Background
- Program must be brought (from disk) into memory and placed within a process for it to be run
- Main memory and registers are only storage CPU can access directly
- Memory unit only sees a stream of:
- addresses + read requests, or
- address + data and write requests
- Register access is done in one CPU clock (or less)
- Main memory can take many cycles, causing a stall
- Cache sits between main memory and CPU registers
- Protection of memory required to ensure correct operation
- 프로그램을 실행하려면 (디스크에서) 메모리로 가져와 프로세스 내에 배치해야 한다.
- 기본 메모리 및 레지스터는 스토리지 CPU만 직접 액세스할 수 있다.
- 메모리 장치에는 다음 스트림만 표시된다.
- 주소 + 읽기 요청 또는
- 주소 + 데이터 및 쓰기 요청
- 레지스터 액세스는 하나의 CPU clock (or less)에서 수행된다.
- 기본 메모리는 여러 사이클이 소요되어 정지를 유발할 수 있다.
- 캐시는 메인 메모리와 CPU 레지스터 사이에 위치한다.
- 올바른 작동을 위해 필요한 메모리 보호
Protection
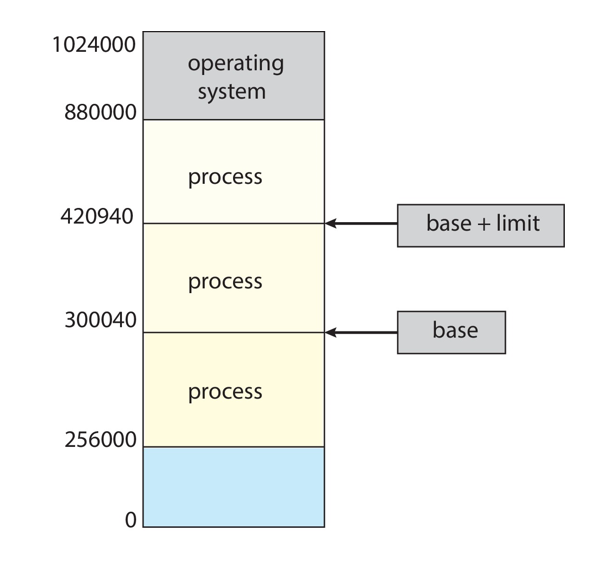
- Need to censure that a process can access only access those addresses in it address space.
- We can provide this protection by using a pair of base and limit registers define the logical address space of a process
- 프로세스가 주소 공간에 있는 해당 주소에만 액세스할 수 있는지 확인해야 한다.
- base와 limit registers 쌍을 사용하여 프로세스의 논리적 주소 공간을 정의함으로써 이러한 보호를 제공할 수 있다.
Hardware Address Protection
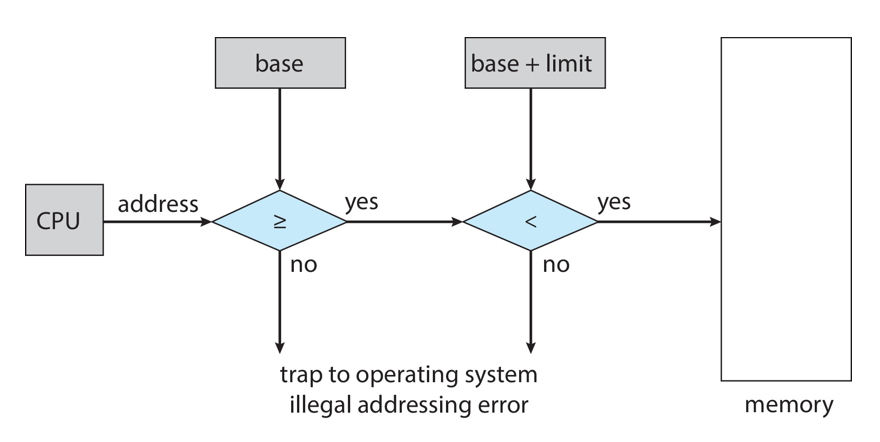
- CPU must check every memory access generated in user mode to be sure it is between base and limit for that user
- CPU는 사용자 모드에서 생성된 모든 메모리 액세스를 확인하여 해당 사용자의 기준과 제한 사이에 있는지 확인해야 한다.
- the instructions to loading the base and limit registers are privileged
- 기본 레지스터 및 제한 레지스터를 로드하는 명령은 권한이 있다.
Address Binding
- Programs on disk, ready to be brought into memory to execute form an input queue
- Without support, must be loaded into address 0000
- Inconvenient to have first user process physical address always at 0000
- How can it not be?
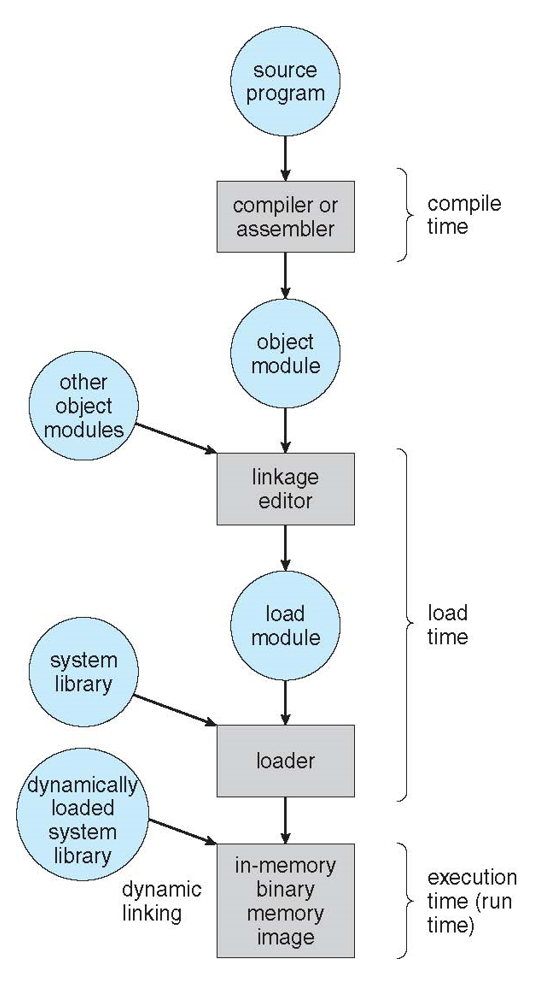
- Addresses represented in different ways at different stages of a program’s life
- Source code addresses usually symbolic
- Compiled code addresses bind to relocatable addresses
- i.e. “14 bytes from beginning of this module”
- Linker or loader will bind relocatable addresses to absolute addresses
- i.e. 74014
- Each binding maps one address space to another
- 디스크에 있는 프로그램, 입력 대기열에서 실행할 수 있도록 메모리에 가져올 준비가 된다.
- 지원되지 않는 경우 주소 0000에 로드해야 한다.
- 항상 0000에 첫 번째 사용자 처리 물리적 주소가 있어야 하는 불편함
- 어떻게 안 그럴 수가 있을까?
- 프로그램 수명의 다른 단계에서 서로 다른 방식으로 표현되는 주소
- 소스 코드 주소는 일반적으로 심볼릭입니다.
- 재배치 가능한 주소로 코드 주소 바인드를 컴파일했습니다.
- 즉, "이 모듈의 시작부터 14바이트"
- 링커 또는 로더가 재배치 가능한 주소를 절대 주소로 바인딩합니다.
- 즉, 74014
- 각 바인딩은 한 주소 공간을 다른 주소 공간에 매핑합니다.
Binding of Instructions and Data to Memory
- Address binding of instructions and data to memory addresses can happen at three different stages
- Compile time: If memory location known a priori, absolute code can be generated; must recompile code if starting location changes
- Load time: Must generate relocatable code if memory location is not known at compile time
- Execution time: Binding delayed until run time if the process can be moved during its execution from one memory segment to another
- Need hardware support for address maps (e.g., base and limit registers)
- 명령어와 데이터를 메모리 주소에 대한 주소 바인딩은 세 가지 다른 단계에서 발생할 수 있다.
- Compile time: 메모리 위치가 priori로 알려진 경우 절대 코드를 생성할 수 있다. 시작 위치가 변경되면 코드를 다시 컴파일해야 한다.
- Load time: 컴파일 시 메모리 위치를 알 수 없는 경우 재배치 가능 코드를 생성해야 한다.
- Execution time: 실행 중에 프로세스가 메모리 세그먼트에서 다른 세그먼트로 이동할 수 있는 경우 실행 시간까지 바인딩이 지연된다.
- address map(예: 기본 레지스터 및 제한 레지스터)에 대한 하드웨어 지원이 필요하다.
Multistep Processing of a User Program
Logical vs. Physical Address Space
- The concept of a logical address space that is bound to a separate physical address space is central to proper memory management
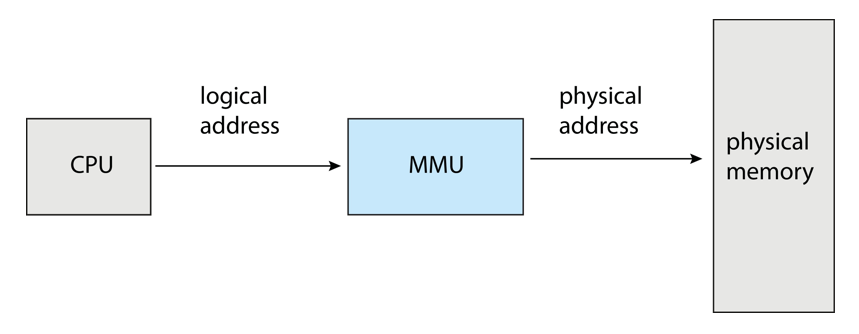
- Logical address – generated by the CPU; also referred to as virtual address
- Physical address – address seen by the memory unit
- Logical and physical addresses are the same in compile-time and load-time address-binding schemes; logical (virtual) and physical addresses differ in execution-time address-binding scheme
- Logical address space is the set of all logical addresses generated by a program
- Physical address space is the set of all physical addresses generated by a program
- 별도의 물리적 주소 공간에 바인딩된 논리적 주소 공간의 개념은 적절한 메모리 관리의 핵심이다.
- 논리 주소 – CPU에 의해 생성되며 가상 주소라고도 한다.
- 물리적 주소 – 메모리 장치에 표시되는 주소이다.
- 논리적 주소와 물리적 주소는 컴파일 타임과 로드 타임 주소 바인딩 체계에서 동일하다. 논리적(가상) 주소와 물리적 주소는 실행 타임 주소 바인딩 체계에서 서로 다르다.
- 논리 주소 공간은 프로그램에 의해 생성된 모든 논리 주소의 집합이다.
- 물리적 주소 공간은 프로그램에 의해 생성된 모든 물리적 주소의 집합이다.
Memory-Management Unit (MMU)
- Hardware device that at run time maps virtual to physical address
- Many methods possible, covered in the rest of this chapter
- 런타임에 가상을 물리적 주소로 매핑하는 하드웨어 디바이스
- 다양한 방법은, 이 장의 나머지 부분에서 다룬다.
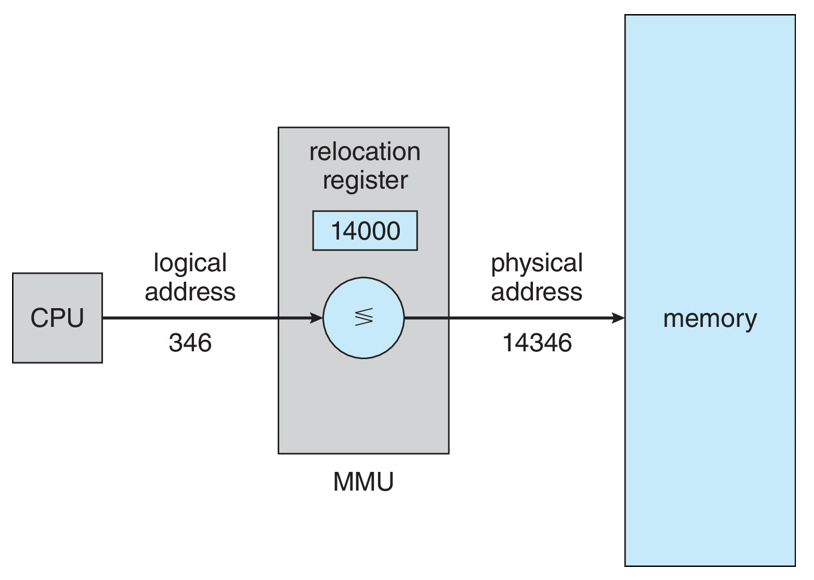
- Consider simple scheme. which is a generalization of the base-register scheme.
- The base register now called relocation register
- The value in the relocation register is added to every address generated by a user process at the time it is sent to memory
- The user program deals with logical addresses; it never sees the real physical addresses
- Execution-time binding occurs when reference is made to location in memory
- Logical address bound to physical addresses
- 간단한 계획을 생각해 보세요. 기본 레지스터 방식의 일반화이다.
- 이제 기본 레지스터는 재배치 레지스터라고 한다.
- 재배치 레지스터의 값은 메모리로 전송될 때 사용자 프로세스에 의해 생성된 모든 주소에 추가된다.
- 사용자 프로그램은 논리적 주소를 처리한다; 그것은 결코 실제 물리적 주소를 보지 못한다.
- 메모리의 위치를 참조할 때 실행 시간 바인딩이 발생한다.
- 물리적 주소에 바인딩된 논리적 주소
Dynamic Loading
- The entire program does need to be in memory to excute
- Routine is not loaded until it is called
- Better memory-space utilization; unused routine is never loaded
- All routines kept on disk in relocatable load format
- Useful when large amounts of code are needed to handle infrequently occurring cases
- No special support from the operating system is required
- Implemented through program design
- OS can help by providing libraries to implement dynamic loading
- 실행하려면 전체 프로그램이 메모리에 있어야 한다.
- 루틴이 호출될 때까지 로드되지 않는다.
- 메모리 공간 활용도 향상, 사용하지 않는 루틴은 로드되지 않는다.
- 재배치 가능한 로드 형식으로 디스크에 보관된 모든 루틴
- 자주 발생하지 않는 사례를 처리하기 위해 많은 양의 코드가 필요할 때 유용하다.
- 운영 체제의 특별한 지원이 필요하지 않다.
- 프로그램 설계를 통해 구현된다.
- 동적 로딩을 구현하기 위한 라이브러리를 제공함으로써 OS가 도움이 될 수 있다.
Dynamic Linking
- Static linking – system libraries and program code combined by the loader into the binary program image
- Dynamic linking –linking postponed until execution time
- Small piece of code, stub, used to locate the appropriate memory-resident library routine
- Stub replaces itself with the address of the routine, and executes the routine
- Operating system checks if routine is in processes’ memory address
- If not in address space, add to address space
- Dynamic linking is particularly useful for libraries
- System also known as shared libraries
- Consider applicability to patching system libraries
- Versioning may be needed
- Static linking – 로더에 의해 바이너리 프로그램 이미지에 결합된 시스템 라이브러리 및 프로그램 코드
- 동적 연결 – 연결이 실행 시간까지 연기됨
- 적절한 메모리 상주 라이브러리 루틴을 찾는 데 사용되는 작은 코드 조각 *stub
- 스텁은 자신을 루틴의 주소로 대체하고 루틴을 실행한다.
- 운영 체제가 프로세스의 메모리 주소에 루틴이 있는지 확인한다.
- 주소 공간에 없는 경우 주소 공간에 추가
- 동적 연결은 특히 라이브러리에 유용하다.
- 공유 라이브러리로도 알려진 시스템
- 패치 적용 시스템 라이브러리에 대한 적용 가능
- 버전 관리가 필요할 수 있다.
Contiguous Memory Allocation
- Main memory must support both OS and user processes
- Limited resource, must allocate efficiently
- Contiguous allocation is one early method
- Main memory usually into two partitions:
- Resident operating system, usually held in low memory with interrupt vector
- User processes then held in high memory
- Each process contained in single contiguous section of memory
- 기본 메모리가 OS 및 사용자 프로세스를 모두 지원해야 함
- 제한된 리소스, 효율적으로 할당해야 함
- 연속 할당은 초기 방법 중 하나이다.
- 기본 메모리는 일반적으로 두 개의 파티션으로 구성된다.
- 일반적으로 인터럽트 벡터가 있는 낮은 메모리에 보관되는 상주 운영 체제
- 사용자 프로세스가 대용량 메모리에 저장됨
- 메모리의 단일 연속 섹션에 포함된 각 프로세스
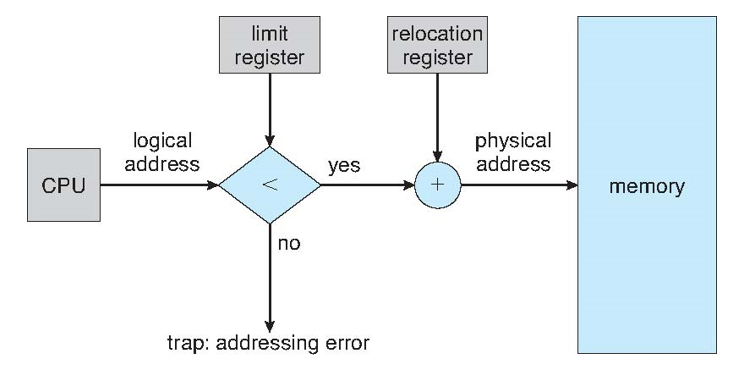
- Relocation registers used to protect user processes from each other, and from changing operating-system code and data
- Base register contains value of smallest physical address
- Limit register contains range of logical addresses – each logical address must be less than the limit register
- MMU maps logical address dynamically
- Can then allow actions such as kernel code being transient and kernel changing size
- 사용자 프로세스를 서로 보호하고 운영 체제 코드 및 데이터가 변경되지 않도록 하는 데 사용되는 재배치 레지스터
- 기본 레지스터에 가장 작은 물리적 주소의 값이 포함되어 있다.
- 제한 레지스터에는 논리 주소 범위가 포함된다. 각 논리 주소는 제한 레지스터보다 작아야 한다.
- MMU가 논리적 주소를 동적으로 매핑한다.
- 그런 다음 커널 코드가 transient가 되고 커널 크기가 변경되는 등의 작업을 허용할 수 있다.
Hardware Support for Relocation and Limit Registers
Variable Partition
- Multiple-partition allocation
- Degree of multiprogramming limited by number of partitions
- Variable-partition sizes for efficiency (sized to a given process’ needs)
- Hole – block of available memory; holes of various size are scattered throughout memory
- When a process arrives, it is allocated memory from a hole large enough to accommodate it
- Process exiting frees its partition, adjacent free partitions combined
- Operating system maintains information about:
- a) allocated partitions
- b) free partitions (hole)
- 다중 파티션 할당
- 파티션 수에 따라 제한된 멀티프로그래밍 정도
- 다양한 파티션 크기로 효율성 향상(특정 프로세스 요구에 맞게 크기 조정)
- 구멍 – 사용 가능한 메모리 블록, 다양한 크기의 구멍이 메모리 전체에 흩어져 있다.
- 프로세스가 도착하면 해당 프로세스를 수용할 수 있을 만큼 충분히 큰 구멍에서 메모리가 할당된다.
- 프로세스를 종료하면 파티션이 해방되고 인접한 사용 가능한 파티션이 결합됨
- 운영 체제는 다음에 대한 정보를 유지 관리한다.
- a) 할당된 파티션
- b) 자유 파티션(구멍)
Dynamic Storage-Allocation Problem
How to satisfy a request of size n from a list of free holes?
- First-fit: Allocate the first hole that is big enough
- Best-fit: Allocate the smallest hole that is big enough; must search entire list, unless ordered by size
- Produces the smallest leftover hole
- Worst-fit: Allocate the largest hole; must also search entire list
- Produces the largest leftover hole
First-fit and best-fit better than worst-fit in terms of speed and storage utilization
- Produces the largest leftover hole
자유 구멍 목록에서 n 크기의 요청을 충족하는 방법은 무엇인가?
- 첫 번째 맞춤: 충분히 큰 첫 번째 구멍을 할당한다.
- 가장 적합: 충분히 큰 구멍을 할당한다. 크기순으로 정렬하지 않는 한 전체 목록을 검색해야 한다.
- 남은 구멍이 가장 작다.
- 가장 적합하지 않음: 가장 큰 구멍을 할당합니다. 또한 전체 목록을 검색한다.
- 가장 큰 남은 구멍을 생성합니다.
속도 및 스토리지 활용률 측면에서 최악의 경우보다 가장 적합하고 가장 적합함
- 가장 큰 남은 구멍을 생성합니다.
Fragmentation
- External Fragmentation – total memory space exists to satisfy a request, but it is not contiguous
- Internal Fragmentation – allocated memory may be slightly larger than requested memory; this size difference is memory internal to a partition, but not being used
- First fit analysis reveals that given N blocks allocated, 0.5 N blocks lost to fragmentation
- 1/3 may be unusable -> 50-percent rule
- 외부 조각화 – 총 메모리 공간이 요청을 충족하기 위해 존재하지만 연속되지는 않는다.
- 내부 조각화 – 할당된 메모리가 요청된 메모리보다 약간 클 수 있다. 이 크기 차이는 파티션 내부의 메모리이지만 사용되지 않는다.
- 첫 번째 적합 분석에 따르면 N개의 블록이 할당되면 0.5N개의 블록이 단편화로 손실된다.
- 1/3을 사용할 수 없음 -> 50% 규칙
- Reduce external fragmentation by compaction
- Shuffle memory contents to place all free memory together in one large block
- Compaction is possible only if relocation is dynamic, and is done at execution time
- I/O problem
- Latch job in memory while it is involved in I/O
- Do I/O only into OS buffers
- Now consider that backing store has same fragmentation problems
- 압축을 통해 외부 단편화 감소
- 메모리 콘텐츠를 셔플하여 사용 가능한 모든 메모리를 하나의 큰 블록에 함께 배치
- 압축은 재배치가 동적인 경우에만 가능하며 실행 시에 수행된다.
- 입출력 문제
- I/O와 관련된 메모리에서 작업 래치
- OS 버퍼에만 I/O 수행
- 이제 백업 저장소에 동일한 조각화 문제가 있다는 점을 고려해라.
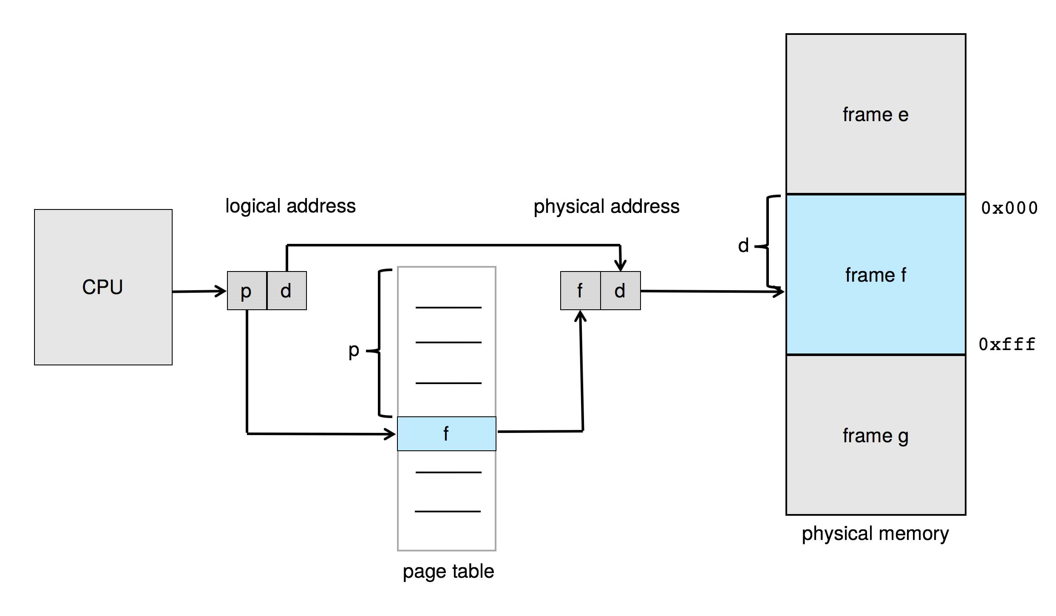
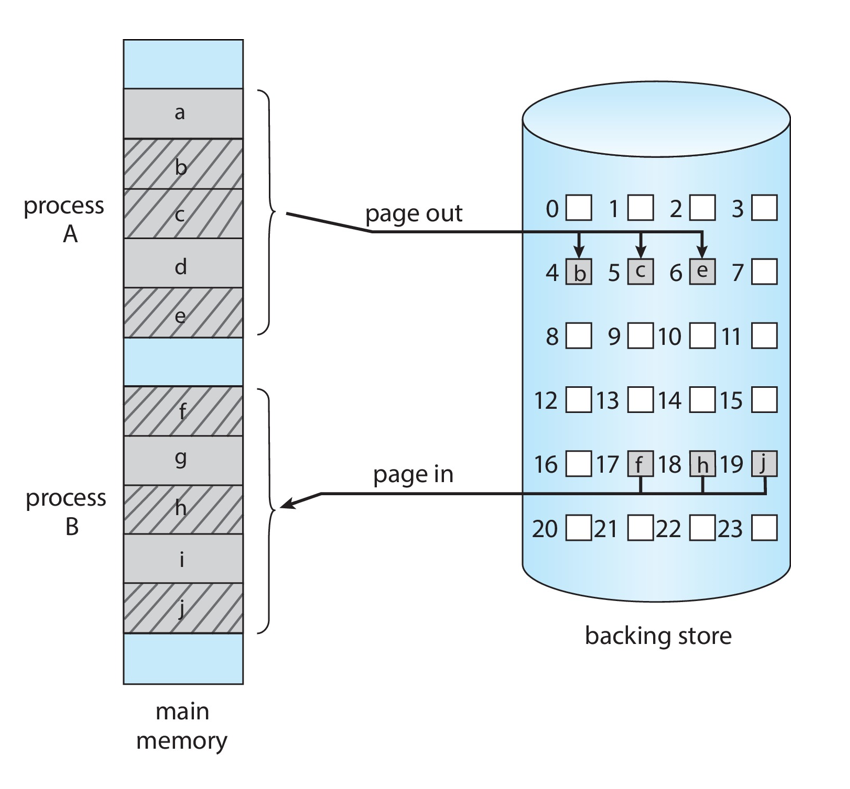
Paging
- Physical address space of a process can be noncontiguous; process is allocated physical memory whenever the latter is available
- Avoids external fragmentation
- Avoids problem of varying sized memory chunks
- Divide physical memory into fixed-sized blocks called frames
- Size is power of 2, between 512 bytes and 16 Mbytes
- Divide logical memory into blocks of same size called pages
- Keep track of all free frames
- To run a program of size N pages, need to find N free frames and load program
- Set up a page table to translate logical to physical addresses
- Backing store likewise split into pages
- Still have Internal fragmentation
- 프로세스의 물리적 주소 공간은 연속되지 않을 수 있으며 프로세스는 물리적 메모리를 사용할 수 있을 때마다 할당된다.
- 외부 단편화 방지
- 다양한 크기의 memory chunk 문제 방지
- 물리적 메모리를 frames라는 고정 크기 블록으로 분할
- 크기는 2의 거듭제곱으로 512바이트에서 16MB 사이
- 논리 메모리를 pages라는 동일한 크기의 블록으로 분할
- 사용 가능한 모든 프레임 추적
- N 페이지 크기의 프로그램을 실행하려면 N개의 빈 프레임을 찾고 프로그램을 로드해야 한다.
- 논리적 주소를 물리적 주소로 변환하는 페이지 테이블 설정
- 백업 저장소도 마찬가지로 페이지로 분할됨
- 여전히 내부 조각화가 있음
Address Translation Scheme
- Address generated by CPU is divided into:
- Page number (p) – used as an index into a page table which contains base address of each page in physical memory
- Page offset (d) – combined with base address to define the physical memory address that is sent to the memory unit
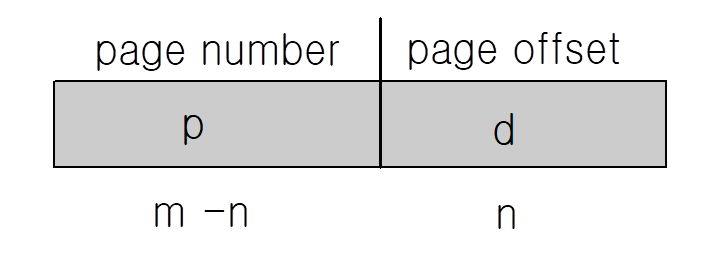
- For given logical address space 2m and page size 2^n
- CPU에서 생성되는 주소는 다음과 같이 구분된다.
- 페이지 번호(p) – 물리적 메모리에 있는 각 페이지의 기본 주소를 포함하는 페이지 테이블의 색인으로 사용된다.
- 페이지 오프셋(d) – 기본 주소와 결합하여 메모리 장치로 전송되는 물리적 메모리 주소를 정의한다.
- 지정된 논리 주소 공간 2m 및 페이지 크기 2^n에 대해
Paging Hardware
Paging Model of Logical and Physical Memory
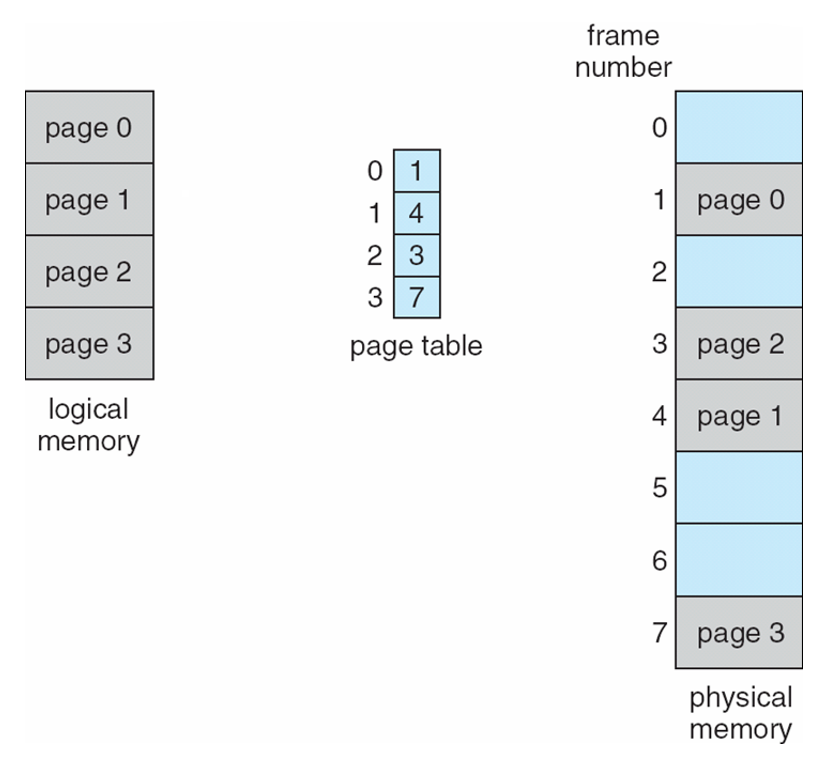
Paging Example
- Logical address: n = 2 and m = 4. Using a page size of 4 bytes and a physical memory of 32 bytes (8 pages)
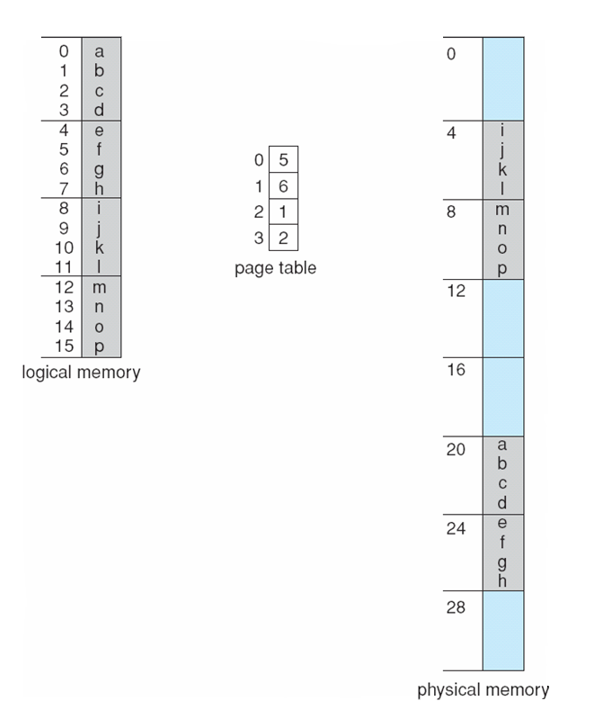
Paging -- Calculating internal fragmentation
- Page size = 2,048 bytes
- Process size = 72,766 bytes
- 35 pages + 1,086 bytes
- Internal fragmentation of 2,048 - 1,086 = 962 bytes
- Worst case fragmentation = 1 frame – 1 byte
- On average fragmentation = 1 / 2 frame size
- So small frame sizes desirable?
- But each page table entry takes memory to track
- Page sizes growing over time
- Solaris supports two page sizes – 8 KB and 4 MB
- 페이지 크기 = 2,048바이트
- 프로세스 크기 = 72,766바이트
- 35페이지 + 1,086바이트
- 2,048 - 1,086 = 962바이트의 내부 조각화
- 최악의 경우 조각화 = 1프레임 – 1바이트
- 평균 조각화 = 1/2 프레임 크기
- 프레임 크기가 작으면 좋은가?
- 그러나 각 페이지 테이블 항목은 추적하는 데 메모리가 필요하다.
- 시간이 지남에 따라 증가하는 페이지 크기
- Solaris는 8KB와 4MB의 두 페이지 크기를 지원한다.
Free Frames
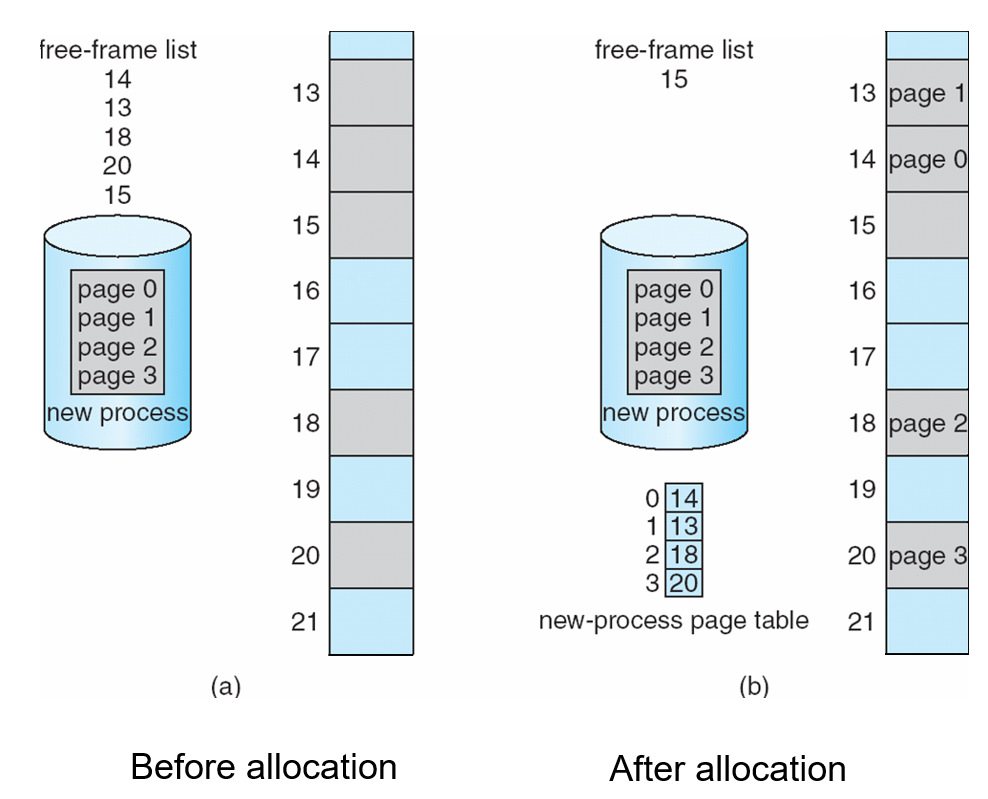
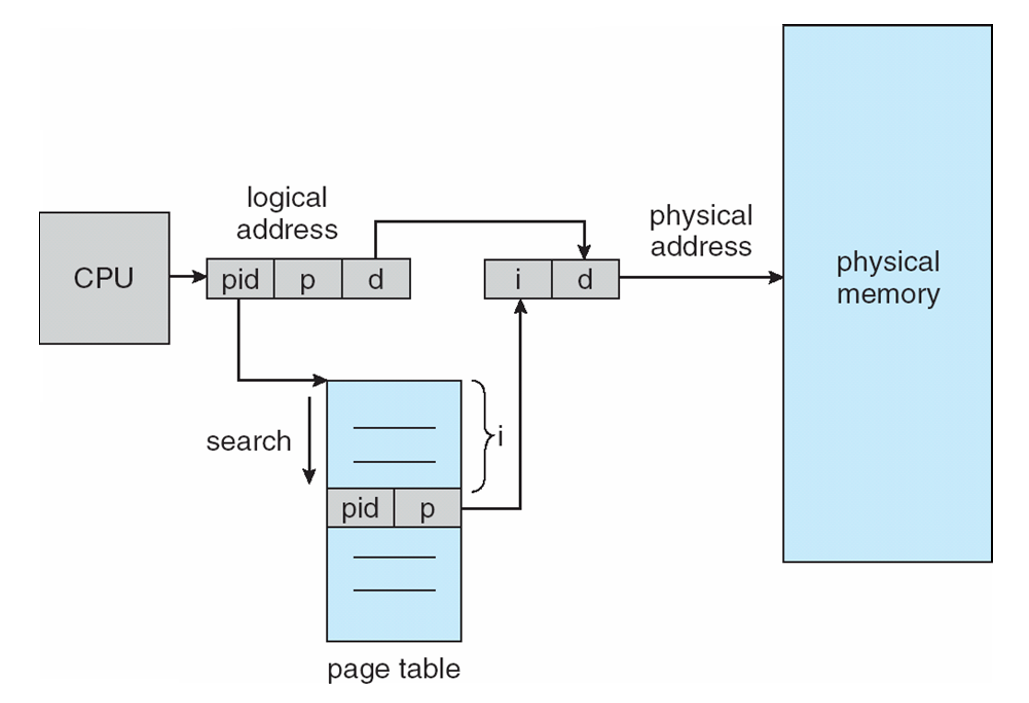
Implementation of Page Table
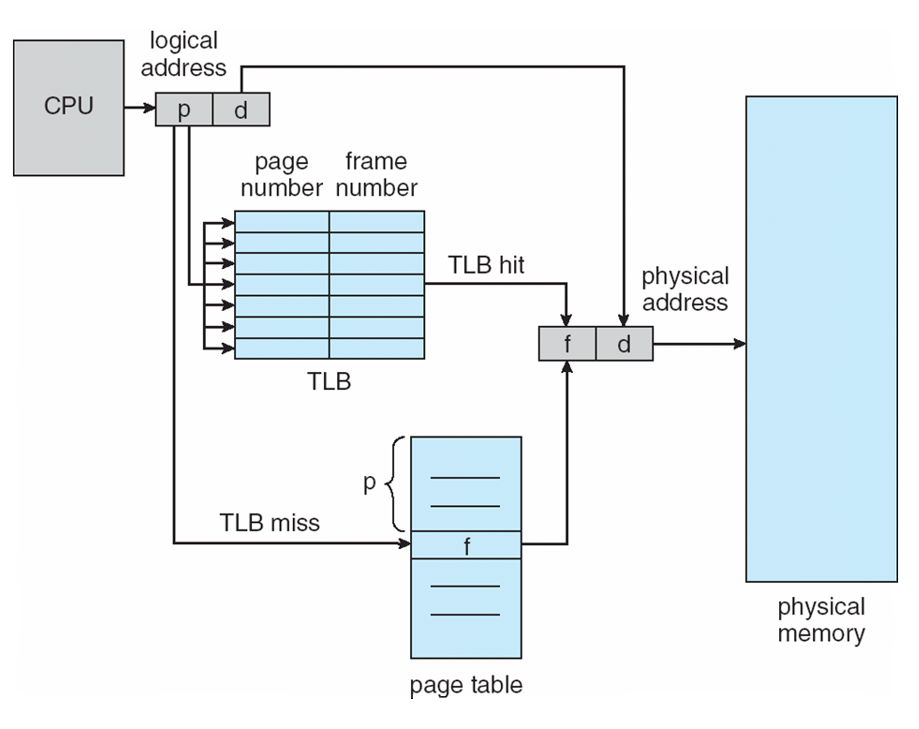
- Page table is kept in main memory
- Page-table base register (PTBR) points to the page table
- Page-table length register (PTLR) indicates size of the page table
- In this scheme every data/instruction access requires two memory accesses
- One for the page table and one for the data / instruction
- The two memory access problem can be solved by the use of a special fast-lookup hardware cache called translation look-aside buffers (TLBs) (also called associative memory).
- 페이지 테이블이 메인 메모리에 유지된다.
- 페이지 테이블 기본 레지스터(PTBR)가 페이지 테이블을 가리킨다.
- 페이지 테이블 길이 레지스터(PTLR)은 페이지 테이블의 크기를 나타낸다.
- 이 체계에서 모든 데이터/명령어 액세스에는 두 개의 메모리 액세스가 필요하다.
- 하나는 페이지 테이블용이고 하나는 데이터/명령어용이다.
- 두 가지 메모리 액세스 문제는 translation Look-aside buffers(TLBs)(associative memory라고도 함)라는 특수한 빠른 검색 하드웨어 캐시를 사용하여 해결할 수 있다.
Translation Look-Aside Buffer
- Some TLBs store address-space identifiers (ASIDs) in each TLB entry – uniquely identifies each process to provide address-space protection for that process
- Otherwise need to flush at every context switch
- TLBs typically small (64 to 1,024 entries)
- On a TLB miss, value is loaded into the TLB for faster access next time
- Replacement policies must be considered
- Some entries can be wired down for permanent fast access
- 일부 TLB는 각 TLB 항목에 ASID(주소 공간 식별자)를 저장한다. 각 프로세스를 고유하게 식별하여 해당 프로세스에 주소 공간 보호 기능을 제공한다.
- 그렇지 않으면 모든 컨텍스트 스위치에서 플러시해야 한다.
- 일반적으로 작은 TLBs(64~1,024개 항목)
- TLB 미스의 경우 다음 번에 더 빠른 액세스를 위해 값이 TLB에 로드된다.
- 교체 정책을 고려해야 한다.
- 영구적인 빠른 액세스를 위해 일부 항목을 유선으로 연결할 수 있다.
Hardware
- Associative memory – parallel search
- Address translation (p, d)
- If p is in associative register, get frame # out
- Otherwise get frame # from page table in memory
- 연상 메모리 – 병렬 검색
- 주소 변환(p, d)
- p가 연상 레지스터에 있으면 프레임 번호를 가져온다.
- 그렇지 않으면 메모리의 페이지 테이블에서 프레임 번호를 가져온다.
Paging Hardware With TLB
Effective Access Time
- Hit ratio – percentage of times that a page number is found in the TLB
- An 80% hit ratio means that we find the desired page number in the TLB 80% of the time.
- Suppose that 10 nanoseconds to access memory.
- If we find the desired page in TLB then a mapped-memory access take 10 ns
- Otherwise we need two memory access so it is 20 ns
- Effective Access Time (EAT)
- EAT = 0.80 x 10 + 0.20 x 20 = 12 nanoseconds
- implying 20% slowdown in access time
- Consider amore realistic hit ratio of 99%,
- EAT = 0.99 x 10 + 0.01 x 20 = 10.1ns
- implying only 1% slowdown in access time.
- 적중률 – TLB에서 페이지 번호를 찾은 횟수(%)
- 적중률이 80%라는 것은 TLB에서 원하는 페이지 번호를 80%라는 것을 의미한다.
- 메모리에 액세스하는 데 10나노초가 걸린다고 가정한다.
- 만약 우리가 TLB에서 원하는 페이지를 찾는다면, 매핑된 메모리 액세스는 10ns
- 그렇지 않으면 메모리 액세스가 두 번 필요하므로 20ns이다.
- 유효 액세스 시간(EAT)
- EAT = 0.80 x 10 + 0.20 x 20 = 12 나노초
- 액세스 시간이 20% 단축됨
- 99%의 보다 현실적인 적중률을 고려해 보라.
- EAT = 0.99 x 10 + 0.01 x 20 = 10.1ns
- 액세스 시간이 1%밖에 느려지지 않았음을 의미한다.
Memory Protection
- Memory protection implemented by associating protection bit with each frame to indicate if read-only or read-write access is allowed
- Can also add more bits to indicate page execute-only, and so on
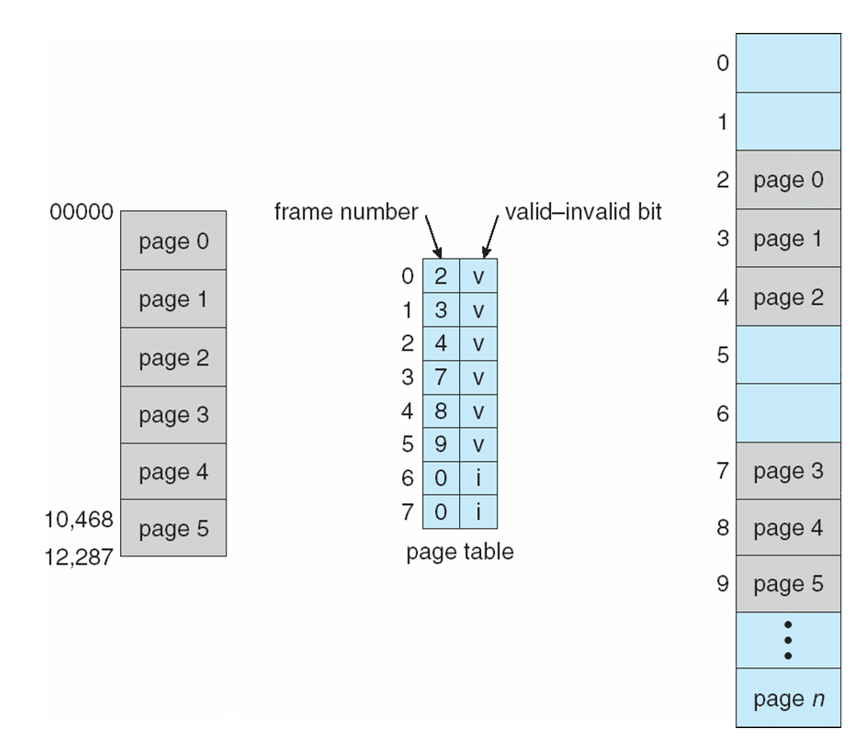
- Valid-invalid bit attached to each entry in the page table:
- “valid” indicates that the associated page is in the process’ logical address space, and is thus a legal page
- “invalid” indicates that the page is not in the process’ logical address space
- Or use page-table length register (PTLR)
- Any violations result in a trap to the kernel
- 각 프레임에 보호 비트를 연결하여 읽기 전용 또는 읽기-쓰기 액세스가 허용되는지 여부를 표시함으로써 구현된 메모리 보호
- 페이지 실행 전용 등을 나타내기 위해 비트를 추가할 수도 있다.
- Valid-invalid 비트가 페이지 테이블의 각 항목에 연결되었다.
- "valid"는 연결된 페이지가 프로세스의 논리적 주소 공간에 있으므로 합법적인 페이지임을 나타낸다.
- 페이지가 프로세스의 논리적 주소 공간에 없음을 나타낸다.
- 또는 페이지 테이블 길이 레지스터(PTL)를 사용해라.
- 위반 시 커널에 트랩이 발생한다.
Valid(v) or Invalid(i) Bit In A Page Table
Shared Pages
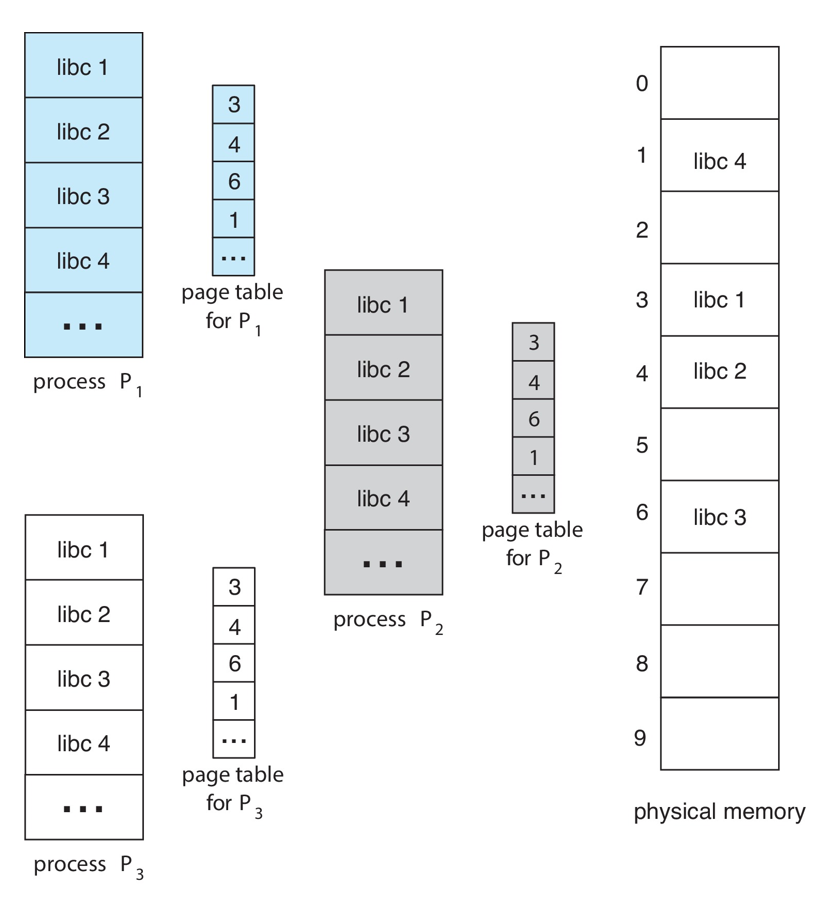
- Shared code
- One copy of read-only (reentrant) code shared among processes (i.e., text editors, compilers, window systems)
- Similar to multiple threads sharing the same process space
- Also useful for interprocess communication if sharing of read-write pages is allowed
- Private code and data
- Each process keeps a separate copy of the code and data
- The pages for the private code and data can appear anywhere in the logical address space
- 공유 코드
- 프로세스 간에 공유되는 읽기 전용(reentrent) 코드 복사본 1개(예: 텍스트 편집기, 컴파일러, 창 시스템)
- 동일한 프로세스 공간을 공유하는 여러 스레드와 유사하다.
- 읽기-쓰기 페이지 공유가 허용되는 경우 프로세스 간 통신에도 유용하다.
- 개인 코드 및 데이터
- 각 프로세스는 코드와 데이터의 별도 사본을 보관한다.
- 개인 코드 및 데이터에 대한 페이지는 논리적 주소 공간의 모든 위치에 나타날 수 있다.
Shared Pages Example
Structure of the Page Table
- Memory structures for paging can get huge using straight-forward methods
- Consider a 32-bit logical address space as on modern computers
- Page size of 4 KB (2^12)
- Page table would have 1 million entries (2^32 / 2^12)
- If each entry is 4 bytes -> each process 4 MB of physical address space for the page table alone
- Don’t want to allocate that contiguously in main memory
- One simple solution is to divide the page table into smaller units
- Hierarchical Paging
- Hashed Page Tables
- Inverted Page Tables
- 페이징을 위한 메모리 구조는 간단한 방법을 사용하면 커질 수 있다.
- 최신 컴퓨터에서와 같이 32비트 논리적 주소 공간을 고려해라.
- 페이지 크기 4KB(2^12)
- 페이지 테이블에는 100만 개의 항목이 있다(2^32 / 2^12).
- 각 항목이 4바이트인 경우 -> 각 프로세스는 페이지 테이블에 대한 4MB의 물리적 주소 공간만 처리한다.
- 주 메모리에 연속적으로 할당하고 싶지 않음
- 한 가지 간단한 해결책은 페이지 테이블을 더 작은 단위로 나누는 것이다.
- 계층 페이징
- 해시된 페이지 테이블
- 반전된 페이지 테이블
Hierarchical Page Tables
- Break up the logical address space into multiple page tables
- A simple technique is a two-level page table
- We then page the page table
- 논리적 주소 공간을 여러 페이지 테이블로 분할한다.
- 간단한 기술은 2단계 페이지 테이블이다.
- 그런 다음 페이지 테이블을 호출한다.
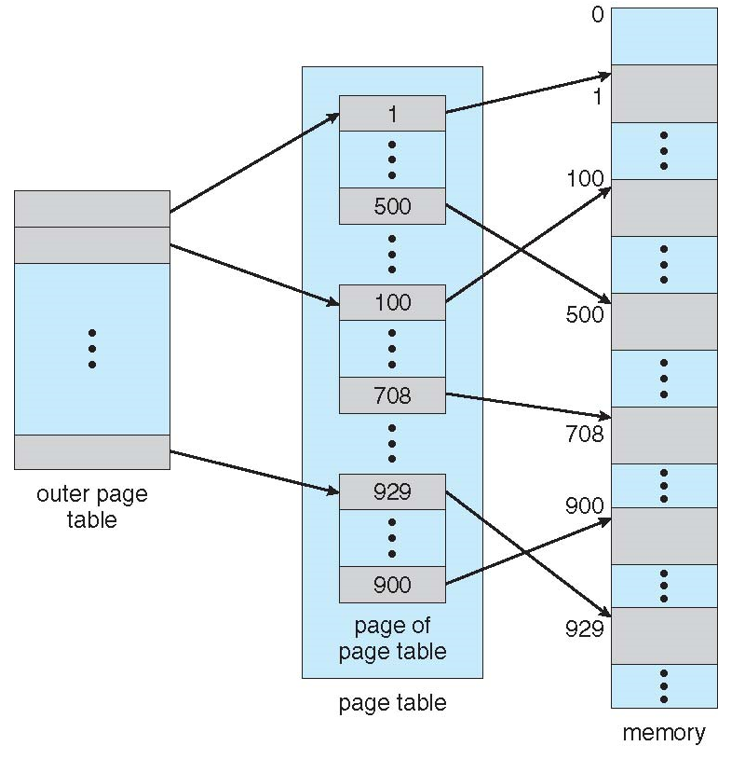
Two-Level Paging Example
- A logical address (on 32-bit machine with 1K page size) is divided into:
- a page number consisting of 22 bits
- a page offset consisting of 10 bits
- Since the page table is paged, the page number is further divided into:
- a 10-bit page number
- a 12-bit page offset
- Thus, a logical address is as follows:
- 논리 주소(1K 페이지 크기의 32비트 시스템)는 다음과 같이 나뉜다.
- 22비트로 구성된 페이지 번호
- 10비트로 구성된 페이지 오프셋
- 페이지 테이블이 호출되므로 페이지 번호는 다음과 같이 추가로 나뉜다.
- 10비트 페이지 번호
- 12비트 페이지 오프셋
- 따라서 논리적 주소는 다음과 같다.
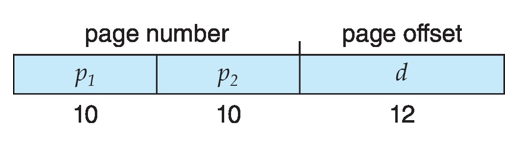
- where p1 is an index into the outer page table, and p2 is the displacement within the page of the inner page table
- Known as forward-mapped page table
- 여기서 p1은 외부 페이지 테이블의 인덱스이고, p2는 내부 페이지 테이블의 페이지 내 변위이다.
- forward-mapped page table로 알려져 있다.
Address-Translation Scheme
64-bit Logical Address Space
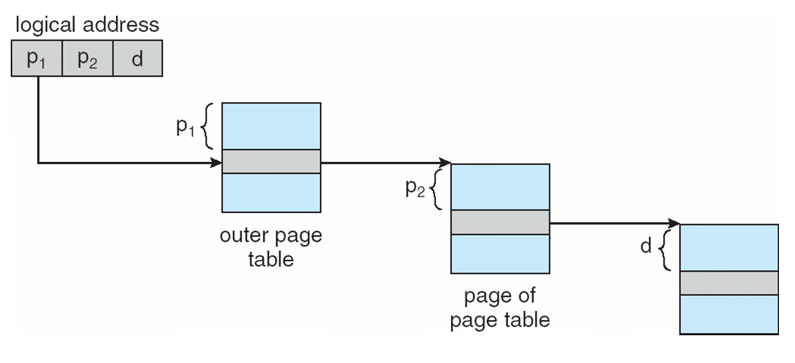
- Even two-level paging scheme not sufficient
- If page size is 4 KB (2^12)
- Then page table has 2^52 entries
- If two level scheme, inner page tables could be 210 4-byte entries
- Address would look like
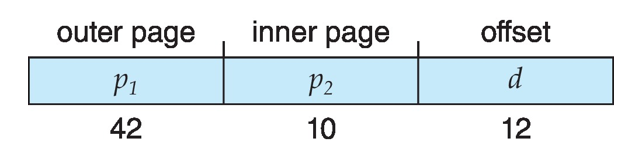
- Outer page table has ^242 entries or 2^44 bytes
- One solution is to add a 2nd outer page table
- But in the following example the 2nd outer page table is still 234 bytes in size
- And possibly 4 memory access to get to one physical memory location
- 2단계 페이징 체계도 충분하지 않다.
- 페이지 크기가 4KB인 경우(2^12)
- 그러면 페이지 테이블에 2^52 항목이 있다.
- 두 개의 수준 체계인 경우, 내부 페이지 테이블은 2104바이트 항목이 될 수 있습니다.
- 주소는 다음과 같습니다. (그림)
- 외부 페이지 테이블에는 2^42개의 항목 또는 2^44 바이트가 있다.
- 한 가지 해결책은 두 번째 외부 페이지 테이블을 추가하는 것이다.
- 그러나 다음 예제에서 두 번째 외부 페이지 테이블의 크기는 여전히 234바이트이다.
- 또한 하나의 물리적 메모리 위치에 도달하기 위해 4개의 메모리 액세스가 가능하다.
Three-level Paging Scheme
Hashed Page Tables
- Common in address spaces > 32 bits
- The virtual page number is hashed into a page table
- This page table contains a chain of elements hashing to the same location
- Each element contains (1) the virtual page number (2) the value of the mapped page frame (3) a pointer to the next element
- Virtual page numbers are compared in this chain searching for a match
- If a match is found, the corresponding physical frame is extracted
- Variation for 64-bit addresses is clustered page tables
- Similar to hashed but each entry refers to several pages (such as 16) rather than 1
- Especially useful for sparse address spaces (where memory references are non-contiguous and scattered)
- 32비트 이상의 주소 공간에서 공통
- 가상 페이지 번호가 페이지 테이블에 해시된다.
- 이 페이지 테이블에는 동일한 위치에 대한 요소 해시 체인이 포함되어 있다.
- 각 요소에는 (1)가상 페이지 번호(2)매핑된 페이지 프레임의 값 (3)다음 요소에 대한 포인터가 포함된다.
- 이 체인에서 일치 항목을 검색하는 가상 페이지 번호가 비교된다.
- 일치하는 항목이 발견되면 해당 물리적 프레임이 추출된다.
- 64비트 주소의 경우 클러스터된 페이지 테이블이(가) 다르다.
- 해시와 비슷하지만 각 항목은 1이 아닌 여러 페이지(예: 16)를 참조한다.
- 특히 sparse 주소 공간(메모리 참조가 비연속적이고 흩어져 있는 경우)에 유용하다.
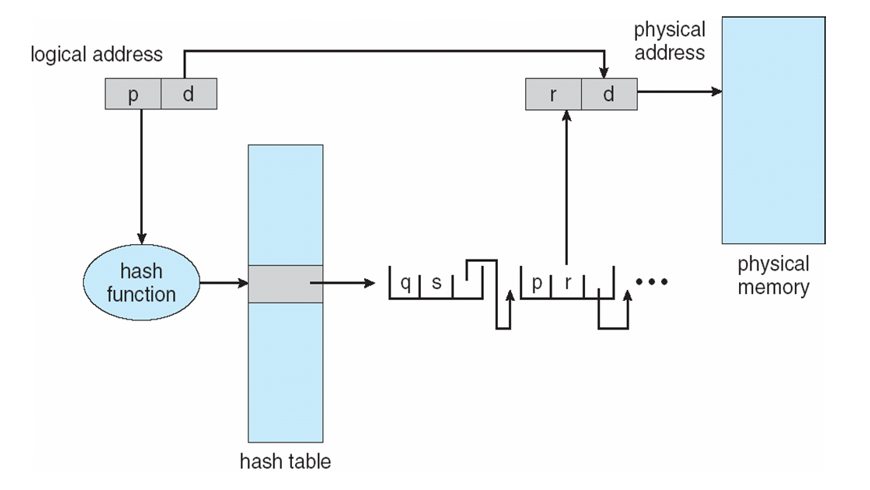
Inverted Page Table
- Rather than each process having a page table and keeping track of all possible logical pages, track all physical pages
- One entry for each real page of memory
- Entry consists of the virtual address of the page stored in that real memory location, with information about the process that owns that page
- Decreases memory needed to store each page table, but increases time needed to search the table when a page reference occurs
- Use hash table to limit the search to one — or at most a few — page-table entries
- TLB can accelerate access
- But how to implement shared memory?
- One mapping of a virtual address to the shared physical address
- 각 프로세스에 페이지 테이블이 있고 가능한 모든 논리 페이지를 추적하는 대신 모든 실제 페이지를 추적한다.
- 메모리의 각 실제 페이지에 대해 하나의 항목
- 항목은 실제 메모리 위치에 저장된 페이지의 가상 주소와 해당 페이지를 소유하는 프로세스에 대한 정보로 구성된다.
- 각 페이지 테이블을 저장하는 데 필요한 메모리를 줄이지만 페이지 참조가 발생할 때 테이블을 검색하는 데 필요한 시간을 늘린다.
- 해시 테이블을 사용하여 검색을 하나 또는 최대 몇 개의 페이지 테이블 항목으로 제한
- TLB는 액세스를 가속화할 수 있다.
- 그러나 공유 메모리를 어떻게 구현할 것인가?
- 공유 물리적 주소에 대한 가상 주소의 단일 매핑
Inverted Page Table Architecture
Oracle SPARC Solaris
- Consider modern, 64-bit operating system example with tightly integrated HW
- Goals are efficiency, low overhead
- Based on hashing, but more complex
- Two hash tables
- One kernel and one for all user processes
- Each maps memory addresses from virtual to physical memory
- Each entry represents a contiguous area of mapped virtual memory,
- More efficient than having a separate hash-table entry for each page
- Each entry has base address and span (indicating the number of pages the entry represents)
- 하드웨어가 긴밀하게 통합된 최신 64비트 운영 체제의 예를 생각해 보라.
- 목표는 효율성, 낮은 오버헤드
- 해싱을 기반으로 하지만 더 복잡하다.
- 해시 테이블 두 개
- 모든 사용자 프로세스에 대해 하나의 커널 및 하나
- 각 메모리 주소를 가상 메모리에서 물리적 메모리로 매핑
- 각 항목은 매핑된 가상 메모리의 인접 영역을 나타낸다.
- 각 페이지에 대해 별도의 해시 테이블 항목을 갖는 것보다 효율적이다.
- 각 항목에는 기본 주소와 범위(항목이 나타내는 페이지 수를 나타냄)가 있다.
- TLB holds translation table entries (TTEs) for fast hardware lookups
- A cache of TTEs reside in a translation storage buffer (TSB)
- Includes an entry per recently accessed page
- A cache of TTEs reside in a translation storage buffer (TSB)
- Virtual address reference causes TLB search
- If miss, hardware walks the in-memory TSB looking for the TTE corresponding to the address
- If match found, the CPU copies the TSB entry into the TLB and translation completes
- If no match found, kernel interrupted to search the hash table
- The kernel then creates a TTE from the appropriate hash table and stores it in the TSB, Interrupt handler returns control to the MMU, which completes the address translation.
- If miss, hardware walks the in-memory TSB looking for the TTE corresponding to the address
- TLB는 빠른 하드웨어 조회를 위해 TTE(Translation Table Entry)를 보유한다.
- TTE의 캐시는 TSB(Translation Storage Buffer)에 상주한다.
- 최근 액세스한 페이지당 항목 포함
- TTE의 캐시는 TSB(Translation Storage Buffer)에 상주한다.
- 가상 주소 참조로 인해 TLB 검색이 발생함
- 누락된 경우 하드웨어는 주소에 해당하는 TTE를 찾기 위해 메모리 내 TSB를 이동한다.
- 일치하는 항목이 발견되면 CPU가 TSB 항목을 TLB로 복사하고 변환이 완료된다.
- 일치하는 항목이 없으면 커널이 해시 테이블 검색을 중단했다.
- 커널은 적절한 해시 테이블에서 TTE를 생성하여 TSB에 저장하고, 인터럽트 핸들러는 MMU로 제어권을 반환하여 주소 변환을 완료한다.
- 누락된 경우 하드웨어는 주소에 해당하는 TTE를 찾기 위해 메모리 내 TSB를 이동한다.
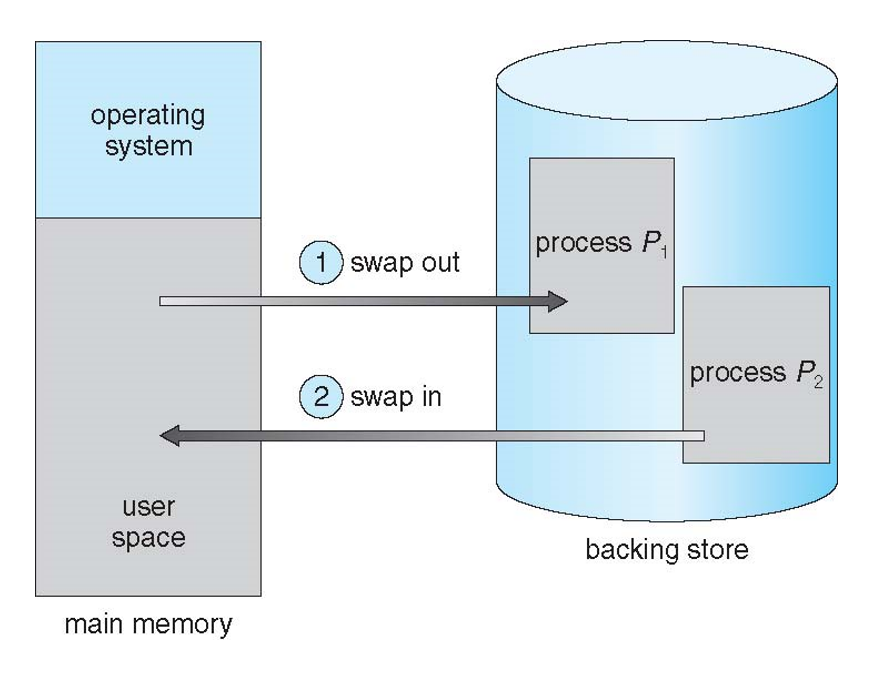
Swapping
- A process can be swapped temporarily out of memory to a backing store, and then brought back into memory for continued execution
- Total physical memory space of processes can exceed physical memory
- Backing store – fast disk large enough to accommodate copies of all memory images for all users; must provide direct access to these memory images
- Roll out, roll in – swapping variant used for priority-based scheduling algorithms; lower-priority process is swapped out so higher-priority process can be loaded and executed
- Major part of swap time is transfer time; total transfer time is directly proportional to the amount of memory swapped
- System maintains a ready queue of ready-to-run processes which have memory images on disk
- 프로세스를 일시적으로 메모리가 부족한 상태로 백업 저장소로 swap한 후 계속 실행하기 위해 메모리로 다시 가져올 수 있습니다.
- 프로세스의 총 물리적 메모리 공간이 물리적 메모리를 초과할 수 있음
- Backing store – 모든 사용자가 사용할 수 있는 모든 메모리 이미지의 복사본을 수용할 수 있을 만큼 충분히 큰 빠른 디스크. 이러한 메모리 이미지에 직접 액세스할 수 있어야 한다.
- Roll out, roll in – 우선순위 기반 스케줄링 알고리즘에 사용되는 스왑 변형. 우선순위가 낮은 프로세스가 스왑 아웃되므로 우선순위가 높은 프로세스를 로드하고 실행할 수 있다.
- 스왑 시간의 주요 부분은 전송 시간이며, 총 전송 시간은 스왑된 메모리 양에 정비례한다.
- 시스템은 디스크에 메모리 이미지가 있는 실행 준비 프로세스의 ready 큐를 유지 관리한다.
- Does the swapped out process need to swap back in to same physical addresses?
- Depends on address binding method
- Plus consider pending I/O to / from process memory space
- Modified versions of swapping are found on many systems (i.e., UNIX, Linux, and Windows)
- Swapping normally disabled
- Started if more than threshold amount of memory allocated
- Disabled again once memory demand reduced below threshold
- 스왑 아웃 프로세스가 동일한 물리적 주소로 다시 스왑해야 하는가?
- 주소 바인딩 방법에 따라 다름
- 또한 프로세스 메모리 공간에 I/O를 대기하는 것도 고려해 보라.
- 많은 시스템(예: UNIX, Linux 및 Windows)에서 스왑의 수정된 버전을 찾을 수 있다.
- 스와핑이 정상적으로 비활성화됨
- 할당된 메모리 양이 임계값을 초과할 경우 시작됨
- 메모리 요구량이 임계값 미만으로 감소하면 다시 비활성화됨
Schematic View of Swapping
Context Switch Time including Swapping
- If next processes to be put on CPU is not in memory, need to swap out a process and swap in target process
- Context switch time can then be very high
- 100MB process swapping to hard disk with transfer rate of 50MB/sec
- Swap out time of 2000 ms
- Plus swap in of same sized process
- Total context switch swapping component time of 4000ms (4 seconds)
- Can reduce if reduce size of memory swapped – by knowing how much memory really being used
- System calls to inform OS of memory use via request_memory() and release_memory()
- CPU에 배치할 다음 프로세스가 메모리에 없는 경우 프로세스를 스왑 아웃하고 대상 프로세스에서 스왑 인해야 한다.
- 그러면 컨텍스트 전환 시간이 매우 길어질 수 있다.
- 전송 속도가 50MB/sec인 하드 디스크로 100MB 프로세스 스왑
- 2000ms의 스왑 아웃 시간
- 동일한 크기의 프로세스를 스왑 인
- 총 컨텍스트 스위치 스왑 구성 요소 시간(4초)
- 실제로 사용 중인 메모리 양을 파악하여 스왑된 메모리 크기를 줄일 수 있다.
- request_memory() 및 release_memory()를 통해 메모리 사용을 OS에 알리기 위한 시스템 호출
- Other constraints as well on swapping
- Pending I/O – can’t swap out as I/O would occur to wrong process
- Or always transfer I/O to kernel space, then to I/O device
- Known as double buffering, adds overhead
- Standard swapping not used in modern operating systems
- But modified version common
- Swap only when free memory extremely low
- But modified version common
- 스와핑에 대한 기타 제약 사항
- 보류 중인 I/O – 잘못된 프로세스로 인해 I/O가 발생하므로 교환할 수 없다.
- 또는 항상 I/O를 커널 공간으로 전송한 다음 I/O 장치로 전송한다.
- 이중 버퍼링으로 알려진 오버헤드 추가
- 최신 운영 체제에서 사용되지 않는 표준 스왑
- 그러나 수정된 버전 공통
- 사용 가능한 메모리가 극도로 부족한 경우에만 스왑
- 그러나 수정된 버전 공통
Swapping on Mobile Systems
- Not typically supported
- Flash memory based
- Small amount of space
- Limited number of write cycles
- Poor throughput between flash memory and CPU on mobile platform
- Flash memory based
- Instead use other methods to free memory if low
- iOS asks apps to voluntarily relinquish allocated memory
- Read-only data thrown out and reloaded from flash if needed
- Failure to free can result in termination
- Android terminates apps if low free memory, but first writes application state to flash for fast restart
- Both OSes support paging as discussed below
- iOS asks apps to voluntarily relinquish allocated memory
- 일반적으로 지원되지 않음
- 플래시 메모리 기반
- 공간이 적음
- 쓰기 주기 수가 제한됨
- 모바일 플랫폼의 플래시 메모리와 CPU 간 처리량 저하
- 플래시 메모리 기반
- 대신 메모리가 부족한 경우 다른 방법을 사용하여 메모리를 확보하십시오.
- iOS가 앱에 할당된 메모리를 자발적으로 포기하도록 요청합니다.
- 필요한 경우 플래시에서 삭제되고 다시 로드되는 읽기 전용 데이터
- 해제하지 않으면 종료될 수 있습니다.
- Android는 사용 가능한 메모리가 부족할 경우 앱을 종료하지만, 빠른 재시작을 위해 먼저 응용 프로그램 상태를 플래시에 기록합니다.
- 아래 설명된 대로 두 OS 모두 페이징을 지원한다.
- iOS가 앱에 할당된 메모리를 자발적으로 포기하도록 요청합니다.
Example: The Intel 32 and 64-bit Architectures
- Dominant industry chips
- Pentium CPUs are 32-bit and called IA-32 architecture
- Current Intel CPUs are 64-bit and called IA-64 architecture
- Many variations in the chips, cover the main ideas here
- 지배적인 업계 칩
- 펜티엄 CPU는 32비트이며 IA-32 아키텍처라고 불린다.
- 현재 Intel CPU는 64비트이며 IA-64 아키텍처라고 한다.
- 칩의 많은 변형, 여기서 주요 아이디어를 다룬다.
Example: The Intel IA-32 Architecture
- Supports both segmentation and segmentation with paging
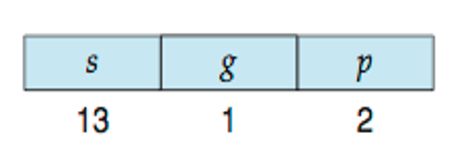
- Each segment can be 4 GB
- Up to 16 K segments per process
- Divided into two partitions
- First partition of up to 8 K segments are private to process (kept in local descriptor table (LDT))
- Second partition of up to 8K segments shared among all processes (kept in global descriptor table (GDT))
- 페이징을 통한 세분화 및 세분화 지원
- 각 세그먼트는 4GB가 될 수 있다.
- 프로세스당 최대 16K 세그먼트
- 두 개의 파티션으로 분할
- 최대 8K 세그먼트의 첫 번째 파티션은 비공개로 처리된다 (Local Descriptor Table(LDT)에 보관됨)
- 모든 프로세스 간에 공유되는 최대 8K 세그먼트의 두 번째 파티션 (Global Descriptor Table(GDT)에 보관된)
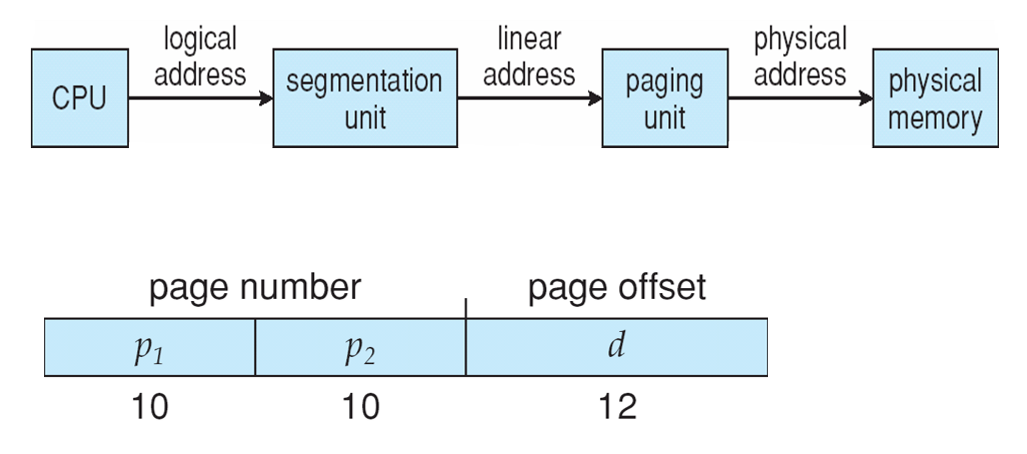
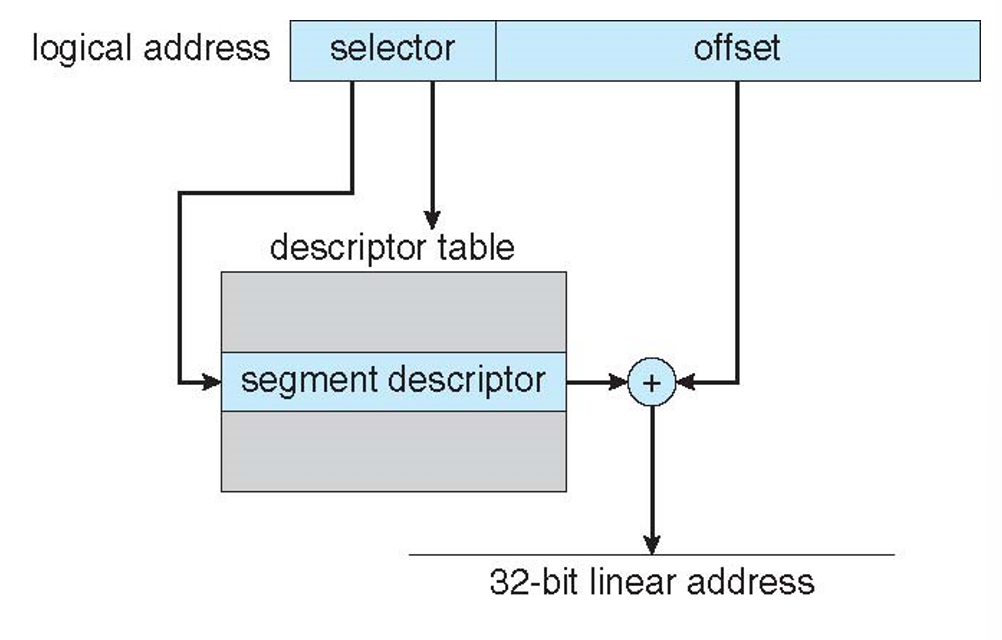
- CPU generates logical address
- Selector given to segmentation unit
* Which produces linear addresses
- Selector given to segmentation unit
- Linear address given to paging unit
- Which generates physical address in main memory
- Paging units form equivalent of MMU
- Pages sizes can be 4 KB or 4 MB
- CPU가 논리적 주소를 생성한다.
- 분할 장치에 지정된 선택기
- 선형 주소를 생성한다.
- 분할 장치에 지정된 선택기
- 페이징 장치에 지정된 선형 주소
- 주 메모리에 물리적 주소를 생성한다.
- MMU와 동등한 형태의 페이징 유닛
- 페이지 크기는 4KB 또는 4MB일 수 있다.
Logical to Physical Address Translation in IA-32
Intel IA-32 Segmentation
Intel IA-32 Paging Architecture
Intel IA-32 Page Address Extensions
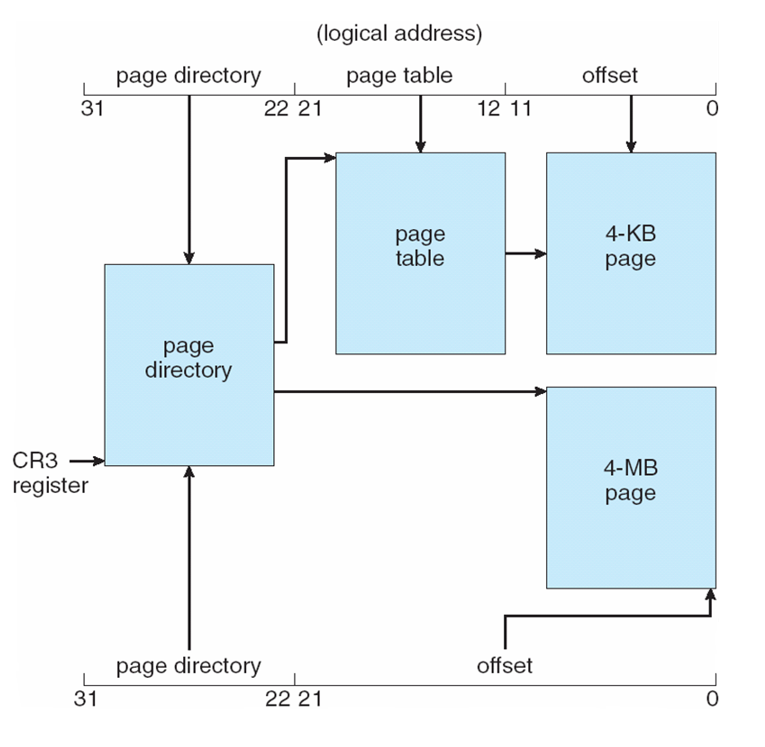
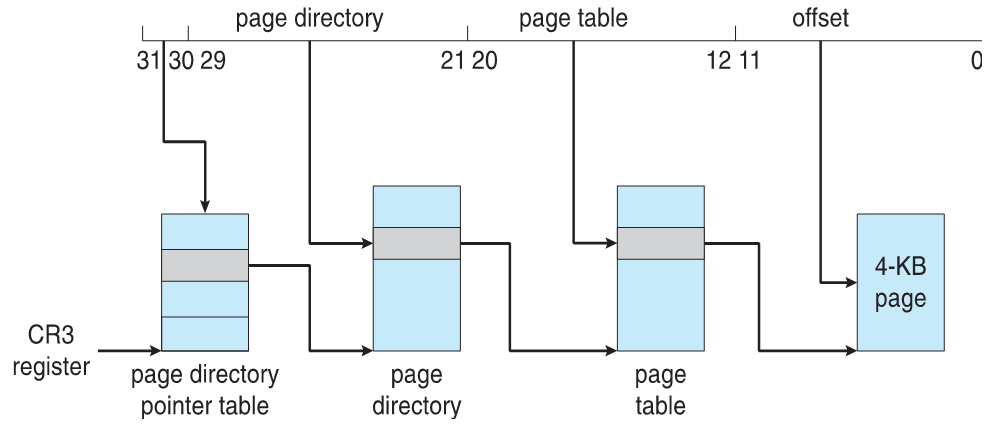
- 32-bit address limits led Intel to create page address extension (PAE), allowing 32-bit apps access to more than 4GB of memory space
- Paging went to a 3-level scheme
- Top two bits refer to a page directory pointer table
- Page-directory and page-table entries moved to 64-bits in size
- Net effect is increasing address space to 36 bits – 64GB of physical memory
- 32비트 주소 제한으로 인해 Intel은 페이지 주소 확장(PAE)을 생성하여 32비트 앱에서 4GB 이상의 메모리 공간에 액세스할 수 있게 되었다.
- 페이징이 3단계 체계로 넘어갔습니다.
- 상위 2비트는 페이지 디렉토리 포인터 테이블을 참조합니다.
- 페이지 디렉토리 및 페이지 테이블 항목이 64비트 크기로 이동됨
- 주소 공간을 36비트(64GB의 물리적 메모리)로 늘리는 순 효과
Intel x86-64
- Current generation Intel x86 architecture
- 64 bits is ginormous (> 16 exabytes)
- In practice only implement 48 bit addressing
- Page sizes of 4 KB, 2 MB, 1 GB
- Four levels of paging hierarchy
- Can also use PAE so virtual addresses are 48 bits and physical addresses are 52 bits
- 최신 세대 Intel x86 아키텍처
- 64비트는 엄청나다. (16엑사바이트 이상)
- 실제로는 48비트 주소 지정만 구현한다.
- 4KB, 2MB, 1GB의 페이지 크기
- 네 가지 수준의 페이징 계층
- PAE를 사용할 수도 있으므로 가상 주소는 48비트이고 물리적 주소는 52비트입니다.

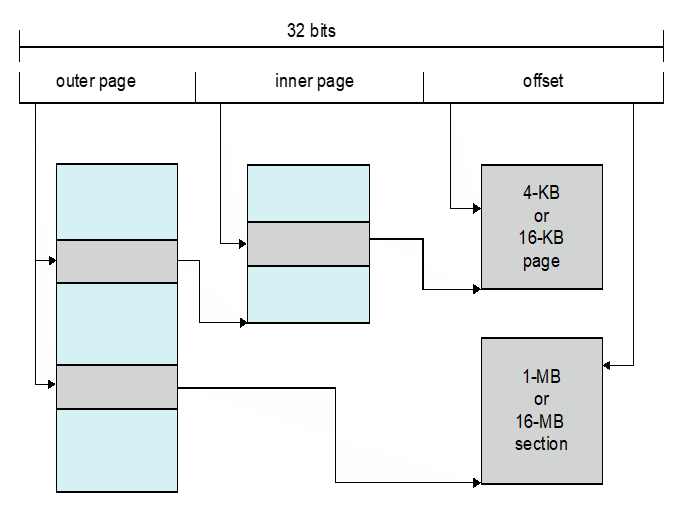
Example: ARMv8 Architecture
- Dominant mobile platform chip (Apple iOS and Google Android devices for example)
- Modern, energy efficient, 32-bit CPU
- 4 KB and 16 KB pages
- 1 MB and 16 MB pages (termed sections)
- One-level paging for sections, two-level for smaller pages
- Two levels of TLBs
- Outer level has two micro TLBs (one data, one instruction)
- Inner is single main TLB
- First inner is checked, on miss outers are checked, and on miss page table walk performed by CPU
- 지배적인 모바일 플랫폼 칩(예: Apple iOS 및 Google Android 장치)
- 최신의 에너지 효율적인 32비트 CPU
- 4KB 및 16KB 페이지
- 1MB 및 16MB 페이지(섹션으로 표현)
- 섹션의 경우 1단계 페이징, 작은 페이지의 경우 2단계 페이징
- 두 가지 수준의 TLBs
- 외부 레벨에는 2개의 마이크로 TLB(데이터 1개, 명령 1개)가 있다.
- 내부는 단일 메인 TLB이다.
- 첫 번째 내부가 확인되고, 누락된 외부가 확인되며, 누락된 페이지의 테이블 워크가 CPU에 의해 수행된다.

아주대학교 수업 기록