
[Java] 문자 정리 - split(), replace(), trim()
문자열을 나눠서 문제를 풀이하는 경우가 굉장히 많다. 특히, 문자열을 단어 하나 단위로 쪼개거나, 띄어쓰기, 특수문자 등을 기준으로 잘라 사용해야 하는 경우가 많은데, 여기서는 활용도가 높은 split() 위주로 활용하여 단어를 나누는 방법에 대해 서술할 예정이다.fo
[Java] int <> String 변환
문제를 풀다보면, 자료형을 변환해야하는 일이 자주 발생한다. 특히 문자를 숫자형으로 변환하는 일들이 자주 발생하는데 이를 미리 정리하여 추후 헷갈리는 일이 없도록 할 예정이다.해당 함수를 사용할 경우 문자열을 기본 정수 (int)로 변환해준다.parseInt(strin
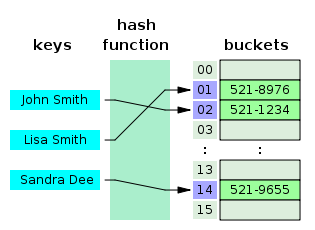
HashTable 정리
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다. 해시 테이블은 각각의 Key값에 해시
Array 정리
Array는 우리가 직관적으로 알고 있는 표 / 테이블과 유사하다. 여기서는 조금 더 언어를 명확히 하여 자료구조의 의미를 써보겠다. Array란 각 데이터와 인덱스가 1:1로 대응하는 구조를 의미한다. 그래서, 데이터와 함께 '인덱스'라는 것이 반드시 존재한다. 이
Array: 백준 10818번 최소, 최대
출처: https://www.acmicpc.net/problem/10818Array를 활용하여 최소, 최대 값을 출력하는 문제이다.별도의 코멘트는 없으나, maxInt, minInt가 처음부터 오류없이 들어가게 하려면 MIN_VALUE, MAX_VALUE 등을
Queue / Deque: 백준 1021번 회전하는 큐
출처: https://www.acmicpc.net/problem/1021결국 제시된 3가지 연산을 이해하는 것이 중요하다.첫 번째 원소를 뽑아낸다. 원래 큐의 원소가 a1, ..., ak이었던 것이 a2, ..., ak와 같이 된다.왼쪽으로 한 칸 이동시킨다.
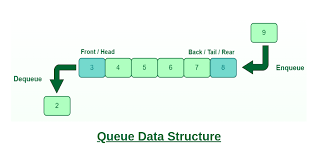
Queue / Deque 정리
Queue는, 일반적으로 우리가 줄을 서는 모습을 상상하면 이해하기 쉽다. 한 쪽에서 줄을 서고 (= Enqueue), 다른 쪽에서 줄이 마무리 (= Dequeue)가 된다. 이러한 구조를 FIFO (First In First Out) 구조라고도 한다.여기서 Deque
Stack: 백준 25556번 포스택
출처: https://www.acmicpc.net/problem/25556처음에 이거 내용 이해가 조금 어려웠는데, 구현은 그에 비해 쉬웠다. 여기서는 이해에 초점을 맞춰서 설명하겠다. (아래는 본인의 언어로 재구성한 문제 내용이다.)포닉스는 길이가 $N$인
Stack 정리
Stack이란? 개념 정리 Stack은, 가장 대표적으로 순서가 보존되는 데이터 구조로, 아래와 같은 그림으로 직관적으로 표기될 수 있다.