
이제 PostgreSQL 통계 쿼리에서 기본이라고 할 수 있는 JOIN 에 대해 알아보자.
🥝 JOIN 기반 지식
JOIN 은 가끔 합집합, 차집합 등으로 표현하지만
나는 일절 그런 방식으로 설명을 하지 않을 것이다.
대신 테이블의 크기 를 중심으로 나는 JOIN 을 설명해볼까 한다.
1. 테이블 크기?
여기서 말하는 테이블 크기는 하나의 테이블에서 갖는 유니크한 컬럼(ex: primary key)
에 의해서 결정되는 테이블의 사이즈라고 이해하면 된다.
더 쉬운 이해를 위해서 아래 그림과 같이 설명을 해보겠다.
actor 라는 테이블을 조회해보면 아래와 같이 나온다.
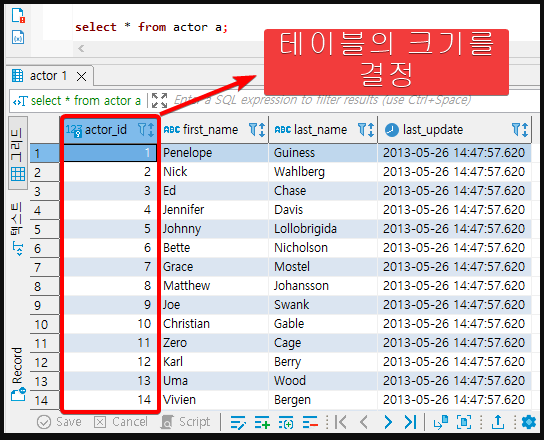
조회하면 actor_id 라는 pk 컬럼이 있고, 이건 각 Row 마다 Unique 한 값을 띈다.
그리고 이런 Unique 값의 개수가 테이블의 크기가 결정되는 것이다.
만약 actor_id 가 1~14 까지 있다면, 해당 테이블의 크기는 14 인 것이다.
더~ 쉽게 말해서 아파트에 각 층에 "층수"라는 고유한 값이 있기 때문에 우리는
그 아파트의 크기를 "? 층"짜리 아파트라고 표현하는 것과 같다.
2. Join 이란?
관계형 DB의 가장 핵심 기능이며, 두 개 이상의 테이블을 연결해서 데이터를 조회하는 기능이다.
3. Join 의 사용과 결과 Set(집합)의 크기
한번 간단한 Join 문 실습을 해보자.
참고로 실습은
inner join위주로 먼저 하겠다.
outer join를 알기 위해서는inner join에 대한 이해가 먼저 필요하다.

현재 film(영화) 과 film_actor(영화배우)가 외래키(film_id)로 연관관계를 갖고 있으니,
이 둘을 Join으로 조회해보겠다.
select a.actor_id, b.film_id , b.title, b.description, b.release_year
from film_actor a
join film b on b.film_id = a.film_id
where b.film_id = 228이렇게 하면 어떻게 될까? 아래와 같은 결과가 나온다.

여기서 중요한 것은 join 결과물(집합)의 크기다.
결과물의 크기는 어느 테이블의 기준으로 정해지는 것일까?
이것을 결정하는 것은 join 에 사용된 외래키이다.
그리고 해당 외래키를 어떤 형태로 보유하고 있는지가 결과물의 크기를 결정한다.
- 해당 외래키를 UNIQUE 하게 갖고 있는 테이블 (=외래키 기준 1집합 테이블)
- 해당 외래키를 중복적으로 보유하고 있는 테이블 (=외래키 기준 M집합 테이블)
결론부터 말하자면 M집합 테이블의 크기에 맞춰서 join 의 결과물 크기가 결정된다!
현재 돌린 쿼리에서는 보면 film_id 라는 외래키가 있고,
film 테이블이 1집합 테이블이고
film_actor 테이블에서는 중복적으로 외래키를 보유하고 있다.
이것은 film:film_actor 테이블이 1:M 이라는 관계를 성립하게 한다.
이때 film 을 1집합, film_actor 를 M집합이라고 표현할 수 있다.
착각하지 말아야 할게
1이라는 표현은 외래키가 UNIQUE 하다는 의미지
정말 하나라는 뜻이 아니다!
이때 M집합에 해당하는 테이블의 크기에 맞춰서 join 의 결과물이 나온다.
위의 실습 쿼리에서는 film_actor 가 M집합, film 이 1집합이여서
join 결과물이 film_actor 크기와 맞춰지는 것을 알 수 있다.
조금 이해가 안될 수 있다. 그러니 아래 예를 하나만 더 보자.
이번에는 3개의 테이블을 join 해보자. 사용될 테이블은 아래와 같다.

select a.country_id, a.country, b.city_id , b.city , c.address_id , c.postal_code
from country a
join city b on a.country_id = b.country_id
join address c on b.city_id = c.city_id
order by 5자... 이러면 최종 join 결과물의 크기는 어느 테이블에 의해서 결정될까?
이미 말했지만, 외래키를 중점으로 봐야한다.
country 테이블과 city 테이블은 country_id 라는 외래키로 연관관계를 맺고,
country (1집합), city (M집합)에 해당한다.
그래서 city 에 의해서 join 결과물의 크기가 결정된다.
이 결과 집합은 또 한번 address 테이블과 join을 하게 된다.
둘 사이에는 city_id 라는 외래키로 join을 할 것이고,
결과 집합이 1집합, address 가 M 집합에서 속한다.
그래서 최종적으로 address 테이블의 크기에 맞춰진 최종 결과물이 나온다.
한번 결과물을 보자.

자세히 보면 최종 크기를 결정하는 address 테이블의 pk인 address_id 는 중복되지
않고 나온다. 이를 통해서 최종 크기 결정자는 address 테이블이라는 것을 알 수 있다.
🥝 JOIN의 종류
아까 전까지 보던 inner join 을 포함해서 다른 join 들도 알아보자.
1. inner join

select a.employee_id, a.employee_name, b.dept_id, dept_nm
from employee a
join dept b on a.dept_id = b.dept_id
order by 1, 3INNER JOIN 은 ON 절의 조건문에 충족하는 것만 결과물에 출력한다.
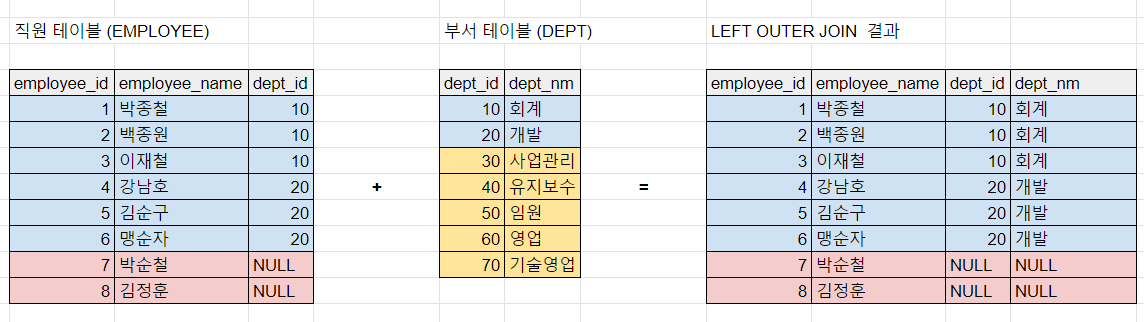
2. left outer join
select a.employee_id, a.employee_name, b.dept_id, dept_nm
from employee a
left outer join dept b on a.dept_id = b.dept_id
order by 1,3left outer join 이라는 명칭은 사실 JOIN 문 양쪽에 표기한 테이블 중에서
어떤 것이 OUTER TABLE 인지를 알려주기 위한 지표라고 할 수 있다.
이 예제에서는 employee 테이블이 outer table 이 된다.
이렇게 outer table로 지정되면 비록 ON 절에 충족하지 않더라도,
join 의 결과물에는 outer table의 모든 ROW 데이터를 "살린다".
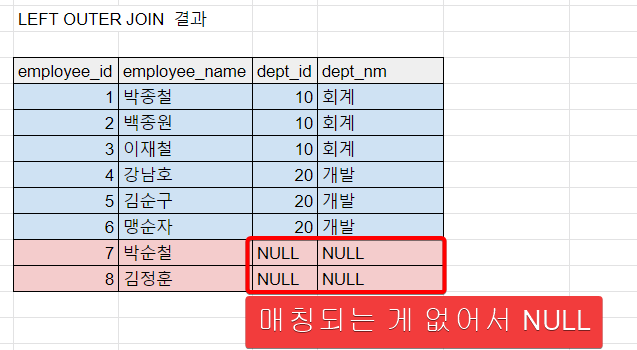
다만 이 과정에서 join 조건에 충족하는 row 가 outer table의 반대편 테이블(DEPT)에는
없기 때문에 join 결과물에 어쩔 수 없이 NULL을 채우게 된다.
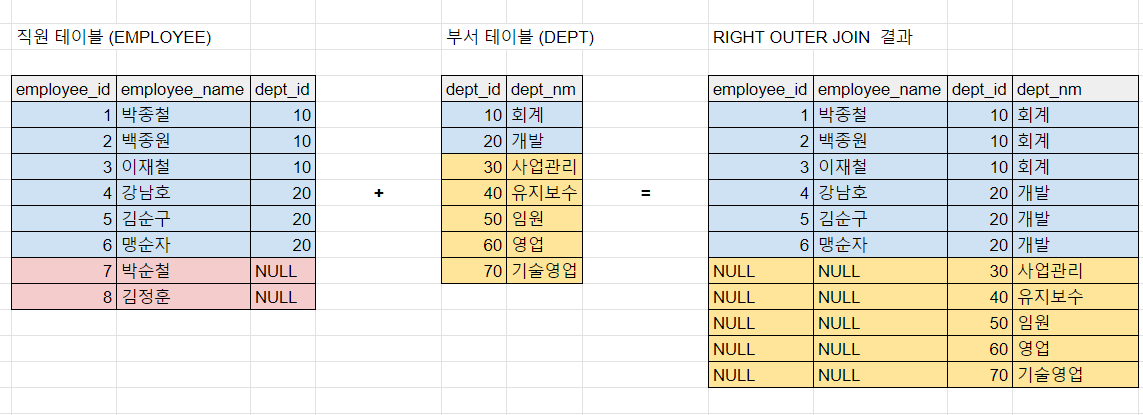
3. right outer join
select a.employee_id, a.employee_name, b.dept_id, dept_nm
from employee a
right outer join dept b on a.dept_id = b.dept_id
order by 3, 1이번에는 OUTER TABLE 이 dept 테이블이다.
그래서 결과가 위처럼 나온다. LEFT OUTER JOIN 과 설명이 중복되니 여긴 생략하겠다.
4. full outer join
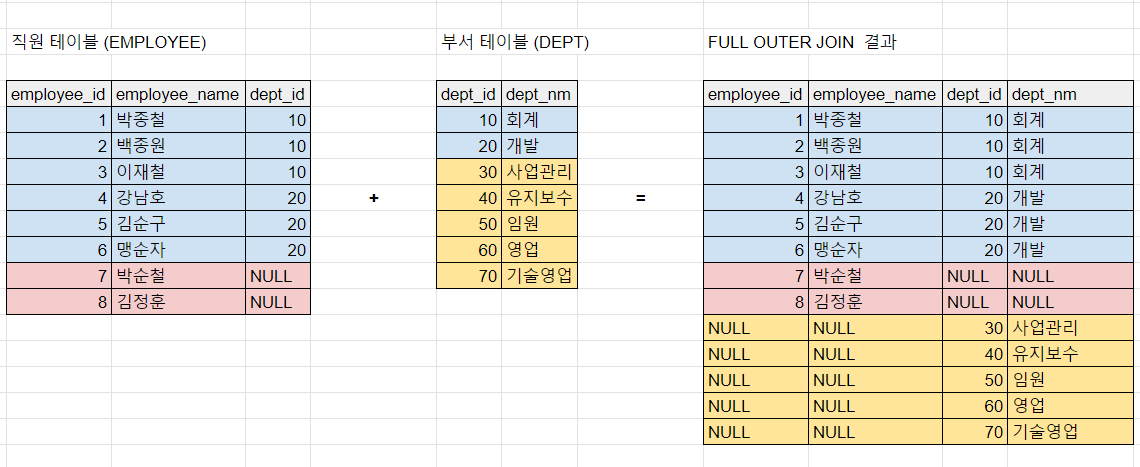
select a.employee_id, a.employee_name, b.dept_id, dept_nm
from employee a
full outer join dept b on a.dept_id = b.dept_id
order by 1,3이번에는 OUTER JOIN 의 양쪽에 있는 테이블이 모두 OUTER TABLE 이 되는 것이다.
이러면 양쪽 테이블의 모두 ON 절의 조건에 충족되지 않더라도 해당 ROW 가
모두 join 결과물에 포함된다. 위 그림으로 최대한 이해하자.
5. cross join
select *
from employee a
cross join dept b기존 앞에서 봤던 JOIN 들은 최소한 ON 절이 있었지만, CROSS JOIN 은 그런게 없다.
그리고 각 테이블의 모든 로우가 조합될 수 있는 모든 조합의 ROW 를 만들어서
join 결과물로 뱉어낸다.
🥝 NON EQUI JOIN
위의 JOIN SQL 들은 봐서 알겠지만, 대부분 ON 절에서 = 을 사용한다.
이런 JOIN 을 EQUI JOIN 이라고 한다.
하지만 모든 JOIN 문들이 단순히 = 만 쓰는 것은 아니다.
BETWEEN 을 사용해도 되고 >, < 등의 연산자도 사용이 가능하다.
이런 JOIN 들을 NON EQUI JOIN 이라고 한다.
NON EQUI JOIN의 사용법을 가볍게 알아보자.
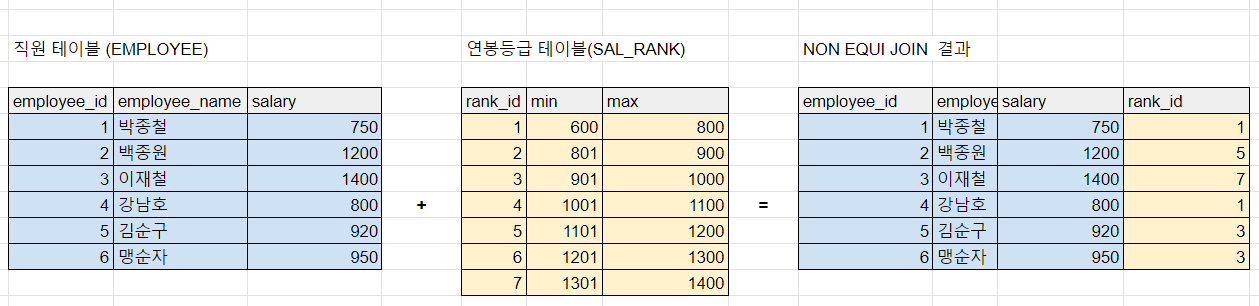
select a.employee_id, a.employee_name, a.salary, b.rank_id
from employee a
join sal_rank b on a.salary between b.min and b.max여기까지 해서 JOIN 의 개념 및 종류를 알아봤다.
