🎈 RNN (Recurrent Neural Network)
일반적인 RNN은 하나의 입력을 통해 하나의 출력을 하거나, 각 입력으로부터 각 출력을 하는 형태였다. 그러나 기계번역 등의 분야에서는 입력 seqeunce로부터 출력 sequence를 만들어야 하는 상황이 있다. 예를 들어, 영어 문장 'I am a student'라는 입력을 받아 프랑스어 'je suis étudian'라고 번역해야 되는 상황이다.
또한 일반적인 RNN은 입력과 출력 sequence의 크기가 고정되어 있다. 물론 입력 sequence 크기는 가변적이지만 이를 동일하게 맞추기 위해 패딩을 사용했다. 하지만 앞서 본 기계번역 분야에서는 한 언어를 다른 언어로 번역해야 하므로 문장 길이가 달라질 수 있기 때문에 가변적인 출력 sequence에 대한 처리가 필요하다. 이를 해결하기 위해 seq2seq 모델이 제안되었다.
🎈 seq2seq (Sequence to Sequence)
기계 번역과 같은 task에서 문제는 입력과 출력에 대한 sequence를 고정할 수 없다는 것이다. 각 sequence에 대한 길이를 미리 알 수 없으며, 기계번역과 같이 입력 sequence를 출력 sequence로 생성하는 문제 해결을 위해 seq2seq 모델이 제안되었다.
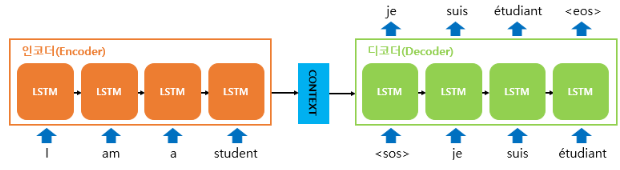
📌 seq2seq 구조
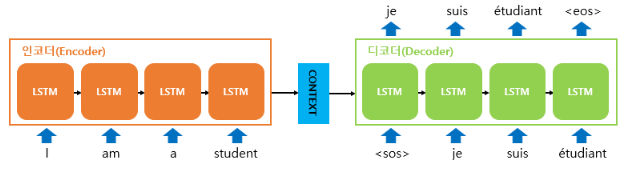
seq2seq의 구조는 위와 같다. 입력 문장으로 'I am a student'가 들어갔으며, 이를 'je suis étudian' 출력 문장으로 만드는 예시이다. 위 구조에서 입력 sequence를 처리하는 부분을 인코더(encoder), 출력 sequence를 생성하는 부분을 디코더(decoder)라고 한다. 이때 위 예시에서는 인코더와 디코더로 LSTM이 사용되었다.
📍 encdoer
인코더는 문장을 입력으로 받아 입력 문장에 대한 압축 정보인 context vector를 생성한다. 이를 위해 LSTM을 통해 hidden state를 넘겨주며 마지막 단계의 hidden state가 context vector가 된다.
📍 decoder
디코더는 전달 받은 context vector를 출력 문장을 예측한다. 기계번역 분야의 경우 입/출력 sequence가 가변적이기 때문에 token 개념을 도입한다. 위 그림에서 <sos>는 문장의 시작(start of string)을 뜻하고, <eos>는 문장의 끝(end of string)을 의미한다.
인코더로부터 전달 받은 context vector와 <sos> or 이전 예측값이 입력되면 다음 나올 확률이 가장 큰 단어를 예측한다.
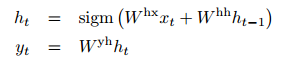
💡
: time step 의 hidden state (마지막 hidden state는 context vector)
: 입력 sequence
: 입력 sequence 와 context vector를 통해 예측한 단어
📍 architecture
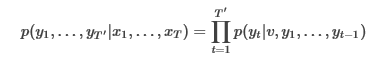
정리하자면 seq2seq는 주어진 입력 sequence()를 위 수식에 반복하여 출력 sequence()를 생성하는 것이다. 결국 구하고자 하는 것은 입력 문장이 들어왔을 때의 번역문장에 대한 조건부 확률 이다.
📌 Teacher Forcing (교사 강요)
seq2seq 모델에서는 교사 강요 학습 방법을 적용한다. 디코더에서 시점의 예측된 단어를 다시 input으로 사용하여 시점의 단어를 예측했다. 하지만 이것을 학습할 때에도 적용한다면 한번 예측이 틀리게 되면 연쇄적으로 디코더 전체의 예측과 학습이 비효율적으로 진행될 것이다.
이러한 문제를 해결하기 위해 학습을 진행할 때에는 시점의 예측값이 아니라 실제값을 input으로 사용하여 학습하는 교사 강요 학습 방법을 사용한다.
📌 추가 학습 전략
seq2seq 논문에서는 여러가지 방법으로 실험 후 성능을 측정하였다. 그 중 input sequence를 변환하여 학습하는 것이 성능에 영향을 주는 것을 확인하였다.
예를 들어, 입력 sequence 'ABC'를 통해 출력 sequence 'XYZ'로 번역하는 모델을 학습한다면, 입력 sequence를 reverse하게 'CBA'로 넣는 것이 더 성능이 좋다는 것을 확인하였다.
📌 seq2seq 문제점
기본적으로 seq2seq 모델도 RNN을 사용하기 때문에 sequence 문장이 길어질수록 정보를 끝까지 보존하지 못하는 문제가 발생한다. 이를 해결하기 위해 LSTM을 사용하지만 완벽하지는 않다.
또한 인코더 부분에서 입력 sequence를 고정된 크기의 vector로 만들기 때문에 정보를 압축하는 과정에서 손실이 발생한다.
