이번에는 Group by 에 대해 간단하게 알아보자.
간단한 것이니 짧게만 정리하겠다.
velog 테마를 어둡게 하고 보시는 걸 추천합니다 😊
🥝 기본 지식 다지기
1. group by?
group by 절은 테이블에서 특정 컬럼 값(또는 가공 컬럼값)을 기준으로 그룹을 생성하고,
각 그룹에 대하여 집계함수를 사용하여 집계 데이터를 조회하는 기능이다.
이런 동작 방식 때문에 Group by 의 결과 집합은 Group by 절에 사용된
컬럼값(또는 가공 컬럼값)을 유니크한 값으로 갖게 되는 특징을 보인다.
아래 간단한 예제를 보면서 위 내용을 이해해보자.
select
company, -- group by 절에 사용된 컬럼, 결과 집합에 유니크한 값으로 존재한다.
avg(salary) -- avg 집계함수를 통해서 집계 데이터 조회
from employee
group by company -- 특정 컬럼 값으로 그룹화, 여기서는 company 컬럼를 기준으로 묶는다.
2. group by 문법
select <컬럼(들)>
from <테이블>
where <조건>
group by <컬럼(들) 및 가공된 컬럼값> -- group by 연산의 기준 컬럼을 지정한다.
having <조건> -- group by 결과에 대한 필터링을 한다.참고로 group by 연산은 where 절에 의해서 필터링이 완료된 결과를 사용한다.
3. 집계 함수 종류
count(*) : 그룹으로 묶인 집합의 데이터의 건수
count(distinct <column>) : 그룹으로 묶인 집합에서 <column> 중복값을 제외한 건수
sum(<column>) : 그룹으로 묶인 집합에서 <column> 에 대한 총합
min(<column>) : 그룹으로 묶인 집합에서 <column> 에 대한 최소값
max(<column>) : 그룹으로 묶인 집합에서 <column> 에 대한 최대값
avg(<column>) : 그룹으로 묶인 집합에서 <column> 에 대한 평균값4. 주의사항
-
select 절에는 group by 절에서 사용한 컬럼(또는 가공 컬럼)과 집계함수만 사용
해야 한다. (몇몇DBMS는 이런 제약을 부분적으로 무시하기도 한다) -
집계 함수는 NULL 을 계산하지 않는다!
🥝 쿼리 실습
1. 테스트 샘플
테스트를 위한 간단한 샘플 테이블 및 데이터를 생성하겠다.
-- (참고) 만약 테스트용 스키마도 만들고 싶다면 아래 2줄을 실행해주자. 필수 X
-- create schema if not exists test authorization postgres;
-- set search_path = test, public; -- 현재 세션의 default 스키마를 지정한다.
-- show search_path; -- 현재 세션의 default 스키마를 조회한다.
-- 직원 테이블 생성
create table employee (
empno numeric(4) NOT NULL, -- 사번
ename varchar(30) NULL, -- 사원 이름
hiredate date NULL, -- 입사일
salary numeric(7, 2) NULL, -- 급여
deptno numeric(2) NULL, -- 부서번호
CONSTRAINT emp_pk PRIMARY KEY (empno) -- 사번을 PK 로 설정
);
-- 직원 테이블 샘플 데이터 생성
insert into employee
(empno, ename, hiredate, salary, deptno)
values
(1, 'Charlie Miles',now() - interval '10 years' , 10000, 10),
(2, 'Hughie Vega', now() - interval '9 years', 9000, 10),
(3, 'Bailey Ortega',now() - interval '8 years', 8000, 10),
(4, 'Jeffrey Read', now() - interval '7 years', 7000, 10),
(5, 'Wallace Badman',now() - interval '6 years', 7000, 20),
(6, 'Cedric Doyle', now() - interval '5 years', 6000, 20),
(7, 'Brad Woolridge', now() - interval '4 years', 5000, 20),
(8, 'Chad Schwartz', now() - interval '3 years',4500, 20),
(9, 'Willa Bird', now() - interval '2 years', 9000, 30),
(10, 'Sam Gramer', now() - interval '1 years', 9000, 30);
-- 부서 테이블
CREATE TABLE dept (
deptno numeric NOT NULL, -- 부서 번호
dname varchar(14) NULL, -- 부서 명
CONSTRAINT dept_pk PRIMARY KEY (deptno)
);
-- 부서 테이블 샘플 데이터 생성
insert into dept
values
(10, '개발'),
(20, '회계'),
(30, '인사');
-- 외래키 매핑
ALTER TABLE employee ADD CONSTRAINT employee_fk FOREIGN KEY (deptno)
REFERENCES dept(deptno);- employee 테이블

- dept 테이블

2. 일반 사용법
-- 부서별 최대,최소,평균 급여 구하기
select deptno, max(salary), min(salary), avg(salary)
from employee e
group by deptno ;
--------------------------------------------------
--|deptno|max |min |avg |
--|------+--------+-------+---------------------+
--| 10|10000.00|7000.00|8500.0000000000000000|
--| 30| 9000.00|9000.00|9000.0000000000000000|
--| 20| 7000.00|4500.00|5625.0000000000000000|
--------------------------------------------------
-- 부서별로 평균 급여가 7000 이상인 부서에 대한 최대, 죄소, 평균 급여 구하기
select deptno, max(salary), min(salary), avg(salary)
from employee e
group by deptno
having avg(salary) >= 7000
;
-- 위 쿼리를 CTE 를 사용해서 구현하기
with
group_temp as (
select deptno, max(salary) max_sal, min(salary) min_sal, avg(salary) avg_sal
from employee e
group by deptno
)
select * from group_temp
where avg_sal >= 7000;
--------------------------------------------------
--| deptno|max_sal |min_sal|avg_sal |
--| ------+--------+-------+---------------------+
--| 10|10000.00|7000.00|8500.0000000000000000|
--| 30| 9000.00|9000.00|9000.0000000000000000|
--------------------------------------------------
-- join 이랑 같이 써보기
-- 부서별로 평균 급여가 7000 이상인 부서에 대한 최대, 죄소, 평균 급여 구하기
-- 다만 이번에는 부서별 번호뿐만 아니라, "부서 이름"도 같이 나오게 한다.
select a.deptno, max(b.dname), max(a.salary), min(a.salary), avg(a.salary)
from employee a
inner join dept b on a.deptno = b.deptno
group by a.deptno
having avg(salary) >= 7000;
------------------------------------------------------
--| deptno|max|max |min |avg |
--| ------+---+--------+-------+---------------------+
--| 10|개발 |10000.00|7000.00|8500.0000000000000000|
--| 30|인사 | 9000.00|9000.00|9000.0000000000000000|
-------------------------------------------------------
-- 부서별 인원수
select a.deptno , count(*) dept_per_count
from employee a
group by a.deptno ;
--------------------------
-- |deptno|dept_per_count|
-- |------+--------------+
-- | 10| 4|
-- | 30| 2|
-- | 20| 4|
--------------------------
-- employee 테이블만 사용해서 부서의 개수 구하기
select count(distinct a.deptno)
from employee a
; -- group by 가 없다면 group by 연산은 테이블 전체를 대상으로 한다.
---------
--|count|
--|-----+
--| 3|
---------3. CASE 와 함께 사용하는 법
한번 연봉이 9000 이상인 사람과 9000미만인 사람들을 Grouping 해서 각 그룹의 연봉 합계를 구해보자.
여러 방법이 있겠지만, Case 문과 Group by 를 섞어서 사용해보자.
두 그룹이 어떻게 나뉠지 먼저 눈으로 확인하기 위해서
아래처럼 평범한 select 쿼리를 실행해보자.
-- 연봉이 9000 이상인 직원과 아닌 직원을 나눠보면 아래와 같다.
select
*
, case
when salary >= 9000 then 'over_9000'
else 'under_9000'
end as sal_gubun
from
test.employee e 결과
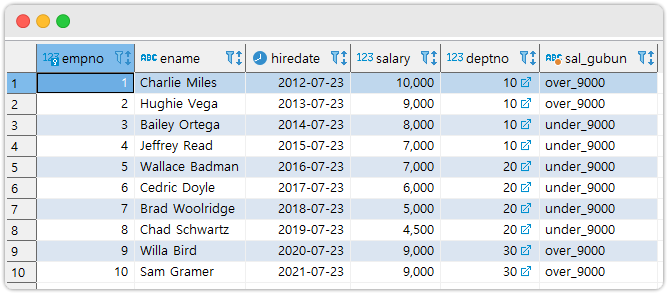
연봉이 9000 이상인 사람이 4명, 아닌 사람이 6명 있는 걸 확인할 수 있다. 이 모습을 잘 기억하고 다음에 나올 Group by 절의 결과를 이해하자.
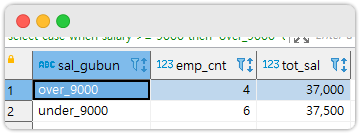
Group By + Case
select
case
when salary >= 9000 then 'over_9000'
else 'under_9000'
end as sal_gubun,
count(*) as emp_cnt,
sum(salary) as tot_sal
from
test.employee e
group by
case
when salary >= 9000 then 'over_9000'
else 'under_9000'
end결과