ChatGPT 이후 급속도록 LLM의 발전이 이루어지고 있지만 업계에 이 기술이 안전하게 효과적으로 안착하지 못하는 모습을 목격하고 있다. 다음의 몇 가지 이유가 있는 것으로 요약할 수 있다.
- 상용 환경에서는, LLM 특유의 활루시네이션의 통제를 위해 RAG 를 함께 사용해야하는 등 기술적인 복잡다고 올라가기 시작
- 정확한 기능을 위해서는 비싼 상용 Cloud LLM API를 사용해야하고 이를 실제 서비스에서 감당하기에는 비용이 실질적으로 비싼 편
- On-prem에서 사용해 보자니 학습용 장비로 A100, H100등 대형 장비가 필요하고 상용서비스를 위해서도 여전히 GPU 장비가 필요하기 때문에 이런 장비구매에는 큰 투자가 필요.
그럼에도 불구하고 여전히 빠르게 고객 응대용 상담봇이나, 코딩용 모델 등 실질적으로 당장 LLM을 적용해서 빠르게 업무 효율을 높여야할 분야들은 여전히 저비용 고효율 방법론을 찾아서 관련된 서비스를 제공하기 위한 경쟁력을 높여야할 필요성이 증가하고 있다.
당장 고객응대용 상담 봇을 개발하는 과정을 단순화하고 다양한 시나리오에 대해 효과적으로 대응하기위해 LLM을 고려해볼 필요가 있어 여러가지 모델들을 시험해보려 한다.
그 첫번째로 과거부터 참조로 사용해보던 skt/kogpt2-base-v2로 학습하는 과정과 결과를 다음과 같이 정리해본다.
1. 학습 데이터 준비
엑셀의 시트에 대화 내용을 담았기 때문에 질의/응답 순으로 정리되어 있다.
이를 각 한 개의 train.csv 및 val.csv로 통합하여 준비
2. 학습 절차 작성
from transformers import GPT2LMHeadModel, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# 1. 모델과 토크나이저 로드 (AutoTokenizer 사용)
model_name = "skt/kogpt2-base-v2"
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# pad_token이 없으므로 eos_token을 pad_token으로 지정
tokenizer.pad_token = tokenizer.eos_token
# 모델 config에도 pad_token_id를 지정하고 임베딩 크기를 재조정
model.config.pad_token_id = tokenizer.pad_token_id
model.resize_token_embeddings(len(tokenizer))
# 2. 데이터셋 로드 (저장 경로에 맞게 수정)
data_files = {"train": "data-train/train.csv", "validation": "data-train/val.csv"}
raw_datasets = load_dataset("csv", data_files=data_files)
# 3. 데이터 전처리 함수 정의: 고객 발화와 상담사 응답을 하나의 시퀀스로 연결하고,
# tokenization 후, 입력 토큰들을 레이블로 사용하여 손실 계산이 가능하도록 함.
def preprocess_function(examples):
texts = [
((inp if inp is not None else "") + tokenizer.eos_token + (out if out is not None else ""))
for inp, out in zip(examples["input"], examples["output"])
]
tokenized = tokenizer(texts, truncation=True, padding="max_length", max_length=128)
# 모델에 입력된 토큰 그대로를 라벨로 사용 (언어모델링 objective)
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
# 전처리 적용 (batched 처리)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
# 4. TrainingArguments 설정
training_args = TrainingArguments(
output_dir="./kogpt2_finetuned",
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=3,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=100,
learning_rate=5e-5,
)
# 5. Trainer 생성
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"]
)
# 6. 학습 진행
trainer.train()
# 7. 학습 완료 후 모델 저장
model.save_pretrained("./kogpt2_finetuned")
tokenizer.save_pretrained("./kogpt2_finetuned")3. 학습 모니터링
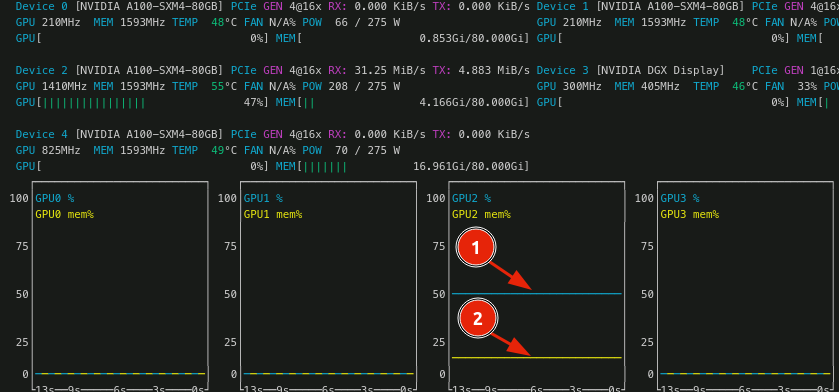
학습중 GPU의 상황은 이 정도. A100 하나에서 실행중이며 메모리는 16Gb인 20% 정도 차지하고 compute는 50%가량 차지하는 형태로 에폭이 반복된다.
4. 학습 결과
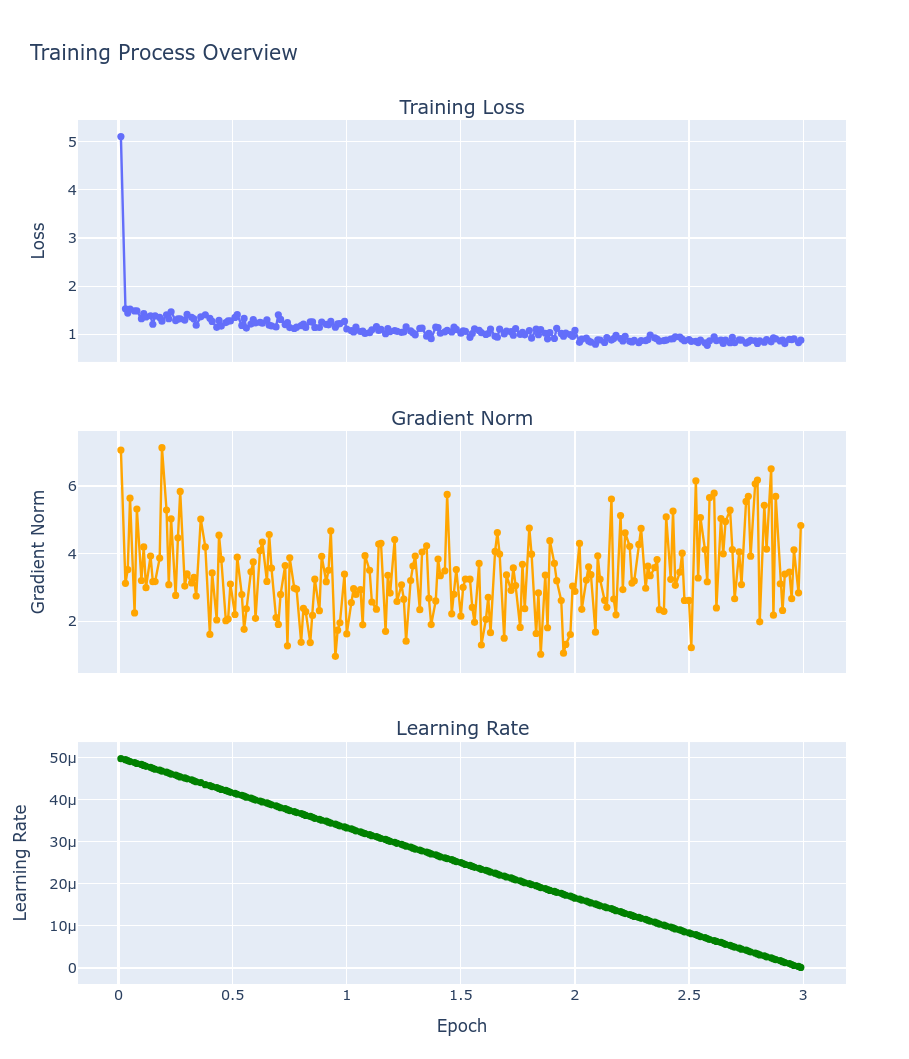
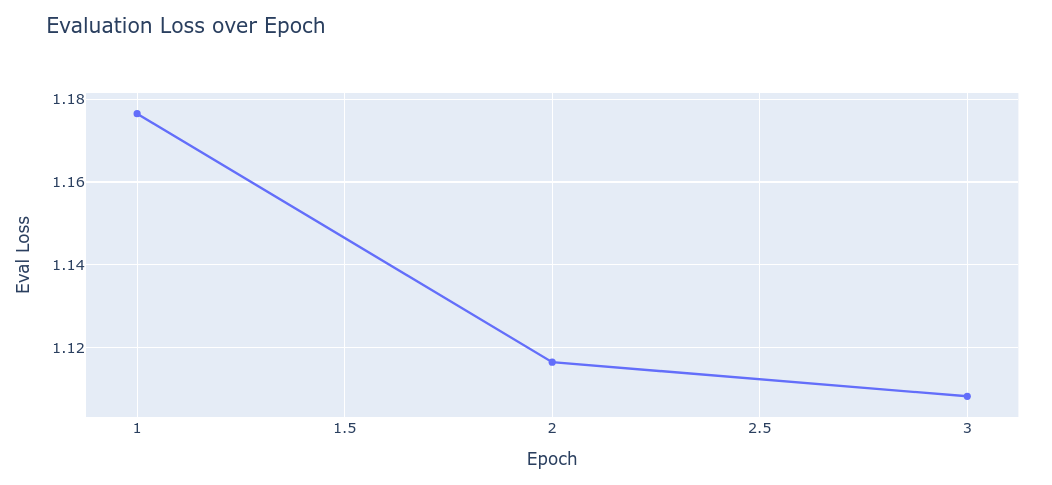
최종 Training Loss: 1.0875
총 학습 시간: 1285.14초
학습 초반에는 손실이 급격히 감소했으며, 이후 약 1.1 근처에서 안정적인 추세를 보이고 있습니다. 평가 손실(eval_loss)도 비슷한 값을 유지하고 있어 과적합의 징후 없이 훈련과 평가가 모두 일관되게 진행된 것으로 보임
주요 관찰 사항:
손실 감소: 초기 손실(약 5.1)에서 빠르게 1.3 이하로 낮아진 후, 전반적으로 1.1 근처에서 안정화됨.
훈련 vs 평가: 마지막 평가 손실과 훈련 손실이 유사하여 모델이 훈련 데이터에만 치우치지 않는 것으로 추정됨.
그라디언트 노름: 훈련 중 그라디언트 노름이 큰 변동 없이 비교적 안정된 범위 내에 있음.
학습률 감소: 학습률이 점진적으로 낮아지며 안정적인 수렴을 돕는 것으로 판단됨.
결론:
전반적으로 학습이 안정적으로 진행되었으며, 모델이 적절한 수렴 과정을 거친 것으로 보임. 다만, 정확한 성능 평가는 목표 손실 값이나 평가 지표에 따라 추가 확인이 필요할 수 있음
요약
Pros: 안정적인 수렴, 훈련과 평가 손실의 일관성, 과적합 우려 없음
Cons: (추가 개선 여지가 있다면) 손실이 plateau에 머무르는 점은 추가 튜닝을 고려할 수 있음
학습이 잘 이루어졌다고 평가할 수 있지만, 최종 성능 목표와 실제 응용 분야의 요구사항에 따라 추가 검증이나 튜닝도 고려해볼 수 있음.
5. 결과 확인

얼추 유사하게 답이 나오는 것 같지만 사람의 눈으로 보기에도 뭐가 문제인지 알 정도로 심각하며, 특히 학습데이터에 묻어 있던 전화번호의 비식별화 필요성을 단번에 알 수 있음. 학습 데이터의 품질이 좋지 않을 것이라는 것은 확실한데, 다른 모델은 어떤 결과를 보일 지 궁금하여 모델을 교체하여 추가 학습하는 실험을 하기로 결정.
