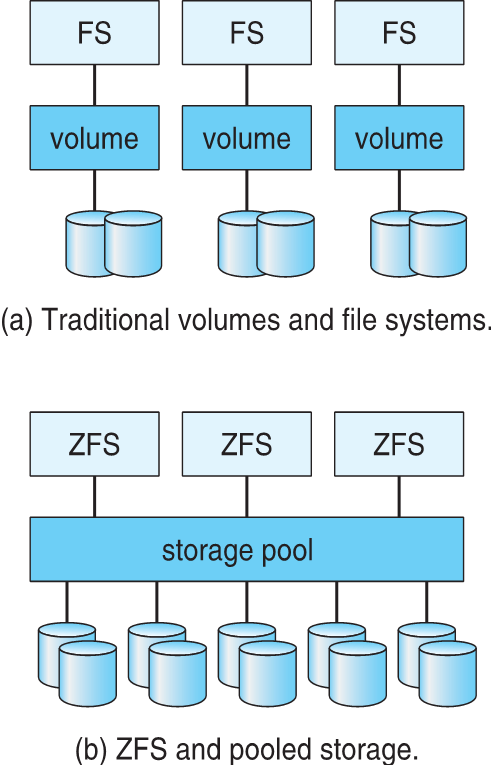
- ZFS also removes volumes, partitions
- Disks allocated in pools
- Filesystems with a pool share that pool, use and release space like malloc() and free() memory allocate / release calls
- RAID만으로는 데이터 손상이나 기타 오류를 방지하거나 감지하지 못하고 Disk 장애만 발생한다.
- Solaris ZFS는 모든 데이터 및 메타데이터의 체크섬을 추가한다.
- 개체에 대한 포인터를 사용하여 개체가 올바른지 여부와 개체가 변경되었는지 여부를 감지하는 체크섬
- 데이터 및 메타데이터 손상 감지 및 수정 가능
- ZFS는 볼륨, 파티션도 제거한다.
- 풀에 할당된 디스크
- 풀이 있는 파일 시스템은 malloc() 및 free() 메모리 할당/해제 호출과 같은 풀, 사용 및 해제 공간을 공유한다.
Traditional and Pooled Storage
Object Storage
- General-purpose computing, file systems not sufficient for very large scale
- Another approach – start with a storage pool and place objects in it
- Object just a container of data
- No way to navigate the pool to find objects (no directory structures, few services
- Computer-oriented, not user-oriented
- Typical sequence
- Create an object within the pool, receive an object ID
- Access object via that ID
- Delete object via that ID
- Object storage management software like Hadoop file system (HDFS) and Ceph determine where to store objects, manages protection
- Typically by storing N copies, across N systems, in the object storage cluster
- Horizontally scalable
- Content addressable, unstructured
- 범용 컴퓨팅, 대규모 파일 시스템으로는 충분하지 않다.
- 또 다른 접근 방식은 스토리지 풀에서 시작하여 개체를 배치하는 것이다.
- 데이터 컨테이너만 객체로 지정
- 풀을 탐색하여 개체를 찾을 수 없음(디렉토리 구조 없음, 서비스가 거의 없음)
- 사용자 지향이 아닌 컴퓨터 지향
- 전형적인 순서
- 풀 내에서 개체 생성, 개체 ID 수신
- 해당 ID를 통해 개체 액세스
- 해당 ID를 통해 개체 삭제
- Hadoop 파일 시스템(HDFS) 및 Ceph와 같은 객체 스토리지 관리 소프트웨어를 통해 객체를 저장할 위치 결정, 보호 관리
- 일반적으로 N개의 시스템에 걸쳐 N개의 복사본을 객체 스토리지 클러스터에 저장합니다.
- 수평적 확장성
- 컨텐츠 주소 지정 가능, 비정형
