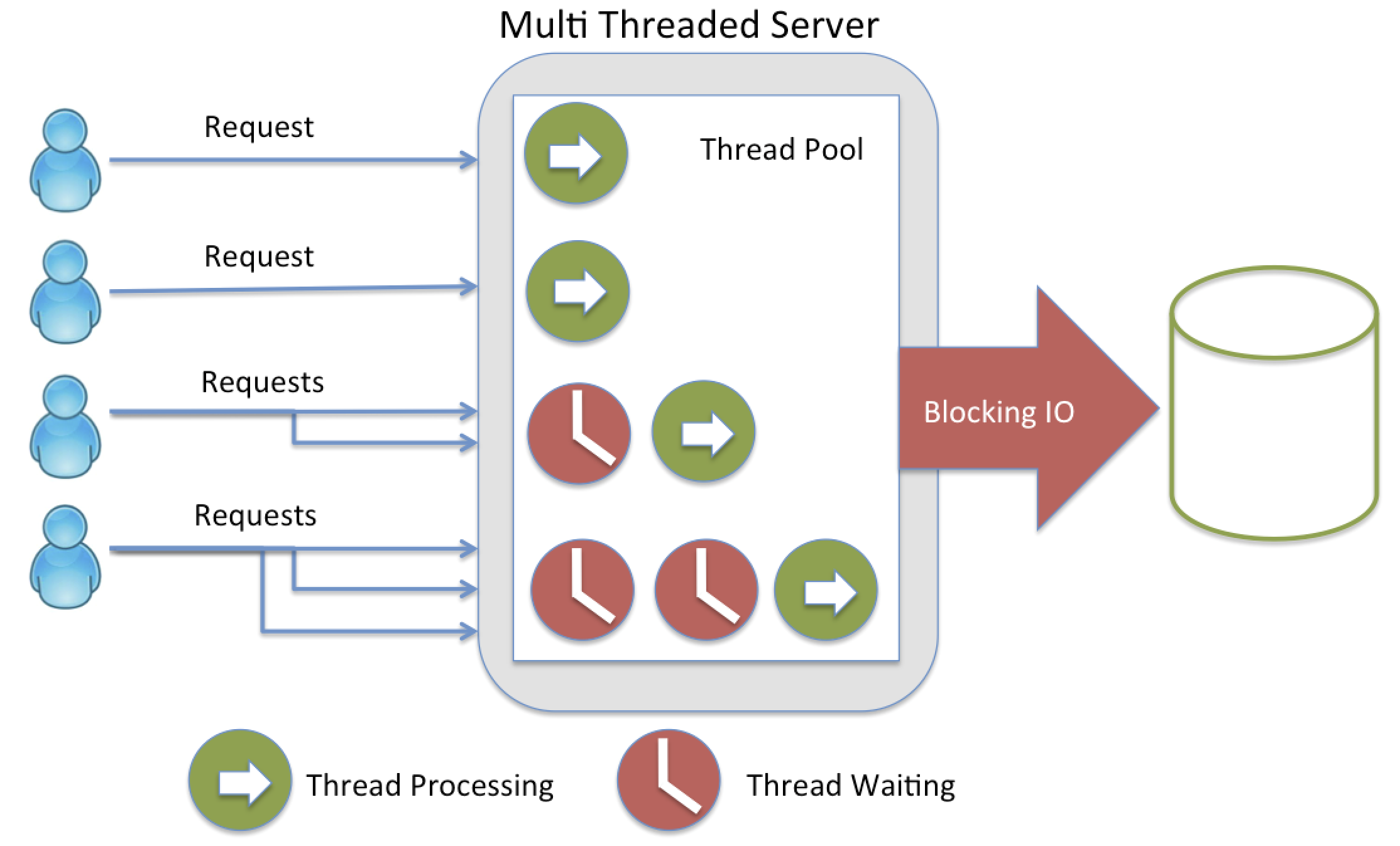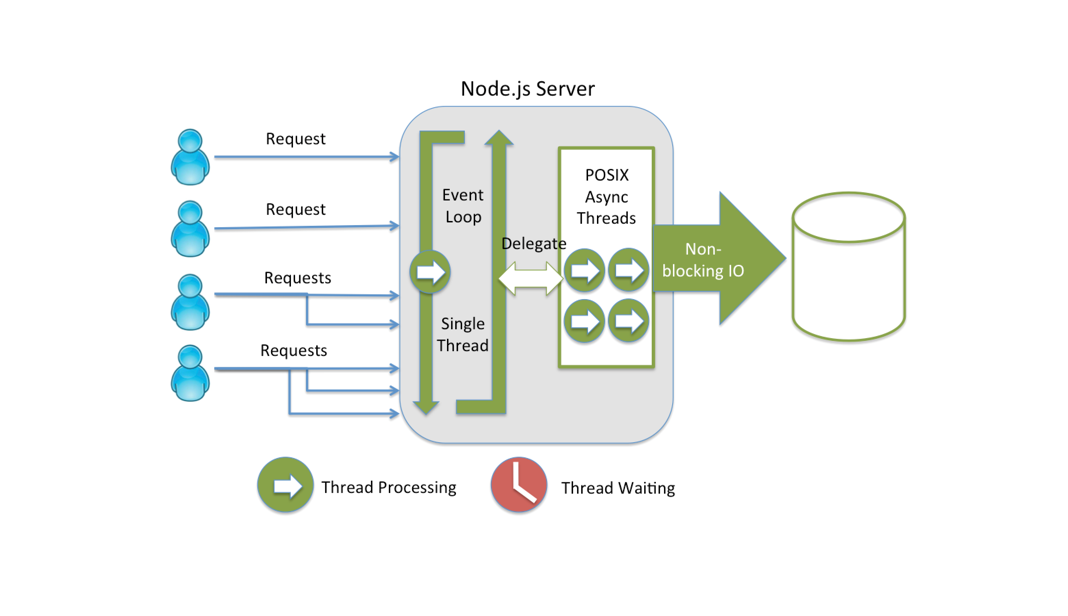
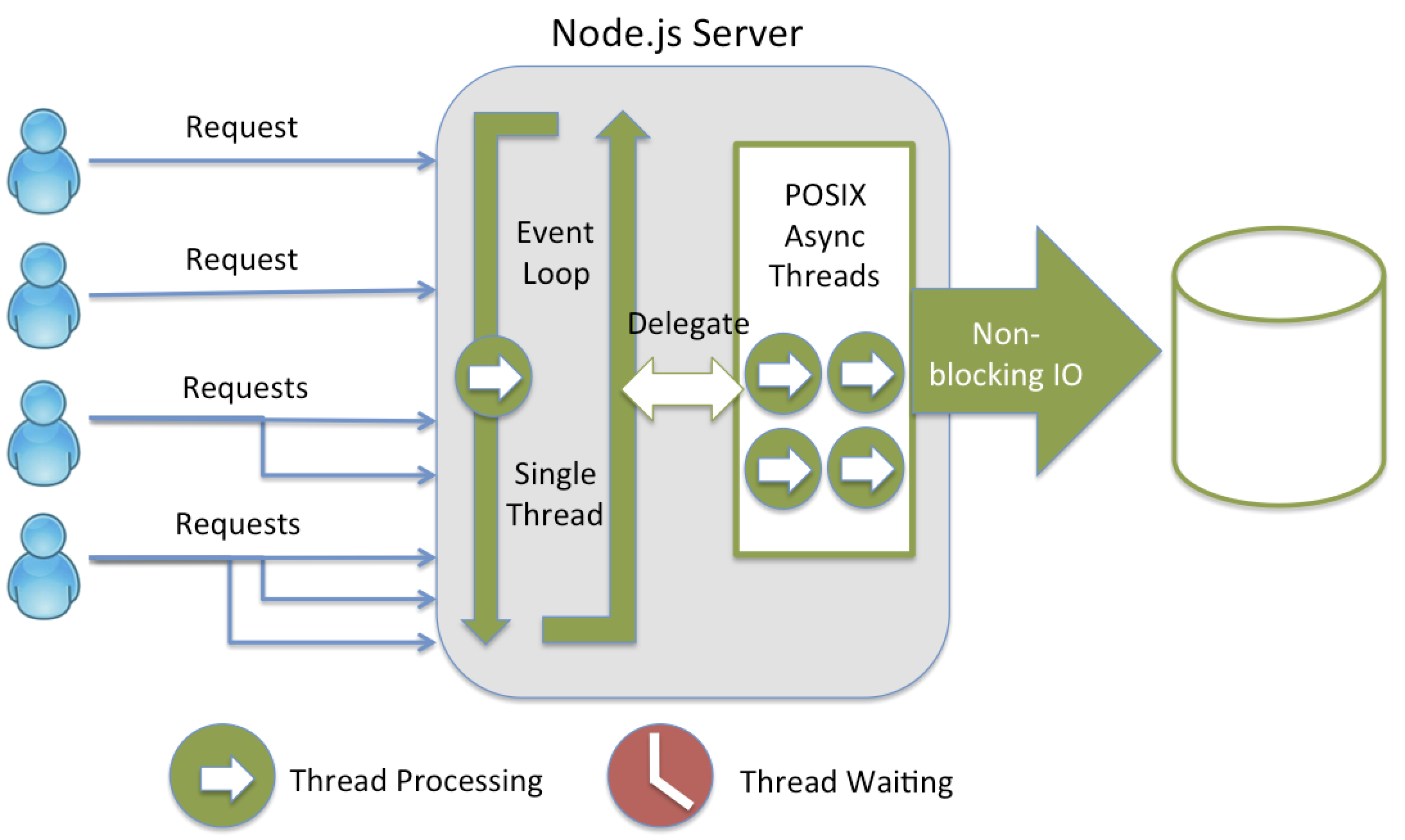
이미지 출처: https://strongloop.com/strongblog/node-js-is-faster-than-java/
동기 / 비동기 / 블로킹 / 논블로킹이 생소하면 아래 영상을 가볍게 한번 보자.
10분 테코톡 🎧 우의 Block vs Non-Block & Sync vs Async
이 글을 읽는데에는 사실 몰라도 된다.
왜냐하면 이 글은 비동기와 논블로킹을 명확하게 구분하면서 작성한 게 아니기 때문이다.
그저 코드 실행을 막는다/안 막는다에 기준을 두고 비동기와 논블로킹을 혼용해서 표현한다.
🤷♂️ 왜 필요한 걸까?
멀티쓰레드를 공부하고 나서 Netty 를 공부하는데,
교재에서는 Netty의 장점을 사용자 요청에 대한 비동기 + 논블로킹 처리라고 한다.
그런데 나는 요청에 대한 동기 + 블로킹 방식 처리를 하는 Spring WebMVC을 사용하면서
딱히 불편했던 적이 없었고 지금까지도 잘 사용하고 있다.
그래서인지 비동기 + 논블로킹이라는 것이 왜 좋은지 체감이 안되었다.
대체 뭐가 그렇게 좋아서 쓰는 걸까??
이 질문에 대한 답변이 이루어지기 전 까지는 Netty 공부가 의미가 없다는 생각이 들었다.
그래서 잠시 Netty 공부를 보류하기로 했다.
그리고 구글링을 시작했다.
처음에는 비동기, 논블로킹을 키워드로 구글을 검색했는데,
뭐랄까... 너무 난해했다. 번역을 해도 도통 뭔소린지 좀 처럼 이해하기가 힘들었다.
찾고 찾아봐도 머리만 아플 뿐 딱히 공감되고 이해되는 내용은 없었다.
그래서 키워드에 대한 고민을 좀 더 해봤다.
그런데 잘 생각해보니 이미 비동기 + 논블로킹 처리를 하는 유명한 프레임워크가 있었다.
바로 NodeJS 다.
아무래도 백엔드를 Java(Spring)만 사용하다 보니 바로 떠오르지 않은 키워드였다.
👏 NodeJS 관점으로 보는 필요성
키워드를 Nodejs 의 장점이 무엇인가 로 다시 검색해보니,
StackOverflow에서 적당한 글을 하나 찾아냈다.
해당 글의 링크는 아래와 같다.
Why node.js is fast when it's single threaded?
위 링크의 질문과 답변의 핵심적인 내용만 번역하면 아래와 같다.
질문
NodeJS 는 싱글 쓰레드인데 어째서 빠르다고 하는 건가요?
답변
일단 멀티쓰레드가 프로그램을 더 빠르게 한다는 생각이 나온 이유는
하나의 쓰레드가IO 연산처리를 하는 동안
다른 쓰레드가 또 다른 처리를 해준다는 것에서 기반된 거야.그렇다면 NodeJS 는 어떻게 멀티쓰레드가 아니면서 어떻게 빠른 처리가 가능할까?
사실 NodeJS의 모든 부분이 싱글 쓰레드인 건 아니야.
사용자가 작성한 JS 스크립트는 싱글 쓰레드가 맞지만,
IO 연산처리는 "멀티쓰레드"를 기반으로 동작하는libuv와운영체제에 의해 따로 처리 돼.
이와 관련된 더 자세한 설명은 여기에서 참고하길 바라.
이 답변이 모든 궁금증을 해소해주지는 않지만 아래와 같은 사실을 알게 해줬다.
- 일반적으로 멀티쓰레드를 써서 성능이 좋아지는지 것은
IO처리와다른 작업을 따로 작업하기 때문 Nodejs의 경우IO 연산을 위해서는멀티쓰레드 방식을 사용
이해가 덜되서 답변에서 제공하는 링크도 추가적으로 봤다.
위 링크의 내용 중에서 핵심만 뽑아 번역과 나의 생각을 조금 섞어서 아래에 작성해봤다.
💀 IO 연산은 굉장히 무겁다
대부분의 프로그래밍 기술의 가장 큰 낭비는 IO 연산의 결과를 기다리는 것이다.
💀 Thread-per-connection 은 메모리를 많이 차지한다
IO 연산 외에도 성능에 지대한 영향을 미치는 게 있는데, 바로 쓰레드다.
우리가 전통적으로 사용하는 서버에 오는 요청당 하나의 쓰레드를 연결하는 전통적인 방식을 쓰면 메모리가 쉽게 바닥난다.
참고로 쓰레드 풀을 써도 상황은 마찬가지다.
요청이 많아지면 결국 쓰레드 풀의 크기를 키우게 되기 때문이다.
그리고 애초에 쓰레드를 많이 쓰면Context Switch에 대한 부담이 커진다.
👏 NodeJS가 제시하는 해결법: 싱글쓰레드 + 비동기 + 이벤트 기반
그렇다면 위의 2가지 문제를 해소하기 위해서 Nodejs에서는 어떻게 할까?
그건 바로 싱글쓰레드로 사용자 요청을 받으면서 IO 연산에 대해서는 비동기적이면서도 이벤트를 기반 처리하는 것이다.
좀 더 풀어서 얘기하면...
싱글 쓰레드가 모든 사용자 요청을 받고, 요청과 관련된 IO 처리는 논블로킹으로 실행되어서
바로 빠져나온다. 그럼으로써 다음 요청을 바로 받을 수 있다.
이 과정에서 IO 처리를 위해서는 따로 쓰레드가 생성되고 처리 작업을 위임한다.
이후 처리가 완료되면 이벤트가 발생하고, 이 이벤트와 엮여있는 콜백을
"이벤트 루프"라는 별개의 쓰레드에 의해서 호출되게 된다.
결과적으로!
- IO에 대한 처리가 블로킹되지 않고 바로 넘어가기 때문에 IO 연산 기다림은 해결
- 싱글 쓰레드로만 요청을 받아서 요청당 쓰레드 연결을 하지 않음
여기서 비동기적/논블로킹 IO 처리, 그에 대한 이벤트 발생 그리고 이벤트를 처리하는 이벤트 루프는 Nodejs 가 사용하는 libuv 덕분이다. 자세한 내용은 링크만 걸어두고 생략하겠다.
👏 참고) NodeJS에서는 내가 작성한 코드 외에는 다 parallel(병렬적)이다.
NodeJS 에 대한 사용자가 작성한 코드는 싱글 쓰레드로 동작하지만,
IO 처리는 멀티쓰레드(병렬적)으로 동작한다.
하지만 이에 대한 결과 처리는 모두 Nodejs 내부에서 사용하는 이벤트 루프 덕분이다.
이벤트 루프는 사용자가 작성한 코드를 동작시키는 쓰레드와는 별개의 쓰레드에서 동작한다.
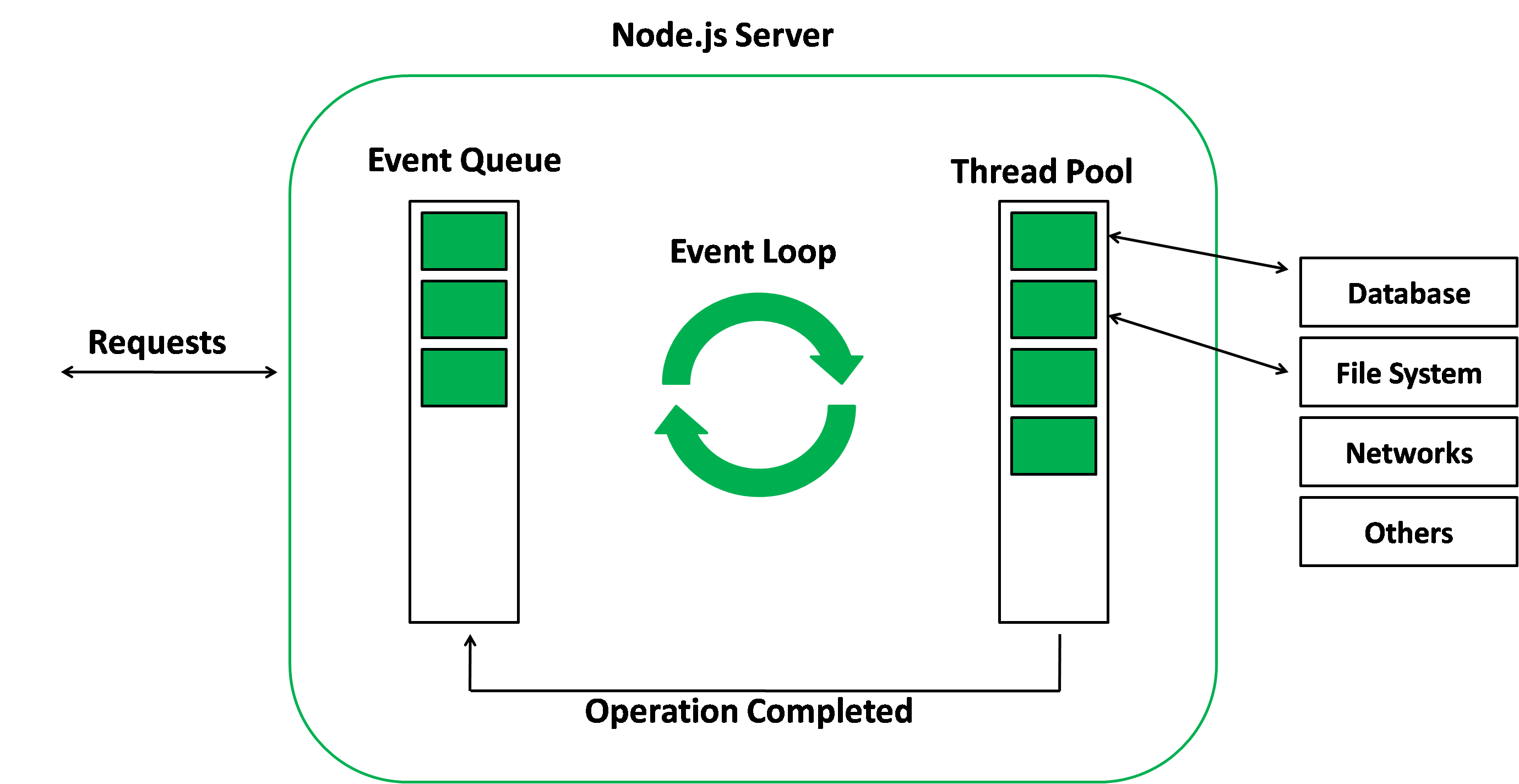
이벤트 루프는 멀티쓰레드로 동작하는 IO 처리 결과들에 대한 알림을 큐(Queue)에 쌓아놓고
큐에서 하나씩 알림을 빼내서 이에 대한 콜백을 하나하나 호출해준다.
👏 참고) Netty 에서도 나오는 "이벤트" 키워드
참고로 Netty도 이벤트 루프라는 개념을 사용한다.
그리고 Netty 또한 이벤트 기반의 아키텍처를 사용한다.
물론 Nodejs 와 Netty 내에서 이벤트를 처리하는 방식에 대한 세세한 구현은 다르겠지만
비동기 + 논블로킹를 위해서는 "event-driven"으로 동작하도록 해야 된다는 것을 알았다.
🙌 그래서 나의 답변은!
장황했지만 결국 비동기 + 논블로킹의 핵심은 서버에서 일어날 수 있는 성능 이슈
2가지를 해소하기 위함이다.
IO 처리에 대한 waiting요청당 쓰레드 생성
그러니 앞으로 "비동기/논블로킹의 필요성은 뭔가요?"라고 질문하면...
"성능 이슈를 일으키는 요청당 쓰레드 생성 및 IO 처리에 대한 waiting을 최소화하여
서버가 보다 나은 성능을 뽑아내기 위해서이다."라고 대답할 것이다.
사실 이건 어디까지나 내가 낸 결론이다.
만약 좀 더 나은 답변이 있다면 댓글 부탁드린다.
✨ 참고
✔ 링크
✔ 이미지