
이번 글에서는 DB 인덱스는 어떤 자료구조로 구현되어있는지 알아보도록 하자.
1. DB 인덱스 구현을 위해서는 어떤 자료구조를 사용할 수 있나요? 여러 가능성을 제시하고 각각의 장단점을 설명해주세요.
-
구현 자료구조
-
Binary Search Tree : 이진 탐색 트리!
-
B Tree : 한 노드에 한개 이상의 값을 가지게 하기 (한번의 스캔으로 탐색할 수 있는 범위 증가)
-
B+Tree : 리프노드에만 값을 가지게 하고 나머지 노드들에는 가이드라인만 가지게 하기 + 리프노드 간의 탐색 추가 (범위 검색에 매우 유리)
-
1.1 Hash Index (Hash Table)
- hash table을 사용하여 index를 구현
- 조회, 삽입, 삭제에 대한 시간복잡도가 O(1)로 매우 성능이 좋다
- 단점
- rehashing에 대한 부담 (크기가 가득차서 동적으로 늘려줄 때의 부담)
- 범위 비교가 불가능하다 (equality 비교만 가능)
- multicolumn index의 경우 전체 attributes에 대한 조회만 가능
- (A, B) 인덱스인 경우 A만으로 검색할 때 hash Index는 안됨
1.2 이진 탐색 트리
- 이진 탐색의 장점과 연결 리스트의 장점을 결합
- 균형 문제 발생시 O(N)으로 수렴
1.3 B-Tree
- 자식 노드가 2개 이상인 트리
- 이진탐색트리처럼 왼쪽이 작은 값, 오른쪽이 큰 값이지만, balance가 맞춰져있음
- 최악의 경우에도 O(logN)
- 중위순회를 하여 모든 데이터 순회시 트리의 모든 노드를 방문해야 하는 문제가 있음
1.4 B+Tree ⇒ Inno DB Index의 구현방법
- 특징
- leaf node에만 데이터를 저장하고 나머지 노드는 자식 포인터만 저장하도록 한다
- 그리고 leaf node까리 linkedList로 연결되어있다 (InnoDB는 doublely linked list)
- 장점
- leaf node에만 데이터를 저장함으로 메모리 확보
- 하나의 node에 더 많은 포인터를 가질 수 있어 트리의 높이가 낮아져 검색속도 증가
- full scan의 경우 linkedLsit를 사용하여 선형 시간 소모
- 단점
- b-tree는 최악의 경우가 O(logN)인데에 비해 B+Tree는 항상 O(logN) 시간
- 특정 key에 접근하려면 반드시 leaf-node로 가야함으로!
- b-tree는 자주 접근하는 데이터를 위쪽 노드에 두면 더 빨리 찾지만 B+Tree는 불가능하다
1.5 Red Black Tree ⇒ 왜 DB 인덱스로 사용하지 않는가?
-
각 노드는 하나의 데이터만 가짐
-
특징
- 좌, 우 자식 노드의 개수 밸런스를 맞추고 검은색, 빨간색 노드는 재 정렬을 위해 사용
- 데이터 접근 시 포인터 필요
- 루트 노드와 리프노드(NIL : null leaf, 자료를 갖지 않고 트리의 끝을 나타내는 노드)는 항상 검은색
- 새로운 노드는 항상 빨간색
- 빨간 노드의 자식은 모두 검은색 (No Double Red)
- Restructuring (삼촌 노드가 검은색이거나 없는 경우)
- Recoloring (삼촌 노드가 빨간색인 경우)
- 관련 글
- 모든 리프 노드에서 Black Depth(리프~루트에서의 검은색 노드 갯수)는 같다.
-
B-Tree와의 공통점
- 밸런스 유지. O(logN)
-
B-Tree와의 차이점
-
참조 포인터 접근 수로 인하여 Index로는 사용되지 않는다
-
하나의 노드가 가지는 데이터 수가 다름
-
B-Tree는 배열로 실제 메모리 상에도 차례대로 저장 되어있음 ⇒ 실제 메모리 디스크에서 다음 인덱스에 접근 하는 식으로 빠름
-
그러나 Red-Black Tree는 각 노드가 개별 참조 포인터로 접근하기 때문에 속도가 느림
-
주소를 알아내기 이해 내부적으로 추가 연산이 필요
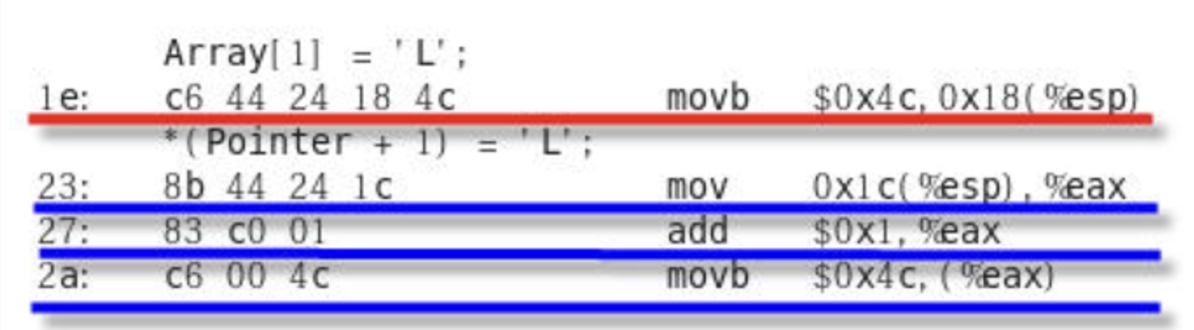
- 첫 바이트 블럭 주소 이동 연산
- 그 주소에서 x Byte 만큼 주소를 더하는 덧셈 연산
- 실제 배열에 넣을 값을 대입하는 연산 수행
-
-
사용 예시
- Java8 이후 TreeMap
- Java HashMap 8개 키-값 쌍 이상인 경우 링크드리스트 ⇒ RBT로 변경
- 6개 이하면 링크드리스트로 원복
- 리눅스 커널에서 많이 사용된다고 함
-
2. 왜 다른 자료구조가 아닌 B-Tree (B+Tree) 자료구조를 사용하나요?
- 왜 배열 X?
- 조회는 O(1)로 빠르지만 저장, 수정, 삭제시 월등히 느림
- 왜 해시테이블 X?
- 데이터 내부 정렬이 되어있지 않아 등호 연산만 가능하고 부등호 연산이 불가능 ⇒ 인덱스 특성상 크기 비교가 필요하기 때문
- 왜 RBT X?
- 시간 복잡도는 O(logN)으로 동일하지만 노드에 1개의 값만 존재하여 참조 포인터 접근수가 더 많아 탐색에 불리하다
- RedBlack-Tree는 무조건 하나의 노드에 하나의 데이터 요소만을 저장하므로 어떠한 요소를 탐색하든 참조 포인터 접근이 필수적이다. 반면, B-Tree는 하나의 노드에 여러 개의 데이터를 저장하므로 각 노드의 데이터 요소를 탐색할 때 참조 포인터 접근 없이 배열의 성질을 이용하여 빠르게 탐색이 가능하다. 결론적으로 참조 포인터의 접근 수가 B-Tree가 훨씬 적으므로 B-Tree를 인덱스의 자료 구조로 사용한다.
- 여기서 배열의 성질이란 B+Tree의 리프 노드가 연결 & 한 노드에 여러 값을 저장, 이 값들은 실제 메모리에도 순차적으로 저장되어있음으로 참조 없이 순차 탐색 가능
3. 공간복잡도 적으로 가장 유리한 자료구조는?
B-Tree, B+Tree, Red-Black Tree 중에서 공간복잡도 측면에서 가장 효율적인 것은 B+Tree이다.
B+Tree는 내부 노드에 데이터를 저장하지 않고 포인터만 저장하므로, 동일한 데이터를 저장할 때 B-Tree나 Red-Black Tree보다 공간을 더 효율적으로 사용할 수 있기 때문이다.

향유하는 개발자