File Concept
- Contiguous logical address space
- Types:
- Data
- numeric
- character
- binary
- Program
- Data
- Contents defined by file’s creator
- Many types
- Consider text file, source file, executable file
- Many types
- 연속 논리 주소 공간
- 유형:
- 데이터
- numeric
- character
- binary
- 프로그램
- 데이터
- 파일 작성자가 정의한 내용
- 많은 종류
- 텍스트 파일, 원본 파일, 실행 파일 고려
- 많은 종류
File Attributes
- Name – only information kept in human-readable form
- Identifier – unique tag (number) identifies file within file system
- Type – needed for systems that support different types
- Location – pointer to file location on device
- Size – current file size
- Protection – controls who can do reading, writing, executing
- Time, date, and user identification – data for protection, security, and usage monitoring
- Information about files are kept in the directory structure, which is maintained on the disk
- Many variations, including extended file attributes such as file checksum
- Information kept in the directory structure
- 이름 – 사람이 읽을 수 있는 형태로 보관된 정보만 해당
- 식별자 – 고유 태그(번호)가 파일 시스템 내의 파일을 식별한다.
- 유형 – 다양한 유형을 지원하는 시스템에 필요
- 위치 – 장치의 파일 위치에 대한 포인터
- 크기 – 현재 파일 크기
- 보호 – 읽기, 쓰기, 실행을 수행할 수 있는 사용자를 제어
- 시간, 날짜 및 사용자 식별 – 보호, 보안 및 사용 모니터링을 위한 데이터
- 파일에 대한 정보는 디스크에 유지되는 디렉토리 구조에 보관된다.
- 파일 체크섬과 같은 확장된 파일 속성을 포함한 많은 변형이 존재한다.
- 정보는 디렉토리 구조에 보관된다.
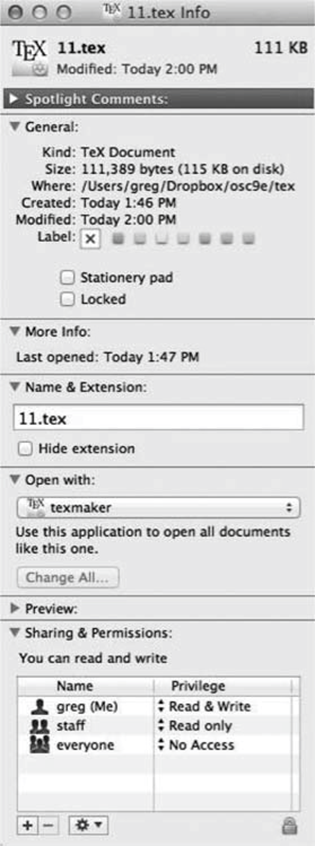
File info Window on Mac OS X
File Operations
- File is an abstract data type
- Create
- Write – at write pointer location
- Read – at read pointer location
- Reposition within file - seek
- Delete
- Truncate
- Open(Fi) – search the directory structure on disk for entry Fi, and move the content of entry to memory
- Close (Fi) – move the content of entry Fi in memory to directory structure on disk
- 파일은 추상 데이터 유형이다.
- 작성
- 쓰기 – 쓰기 포인터 위치
- 읽기 – 읽기 포인터 위치
- 파일 내 위치 변경 - 검색
- 삭제
- 잘라내기
- 열기(Fi) – 디스크의 디렉토리 구조에서 항목 Fi를 검색하고 항목의 내용을 메모리로 이동한다.
- 닫기(Fi) – 메모리의 항목 Fi 내용을 디스크의 디렉토리 구조로 이동한다.
Open Files
- Several pieces of data are needed to manage open files:
- Open-file table: tracks open files
- File pointer: pointer to last read/write location, per process that has the file open
- File-open count: counter of number of times a file is open – to allow removal of data from open-file table when last processes closes it
- Disk location of the file: cache of data access information
- Access rights: per-process access mode information
- 열려 있는 파일을 관리하려면 다음과 같은 몇 가지 데이터가 필요하다.
- 열린 파일 테이블: 열려 있는 파일을 추적한다.
- 파일 포인터: 파일이 열린 프로세스별 마지막 읽기/쓰기 위치 포인터
- 파일 열기 횟수: 파일 열기 횟수 카운터 - 마지막 프로세스에서 파일을 닫을 때 파일 열기 테이블에서 데이터를 제거할 수 있다.
- 파일의 디스크 위치: 데이터 액세스 정보 캐시
- 액세스 권한: 프로세스별 액세스 모드 정보
Open File Locking
- Provided by some operating systems and file systems
- Similar to reader-writer locks
- Shared lock similar to reader lock – several processes can acquire concurrently
- Exclusive lock similar to writer lock
- Mediates access to a file
- Mandatory or advisory:
- Mandatory – access is denied depending on locks held and requested
- Advisory – processes can find status of locks and decide what to do
- 일부 운영 체제 및 파일 시스템에서 제공
- reader-writer lock과 유사
- shared lock은 reader lock과 유사하다. 여러 프로세스가 동시에 수행될 수 있다.
- exclusive lock writer lock과 유사하다.
- 파일에 대한 액세스를 조정한다.
- 필수 또는 권고 사항:
- 필수 – 유지 및 요청된 잠금에 따라 액세스가 거부된다.
- 권고 – 프로세스에서 잠금 상태를 확인하고 수행할 작업을 결정할 수 있다.
File Locking Example - Java API


File Types - Name, Extension
File Structure
- None - sequence of words, bytes
- Simple record structure
- Lines
- Fixed length
- Variable length
- Complex Structures
- Formatted document
- Relocatable load file
- Can simulate last two with first method by inserting appropriate control characters
- Who decides:
- Operating system
- Program
- 없음 - 단어 순서, 바이트
- 단순 레코드 구조
- 선
- 고정길이
- 가변 길이
- 복잡한 구조
- 서식 있는 문서
- 재배치 가능한 로드 파일
- 적절한 제어 문자를 삽입하여 첫 번째 방법으로 마지막 두 개를 시뮬레이션할 수 있다.
- 결정하는 사람:
- 운영 체제
- 프로그램
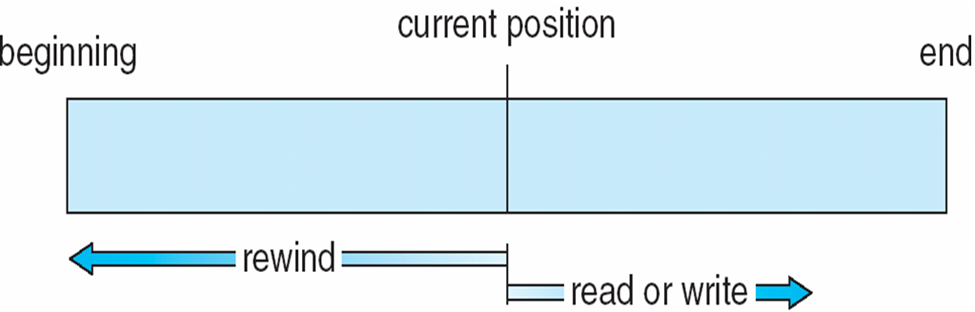
Sequential-access File
Access Methods
-
Sequential Access
read next
write next
reset
no read after last write
(rewrite) -
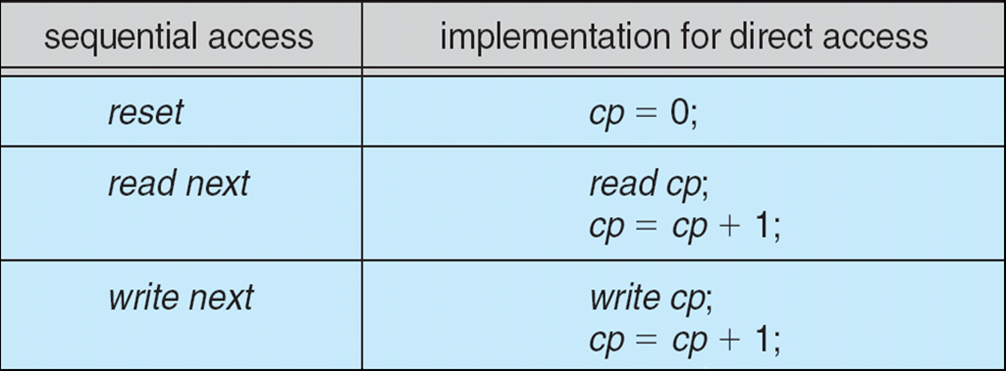
Direct Access – file is fixed length logical records
read n
write n
position to n
read next
write next
rewrite n
n = relative block number -
Relative block numbers allow OS to decide where file should be placed
- See allocation problem in Ch 12
-
순차 액세스
다음을 읽다
다음에 쓰다
재설정하다
마지막 쓰기 후 읽기 없음
(계속) -
직접 액세스 – 파일은 고정 길이의 논리적 레코드이다.
읽혔다
글을 쓰다
n에 위치시키다.
다음을 읽다
다음에 쓰다
n을 고쳐 쓰다
n = 상대 블록 번호 -
상대적인 블록 번호를 통해 OS가 파일을 배치할 위치를 결정할 수 있다.
- Ch 12의 할당 문제 참조
Simulation of Sequential Access on Direct-access File
Other Access Methods
- Can be built on top of base methods
- General involve creation of an index for the file
- Keep index in memory for fast determination of location of data to be operated on (consider UPC code plus record of data about that item)
- If too large, index (in memory) of the index (on disk)
- IBM indexed sequential-access method (ISAM)
- Small master index, points to disk blocks of secondary index
- File kept sorted on a defined key
- All done by the OS
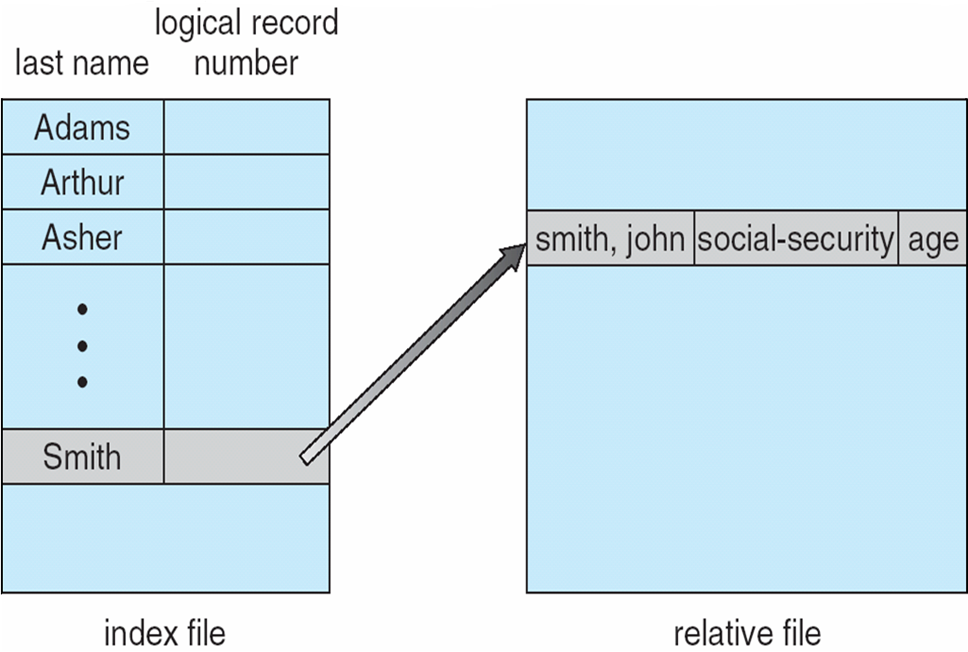
- VMS operating system provides index and relative files as another example (see next slide)
- 기본 메서드를 기반으로 구축 가능
- 일반적으로 파일에 대한 index 생성이 포함된다.
- 작업할 데이터의 위치를 빠르게 결정할 수 있도록 메모리에 인덱스를 보관한다(UPC 코드와 해당 항목에 대한 데이터 기록을 고려).
- 너무 클 경우 인덱스의 인덱스(메모리 내)(디스크 내)
- IBM 색인 순차 액세스 방법(ISAM)
- 작은 마스터 인덱스, 보조 인덱스의 디스크 블록을 가리킨다.
- 정의된 키에 정렬된 파일
- 모든 작업이 OS에서 수행됨
- VMS 운영 체제는 인덱스 및 관련 파일을 다른 예로 제공한다(다음 슬라이드 참조).
Example of Index and Relative Files
Disk and Directory Structure
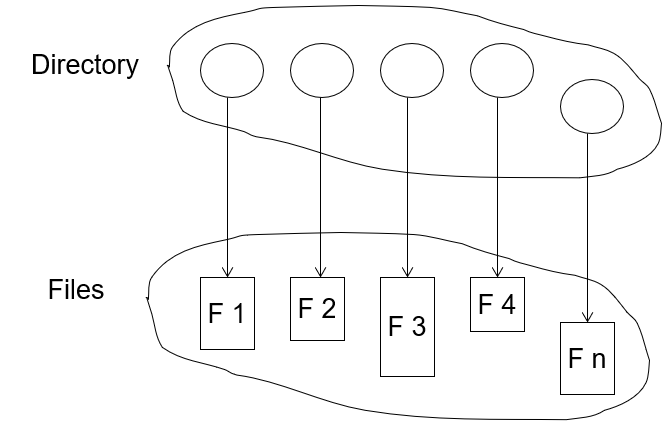
Directory Structure
- A collection of nodes containing information about all files
-
Both the directory structure and the files reside on disk
-
모든 파일에 대한 정보를 포함하는 노드 모음
-
디렉터리 구조와 파일이 모두 디스크에 있다.
Disk Structure
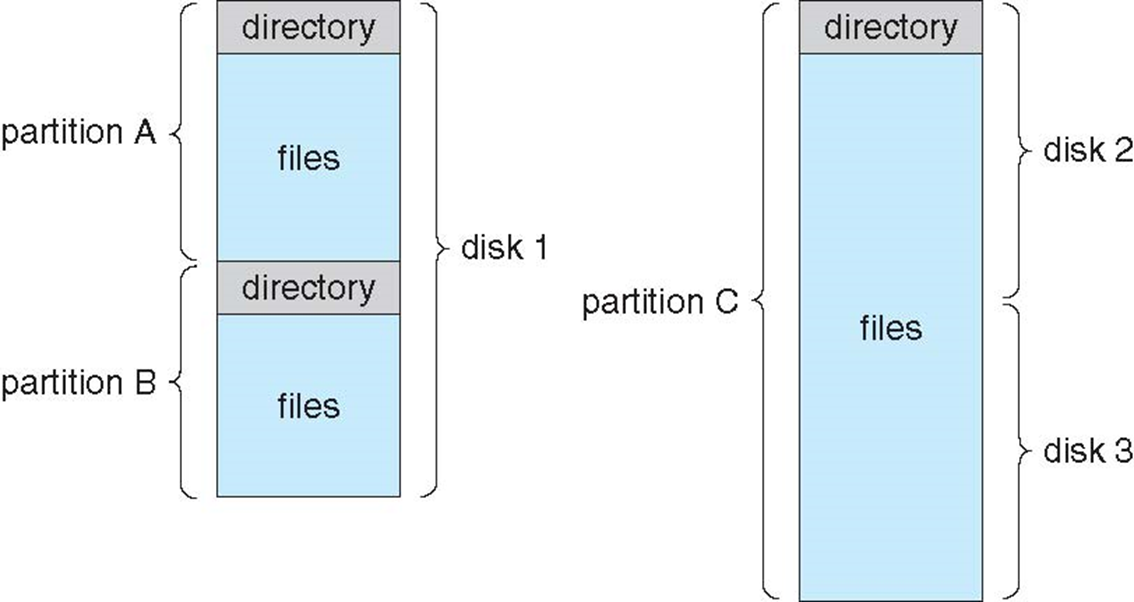
- Disk can be subdivided into partitions
- Disks or partitions can be RAID protected against failure
- Disk or partition can be used raw – without a file system, or formatted with a file system
- Partitions also known as minidisks, slices
- Entity containing file system known as a volume
- Each volume containing file system also tracks that file system’s info in device directory or volume table of contents
- As well as general-purpose file systems there are many special-purpose file systems, frequently all within the same operating system or computer
- 디스크를 파티션으로 세분화할 수 있다.
- 디스크 또는 파티션은 장애로부터 RAID 보호 가능
- 디스크 또는 파티션을 파일 시스템 없이 원시적으로 사용하거나 파일 시스템으로 포맷할 수 있습니다.
- 미니 디스크, 슬라이스라고도 하는 파티션
- volume으로 알려진 파일 시스템을 포함하는 엔티티
- 또한 파일 시스템을 포함하는 각 볼륨은 device directory* 또는 volume table of contents*에서 해당 파일 시스템의 정보를 추적합니다.
- 범용 파일 시스템뿐만 아니라 특수 파일 시스템도 다수 존재하며, 대부분 동일한 운영 체제 또는 컴퓨터 내에 있습니다.
A Typical File-system Organization
Types of File Systems
- We mostly talk of general-purpose file systems
- But systems frequently have may file systems, some general- and some special- purpose
- Consider Solaris has
- tmpfs – memory-based volatile FS for fast, temporary I/O
- objfs – interface into kernel memory to get kernel symbols for debugging
- ctfs – contract file system for managing daemons
- lofs – loopback file system allows one FS to be accessed in place of another
- procfs – kernel interface to process structures
- ufs, zfs – general purpose file systems
- 우리는 주로 범용 파일 시스템에 대해 이야기한다.
- 그러나 시스템에는 종종 파일 시스템이 있으며 일부는 일반적이고 일부는 특수한 용도로 사용된다.
- Solaris has를 고려해리.
- tmpfs – 빠르고 일시적인 I/O를 위한 메모리 기반 휘발성 FS
- objfs – 디버깅을 위한 커널 기호를 얻기 위해 커널 메모리에 인터페이스를 제공한다.
- ctfs – 데몬을 관리하기 위한 계약 파일 시스템
- lofs – 루프백 파일 시스템을 통해 다른 FS 대신 하나의 FS에 액세스할 수 있다.
- procfs – 구조를 처리하기 위한 커널 인터페이스
- ufs, zfs – 범용 파일 시스템
Operations Performed on Directory
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
- 파일 검색
- 파일 만들기
- 파일 삭제
- 디렉터리 나열
- 파일 이름 바꾸기
- 파일 시스템 횡단
Directory Organization
The directory is organized logically to obtain
- Efficiency – locating a file quickly
- Naming – convenient to users
- Two users can have same name for different files
- The same file can have several different names
- Grouping – logical grouping of files by properties, (e.g., all Java programs, all games, …)
디렉토리가 논리적으로 구성되어 있다.
- 효율성 – 파일을 신속하게 찾을 수 있음
- 이름 지정 – 사용자에게 편리함
- 두 사용자가 서로 다른 파일에 대해 동일한 이름을 가질 수 있음
- 동일한 파일은 여러 개의 다른 이름을 가질 수 있음.
- 그룹화 – 속성별로 파일을 논리적으로 그룹화 (예: 모든 Java 프로그램, 모든 게임 등).
Single-Level Directory
- A single directory for all users
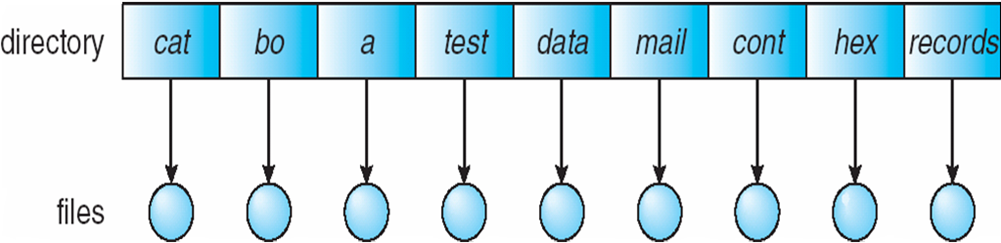
- Naming problem
- Grouping problem
Two-Level Directory
- Separate directory for each user
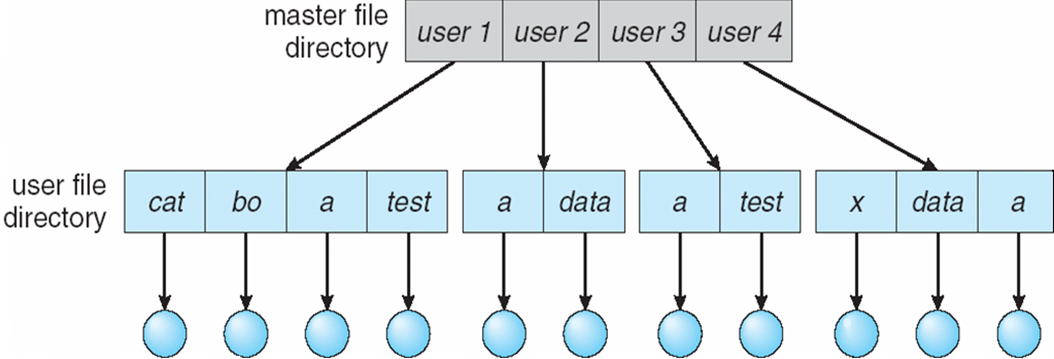
- Path name
- Can have the same file name for different user
- Efficient searching
- No grouping capability
Tree-Structured Directions
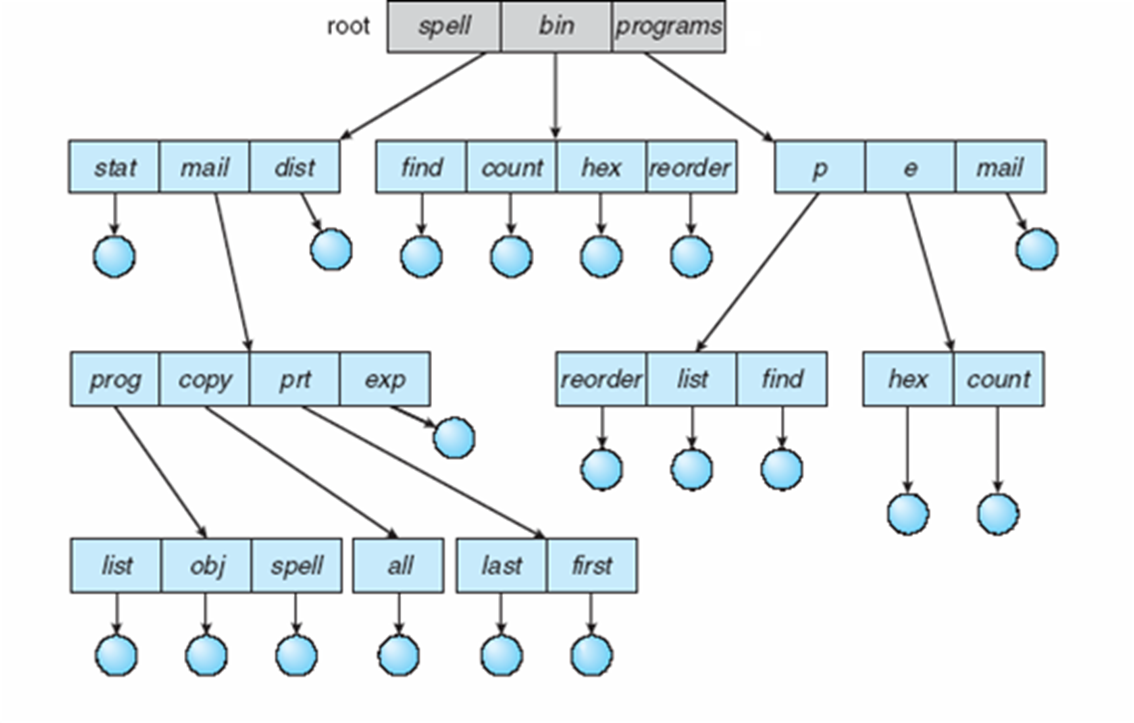
- Efficient searching
- Grouping Capability
- Current directory (working directory)
- cd /spell/mail/prog
- type list
- Absolute or relative path name
- Creating a new file is done in current directory
- Delete a file
- rm file-name
- Creating a new subdirectory is done in current directory
- mkdir dir-name
- Example: if in current directory /mail
- mkdir count
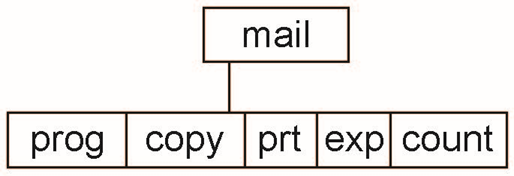
Deleting “mail” -> deleting the entire subtree rooted by “mail”
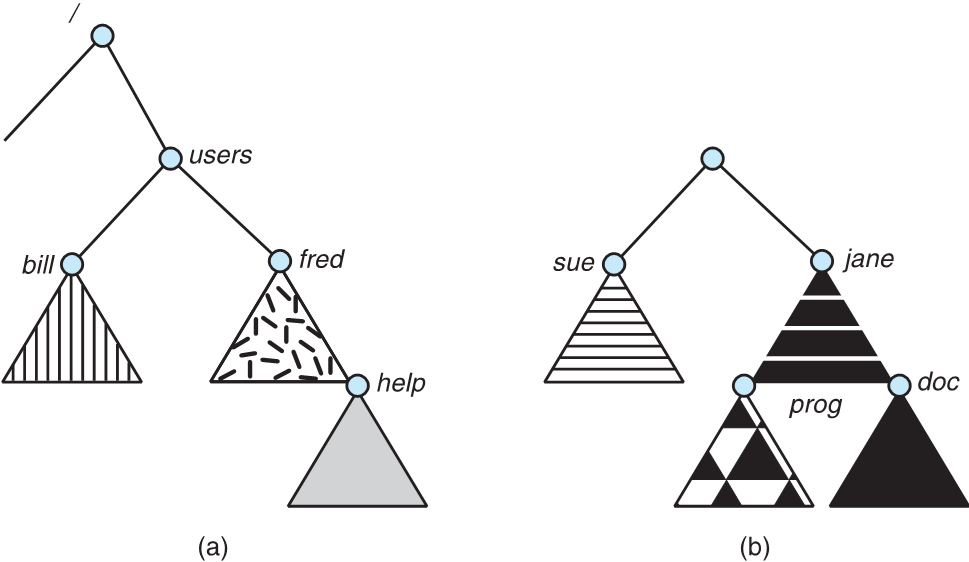
Acyclic-Graph Directions (Cont.)
-
Two different names (aliasing)
-
If dict deletes list -> dangling pointer
- Solutions:
- Backpointers, so we can delete all pointers Variable size records a problem
- Backpointers using a daisy chain organization
- Entry-hold-count solution
- Solutions:
-
New directory entry type
- Link – another name (pointer) to an existing file
- Resolve the link – follow pointer to locate the file
-
두 개의 다른 이름(앨리어싱)
-
dict가 목록을 삭제하면 -> dangling 포인터
- 해결책:
- 모든 포인터를 삭제할 수 있도록 백 포인터. 가변 크기가 문제를 기록합니다.
- 데이지 체인 조직을 사용한 백 포인터
- 엔트리-홀드-카운트 솔루션
- 해결책:
-
새 디렉토리 항목 유형
- 링크 – 기존 파일에 대한 다른 이름(포인터)
- 링크를 확인한다. 포인터를 따라 파일을 찾는다.
General Graph Directory
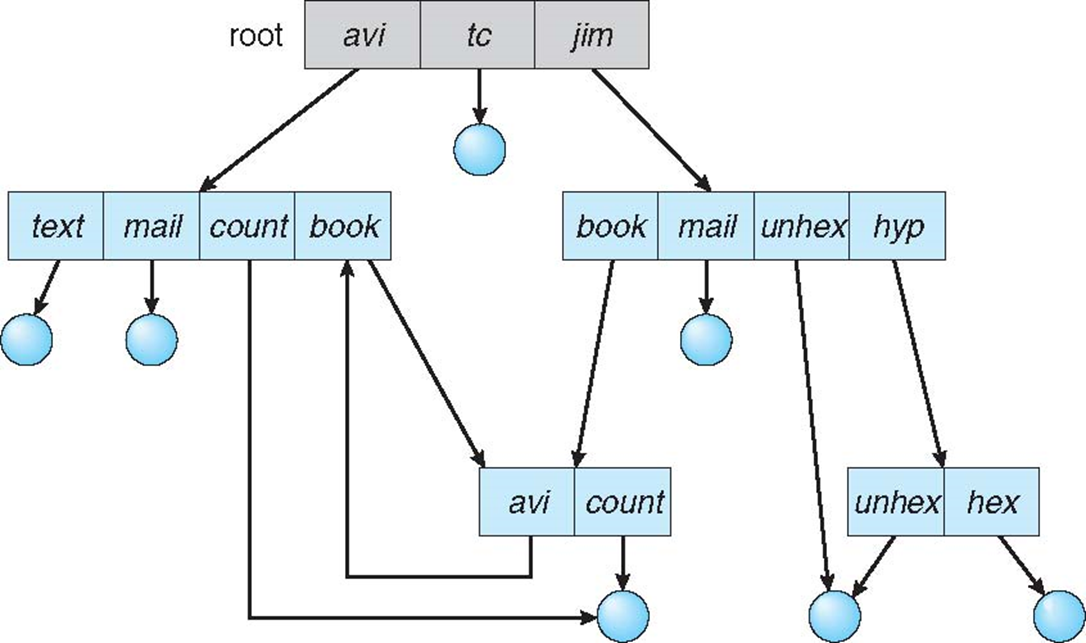
- How do we guarantee no cycles?
- Allow only links to file not subdirectories
- Garbage collection
- Every time a new link is added use a cycle detection algorithm to determine whether it is OK
- 사이클이 없다는 것을 어떻게 보장하는가?
- 하위 디렉토리가 아닌 파일에 대한 링크만 허용
- 쓰레기 수거
- 새 링크가 추가될 때마다 주기 감지 알고리즘을 사용하여 정상인지 확인한다.
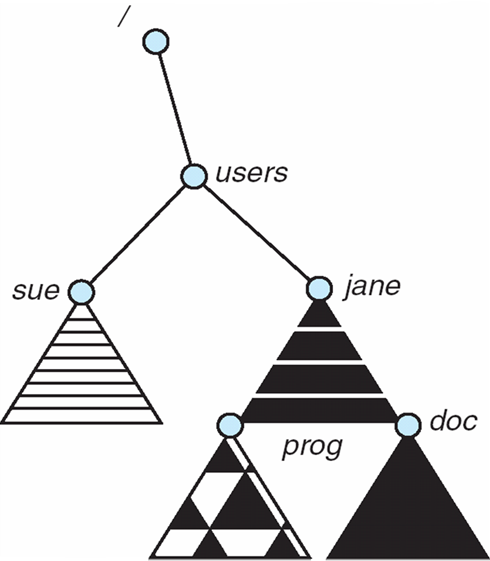
File System Mounting
- A file system must be mounted before it can be accessed
- A unmounted file system (i.e., Fig. 11-11(b)) is mounted at a mount point
- 파일 시스템에 액세스하려면 마운트해야 한다.
- 마운트 해제된 파일 시스템(즉, 그림 11-11(b))은 마운트 지점에 마운트된다.
Mount Point
File Sharing
- Sharing of files on multi-user systems is desirable
- Sharing may be done through a protection scheme
- On distributed systems, files may be shared across a network
- Network File System (NFS) is a common distributed file-sharing method
- If multi-user system
- User IDs identify users, allowing permissions and protections to be per-user
- Group IDs allow users to be in groups, permitting group access rights
- Owner of a file / directory
- Group of a file / directory
- 다중 사용자 시스템에서 파일을 공유하는 것이 바람직하다.
- 공유는 보호 체계를 통해 수행될 수 있다.
- 분산 시스템에서는 네트워크를 통해 파일을 공유할 수 있다.
- NFS(네트워크 파일 시스템)는 일반적인 분산 파일 공유 방법이다.
- 다중 사용자 시스템인 경우
- 사용자 ID가 사용자를 식별하여 사용자별 권한 및 보호 허용한다.
- 그룹 ID는 사용자가 그룹에 속해 그룹 액세스 권한을 허용한다.
- 파일/디렉토리 소유자
- 파일/디렉토리 그룹
File Sharing - Remote File Systems
- Uses networking to allow file system access between systems
- Manually via programs like FTP
- Automatically, seamlessly using distributed file systems
- Semi automatically via the world wide web
- Client-server model allows clients to mount remote file systems from servers
- Server can serve multiple clients
- Client and user-on-client identification is insecure or complicated
- NFS is standard UNIX client-server file sharing protocol
- CIFS is standard Windows protocol
- Standard operating system file calls are translated into remote calls
- Distributed Information Systems (distributed naming services) such as LDAP, DNS, NIS, Active Directory implement unified access to information needed for remote computing
- 네트워킹을 사용하여 시스템 간 파일 시스템 액세스 허용
- FTP와 같은 프로그램을 통해 수동으로 실행
- 분산 파일 시스템을 자동으로 원활하게 사용
- 월드 와이드 웹을 통해 반자동으로 실행
- 클라이언트-서버 모델을 통해 클라이언트가 서버에서 원격 파일 시스템을 마운트할 수 있다.
- 서버가 여러 클라이언트에 서비스를 제공할 수 있다.
- 클라이언트 및 사용자 온 클라이언트 식별이 안전하지 않거나 복잡하다.
- NFS는 표준 UNIX 클라이언트-서버 파일 공유 프로토콜이다.
- CIFS는 표준 윈도우즈 프로토콜이다.
- 표준 운영 체제 파일 호출이 원격 호출로 변환된다.
- LDAP, DNS, NIS, Active Directory와 같은 분산형 정보 시스템(분산 명명 서비스)은 원격 컴퓨팅에 필요한 정보에 대한 통합 액세스를 구현한다.
File Sharing - Failure Modes
- All file systems have failure modes
- For example corruption of directory structures or other non-user data, called metadata
- Remote file systems add new failure modes, due to network failure, server failure
- Recovery from failure can involve state information about status of each remote request
- Stateless protocols such as NFS v3 include all information in each request, allowing easy recovery but less security
- 모든 파일 시스템에 장애 모드가 있다.
- 예를 들어 디렉토리 구조 또는 메타데이터라고 하는 사용자가 아닌 다른 데이터의 손상
- 원격 파일 시스템이 네트워크 장애, 서버 장애로 인한 새로운 장애 모드 추가
- 장애로부터의 복구에는 각 원격 요청의 상태에 대한 상태 정보가 포함될 수 있다.
- NFS v3과 같은 상태 비저장 프로토콜은 각 요청에 모든 정보를 포함하므로 복구는 쉽지만 보안은 떨어진다.
File Sharing - Consistency Semantics
- Specify how multiple users are to access a shared file simultaneously
- Similar to Ch 5 process synchronization algorithms
- Tend to be less complex due to disk I/O and network latency (for remote file systems
- Andrew File System (AFS) implemented complex remote file sharing semantics
- Unix file system (UFS) implements:
- Writes to an open file visible immediately to other users of the same open file
- Sharing file pointer to allow multiple users to read and write concurrently
- AFS has session semantics
- Writes only visible to sessions starting after the file is closed
- Similar to Ch 5 process synchronization algorithms
- 여러 사용자가 공유 파일에 동시에 액세스하는 방법 지정
- Ch 5 프로세스 동기화 알고리즘과 유사
- (원격 파일 시스템의 경우) Disk I/O 및 네트워크 대기 시간으로 인해 덜 복잡해지는 경향이 있음
- Andrew File System(AFS)은 복잡한 원격 파일 공유 의미론을 구현했다.
- 유닉스 파일 시스템(UFS)은 다음을 구현한다.
- 동일한 열린 파일의 다른 사용자가 바로 볼 수 있는 열린 파일에 쓰기
- 여러 사용자가 동시에 읽고 쓸 수 있도록 파일 포인터 공유
- AFS에 세션 의미론이 있음
- 파일을 닫은 후 시작되는 세션에만 기록
- Ch 5 프로세스 동기화 알고리즘과 유사
Protection
- File owner/creator should be able to control:
- what can be done
- by whom
- Types of access
- Read
- Write
- Execute
- Append
- Delete
- List
- 파일 소유자/작성자는 다음을 제어할 수 있어야 합니다.
- 할 수 있는 일
- 누구에 의해
- 액세스 유형
- 읽기
- 쓰다
- 실행
- 추가
- 삭제
- 리스트
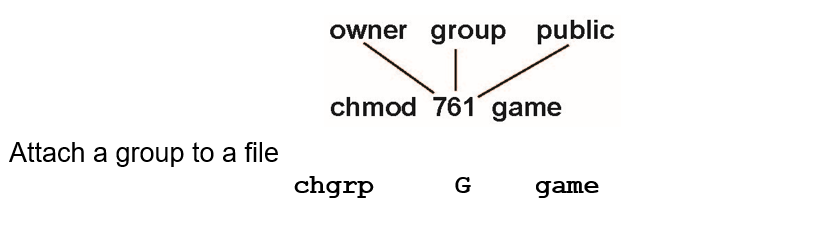
Access Lists and Groups
- Mode of access: read, write, execute
- Three classes of users on Unix / Linux
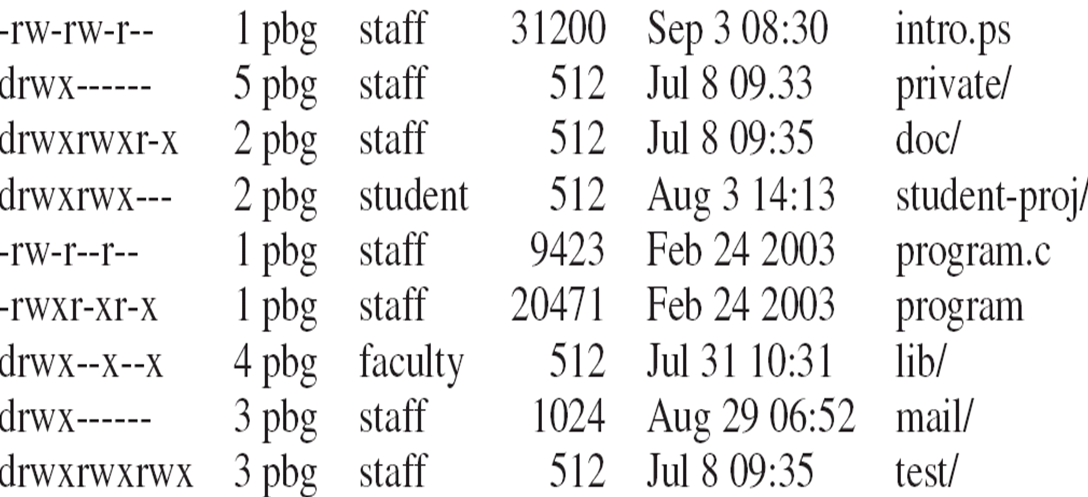
RWX
a) owner access 7 -> 1 1 1
b) group access 6 -> 1 1 0
c) public access 1 -> 0 0 1 - Ask manager to create a group (unique name), say G, and add some users to the group.
- For a particular file (say game) or subdirectory, define an appropriate access.
- 액세스 모드: 읽기, 쓰기, 실행
- Unix/Linux의 세 가지 사용자 클래스
- 관리자에게 그룹(고유한 이름)을 만들고 G라고 말하고 그룹에 일부 사용자를 추가하도록 요청한다.
- 특정 파일(예: 게임) 또는 하위 디렉터리에 대해 적절한 액세스를 정의한다.
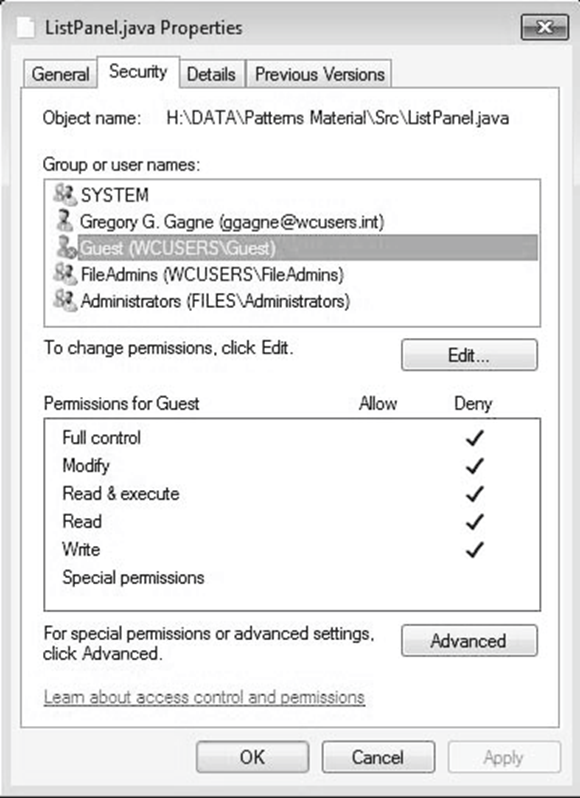
Windows 7 Access-Control List Management
A Sample UNIX Directory Listing