
엥 갑자기 한달이 지나버렸슴다;
아무튼 다음으로 Support Vector Machine를 사용해 모델링해보겠습니다. (이 모델은 분류 및 회귀분석에 사용됩니다.)
# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)
acc_svcacc_svc의 값은 78.23이 나왔습니다.
(예제에서는 83.84로 훨씬 높은 값이 나오는데, 왜일까요..?)
다음으로 k-nearest neighbors 알고리즘을 이용해서 모델링해보겠습니다. (분류 및 회귀에 사용되는 비모수적 방법입니다.)
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
acc_knnacc_knn의 값은 84.74가 나왔습니다.
naive Bayes classifier를 이용해보겠습니다. 이것은 베이즈 정리를 이용한 것입니다. 공부할 게 많습니다.
# Gaussian Naive Bayes
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)
acc_gaussianacc_gaussian의 값은 72.28이 나왔습니다.
다음으로 퍼셉트론(Perceptron)입니다. 선형 분류기의 일종인 분류 알고리즘입니다.
# Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
acc_perceptronacc_perceptron의 값은 78.34입니다. (예제는 78.0이 나옵니다)
Linear Support Vector Machine입니다.
# Linear SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
acc_linear_svcacc_linear_svc는 79.12입니다.
Stochastic 경사하강법입니다.
# Stochastic Gradient Descent
sgd = SGDClassifier()
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)
acc_sgdacc_sgd는 72.5입니다.
다음으로 의사결정나무입니다. feature(tree branches)를 목표값(tree leaves)에 매핑하는 예측모델입니다.
# Decision Tree
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
acc_decision_treeacC_decidion_tree의 값은 86.76입니다. 지금까지 중 제일 높은 값이 나왔습니다.
다음으로 랜덤 포레스트입니다. 자주 쓰이는 모델 중 하나라고 합니다. 앙상블 학습 방법으로 ADsP 공부할 때 들은 기억이 있습니다.
# Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forestacc_random_forest의 값은 86.76입니다.
이 모델의 출력인 y_pred를 이용하여 결과를 제출하겠습니다.
models = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Stochastic Gradient Decent', 'Linear SVC',
'Decision Tree'],
'Score': [acc_svc, acc_knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_sgd, acc_linear_svc, acc_decision_tree]})
models.sort_values(by='Score', ascending=False)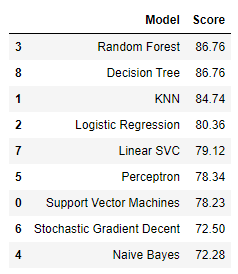
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
# submission.to_csv('../output/submission.csv', index=False)
# .csv파일로 만든 다음 kaggle에 제출합니다.kaggle competitions submit -c titanic -f submission.csv -m "Message"
이렇게 첫 kaggle이 끝났습니다.
어떻게 돌아가는 것인지 배웠으니, 이제는 또 다른 문제를 찾아 스스로 해결해봐야겠습니다.
또한, 이 과정에서 정확히 모르던 모델링 기법들에 대해서 자세히 공부해봐야겠다는 필요성을 느꼈습니다.
(참고: https://www.kaggle.com/startupsci/titanic-data-science-solutions)
