2026-02-07 에 Kosta Edu 로 수강한
폐쇄형 LLM 시스템 구축강의를 듣고
그 내용들을 제가 한번 정리해본 겁니다. 저만 알아보기 쉽게 작성해서 읽기 힘드실 수 있습니다 😅
🍀 오픈소스 LLM 생태계 (이론)
클로즈드 vs 오픈소스 LLM
일반적으로 이미 개발된 LLM 사용하게 됨.
그리고 이러한 LLM 을 선택할 수 있게 되는데 크게 2가지,
클로즈드 소스 LLM , 오픈소스 LLM 이다.
클로즈드 소스는 주로 Cloud API 를 통해 사용하고,
오픈소스의 경우에는 Self-hosted 환경에서 직접 설치 및 응용할 수 있다.
각각의 장단점:
클로즈드 소스
-
장점: 성능 좋음, LLM 자체 구축 필요 X, 지속적 모델 업데이트
-
단점: 토큰당 과금, 대량 사용시 비용 급증, 프롬프트가 외부로 전송되기 때문에 보안적 문제를 갖고 있음.
오픈소스
-
장점: 사내 서버에 설치해서 쓰므로 보안성 좋고,
고정 비용이며, 파인튜닝도 가능하고 독자적인 RAG 활용도 가능하다!
단점: 인프라 구축/운영이 필요하다. 특히 GPU 에 대한 비용과 관리가 쉽지 않다.
클로즈드 대비 성능이 낮다. 새로운 모델이 나오고 적용하려면 직접 업데이트하고 관리해야 된다.
알아두면 좋은것:
AWS 배드락
용어 이해
- 토큰(Token):
- LLM 이 텍트르를 처리하는 최소 단위다.
- 참고로 절대로 하나의 단어가 하나의 토큰이라고 생각하면 안된다.
- 이와 관련해서는 https://platform.openai.com/tokenizer 를 참고.
- 파인튜닝(Fine-Tuning):
- 사전 학습된 모델에 특정 도메인 데이터를 추가로 학습시키는 것이다.
- 그런데 이 파인 튜닝은 일반적으로 오랜 시간이 걸린다.
그리고 도메인이 자주 변경되면 또다시 처음부터 파인튜닝을 해야된다. - 이러한 이유로 RAG 를 사용한다.
- RAG (Retrieval-Argument Generation)
- 문서(외부지식) 검색 + LLM
- Retrieval(검색) + Augmented(보강) + Generation(생성)
- 풀어서 말하자면, 내 질문과 관련해서 먼저 문서에서 검색을 하고,
그 검색된 결과와 내 질문을 합쳐서 LLM 에게 전달하는 것을 의미한다. - 여기서 문서(외부지식)은 일반적으로는 Vector DB 이지만,
외부 인터넷 검색 결과일 수도 있다. 즉 문서의 형태는 다양할 수 있다.
- 컨텍스트 (Context)
- LLM 이 한 번에 처리할 수 있는 입력 텍스트 범위이다.
- 또는 이전 대화와 관련된 기억의 범위, 즉 맥락의 범위라고 할 수 있다.
- 많이 오해하는게 LLM 은 우리가 준 질문 1개에 대해서 답변을 잘하는 거지,
여태한 모든 대화를 다 기억하고 답변을 하는 게 아니다. - LLM 에 컨텍스트의 개념을 붙이는 건 LLM 을 활용한 서비스(또는 앱)의 역할이지, LLM 스스로는 컨텍스트 개념이 없다.
TIP!
가끔 ChatGPT 로 오랫동안 대화하다보면 갑자기 메모리 기능 활성화라는 게 나온다.
이건 우리가 나눴던 대화를 문서로 저장하고, 그 문서를 RAG 로 활용하겠다는 의미다.
- 프롬프트 (Prompt)
- LLM 에게 주는 입력 텍스트
- 요즘은 프롬프트 엔지니어가 많이 없어졌다. 이유는 LLM 자체의 기능이 너무 좋아져서 개떡같이 말해도 찰떡같이 알아듣기 때문이다.
- 요즘은 프롬프트 엔지니어 보다는 컨텍스트 엔지니어링을 공부해보는 것을 권장한다. (맥락을 어떻게 유지할 것인가?)
- Vector DB:
- 텍스트, 이미지 등의 데이터를 임베딩(embedding)이라는 고차원 숫자 벡터(=고차원 배열)로 변환하여 저장하는 데이터 베이스.
- 의미가 비슷한 문장들은 벡터 공간에서 가까이 위치하는 특징을 갖음.
- VectorDB 는 이러한 의미 기반 유사도에 따른 검색이 가능!
단순 like 검색 같은 게 아님. 사람의 의도를 파악하는 게 핵심. - Vector DB 는 RAG 와도 굉장히 밀접한데, 우리가 질문을 하면 이 질문도 벡터로 변환한 뒤, Vector DB 에서 가장 유사한 벡터(= 가장 관련있는 문서 조각)를 찾고 그걸 LLM 에게 넘겨준다.
우리가 말하는 문서 검색이라는 게 바로 이런 Vector DB 덕분이다. - Pinecone, Weaviate, Milvus, Chroma, Qdrant, pgvector(PostgreSQL 확장) 등이 있다.
RAG 의 처리 흐름:
------------------------------------------------------------------------
원본 문서 → Chunking(조각 분할) → 각 Chunk를 임베딩 → Vector DB에 저장
↓
사용자 질문 → 질문 임베딩 → Vector DB에서 유사 Chunk 검색 → LLM에 전달 → 답변 생성- Chunk (청크)
- Chunk 는 원본 문서를 적절한 크기로 잘라놓은 조각이다.
- 이렇게 자르는 이유는 LLM 의 컨텍스트 윈도우의 한계와
임베딩 모델의 너무 긴 문장에 대한 처리가 힘들다는 점 때문이다.
생태계 구조
구조가 크게 3가지로 나뉜다.
- 추론엔진 영역
- 통합 플랫폼 영역
- 사용자
추론엔진 (Inference Engine)
LLM 모델을 메모리에 효율적으로 로딩하고 실행하는 백엔드 소프트웨어(=런타임)이다.
- 모델파일(.gguf, safetensors)를 GPU/CPU 에 로드
- API 를 제공하여 LLM 과 상호작용 가능토록 함
추론 엔진에는 다음과 같은 것들이 있다.
상용: vLLM, SGLang
개인용: ollama, LM Studio
참고: 왜 "추론" 엔진인가?
ChatGPT 나 Claude 에 질문하면 우리가 얻는 답은 이미 학습이 완료딘 모델에서 답을 "추론"하는 것이다.
참고: 꼭 추론엔진으로 LLM 을 활용해야 되나?
사실 추론엔진이 아니여도, PyTorch 로 모델을 로드하고 바로 질의응답을 할 수 있다.
다만 이러면 기본적으로 개발자 및 일반 사용자들 모두 PyTorch 를 알아야 한다는 제약이 생기며, 단순하게 사용하는 편의성 측면에서도 꽝이다.
이런 편의성을 위해 있는 추론엔진이 ollama, LM Studio 같은 것들이다.
그리고 이런 단순 편의성이 아닌, 실제 LLM 을 Production 환경에서 여러 사용자가 동시 다발적으로 접근해도 가용이 가능하도록 최적화가 많이 필요한데, 이때 vllm, SGLang 같은 추론 엔진은 절대적으로 필요하다.
통합 플랫폼 (Integration Platform)
추론 엔진 위에 구축된 사용자 애플리케이션의 영역이다.
이전에 설명한 추론엔진이 제공하는 API 로 통해서 통신하여
사용자들에게 인터페이스를 제공하는 영역이다.
참고로 여기서 Context 관리, RAG 등의 LLM 관련된 응용영역이면서,
사용자들의 편의성인 문서 업로드, 검색, 로그인 등의 기능들을 제공하는 영역이기도 하다.
OpenWebUI(ChatGPT 와 유사한 웹 채팅 솔루션, 팀을 위한 LLM 기반 채팅 용도),
AnythingLLM (RAG 기능 내장 올인원 솔루션, 문서 검색용) 등의 오픈소스가 존재한다.
추론엔진과 통신해서 애플리케이션을 만들면 그런 커스텀 애플리케이션도
이 영역에 소속된다.
사용자
통합 플랫폼을 사용하는 사용자들을 의미한다.
추론엔진, 플롯폼 선택 가이드 (중요)
- 개인 개발/테스트 : Ollama
- 팀 채팅 서비스 : Ollama + OpenWebUI
- 사내 문서 검색 : Ollama + AnythingLLM
- 고성능 API 서버: vLLM + 커스텀 애플리케이션
- 대규모 트래픽 : vLLM + K8s + 커스텀 애플리케이션
개발 초기에는 ollama 먼저, 이후 vLLM 적용도 좋은 방법.
초간단 실습
ollama pull qwen3:1.7b # 설치진행
pulling manifest
pulling 3d0b790534fe: 100% ▕███████████████████████████████████████████████████████▏ 1.4 GB
pulling ae370d884f10: 100% ▕███████████████████████████████████████████████████████▏ 1.7 KB
pulling d18a5cc71b84: 100% ▕███████████████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕███████████████████████████████████████████████████████▏ 120 B
pulling 517ccaff02fe: 100% ▕███████████████████████████████████████████████████████▏ 487 B
ollama run qwen3:1.7b "안녕하세요? 파이썬이 뭐에요?"
# run 모델을 메모리에 올리고 답변을 주는 것ollama run qwen3:1.7b # 이렇게만 입력하면 마치 채팅하듯 사용이 가능하다.
# 하지만... Context 관련 기능이 없기 때문에 단건 질문, 즉 테스트용이다!
/bye # 빠져나오기🍀 오픈소스 LLM 모델 패밀리
모델 아키텍처 관련 주요 용어
- 파라미터(Parameter)
- 모델의 가중치 수.
- ex: 7b 라고 표기되어 있으면 70 억개의 파라미터를 의미한다.
- 파라미터는 일종의 필터의 집합이다. 우리가 LLM 에 어떤 INPUT 을 넣으면 그와 관련된
다양한 필터링이 발생하게 된다. 아래이 보이는가? 저 선 하나하나가 파라미터라고 생각하면 된다.
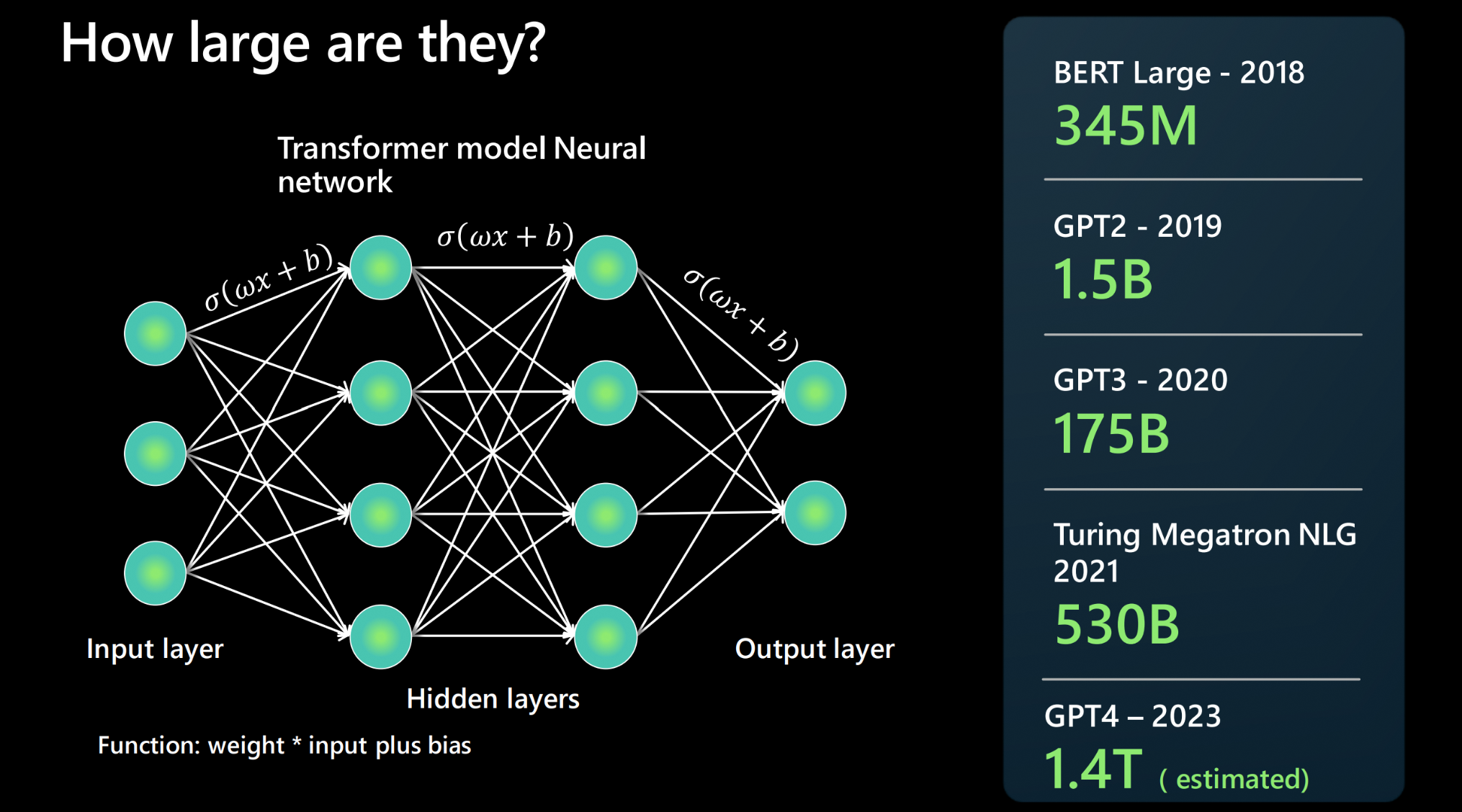
- 이 선 하나하나에 가중치가 존재한다.
- 일반적으로 필터가 크면 좋지만, 그 필터를 결국 메모리에 올려야 하기 때문에 컴퓨터의 자원이 어느정도 받쳐줘야 한다.
좀 더 조사해보자.
https://catherinebreslin.medium.com/what-is-a-parameter-3d4b7736c81d
https://news.lginnotek.com/1387
MoE:- 전문가 혼합 구조
- 파라미터, 즉 필터가 많을 때 가끔은 이 필터가 어떤 주제영역에 대해서 더 잘 대응하도록 영역을 나누고 싶을 수 있다.
- 예를 들어서 코딩을 잘하는 필터, 글쓰기를 잘하는 필터 처럼 말이다.
- 이렇게 구분해서 필터를 통과시킬 수 있는 기술이 바로 MoE 이다. 이러면 응답 속도가 빨라진다!
(물론 파라미터(필터)를 모두 메모리에 올려야 한다는 건 똑같지만...)
활성/전체:
MoE에서 실제 사용되는 파라미터 / 전체 파라미터
-
Dense:
모든 파라미터가 항상 활성화되는 전통적 구조, MoE 의 반대. 그냥 필터 다 통과. -
멀티모달:
입력으로 글 외의 것을 넣을 수 있음.
이게 가능한 건, 파일이 결국 바이너리라서 그런거임. 컴퓨터한테는 문자열이나 이미지나 도찐개찐이다. -
컨텍스트 길이: 한 번에 처리 가능한 최대 토큰 수 (예: 128K)
우리가 앞으로 모델의 명칭들을 보면 대충 아래처럼 나올 것이다.
Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
여기서235B은 파라미터의 갯수를 의미한다.
그리고A22B에서A는 Active(활성) 라는 의미고, MoE 모델이라는 뜻이기도 하다.
중요: 모델이 클수록 답변의 품질이 올라가지만,
속도가 내려가고, 사용 메모리가 올라간다.
용도에 맞는 선택이 중요하다!
봐두면 좋은 LLM 모델 몇가지
-
Qwen 3
-
Gemma 3 도 아주 많이 쓴다. (
p.22)
개인으로 쓰기도 좋고, 멀티 모달이 지원된다.
일반 사용자에겐 더 좋은 활용성을 줌.
compact 한 기기에서도 사용이 가능하려고, 270M 모델도 있다.
참고로 Gemma Licence 는 상용 가능!
- GLM-4.7 은 코딩 작업을 위해 나온 거다.
🍀 모델 크기와 양자화
용어 이해 - 하드웨어 & 메모리
GPU
그래픽 처리 장치. LLM 연산에 필수적인 병렬 처리 칩이다.
그래픽 카드는 단순하게 생각해서 병렬적으로 사용할 수 있는 계산기가 많이 들어간 카드이다.
그리고 이런 특이점 덕분에 본의 아니게(?) 오늘날 LLM 연산할 때 필수품이 되버렸다.
TIP: 사실 GPU 는 그래픽을 위한거지 LLM 을 위한 건 아니다.
그래서 요즘은 LLM 타겟팅한 칩을 만드는 회사도 있는데,
그중 눈여겨보면 좋은게 cerebras (https://www.cerebras.ai/) 이다.
VRAM
GPU 의 RAM 이다. 일반 RAM 은 시스템 렘이다! 구분을 잘해야 한다.
우리가 추후에 모델이 사용하게 될 메모리와 우리가 갖고 있는 자원, 즉 RAM 크기를 비교해야 되는데,
이때 바로 확인하는 RAM 이 바로 VRAM 이다.
TIP : VRAM 사양 확인하는 법:
LLM 을 로드하기 위해서는 VRAM 의 크기를 확인하는 법은 다음과 같다.
먼저 외장형이냐, 내장형인지 먼저 구분해야 한다. 계산법이 다르기 때문이다.
외장형의 경우에는 GPU(ex: 엔비디아) 에 있는 메모리를 보면 된다.
하지만 내장형 GPU (ex: Intel(R) UHD Graphics)의 경우에는 아래처럼 "공유 GPU 메모리"라고 나온다.
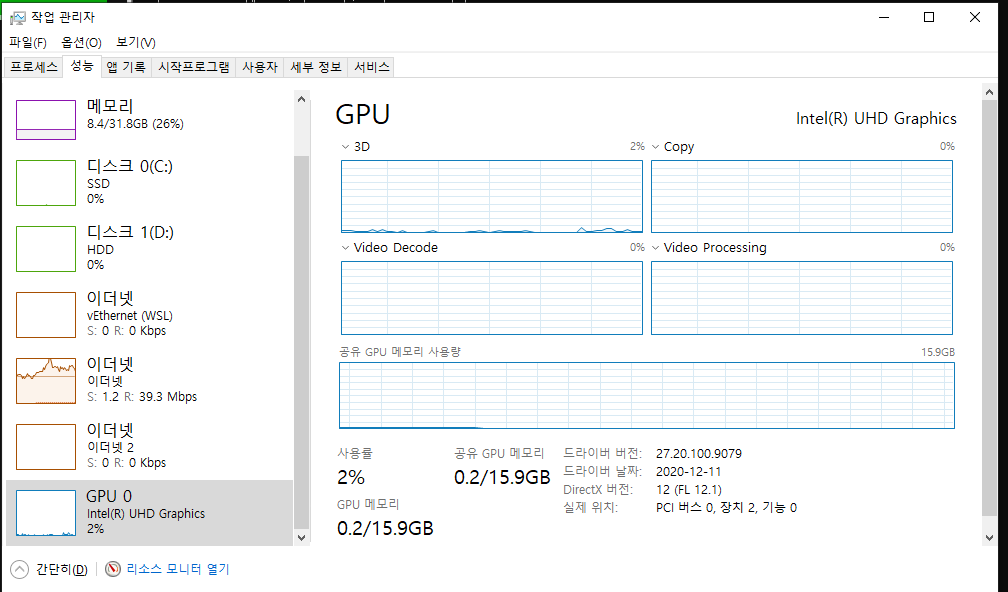
이 공유 GPU 메모리는 사실 시스템 전반에서 사용되는 시스템 RAM 을 공유해서 사용한다는 의미다.
즉 그래픽 카드 전용 RAM 이 없다는 의미다.
아마 이걸 보고 "RAM 만 많으면 되지 않아?" 라고 생각할 수도 있다.
하지만 확실히 말하지만 돌릴 수는 있지만, 매우 매우 매우 느리다.
CPU 가 사용하는 메모리를 공유하기 때문에 느릴 수 밖에 없다.
아주 예외적으로 이런 논리를 깨는 하드웨어가 있다.
- MAC :
CPU,GPU가 하나에 있고, 메모리를 공유하는데, 이 메모리 대역폭이 매우 크다! - Nvidea 에 있는 무슨 미니 PC 가 있는데 , 그것도 가능함.
양자화와 정밀도
LLM의 파라미터는 기본적으로 부동소수점 숫자이다.
이 부동소수점의 숫자값의 정밀도를 낮추는 것, 즉 반올림을 하는 것이 양자화다.
ex: 3.141592 -> 3.14
이렇게 하면 기존의 모델 크기가 많이 압축되고,
메모리에 올릴 때의 부담도 줄어들게 된다.
이때 정밀도와 관련해서 표현하는 방법은 다음과 같다.
| 정밀도 | 파라미터당 크기 |
|---|---|
| FP16 (16비트) | 2바이트 |
| FP8/INT8 (8비트) | 1바이트 |
| INT4 (4비트) | 0.5바이트 |
참고로 원본 모델은 보통
FP16(16비트)로 저장된다.
즉 모델들은 일반적으로 한 파라미터당 2바이트를 사용한다는 것이다.
이번에는 예를 들어서 생각해보자.
예를 들어서 70억(7B) 파라미터 모델의 경우에는 대략 아래처럼 크기가 정해질 것이다.
| 정밀도 | 파라미터당 크기 | 전체 모델 크기 (대략) |
|---|---|---|
| FP16 (16비트) | 2바이트 | ~14GB |
| FP8/INT8 (8비트) | 1바이트 | ~7GB |
| INT4 (4비트) | 0.5바이트 | ~3.5GB |
칼로 딱 자르듯 저 크기가 정확히 나오는 건 아니다.
실제로는 저 크기 보다 조금 더 크다고 한다.
양자화와 VRAM 요구량
VRAM 과 모델 크기
VRAM = GPU 메모리. 모델 크기 < VRAM 이어야 실행 가능하다!
원본 모델은 보통 FP16(16비트) 로 저장된다고 이전에 말했다.
이 말은 7b 짜리면 70 억 x 2bytes = 140억 바이트 이고,
다시 GB 로 계산하면 140억 바이트 ÷ 10억 = 약 14GB 이다.
즉 14GB 보다 더 큰 VRAM 이 있어야 한다는 의미다.
이렇게 계산하면 된다.
다만 양자화의 정도에 따라서 이 크기가 달라진다.
예를 들어서 FP8(8bit) 양자화를 하면? 아까 구한 값의 절반으로 떨어진다.
즉 7GB 보다 큰 VRAM 만 있어도 같은 모델을 실행시킬 수 있다는 의미다.
참고로 양자화와 관련된 요즘 연구에 따르면 8bit 양자화만 해도 충분하다고 좋다고 한다.
절반으로 크기가 줄어서 대답 품질이 안좋을 것이라 생각되겠지만, 그 정도가 미미하다고 한다.
TIP: 허깅페이스에서 모델 크기 및 양자화 확인방법
먼저 https://ollama.com/search 에 접속하고, local 용으로 쓸 만한 걸 찾아낸다.
나는 qwen3 를 찾아냈다. 보면 대충 알겠지만, 같은 모델이더라도, 파라미터의 크기가
0.6b, 1.7b 처럼 여러개로 나뉜 걸 확인할 수 있다.
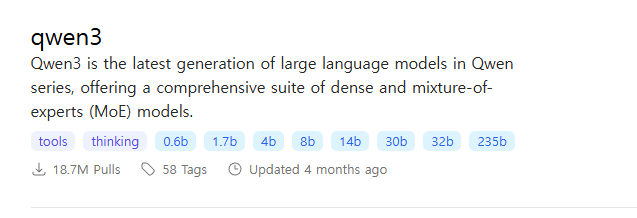
참고: 모델설명 하단의 태그에서
cloud라고 작성된 것은 local 설치 용이 아니다.
해당 모델들은 ollama 서버에서 동작한다는 의미다.
qwen3 를 클릭하면 다음과 같이 화면이 나온다.
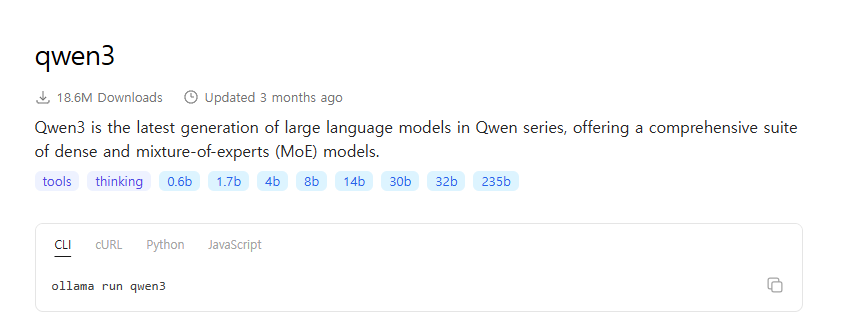
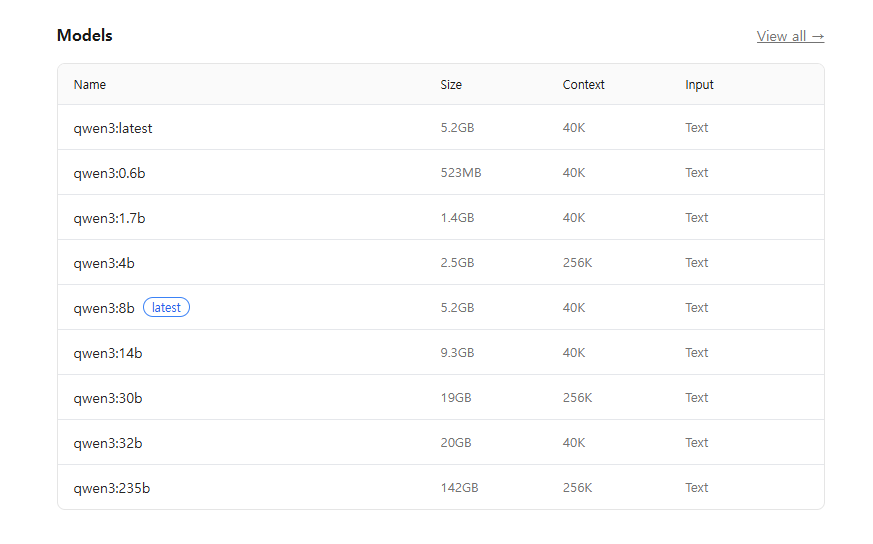
위 그림을 보면 분명 qwen3:8b 인데, 머리로 계산하면 대충 16GB 보다 좀 더 큰 크기가
필요하다만, Size 를 보면 5.2G 라고 나온다. 이건 양자화가 진행됐다는 의미다.
해당 모델을 클릭해보자.
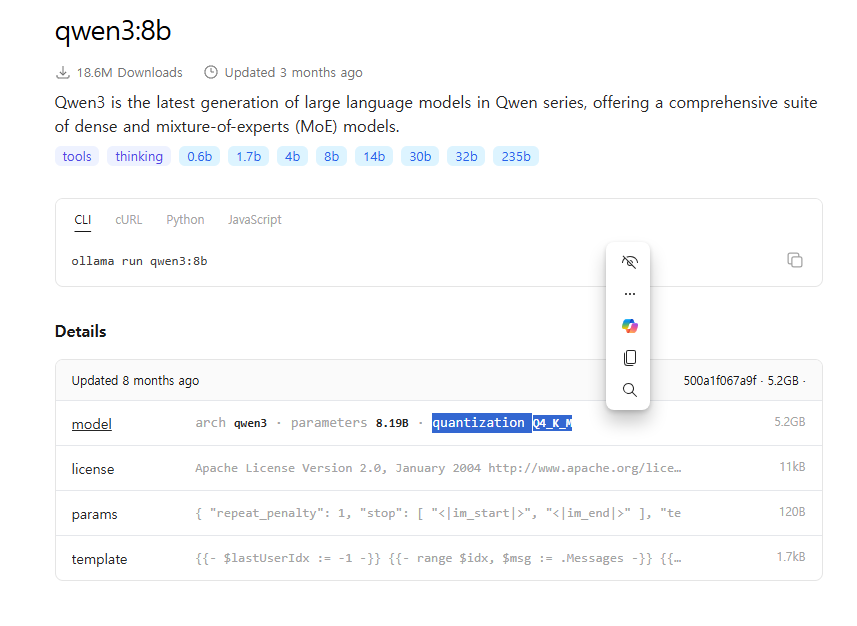
위 그림처럼 quantization: Q4_K_M 이라고 표기되어 있는데,
여기서 Q4 가 바로 4bit 양자화를 했다는 것을 의미한다.
그래서 우리가 아까 계산했던 16G 보다 1/4 크기로 잘려나가고,
거기서 조금 더 더해져서 결과적으로 5.2G 가 Size 에 표기된 것이다.
양자화 방식 분류
양자화 방식은 쉽게 생각해서 어떤 파일을 압축할 때 zip, rar, 7z 등 다양한 포맷이 있는데,
양자화도 이렇듯 모델을 파일로 저장/압축할 때 사용하는 형식(포맷)이 있다.
여기서 알아야 할 게 있는데,
양자화 방식에 따른 포맷은 추론 엔진에 따라 지원 유무가 다르다.
Ollama와 LM Studio는 GGUF 포맷, vLLM은 AWQ/GPTQ/FP8을 지원한다.
아무튼 이러한 양자화 방식은 다음과 같다.
| 추론 엔진 | 지원 양자화 | 주요 용도 |
|---|---|---|
| Ollama / LM Studio | GGUF (Q2~Q8) | 로컬 CPU/GPU |
| vLLM | AWQ, GPTQ, FP8, INT4/8, Marlin | 프로덕션 GPU 서버 |
| SGLang | AWQ, GPTQ, FP8, FP4, GGUF 등 | 고성능 추론 |
GGUF 는 특히 꼭 GPU 가 없는 환경에서도 사용할 수 있어서
호환성을 생각한다면 이걸 쓰면 된다. 하지만 GPU 가 없는 환경에서 된다고 하더라도,
성능은 압도적으로 안 좋을 것이다.
결론: 모델을 선정하는 기준
- 모델이 무엇인가?
- 모델의 크기 (=파라미터 크기)가 어느정도인가?
- 양자화를 어떻게 했는가?
🍀 추론 엔진 실습
이 목차에서는 개인 사용을 위해 나온 추론 엔진인 Ollama, LM Studio 의 간단 사용법을 알아보겠다.
Ollama
다운로드 링크: https://ollama.com/download
본인이 Docker 를 사용한다면, 이와 유사한게 Ollama 다.
Ollama 는 Docker for LLMs 라고 해도 될 정도로 그 사용감이 비슷하다.
docker 에서 컨테이너를 pull 해서 다운로드 받고, run 해서 실행하는 것처럼,
ollama 도 ollama pull, ollama run 등의 명령어를 지원한다.
Ollama 모델을 컨테이너 이미지처럼 관리한다.
이러한 모델들은 ollama list 로 확인도 가능하다.
또한 ollama 는 모델을 메모리에 올리게되면, 이와 상호작용을 할 수 있도록
API 를 제공하고, 이때 사용하는 API 규격은 OpenAI 호환 Rest API 이다.
CLI 활용
# 모델 설치
$ ollama pull qwen3:1.7b
pulling manifest
pulling 3d0b790534fe: 100% ▕██████████████████████████████████████████████████████████████████████████▏ 1.4 GB
pulling ae370d884f10: 100% ▕██████████████████████████████████████████████████████████████████████████▏ 1.7 KB
pulling d18a5cc71b84: 100% ▕██████████████████████████████████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕██████████████████████████████████████████████████████████████████████████▏ 120 B
pulling 517ccaff02fe: 100% ▕██████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
# 모델 목록 확인
$ ollama list
NAME ID SIZE MODIFIED
qwen3:1.7b 8f68893c685c 1.4 GB 3 hours ago
# 모델 상세 확인
$ ollama show qwen3:1.7b
Model
architecture qwen3
parameters 2.0B
context length 40960
embedding length 2048
quantization Q4_K_M
Capabilities
completion
tools
thinking
Parameters
top_k 20
top_p 0.95
repeat_penalty 1
stop "<|im_start|>"
stop "<|im_end|>"
temperature 0.6
License
Apache License
Version 2.0, January 2004
$ ollama run qwen3:1.7b "docker 에 대해 설명해줘"
# 위처럼 질문하는 건 1회성 질문이다. Context 같은 걸 기대하면 안된다.참고: Generate API vs Chat API
원래 AI 의 출발이 빈칸 완성, 문장 완성할 때 쓰는 용도였고, 그게 Generate API 다.
반면 Chat API(ollama 에서 instruct 모델) 는 조금 더 채팅 형태로 대화를 하는 느낌을 준다.
문장완성, 코드 완성은 Generate API 를 써라!
LM Studio
LM Studio는 로컬 LLM을 활용하기 위한 GUI 앱이다.
비개발자도 쉽게 다양한 모델을 탐색하고 테스트할 수 있습니다.
사실 LM Studio 는 단순히 추론 엔진일 뿐만 아니라 통합 플랫폼의 역할도 한다.
GUI 를 제공해서 사용자들이 편하게 사용할 수 있도록 해주니 통합 플롯폼이기도 한 것이다.
설치 링크: https://lmstudio.ai/
모델 검색 및 설치
LM Studio 를 실행하고, 좌측에서 메뉴에서 맨 아래 로봇에 돋보기가 그려진
아이콘이 있는데, 그걸 클리갛여 모델 검색창을 활성화 한다.
그러면 아래처럼 허깅페이스를 통해서 다운로드 받을 수 있는 모델을 목록들이 쫙 보인다.
참고로 ollama 랑 lm studio 가 llm 가져온느 곳이 다르다!
ollama 로 설치했다고, LM Studio 가 그걸 인식할 거라는 기대는 하지 말자.
qwen3 1.7b 를 검색해보니 아래처럼 나온다. 다운로드 버튼을 클릭한다.
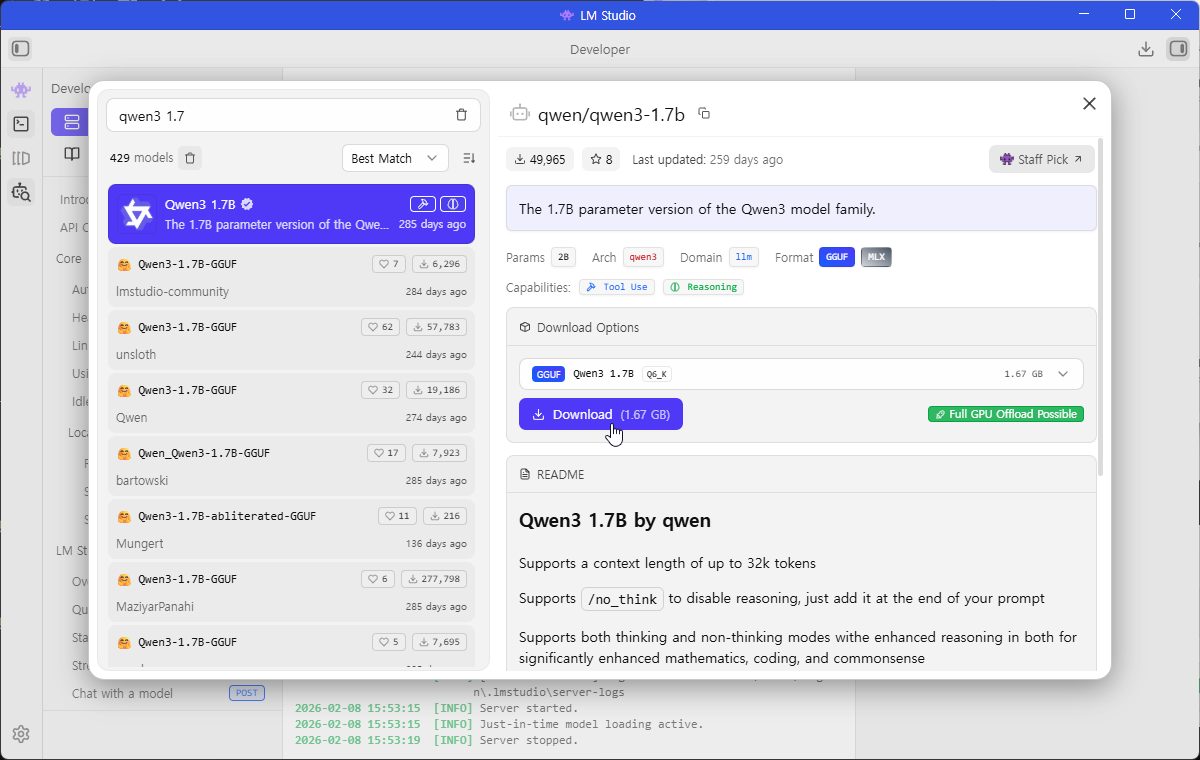
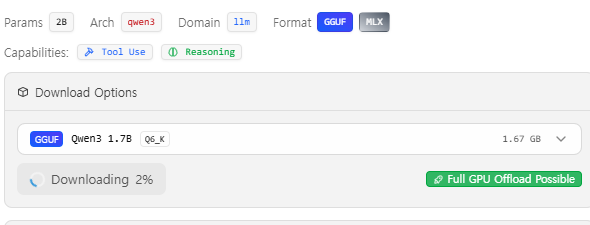
이후에는 아래처럼 Downloading 표기가 보이고 설치를 시작한다.
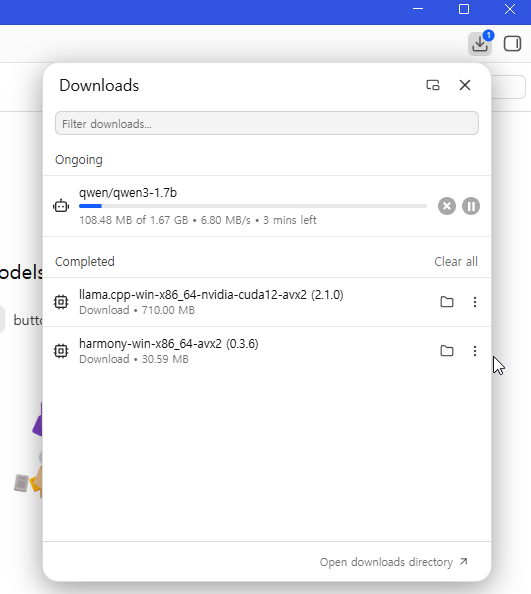
다운로드 진행도는 우측 상단에 있는 화살표 아이콘을 누르면 확인 가능하다.
그리고 설치가 완료됐다면 아래처럼 목록으로 확인도 가능하다.
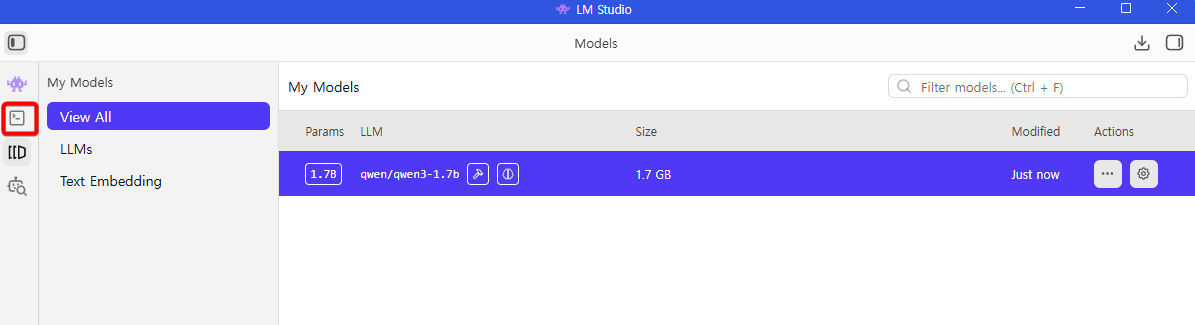
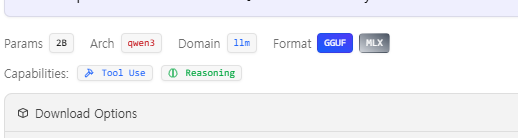
그런데 위그림처럼 모델 아래에 이것저것 작성되어 있다.
Params 는 파라미터 크기를 의미하고, Arch 는 모델이 소속된 그룹을 의미한다.
그외에도...
Domain: 용도, 꼭 llm 만 있는게 아니라 임베딩 모델 같은 것도 있기 때문이다.Format: 모델 파일의 (양자화)포맷 의미한다. 참고로MLX은 Mac 용으로 조금 더 좋은 포맷이다.Capabilities: 모델에 어떤 특징이 있는지 알려준다.Tool Use: 이게 없으면 단순 챗봇같은 거고, 뭔가 다른 기능을 호출하는 거면 이게 있어야 한다.
예를 들어 플러그인 같은 것들(js-sandbox) 같은 걸 사용하려면 이게 필요하다.Reseaoning: 한번 생각을 하고 말하는 것이다.Thinking한다고 나오면 이런 리즈닝 모델이다.
Vision: 이건 입력으로 이미지 같은 걸 줄 수 있다는 의미다.
local server 활성화
때로는 LM Studio 말고, 외부에서 LLM 에 채팅을 날리고 싶을 수도 있다.
이럴 때는 Local Server 기능을 활성화해주기만 하면 된다.
이러면 LM Studio 가 하나의 서버가 되고, 외부 다른 프로그램에서
LLM 에 보낼 요청을 REST API 로 호출이 가능토록 해준다.
자세히 보면 Supported Endpoint 라는 게 있는데, LM Studio 를 통해서
API 요청을 할때 어떻게 보낼 수 있는지를 알려준다. OpenAI 가 사실상 표준이니 이걸 사용하자.
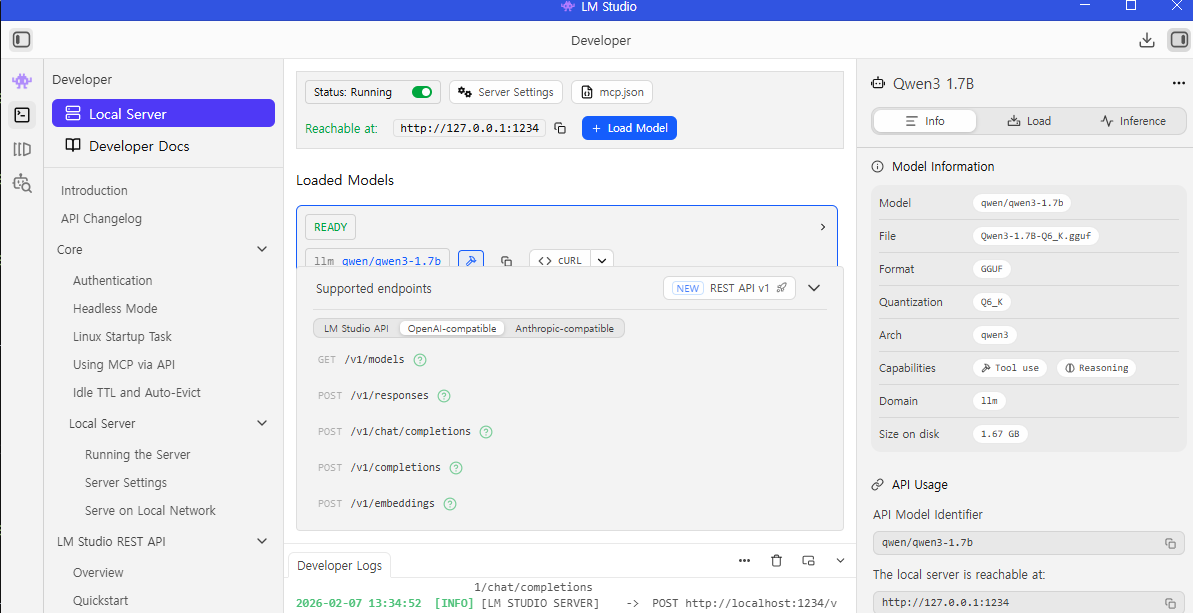
이후에 아래처럼 호출이 가능하다.
모델 끼우고 채팅 시작
좌측 메뉴에서 외계인 아이콘을 누르고, New Folder 클릭, 새로 생긴 디렉토리에 있는 체크박스 클릭.
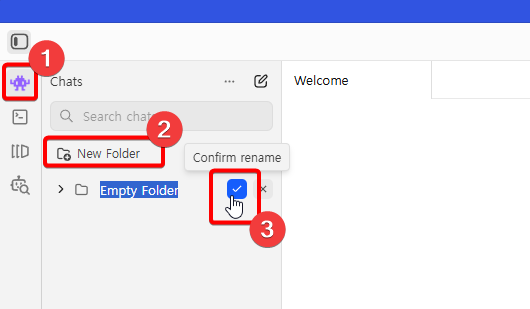
새로 생성한 디렉토리에 마우스 우클릭 후 New Chat in Folder 를 클릭하여 채팅방을 생성한다.
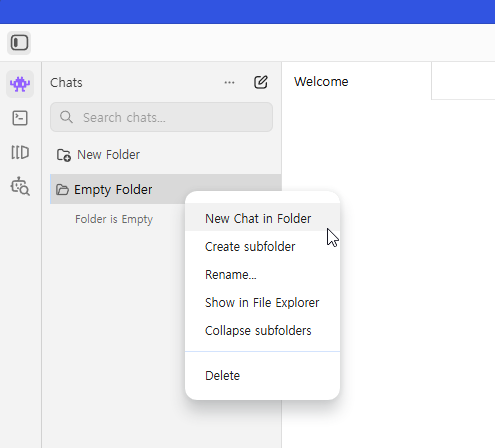
채팅방 입력란에 Pick a model 을 클릭하고, 앞서 설치한 모델을 클릭한다.
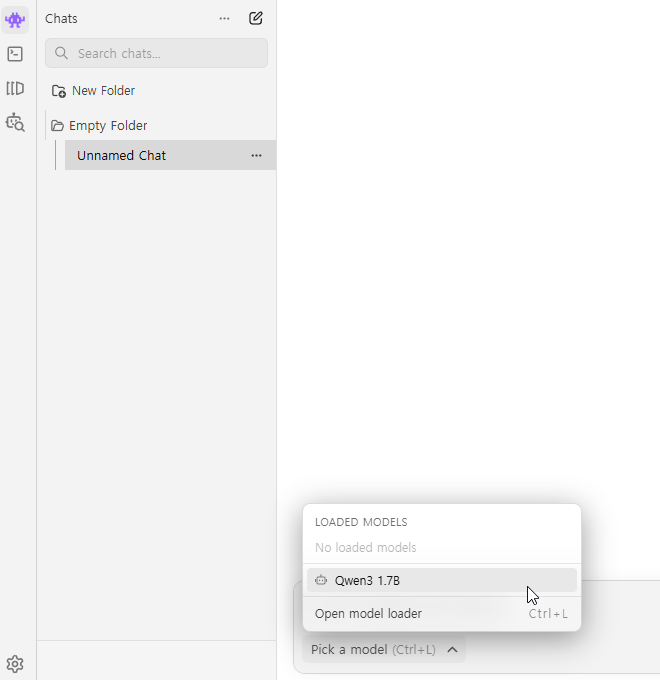
이후에 상세한 설정이 나오는데, 다 하고 나서 Load Model 을 클릭한다.
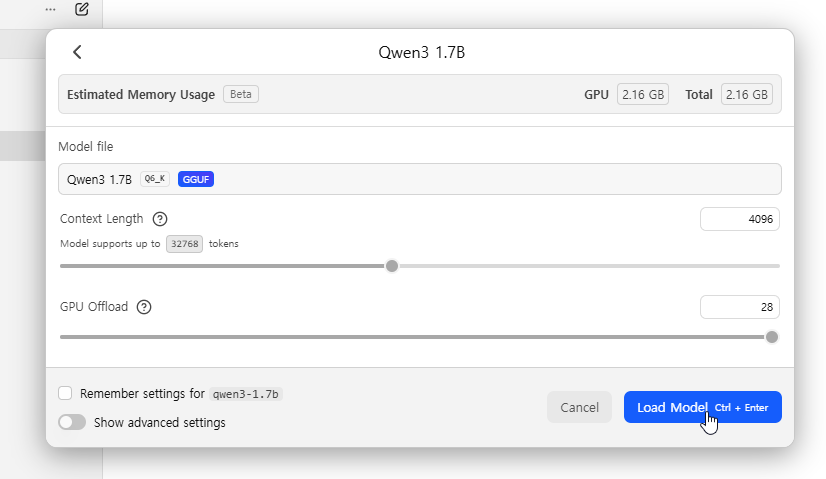
이후에 채팅하면 된다.
🍀 통합 플랫폼
이제는 추론엔진이 구동된 상태에서 이를 활용한 통합 플랫폼을 사용해 볼 것이다.
이 목차에서는 OpenWebUI(ChatGPT 스타일 채팅 서비스),
AnythingLLM(RAG 기반 문서 검색 시스템)에 대해서 알아보자.
OpenWebUI
ChatGPT 스타일의 오픈소스 웹 인터페이스다.
Ollama, OpenAI, vLLM 등 다양한 LLM 백엔드와 연동이 가능하다(=멀티 백엔드).
그뿐만 아니라 사용자 관리, 인증, 권한 제어로 팀 협업 지원한다.
회원가입과 관련된 기능이 이미 내장되어 있다.
권한 제어를 통해서 특정 어떤 조직에게는 좀 가벼운 모델만 쓰도록 제한하고,
핵심 개발자들에게는 무거운 모델을 사용할 수 있도록 해준다.
설치
직접 설치하지 않고, Docker 로 컨테이너를 띄우는게 일반적이다.
https://github.com/open-webui/open-webui 에 접속해서 docker run 커맨드를 복사해서 실행한다.
docker desktop 을 실행하고, 아래처럼 명령어 실행(이거 github 에서 복사해온 거임)
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main참고로 이렇게 하면 host pc 에 설치된 ollama 와 연동해서 동작한다.
설치가 완료되면 localhost:3000 에 접속한다.
첫 접속
처음 접속하면 아래처럼 관리자 계정 생성 페이지가 나온다. 적절하게 생성한다.
이후에 아래처럼 나온다.
- 올라마에 연결해서 동작해서, 올라마에 설치한 모델을 바로 적용함.
참고로 좀 더 세세하게 프롬프트 설정을 하고 싶다면 우측 상단 제어 아이콘을 클릭하면 된다.

관리자 패널
좌측 하단에 자신의 닉네임이 보이는 곳을 클릭하면 아래처럼 나오는데,
여기서 관리자 패널을 클릭한다.
이후에 어떤 화면이 나오는데, 거기서 상단에 "설정" 버튼을 클릭한다.
그러면 나오는 화면이 본격적으로 관리자가 설정해야될 부분이 나온다.
일반
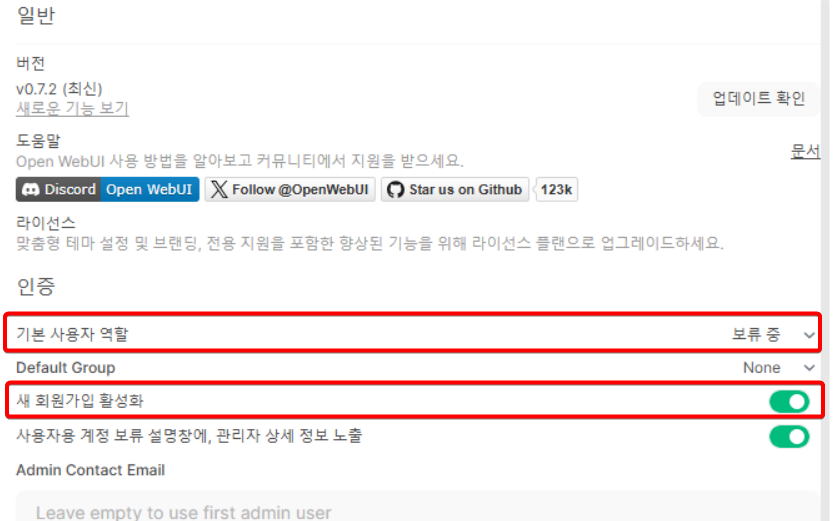
위처럼 기본 사용자 역할을 보류 중 으로 하고,
새 회원가입 활성화를 하면 이제부터 새로운 사용자가 도메인에 접속해서
회원가입 신청을 할 수 있다.
하지만 신청을 수락할지 말지는 관리자가 결정하게 된다.
연결
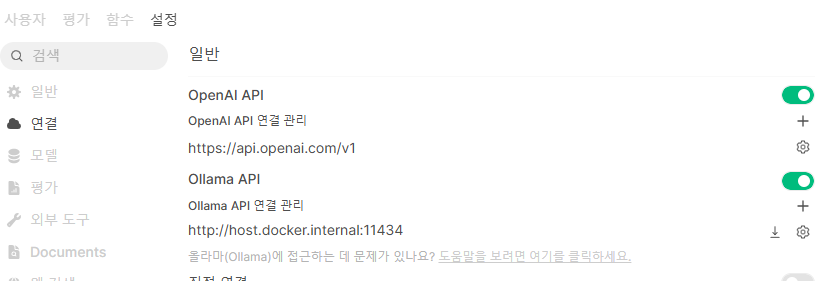
보면 알겠지만, 추론 엔진이나, 다른 Cloud API 를 연동할 수 있는 화면이 나온다.
여기서 OpenAI 와 연동을 하거나, Ollama 와 연동하는 설정을 넣을 수 있다.
모델
모델 목록을 확인할 수 있다.
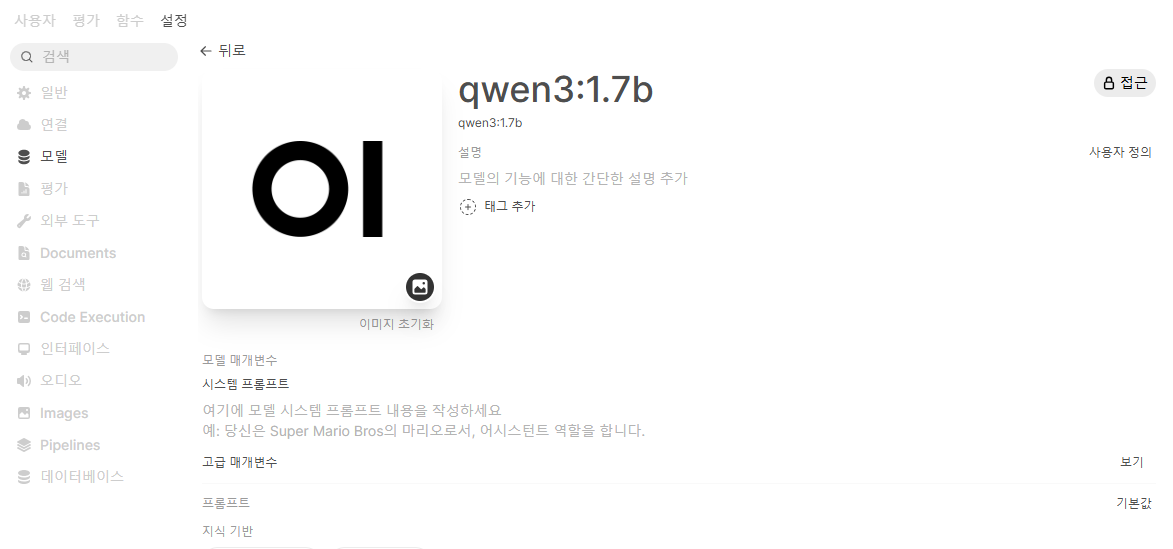
우측 상단의 접근 버튼을 클릭해서
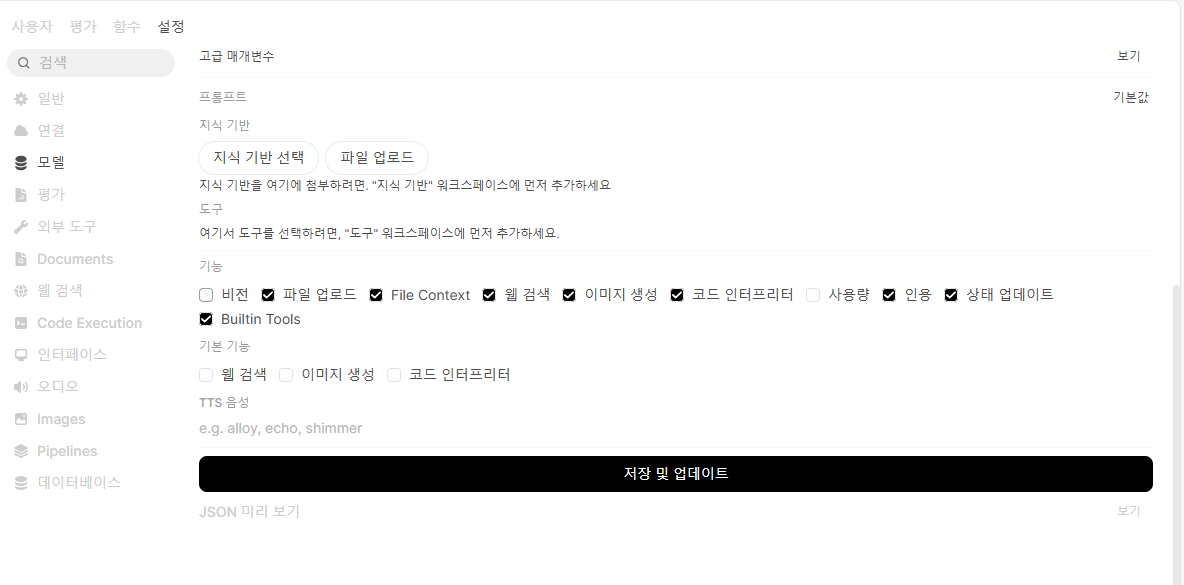
qwen 은 비전 기능이 없기 때문에 꺼주자!
저장 및 업데이트도 클릭!
평가
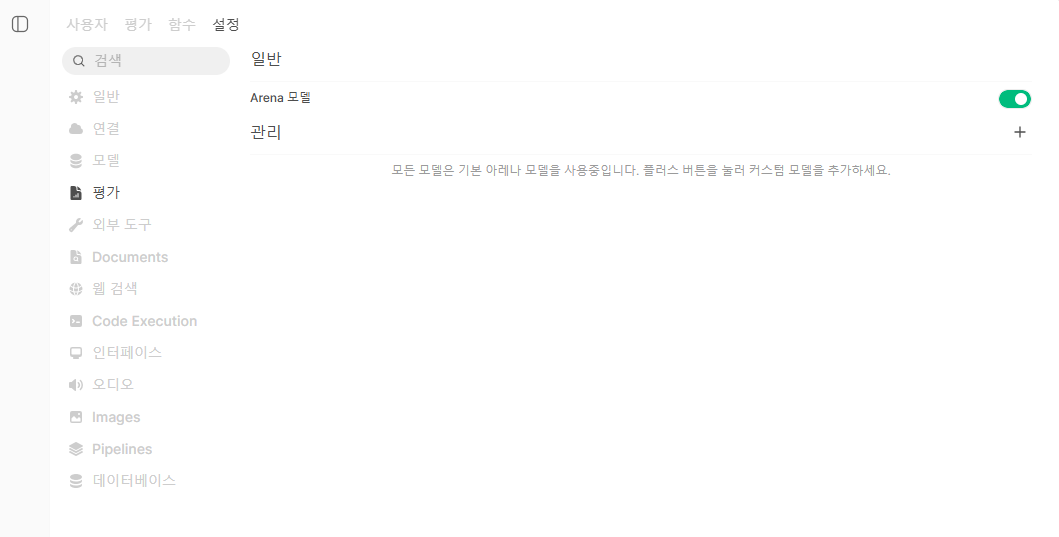
벤치 마킹을 위한 건데, 방법이 어떤 문제를 주고, 평가해보는 것이다.
여기서는 Arena 모델이 있는데,
이거는 2개의 모델을 뽑아서 동시에 답변을 뽑아내고,
그중에서 더 좋은 걸 뽑아내는 거다.
이 기능은 https://arena.ai/ 에서 테스트해볼 수 있다.
참고로 처음에는 어떤 모델을 쓰는지는 숨기고,
평가를 내리면? 그때 딱 알려준다.
외부도구
MCP 랑 비슷하지만 MCP 가 나오기 전부터 있던 기능이다.
아무튼 외부 API 호출이 가능하다.
Documents
대망의 RAG 관련 설정이다.
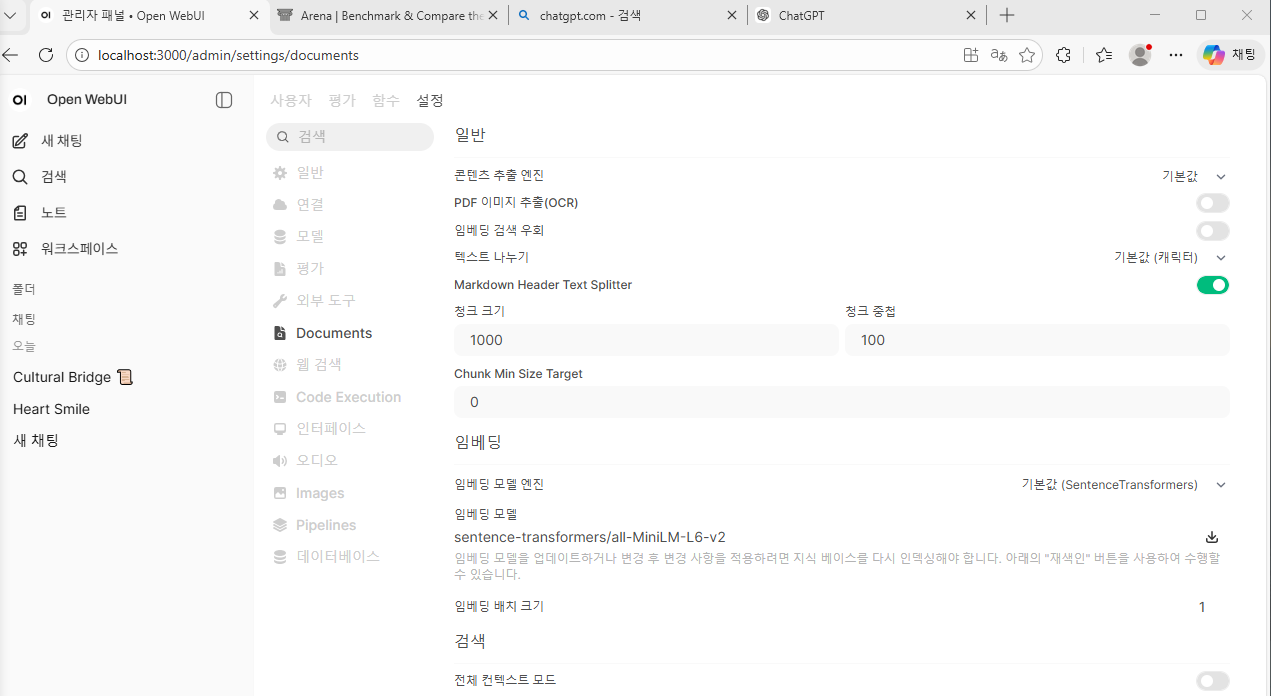
참고:
여기서 말하는콘텐츠 추출이라는 건 예를 들어서 pdf 에서 텍스트를 추출하는 그런 것들을 위한 엔진이다.OCR 기능은 시간과 자원을 많이 먹으니 조심!
pdf 같은 경우는 먼저 텍스트 추출하고 RAG 하는 게 좋다.임베딩 검색 우회는 그냥 컨텍스트를 한방에 다 넣냐는 건데, 그냥 OFF 하자.
계속 스크롤을 내리면...
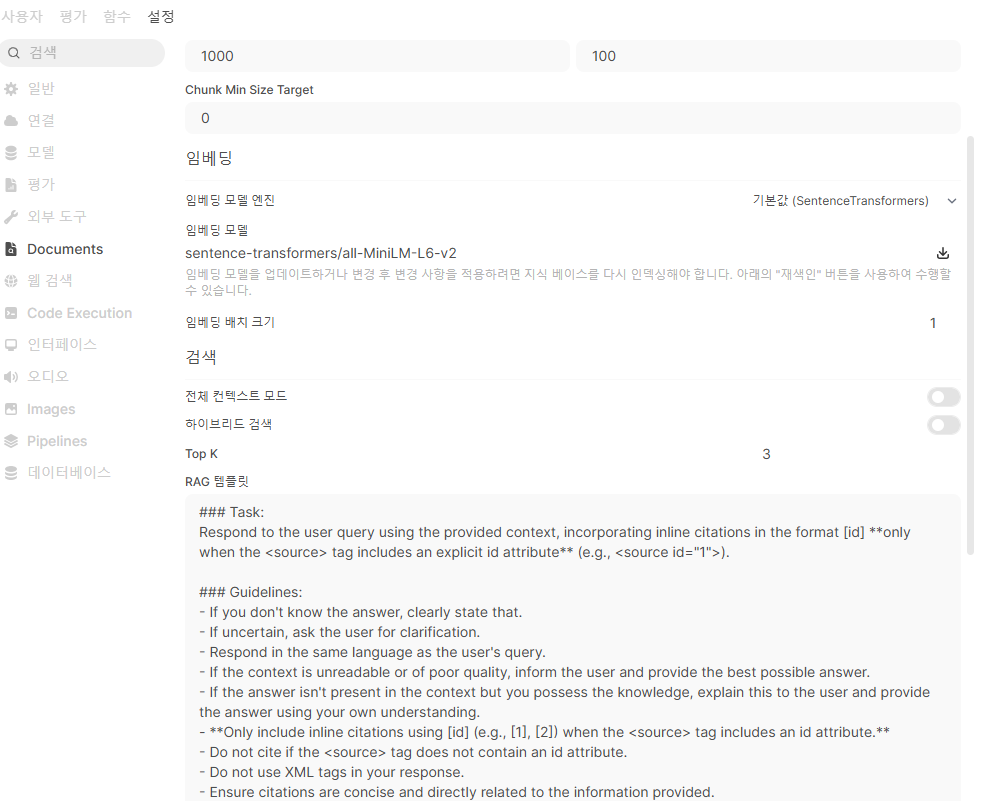
참고로 임베딩 모델은 OpenAI 가 가장 좋다고 한다.
(https://platform.openai.com/docs/guides/embeddings)
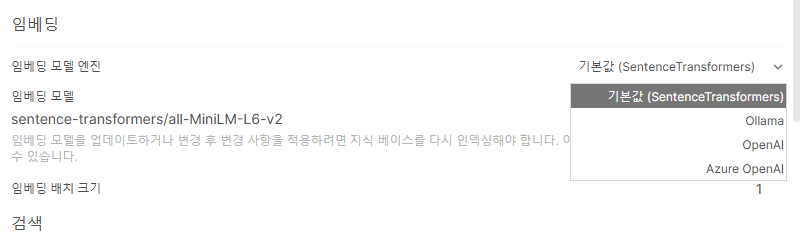
하지만 비용이 발생하고, 외부에 요청이 한번 나가서, 기본값 또는 Ollama 를 사용하는 게 좋다.
ollama 선택하게 되면 ollama 를 통해서 설치한 embedding model 의 이름을 지정하면 된다.
먼저 ollama 에 접속해서 embedding 모델을 하나 선택해준다.
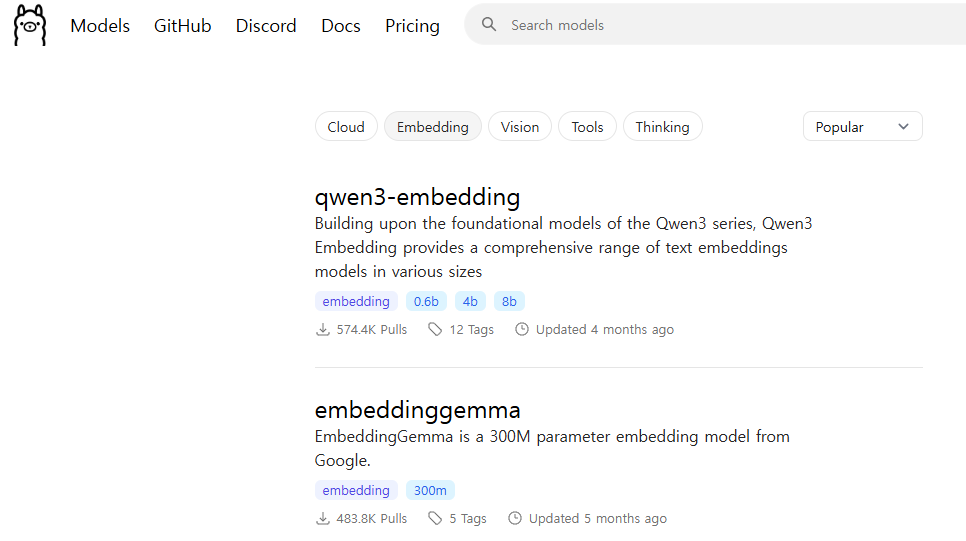
- qwen3-embedding : 이건 그나마 최근임!
- embeddinggemma
- bge-m3 : 사양 좋으면 이거 쓰시고~
여기서는 qwen3-embedding 를 선택하겠다.
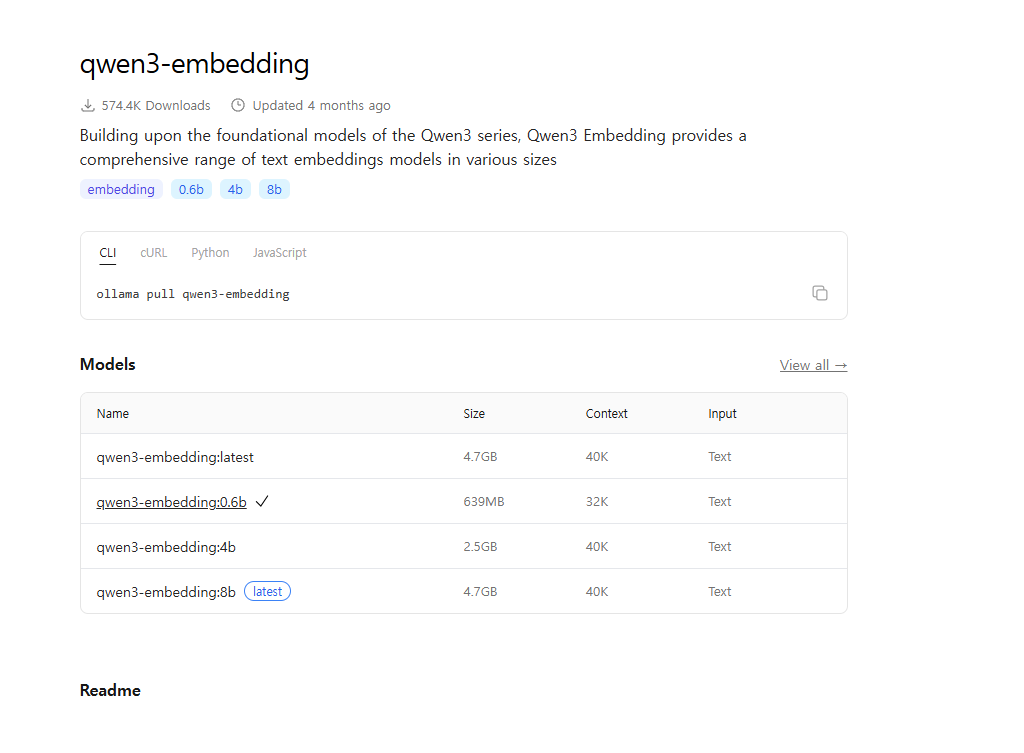
아래처럼 설치 진행...
ollama pull qwen3-embedding:0.6b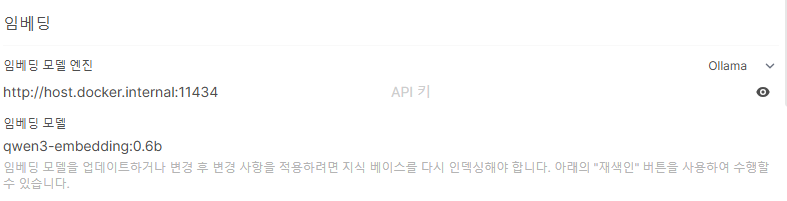
위처럼 다시 설정!
그런데... 지식 베이스를 다시 인덱싱해야 합니다. ???
기존의 임베딩 모델을 통해서 벡터라이징 한걸 다시 Vectorizing 해야된다는 의미다
그래서 맨 밑에 재색인 이라는 버튼이 있다.

재색인 을 클릭하면 지식 베이스에 있던 걸 모두 다시 벡터라이징 한다.
임베딩 모델은 참고로 질문할 때 그 질문 자체도 임베딩을 한다!
그래야 Vector DB 에서 찾을 수 있으니까!
현재 openwebui 도 내부적으로 vector db 가 이미 있다(?)
이건 좀 조사해봐야 할듯!
아무튼 스크롤을 또 계속 내리면...

-
Async Embedding Processing는 큐에 넣고 작업하겠다는 의미 -
전체 컨텍스트 모드는 무조건 OFF, 이거 하면 문서를 그냥 다 컨텍스트에 때려박는다.
-
Top k 는 일종의 순위 매기고 거기서 3개만 자르겠다는 거다.
작게하면 조금 더 정확하게 나온다. Context 를 아낄 수도 있다.
크게하면 조금 반론의 여지가 있는것도 대답한다.
더 스크롤을 내리면...
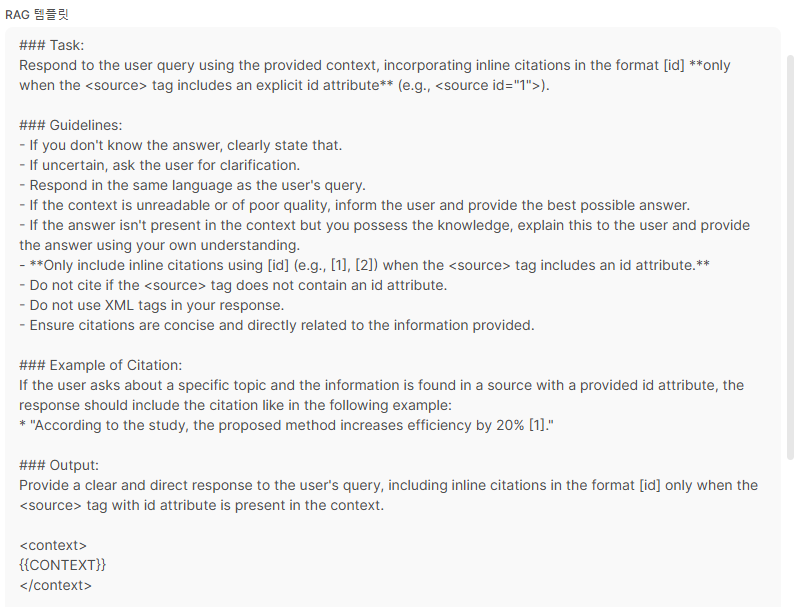
- RAG 템플릿: 답변에 대한 템플릿. 이게 중요하다!
- 이거를 통해서 답변을 조금 더 정제된 답변을 주게 할 수도 있다!
TIP: 지식 기반
OpenWebUI 에는 지식 기반 이라는 게 있는데,
하나의 그룹을 만들고, 그 그룹 안에 다른 사람들과 공유할 문서를 업로드하고,
추후에 다른 사람들이 각자의 채팅에서 지식 기반 을 첨부해서 질문을 날릴 수 있다.
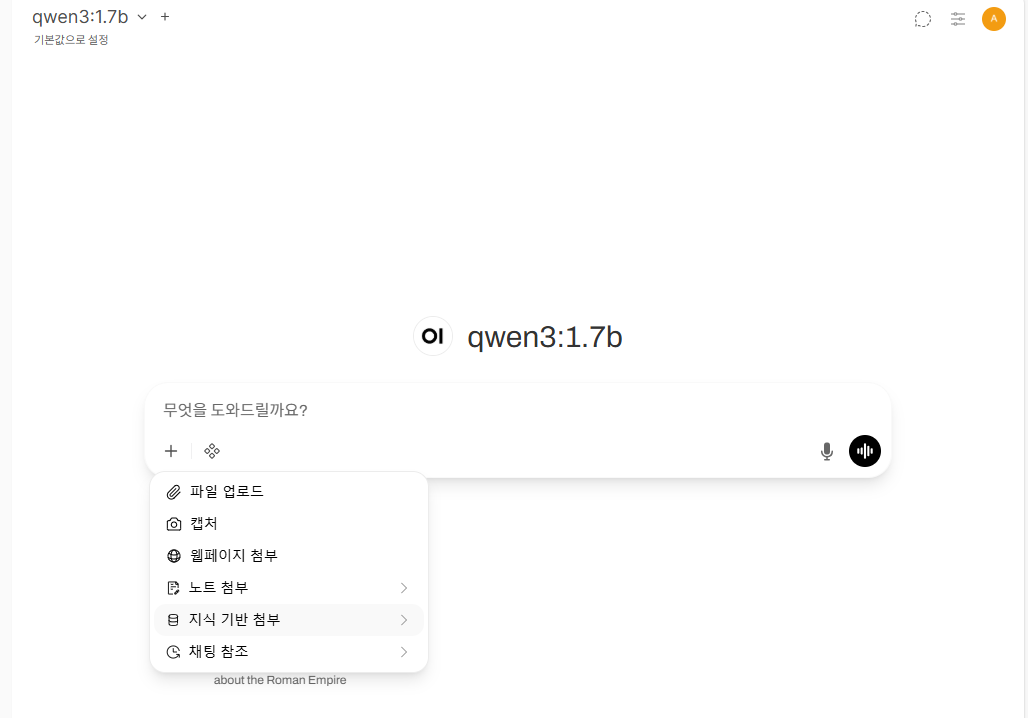
당연하지만 이 문서들은 RAG 기반으로 활용되는 것이다.
참고로 지식 기반을 생성하고 파일을 첨부하려면 먼저 좌측 메뉴에서 워크스페이스 를 클릭하고,
나오는 화면에서 지식 기반 을 클릭한다. 그러면 아래처럼 나온다.
우측 상단에 있는 지식 기반 생성 버튼을 클릭하면 아래처럼 나오는데, 먼저 그룹을 생성하게 된다.
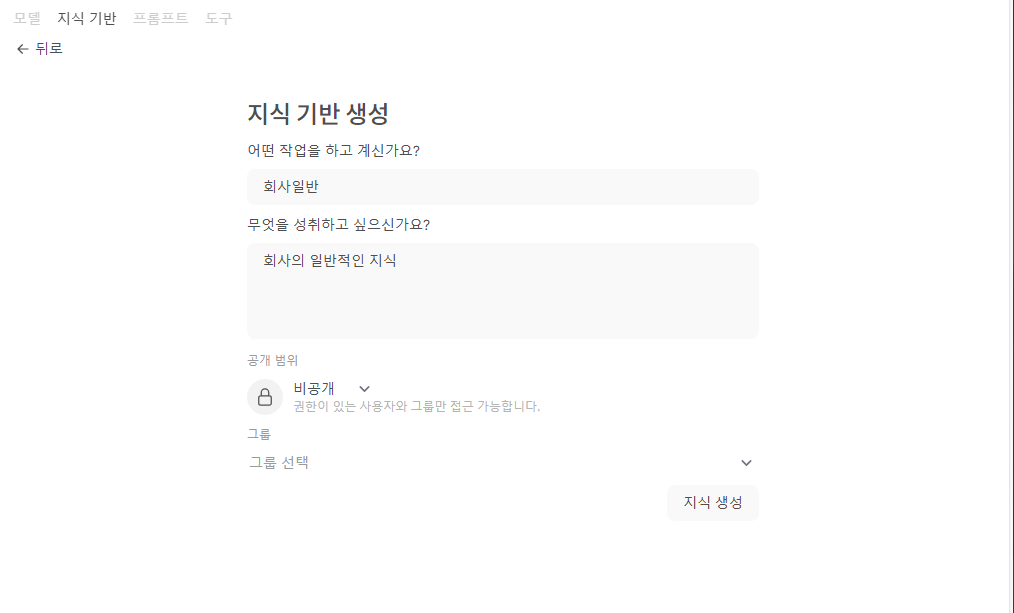
이후에 생성된 지식 기반에 파일 같은 것들을 올릴 수 있다.
정확히는 Vectorizing 을 해서 저장하게 되는 과정을 거치는 것이다.
모든 사용자의 새 채팅에서 접근 가능한 사용자들이 여기 올라간 자료를 참고할 수 있게 할 수 있다.
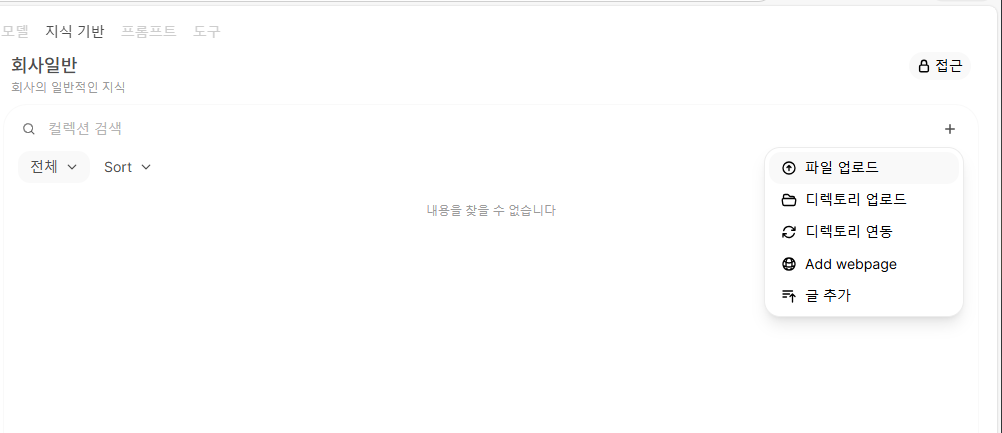

이렇게 파일을 업로드하면 임베딩이 되서 저장된다.
참고로 임베딩도 결국은 모델을 돌리는 거라서 PC 안 좋으면 느리다.
이후에 지식 기반을 선택하고...

업로드한 문서 관련해서 질문하면 그와 관련된 대답을 해준다...
물론 위처럼 실패할 때도 있다. 아무래도 모델이 워낙 작고, PC 성능도 좋지 않아서 그런 거 같다.
웹 검색
채팅 중에 웹 검색을 시킬 수도 있다.
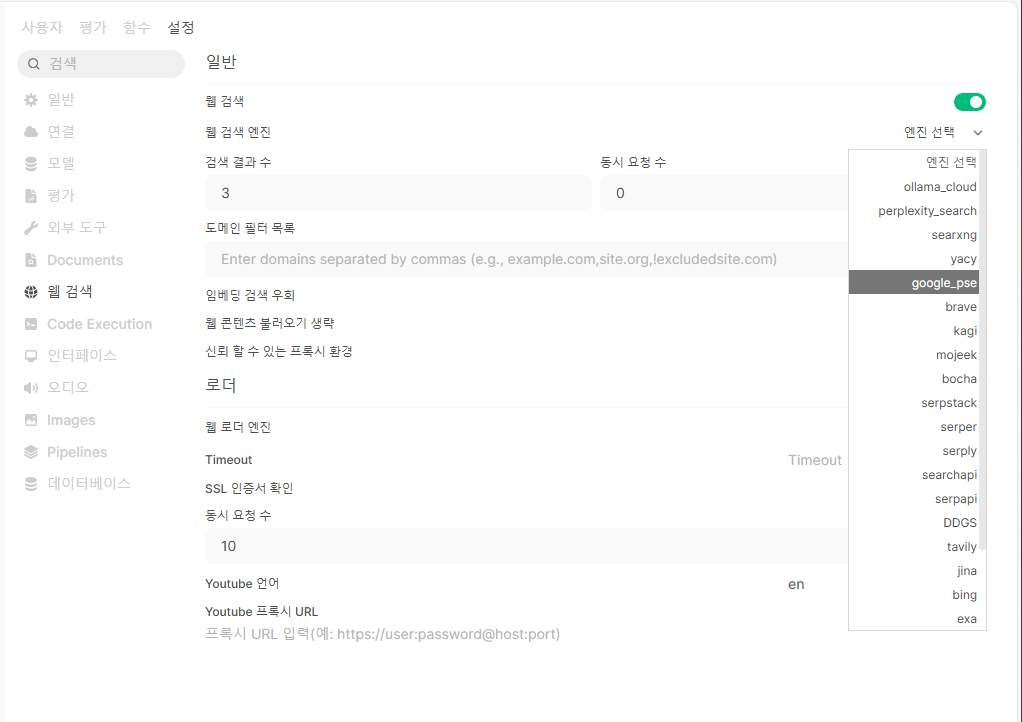
- perplexity_search 추천, 비용 듬!
- google 추천
- Brave 도 추천
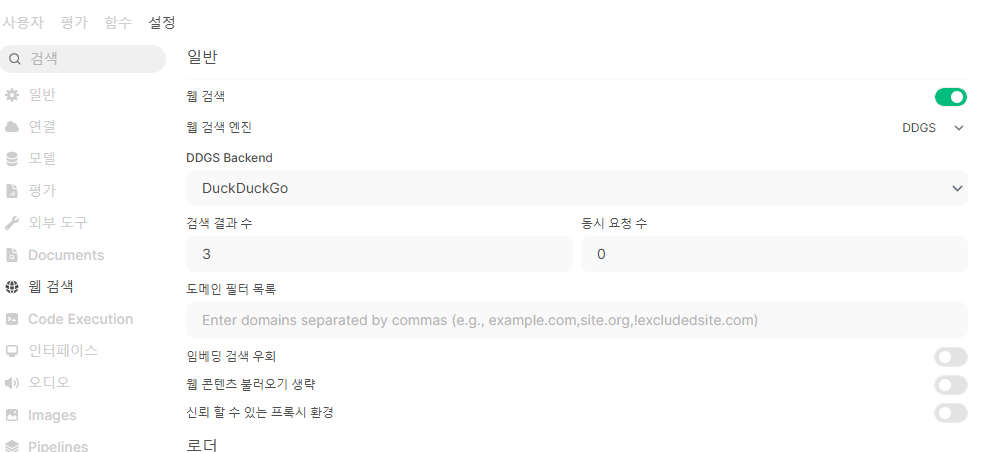
- DuckDuckGo 도 있다!
Code Execution

인터페이스
Skip!
오디오
음성 -> 텍스트 : Whisper 는 우리가 말로 하면 그걸 글로 프롬프트에 적어준다.
텍스트 -> 음성 : 좀 무쓸모임.
Images
이미지 생성 엔진을 지정하는 곳이다.
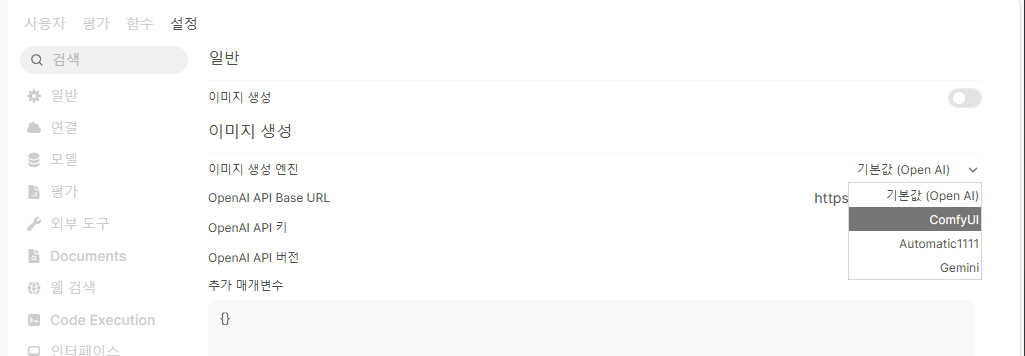
개인적으로 ComfyUI 를 추천한다.
Comfy 가 매우 핫하다.
이게 뭐냐면 로컬에 이 이미지 생성 전용 모델을 깔고, 그걸로 이미지 생성이 가능해진다.
https://www.comfy.org/ 에서 접속하고 상단 좌측에 Models 메뉴를 클릭하면
다운로드 해서 로컬에서 이미지 생성이 가능해진다.
대신 자원을 많이 먹는다.
TIP 을 드리자면 한 컴퓨터는 텍스트만, 다른 건 이미지만 생성하도록 서버를 나눠서 쓰면 좋다.
https://civitai.com/ : 허깅페이스와 비슷하지만, 이미지를 생성하는 모델들을 검색할 수 있다.
Pipelines, 데이터베이스 는 Skip
AnythingLLM
설치 링크: https://anythingllm.com/
마지막으로 NotebookLLM 과 굉장히 유사한 듯한 통합 플랫폼 솔루션인 AnythingLLM
사용법을 알아보자. 처음 키면 LLM 기본 설정이 나오는데, 나는 상단에서 사용할 백엔드를 Ollama 로 지정했고, ollama 에서 설치한 모델인 qwen3:1.7를 모델을 기본 채팅 모델로 지정했다.
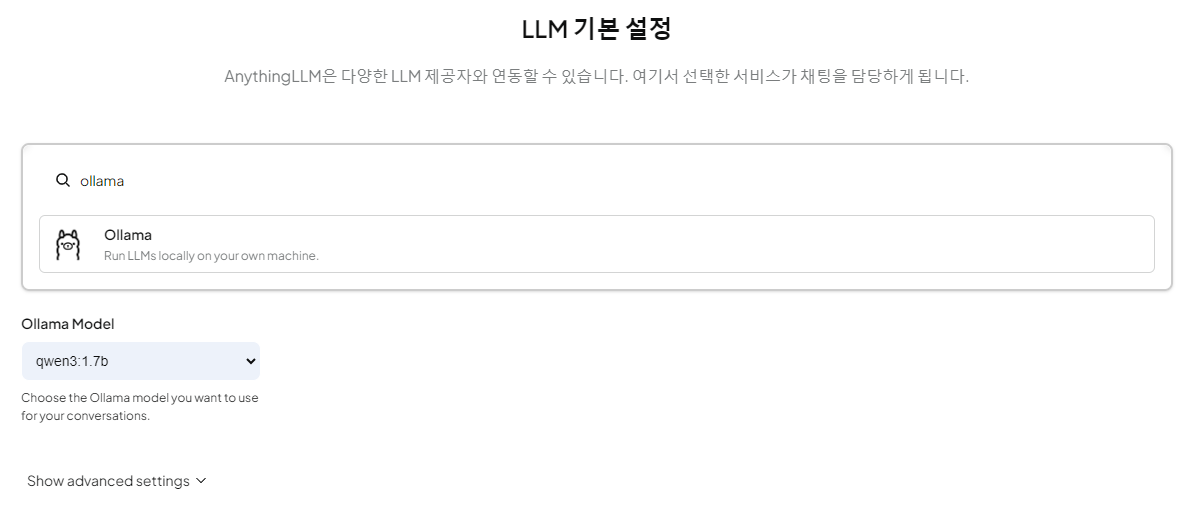
이후에 좌측 하단 Settings 클릭하면 다음과 같은 화면이 나온다.
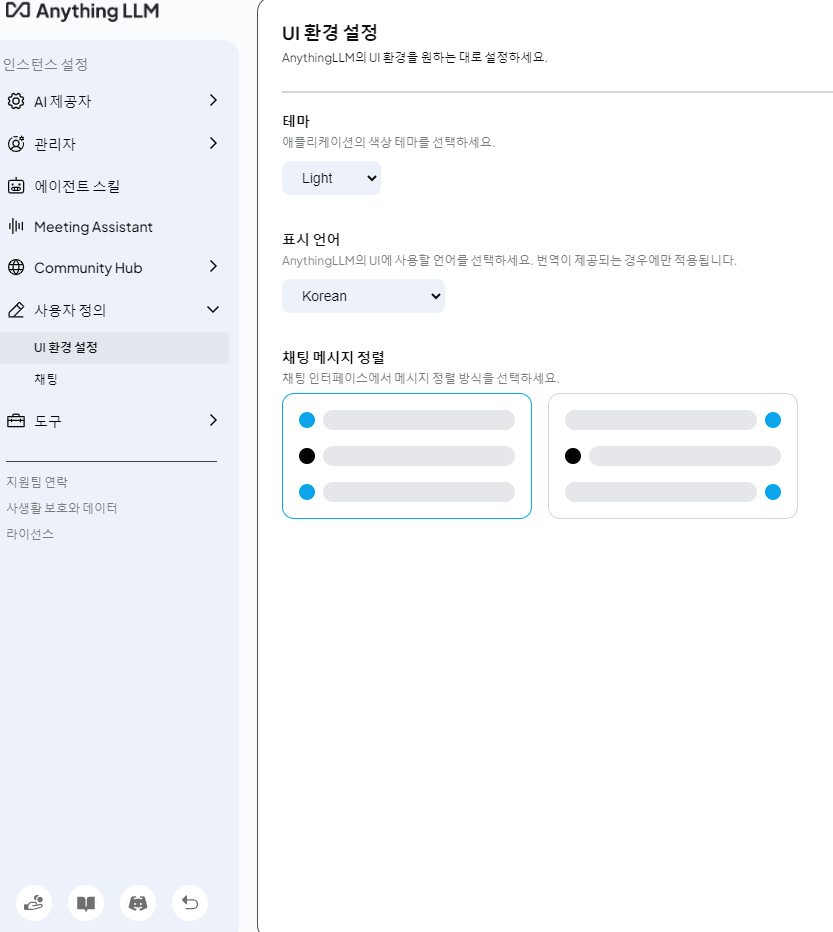
LLM 설정
소통할 백엔드 엔진(LLM 제공자)를 지정하고, 실제 사용할 모델을 지정한다.
그외에도 Ollama 와 API 통신하기 위한 URL 등을 지정한다.
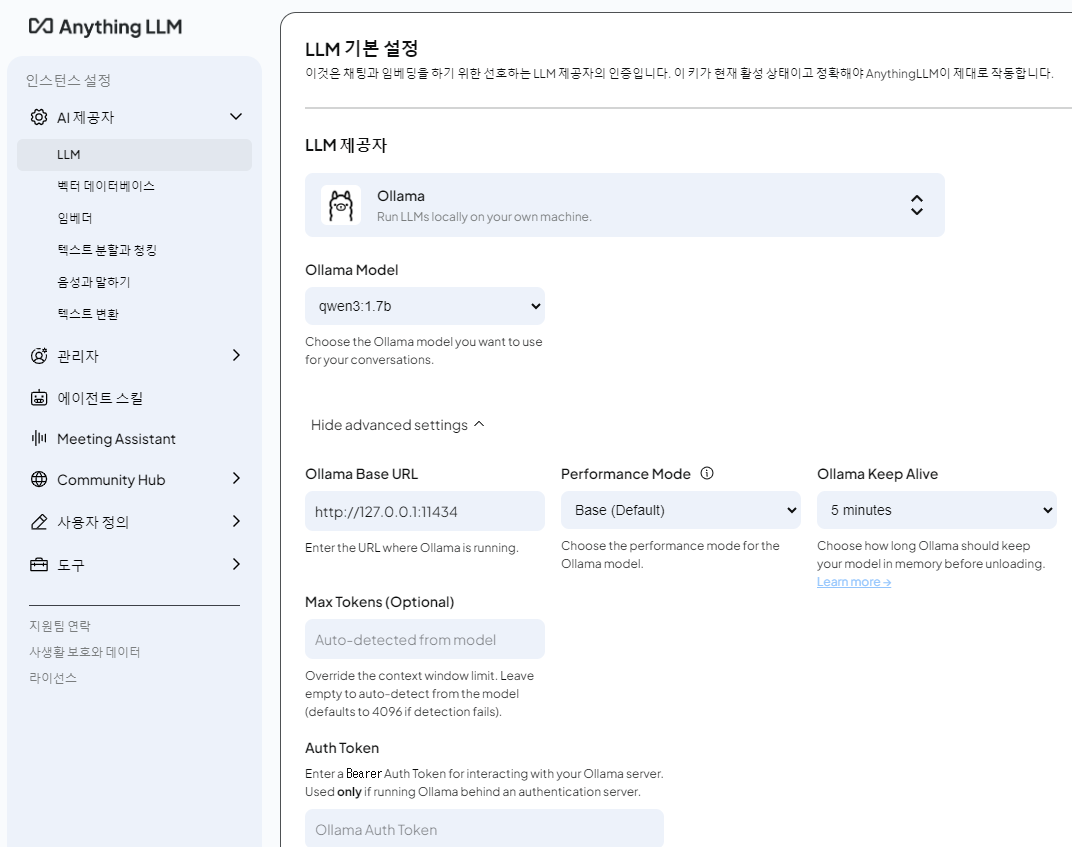
백터 데이터베이스
백터 데이터를 저장할 데이터베이스를 지정하는 곳이다.
기본적으로 LanceDB 가 설정되어 있다. 이러면 따로 뭔가 설치할 필요가 없어서 편하다.
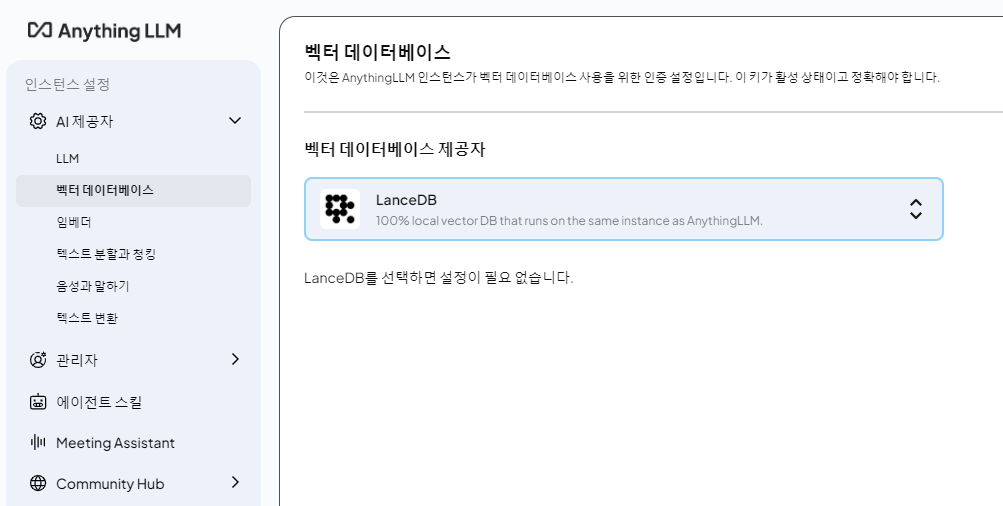
임베더
임베딩 모델을 지정하는 곳이다.
마찬가지로 ollama 에서 설치했던 임베딩 모델을 지정했다.
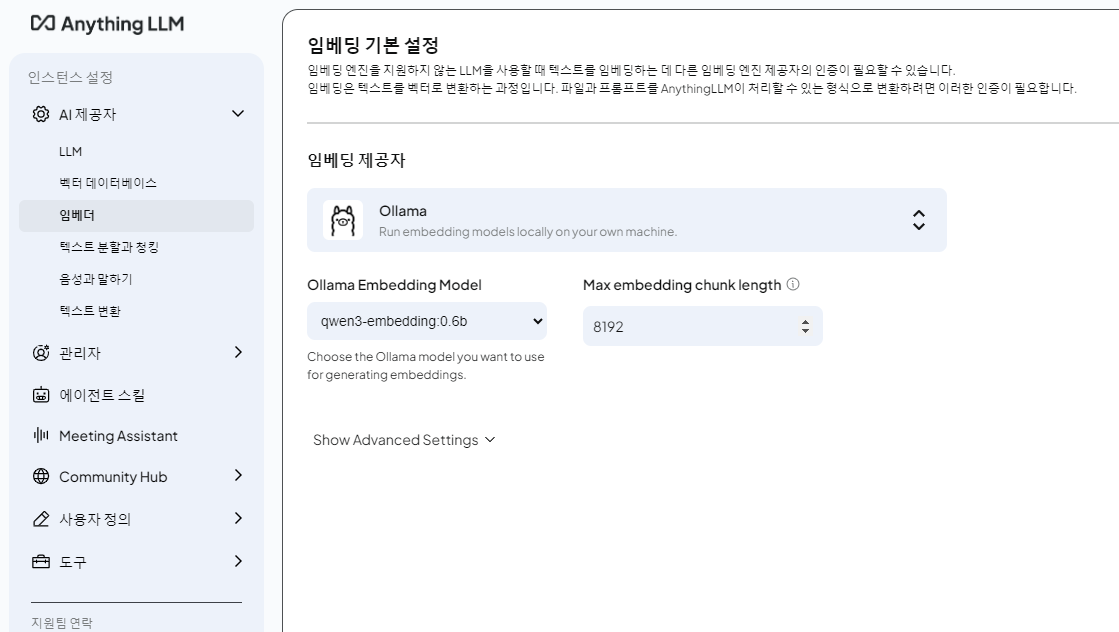
주의사항: 기본적으로 아래처럼 설정되어 있는데, 이거는 한글이 안 먹히니 주의하자!
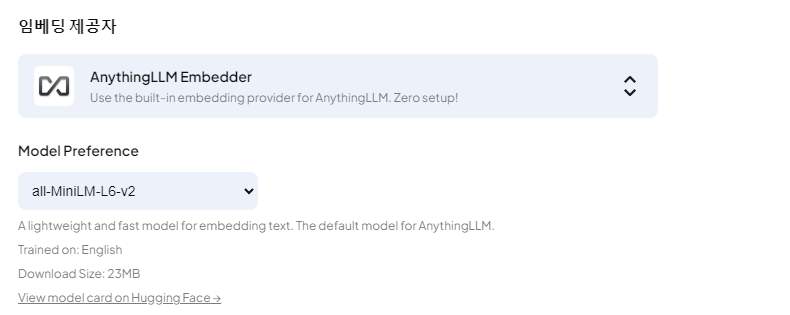
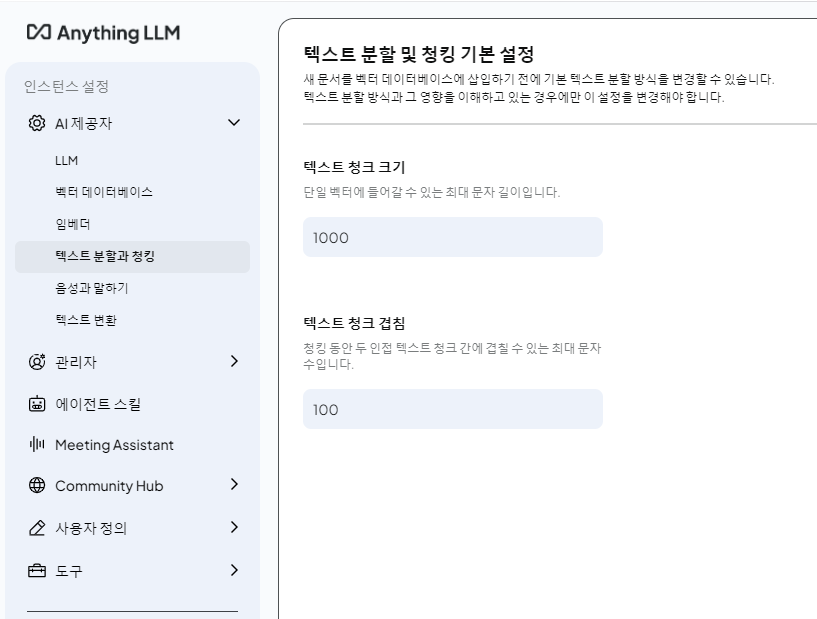
텍스트 분할과 청킹
굳이 설명 안하겠다.
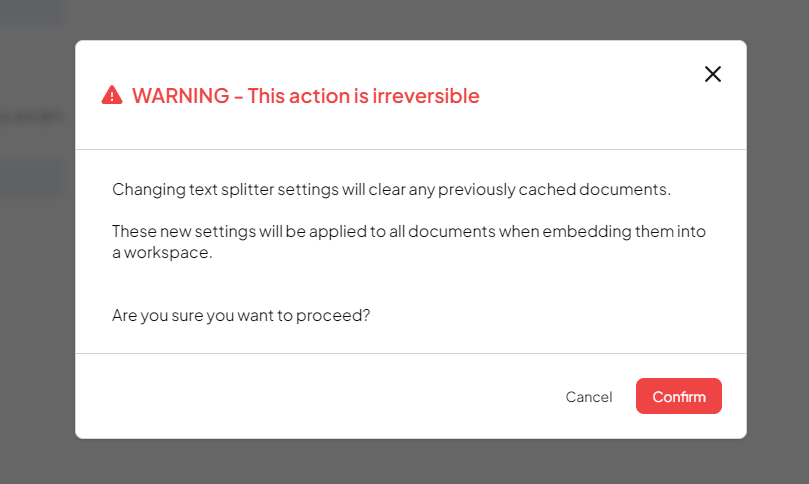
참고로 변경하고 설정을 하게되면 위처럼 경고문이 나온다.
그냥 Confirm 누르면 된다.
문서 임베딩
문서 관리 화면을 키면 아래처럼 팝업이 보인다.
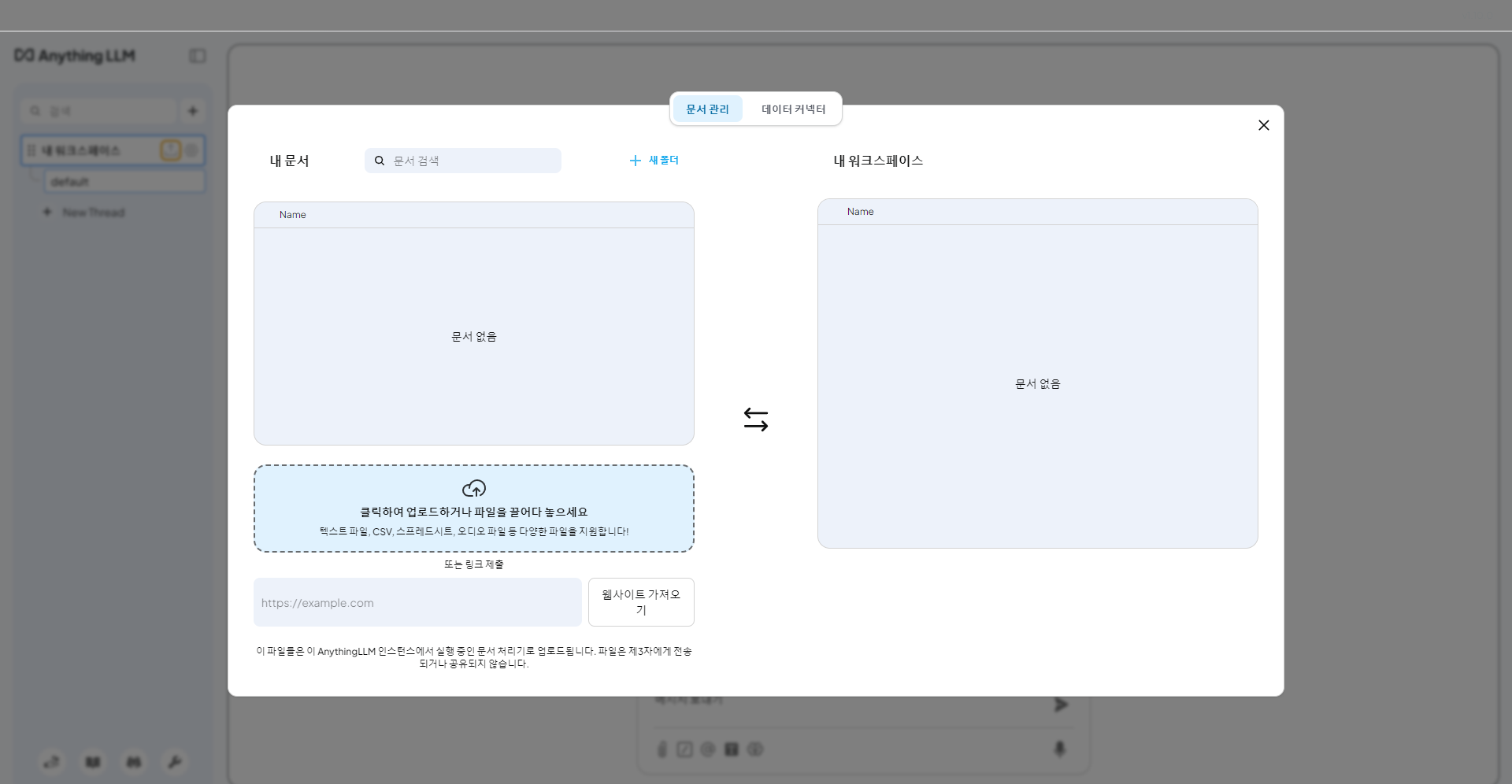
팝업 좌측에서 임베딩할 파일을 업로드한다.
그리고 나서 워크스페이스로 이동 을 클릭한다.
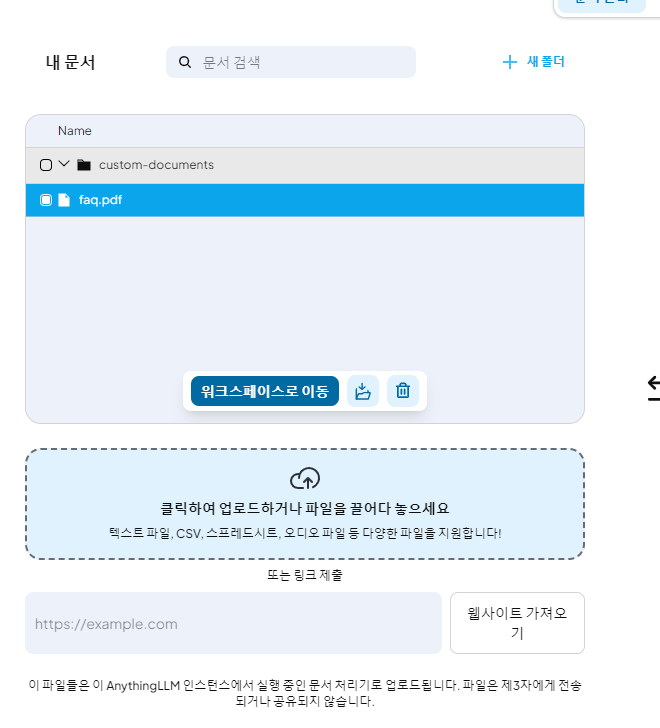
그러면 바로 옆에 있는 내 워크스페이스 로 파일이 옮겨진다.
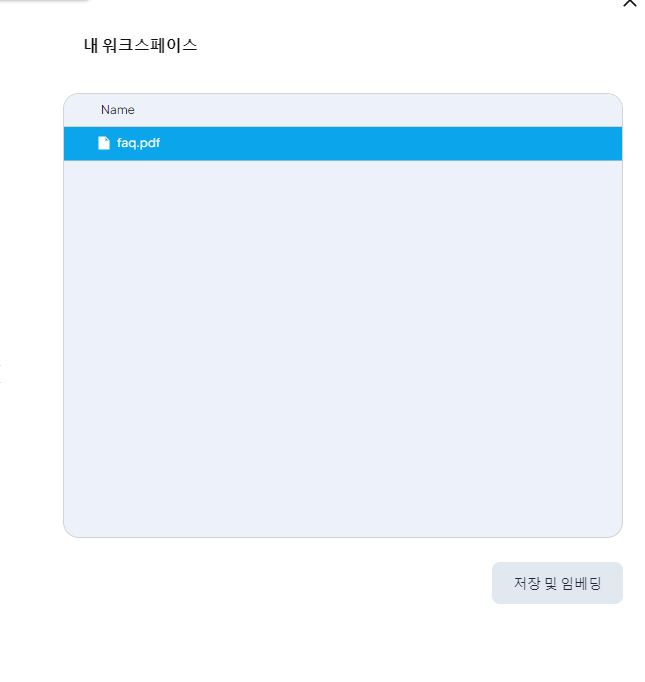
이후에 저장 누른 순간 임베딩이 시작된다.
채팅
내 워크스페이스 를 클릭하면 아래 default 라고 하나 생긴다. 이게 채팅방이다.
강사님 Pick:
notebooklm 을 한 번 꼭 사용해보세요.
https://notebooklm.google/특히 옆에 스튜디오 기능을 잘 쓰면 정말 좋습니다.
이 기능은 업로드한 소스 파일들을 기반으로 새로운 산출물을 만드는 기능들입니다.
TIP: jan app
https://www.jan.ai/ 앱이다 보니까 기능이 매우 많다.
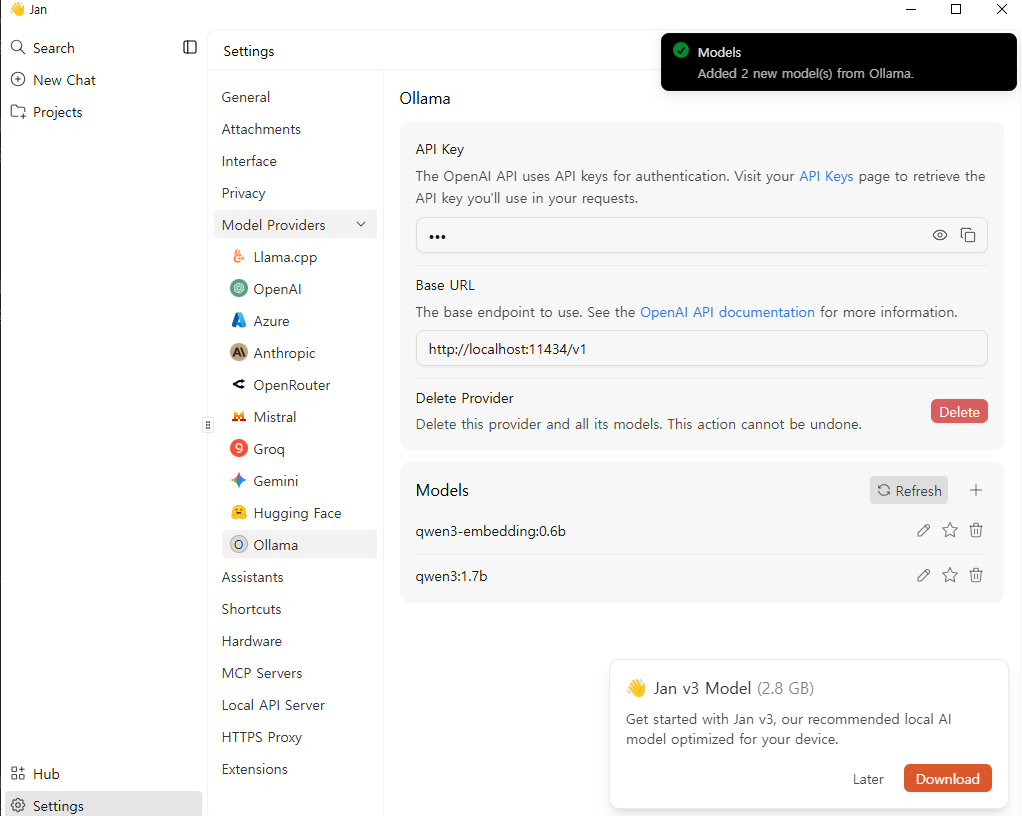
API Key 는 그냥 대충 넣으면 된다. 확인 안한다.
아예 안 넣어도 됨.
그리고 이외에도 MCP 기능도 활용하면 좋다.
🍀 RunPod
이야기를 안했지만, 우리는 vLLM 같은 실제 Production 에서 활용할 수 있는
추론 엔진에 대한 이야기는 안했다.
아무래도 워낙에 좋은 서버가 미리 구축되고 그위에서 테스트를 해야되다 보니,
일반 개인이 가볍게 테스트, 활용하기가 어렵다.
이때 좋은게 바로 RunPod 이다.
RunPod 를 통해서 연구 목적으로 GPU 서버를 빌릴 수 있다.
그걸 쓰는 법을 알아볼 것이다.
참고로 나중에 RunPod 의 서버 종류를 선택하는데,
Community Cloud 보다는 Secure Cloud 를 무조건 선택하길 바란다.
Community Cloud 는 등록이 됐지만 서버가 구동되지 않는 상태일 때가 많다.
물론 RunPod 쪽에서 이러면 환불을 해준다.
아쉽지만 이부분 부터는 돈이 나가는 영역이여서 제대로 필기를 못함.
언젠가 직접 테스트 해봐야 함.
🍀 추가적으로 알려주신 사항
허깅페이스 모델 용도 분류법
https://huggingface.co/Qwen
https://huggingface.co/collections/Qwen/qwen3
위 링크에 접속하면 정말 다양한 모델들이 나온다.
그런데 각 모델들에 붙는 글자에 따라 뭔가 조금씩 다른 용도이다.
Qwen/Qwen3-235B-A22B-Instruct-2507-FP8 : InStruct 은 채팅용, 지시용
Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 : Thinking 은 리즈닝 모델
Qwen/Qwen3-235B-A22B-GGUF : GGUF 포맷으로 저장. 이거는 vllm 에서는 사용 못함!
참고로 Qwen/Qwen3-4B-AWQ 처럼이름에 양자화 정도가 안나오는 것도 있는데 그런건 태그를 통해 확인할 수 있다.

vLLM 에서 사용 권장 포맷
vllm 에서는 AWQ 를 사용하는 걸 권장
선택적으로 가중치에 따라서 양자화를 하고 안하고 한다.
그래서 조금 더 좋다. (정확히 이해는 못하겠다)
참고로 vLLM 은 무조건 GPU 가 있어야 동작한다.
그러니까 GFFU 포맷은 그냥 사용이 안된다.
위 그림을 보면 4-bit precision 이 있는 걸 봐서 4bit 양자화임을 알 수 있다.
VRAM 연산시 모델의 크기만 생각하지 마라
모델의 크기만 보고 VRAM 을 준비하면 안된다.
모델에 의한 연산, 그리고 동시 연산 등을 위한 메모리 공간도 반드시 생각해야 한다.
그러니까 모델의 크기에만 딱 맞춰서 VRAM 을 구성하면 안된다!
vLLM 추론 서버
vLLM은 UC Berkeley에서 개발한 고성능 LLM 추론 엔진이다.
핵심 특징
| 특징 | 설명 |
|---|---|
| PagedAttention | 메모리 효율적인 어텐션 구현 |
| Continuous Batching | 동적 배치로 처리량 최대화 |
| OpenAI 호환 | 기존 코드 변경 없이 전환 |
| Prefix Caching | 공통 프롬프트 캐싱 |
vLLM = 프로덕션 LLM 서빙의 표준이다! OpenAI API와 100% 호환된다.
참고로 vLLM 은 웬만하면 네이티브 하게 설치하는 것보다는
컨테인너 기반으로 설치하는걸 권장한다고 하셨다.
이게 설치가 꼬이면 많이 힘들어진다고 한다.
참고 문서
https://docs.vllm.ai/en/latest/
https://docs.vllm.ai/en/latest/features/tool_calling/?h=tool+calling
SGLang 과 vLLM 중 뭘 선택?
SGLang 은 안정적이고 성능도 vLLM 보다 좋지만,
최신의 모델에 대한 지원은 vLLM 이 훨씬 빠르다.
SGLang 은 이게 느리다.
그러니까 앞으로 안정적으로 하나의 모델로 계속 갈거면 SGLang,
그게 아니라 계속 최신 모델을 바꿔가면서 해보고 싶다면 vLLM 을 쓰라고 하신다.
