
이미지출처
syntax 약속
본 포스팅은 KT 에이블스쿨 교육내용을 제 나름대로 정리하여 작성하였습니다
머신러닝?
ML(머신러닝)은 사용하는 데이터를 기반으로 학습 또는 성능 향상을 지원하는 시스템을 구축하는 데 초점을 맞추는 인공 지능(AI)의 하위 집합입니다. 출처
 대충 이런관계이다.
대충 이런관계이다.
머신러닝 학습 종류
머신러닝은 학습 방법에 따라
-
지도학습(Supervised Learning)
학습 대상이 되는 데이터에 정답을 주어 규칙성을 배우게 하는 방법 -
비지도학습(Unsupervised Learning)
정답이 없는 데이터 만으로 배우게 하는 방법 -
강화학습(Reinforcement Learning)
선택한 결과에 보상을 받아 행동을 개선하며 배우게 하는 학습방법
으로 나뉜다.
또한 학습 과제에 따라
- 분류(Classification)
- 회귀(Regression)
- 군집화(Clulstering)
로 나뉜다.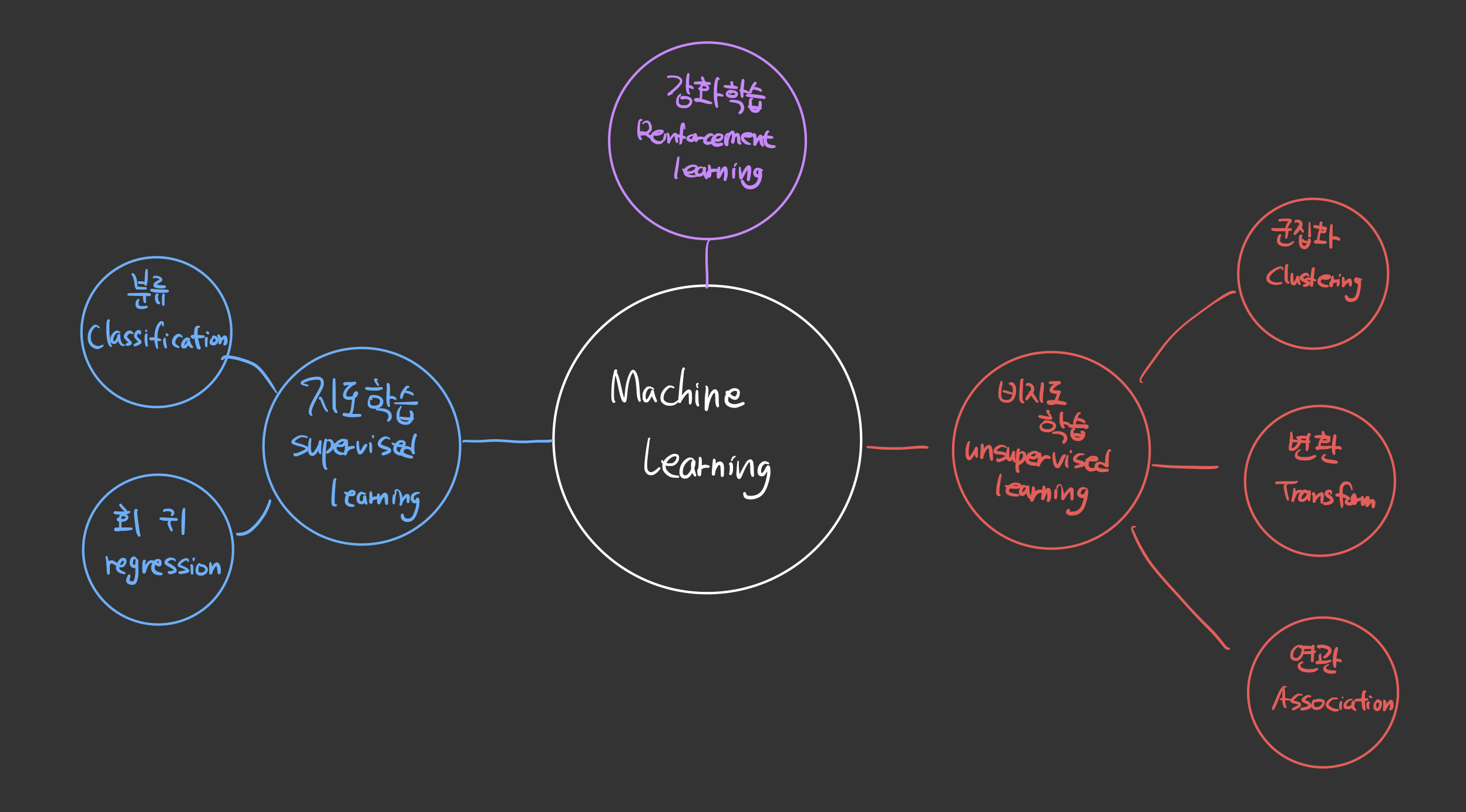 자세한건 그림을 참고하자.
자세한건 그림을 참고하자.
일단은 '사이킷런(sklearn)을 사용하여 분류와 회귀에 대해서만 다룰 예정이다.
1. 미리 알아 둘 용어
- 분류와 회귀
- 모델, 모델링
- 행, 열
- 독립변수, 종속변수
- 오차와 평균
- 데이터 분리
- 과대적합 & 과소적합
1. 0. 분류와 회귀
주어진 문제가 분류인지 회귀를 구분하는 것은 매우 중요하다. 사용하는 알고리즘과 평가 방법이 달라지기 때문다.
매우 간단하게 요약하자면
-
분류 : 그룹 예측
-
회귀 : 값 예측
판단기준은 값의 연속성 여부 이다.
1. 1. 모델, 모델링
-
모델 : 데이터로 부터 pattern 을 찾아 수식으로 정리해 놓은 것
-
모델링 : (오차가 적은) 모델을 만드는 것 혹은
머신이 적절한 학습을 통해 최선의 모델을 만들 수 있도록 노력하는 행위
- 모델링의 목적 : sample을 가지고 전체를 추정하기 위함
- sample = 표본, 부분집합, 일부, 과거의 데이터
- 전체 = 모집단, 전체집합, 현재 혹은 미래의 데이터
1. 2. 행, 열
다른 명칭들을 숙지해야 한다.
-
행(Row)
- 개체(Instance)
- 관측치(Observed Value)
- 기록(Record)
- 사례(Example)
- 경우(Case)
-
열(Column)
- 특성(Feature)
- 속성(Attribute)
- 변수(Variable)
- 필드(Field)
1. 3. 독립변수, 종속변수
y = ax + b 에서
x : 독립변수
y : 종속변수
이다.
x 의 값의 변화에 따라 y의 값이 변화하므로 y는 x에 종속되어있다고 할 수 있다.
1. 4. 오차와 평균
- 평균(mean) - 통계학에서 사용되는 가장 단순한 모델
- 오차(error) - 관측치와 모델의 차이(이탈도, Deviance 라고도 부른다.)
1. 5. 데이터 분리
머신러닝을 하기 위해서는 데이터셋의 분리가 필요하다.
- 학습용(training)
- 검증용(validation)
- 평가용(testing) -> 미래의 data, 찐 막 최종 평가
좀 검증용과 평가용 데이터가 햇갈릴 수도 있는데, 모의고사와 수능의 차이라고 생각하면 이해가 조금 편할 것 같다.
- target(y)
- feature(x)
실전에서는 평가용 데이터는 현실 상황에선 별도로 제공되는 경우가 많다. 하지만 학습에서는 가지고 있는 데이터에서 따로 떼서 사용한다.
각각 6:2:2 비율 혹은 검정을 제외한 7:3 비율로 나누는 것이 일반적이나,
아주 많은 양의 데이터(백만개단위)를 다루는 빅데이터의 경우에는 98:1:1 로하는 경우도 있다고 한다.
출처
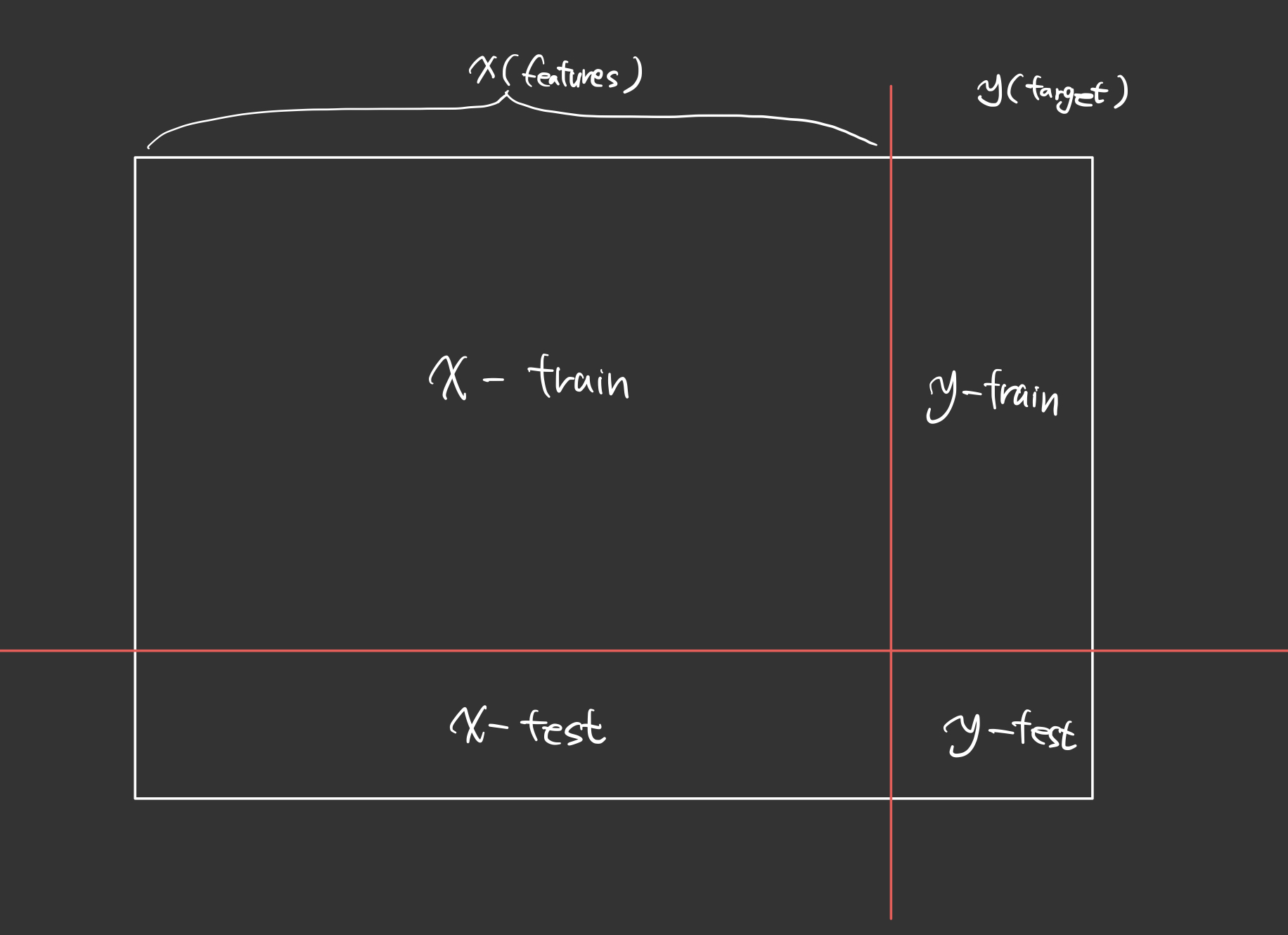 일반적인 지도학습 머신러닝 교육에서 분리되는 데이터 모양
일반적인 지도학습 머신러닝 교육에서 분리되는 데이터 모양
1. 6. 과대적합과 과소적합
머신러닝을 관통하는 키워드에는 '과유불급' 이라고 생각한다. 모델 학습이 너무 과하면 과대적합이, 너무 적으면 과소적합이 일어나는 등...
항상 적절한 point를 찾는게 중요하다고 할 수 있다.
-
과대적합(Overfitting)
학습 데이터에 대해서 점수가 높지만, 실제 데이터를 가지고 하는 예측(평가 데이터)에는 점수가 매우 낮은 경우 -
과소적합(Underfitting)
학습 데이터가 평가데이터보다 점수가 낮은 경우, 혹은 둘 다 매우 낮은 경우, 모델이 너무 단순하여 적절하게 훈련이 안 된 경우
2. 모델링 과정
- 불러오기
- 데이터 이해 및 준비
- 모델 성능 예측 및 선정
- 모델 튜닝 및 학습
- 예측 및 평가
2. 1. 라이브러리 불러오기
머신러닝에 필요한 기본 라이브러리와 데이터들을 불러온다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings(action='ignore')
%config InlineBackend.figure_format = 'retina'데이터프레임에 관련된 라이브러리인 numpy, pandas
시각화를 담당하는 라이브러리인 seaborn, matplotlib
그리고 각종 다양한 라이브러리도 많지만 생략한다.
2. 2. 데이터 이해 및 준비
2. 2. 1. 데이터 이해
불러온 데이터를 탐색하여 충분히 이해할 수 있도록 한다. 데이터 탐색과정은 링크로 대체한다.
추가적으로 seaborn의 corr() 메소드를 이용하여 변수 관 상관관계를 분석할 수 있다.
이 단계에서 제일 중요한 과정은 Target(y) 값을 찾는 것이다.
2. 2. 2. 데이터 준비
머신러닝에 사용할 수 있도록 데이터들을 전처리해주는 과정이다.
- 불필요한 변수 제거
머신러닝에 사용할 필요가 없는 항목들, 주민번호나 사번 등 개인을 식별할 용도로 쓰이는 변수들은drop메소드를 이용하여 삭제해준다.
data.drop('colname', axis=1, inplace=True)-
필요한 변수 추가
데이터 이해과정중 추가가 필요하겠다고 생각한 변수들을 추가해준다. -
타겟 설정과 데이터 분리
타겟을 설정한 뒤 기존 데이터프레임에서 분리해 y에 할당하고, y를 제외한 데이터들도 x에 할당해준다.
target = 'colname'
y = data[target]
x = data.drop(target, axis=1)-
결측치 처리
자세한 내용은 링크를 참고하자.
추가로 Knn imputer같은 다양한 결측치 처리 방법도 있는데, 후에 수정하여 추가하겠다. -
가변수화
분류를 위한 머신러닝 알고리즘에는 '가변수화'라는게 필요하다.
일반적으로 자료형이 object인 변수들(예를들어 성별, 만족도 조사 결과 등) 들이 대상이 된다. 코드에 대한 자세한 이해도 역시 링크를 참고하자 ㅋㅋㅋ
dumn_cols = ['col1', 'col2', 'col3', 'col4']
x = pd.get_dummies(x, columns=dumn_cols, drop_first=True)- 데이터 분리
학습용 데이터와 평가용(예측용) 데이터를 분리해야 한다.
sklearn의train_test_split모듈을 이용해서 분리한다.
학습에서는 같은 결과값을 봐야하므로random_state를 같은 값으로 지정한다.
위쪽의 데이터 분리의 그림을 토대로 분리한 것이며, 7:3 비율로 분리한 것이다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)-
정규화(scaling)
모델의 성능을 높이기 위해(특히 KNN) 스케일링이 필요한 경우가 있다.
대표적으로 2가지가 있다.- Normalization(min-max scaling)
- Standardization
- Normalization(min-max scaling)
위 공식을 직접 사용하거나, sklearn 이 기본적으로 제공하는 함수를 사용해도 된다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train_s = scaler.transform(x_train)
x_test_s = scaler.transform(x_test)2. 3. 모델 성능 예측 및 선정
모델의 종류
주어진 데이터셋에 어떤 모델을 사용할지 결정하는 것이다. 모델 성능 예측은 해당 모델로 학습한 후 테스트를 진행했을 때 예상되는 성능을 추정하는 과정이다. 이는 검증 과정과 유사하다.(같은건가?)
예측 및 평가가 '수능'이라면 본 과정은 '모의고사' 인 셈이다.
일반적인 모델 성능평가 지표를 사용하거나, K-분할 교차 검증(K-Fold Cross Validation)을 사용한다.
2. 3. 1. 모델 종류
따로 포스팅 예정
2. 3. 2. 선정을 위한 모델 성능 예측
K-분할 교차 검증(K-Fold Cross Validation)
모든 데이터를 K 개로 분할하여 1번 평가 K-1 번 학습 후, 분할에 대한 모든 성능 추정치를 평균 혹신 표준편차로 나타낸 수치를 최종 정확도로써 사용한다.
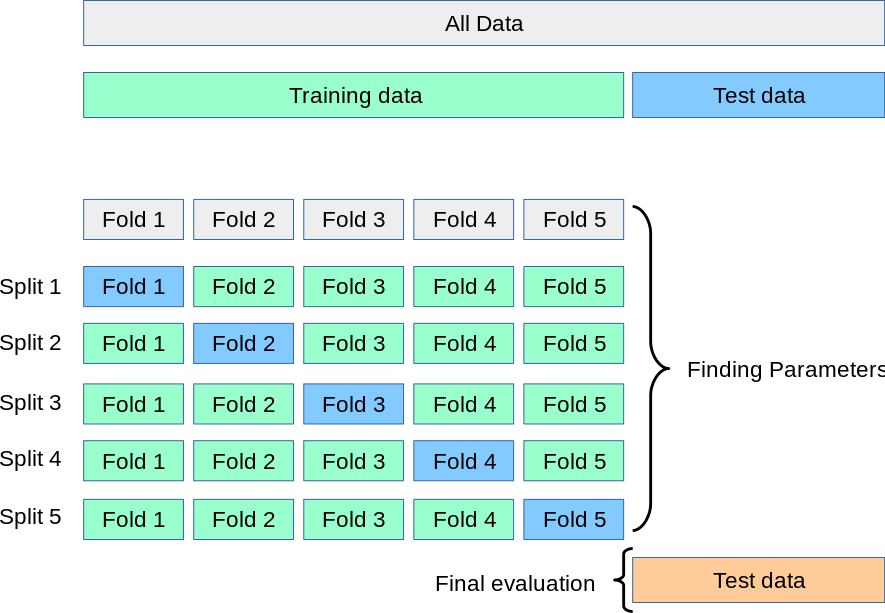 출처 - scikit-learn 라이브러리의 공식 문서
출처 - scikit-learn 라이브러리의 공식 문서
다크모드에서는 잘 안보인다...(이런젠장)
다음과 같은 장점들이 있다.
- 정확도상승
- 평가데이터 편향 방지
- 일반화된 모델
- 데이터 부족으로 인한 과소적합 방지
sklearn 에서는 cross_val_score 모듈을 임포트 하여 간단하게 사용할 수 있다.
# 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 검증용 모델 선언하기
model = DecisionTreeClassifier(max_depth=5, random_state=1)
# 검증하기
cv_score = (model, x_train, y_train, cv=10)
cross_val_score
# 확인
print(cv_score)
print('평균:', cv_score.mean())
print('표준편차:', cv_score.std())2. 4. 모델 튜닝 및 학습
2. 4. 1 하이퍼파라미터 튜닝
모델의 하이퍼파라미터(hyperparameter)를 조절하여 모델을 튜닝할 수 있다.
하이퍼파라미터(hyperparameter)란?
훈련 과정에서 학습되지 않지만 훈련이 시작되기 전에 설정되는 매개변수
간단하게 말하면, 모델링 시에 사용자가 조절할 수 있는 옵션이라고 보면 되겠다.
하이퍼파라미터는 모델의 성능에 큰 영향을 미치므로 적절한 값의 설정은 매우 중요하다.
물론 다음의 이유로 최적의 파라미터를 얻었을 지라도 운영환경에서 성능이 보장되지 않을 수도 있다.
-
과적합
-
미래의 데이터가 과거와는 다른 경향값을 가짐
과거의 데이터를 가지고 미래를 평가하는 머신러닝 모델의 특성상 미래의 모델이 과거의 경향성을 따라가지 않는다면 맞지 않을 수 있다. -
확률론적 관점
어디까지나 최적의 파라미터는 최고의 성능을 가질 수 있는 '확률'이 제일 높은 값이기 때문에 한~두번의 평가에서는 다른 파라미터가 우세한 경우도 있다.
하이퍼파라미터를 튜닝하는데는 두가지 방법이 있다.
- Grid Search -> 전수조사
- Random Search -> 일부만 조사
'딱 봐도 그리드서치는 잘뽑는데 오래걸리고, 랜덤은 반대겠지? ㅎㅎ~' 라 생각한 당신
정답이다 ㅋㅋ
# 기본 모델 선언
model_xgb = XGBClassifier(random_state=1)
# 파라미터 지정, 여러개 지정도 가능하다.
param = {'max_depth': range(1, 21)}
model = GridSearchCV(model_xgb,
param,
cv=5,
scoring='accuracy') Random Search는 위의 코드 괄호 안에 n_iter 라는 변수를 추가하면 된다.
임의로 선택할 파라미터의 조합 수를 나타낸다.
cv는 검증용으로 사용하는 K-Fold Cross Validation 의 K 값이다.
위의 코드는 max_depth 를 1~20 까지, 그리고 각각 5번의 검증을 거치므로 총 100번의 시행횟수를 가지게 될 것이다.
# 학습하기
model.fit(x_train, y_train)
print(model.best_params_)
print(model.best_score_)튜닝을 거치고 바로 모델을 fitting 하게되면 알아서 최적의 값을으로 학습을 하게된다.
beat_params_ 와 bset_score_ 를 통해 최적의 파라미터와 test 데이터를 넣었을 시 예측되는 점수를 표시해준다.
plt.figure(figsize=(6, 5))
plt.barh(list(x), model.best_estimator_.feature_importances_)
plt.show()best_estimator_ 최고 추정치의 feature_importances_ 변수 중요도도 Plot 할 수 있다.
2. 4. 2 Feature selection
Decision Tree, Random Forest를 기반으로 하는 모델들에 사용되며 Feature 가 많은 데이터에 유용하다.
모델 fitting(학습) 후 모델명.feature_importances_ 를 작성하면 중요도를 반환해준다.
보통은 feature 이름과 결합하여 DataFrame을 만들어 사용하며. 이를 통해 중요한 feature를 쉽게 확인할 수 있다.
다음은 for 문을 이용하여 모델링에 필요한 최적의 feature 갯수를 구하는 코드의 예시이다.
미리 GridSearch를 통해 최적의 파라미터를 구한 상태에서 시작한다.
acc = pd.DataFrame(columns=['accuracy_score'])
for i in range(130):
importance_n = importance_sort['feature_name'][:i+1]
x_train_n = x_train[importance_n]
x_val_n = x_val[importance_n]
xgb_n_model = XGBClassifier(learning_rate=0.3, max_depth=3, random_state=2023)
xgb_n_model.fit(x_train_n, y_map_train)
xgb_n_pred = xgb_n_model.predict(x_val_n)
acc.loc[i] = accuracy_score(y_map_val,xgb_n_pred)
print(acc.loc[i])
acc2. 5. 예측 및 평가
문제가 분류인지 회귀인지에 따라 평가방식이 다르다.
값에는 3가지가 있다.
-
실제값
목표로 하는 값, 성능평가는 이 값과의 비교로 한다. -
예측값
머신러닝 알고리즘으로 '새롭게' 예측한 값 -
평균값
'기존에' 예측한 값
2. 5. 0. 평가 관련 모듈 불러오기
평가 관련 모듈 불러오기
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error, mean_absolute_percentage_error
# 보통은 이렇게 씀
from sklearn.metrics import *2. 5. 1. 회귀모델의 평가
-
오차
회귀 모델의 평가는 예측값과 실제값의 차이인 오차(Error)를 확인한다.
상식적으로 예측값과 실제값의 차이가 작을 수록 좋은 모델이므로, 오차는 낮을수록 좋다.
실제값과 예측값의 오차는 샘플마다 다르므로, 이를 한번에 말하는 수치들이 필요하다.MSE(Mean Squared Error) - 평균 제곱 오차
RMSE(Root Mean Squared Error) - 평균 제곱근 오차
MAE(Mean Absolute Error) - 평균 절대 오차
MAPE(Mean Absolute Percentage Error) - 평균 절대 백분율 오차
일반적으로 MAE를 많이 사용한다.
-
오차 제곱합
SST(Sum Squared Total) : 전체 오차SSR(Sum Squared Regression) : 전체 오차 중 회귀식이 잡은 오차
SSE(Sum Squared Error) : 전체 오차 중 회귀식이 못잡은 오차
정의대로라면 당연히 밑의 공식도 성립한다.
-
결정계수(R²)
MSE를 표준화 한 수치, 전체 오차 중 회귀식이 잡아낸 오차의 '비율'을 의미한다.
오차의 비, 설명력이라고도 부른다.
비율이므로 0~1 사이에 값이 표기되며, 높을수록 모델이 데이터를 잘 학습함을 의미한다.
사이킷런에서는 다양한 메소드를 이용해서 평가값을 구할 수 있다.
RMSE는 MSE에서 squared 옵션을 이용하여 구할 수 있다
print(f'RMSE : {mean_squared_error(y_val, pred, squared=False)}')
print(f'MAE : {mean_squared_error(y_val, pred)}')2. 5. 2. 분류모델의 평가
분류모델은 정확히 맞춘 비율을 평가한다.
confusion matrix(혼동행렬, 오분류표)
실제값과 예측된 값의 관계를 나타낸 표이다.
예측값과 실제값이 일치한 경우 True 이며, 예측여부에 따라 N과 P로 나뉜다.
| Actual/Predicted | Negative | Positive |
|---|---|---|
| Negative | True Negative (TN) | False Positive (FP) |
| Positive | False Negative (FN) | True Positive (TP) |
평가 지표
- 정확도(Accuracy)모든 예측 중 정확히 예측(True) 한 비율
가장 직관적으로 모델 성능을 확인할 수 있는 평가 지표 - 정밀도(Precision) : 1이라 예측한 것 중 1인 비율
- 재현율(Recall, 민감도) : 실제 1인 것을 1이라 예측한 비율
- 특이도(Specify) : 실제 0인 것을 0이라 예측한 비율
- 정밀도와 재현율의 조화평균
정밀도와 재현율
- 매우 햇갈리므로 정확하게 아는것이 중요하다.
- 정밀도 : 예측 관점, 'P'를 통해 연상하면 편하다.
- 재현율 : 실제 관점, 실제가 positive 인 것이 분모이다.
- 비슷해 보이는데 왜 쓸까?
- 실제 1인 것을 맞출 확률이 중요한 분야에서 사용한다.(감염병 판별, 산업분야 등)
혼동행렬과 분류결과 예시
Classification Report 의 recall 값과 f1-score 값을 주로 본다.
print('accuracy_score: ',accuracy_score(y_test,xgb_top_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_test,xgb_top_pred))
print('\n classification_report: \n',classification_report(y_test,xgb_top_pred))Confusion Matrix:
[[10 0 0]
[ 0 9 1]
[ 0 1 9]]
Classification Report:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 0.90 0.90 0.90 10
virginica 0.90 0.90 0.90 10
accuracy 0.93 30
macro avg 0.93 0.93 0.93 30
weighted avg 0.93 0.93 0.93 303. 토이데이터
4. 학습곡선
5. 규제
6. 분산팽창지수
참고 : 관련 함수 불러오기
# 분리하기
from sklearn.model_selection import train_test_split
# 회귀문제
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.metrics import r2_score
# 분류문제
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTree Classifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# 성능튜닝
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import GridSearchCV